目的
SIGNATEさんの練習問題として公開されている「レンタル自転車の利用者予測」 に挑戦します。レンタル自転車の利用者数を予測するコンペです。
予測する手段として、回帰分析やDeep learning、XBBoostをやってみようと思いますが、その前に、教師データ(train data)の中身を確認します。データ数の確認や基本統計量、グラフなどを出力してデータの特徴や傾向を探ります。
使用するデータ
データはコンペのサイトにあるデータで入手します。学習用データ(train.tsv)、評価用データ(test.tsv)そして提出用のフォーマットとして応募用のサンプルファイル(sample_submit.csv)が提供されています。tsvはダウンロードした時に、csvに保存し直しました。
データを読み込む
train dataを読み込みます。いつもnumpy、pandas、matplotlib.pyplotもインストールしています。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
そしてtrain dataを読み込みます。
df = pd.read_csv("データの保存先のパスをコピペ/train.csv")
基本的な確認
まずはhead()でデータの頭出し。最初の5つの行が表示されます。
df.head()
下から5つの行を出したかったら、df.tail() を使います。尻尾ですね。
コンペのページでデータについて説明されています。文字列なのか、整数なのか書かれていますが、書かれていない時は
df.dtypes
で確認しましょう。丸括弧()は不要です。
そして基本統計量を出力します。
df.describe()
データ数(count)、平均(mean)、標準偏差(std)、最小値(min)、最大値(max)、第1から第3四分位数を確認する事ができます。
個別に基本統計量を見たい時、例えば最大値だけ見たい時は
df.describe.loc['max']
と書きます。
相関関係
このコンペは利用者数を予測することが目的です。利用者数('cnt')と他の変数の相関関係を調べて、相関がありそうであれば、説明変数に含めることを検討します。
コードはとてもシンプルです。
df.corr()
ただ、これだと全ての変数に対して相関関係を出力してきます。変数名が多いと左右にスクロールする手間が発生します。今回は利用者数に対して相関関係を見たいので、
df.corr()[['cnt']]
を実行します。
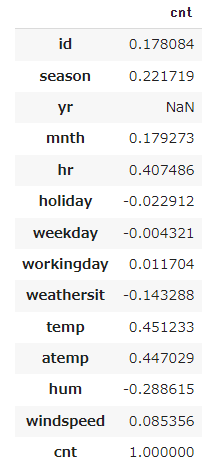
シンプルな出力になりました。0.4を超えているのが時間('hr')、温度('temp')、体感温度('atemp')で、季節('seanson')は0.2を超えています。季節('season')や曜日('weekday')はカテゴリーデータなので、この表を見て、相関の有無を判断することはしない方が良いと思います。カテゴリーデータはクロス集計などを作って特徴あるデータかどうか判断しても良いでしょう。
クロス集計
時間('hr')と利用者数に相関がありそうです。曜日ごとに何か特徴があるかもしれません。そこで、利用者数を時間('hr') x 曜日('weekday')でクロス集計を作りたいと思います。
p_table2 = pd.pivot_table(data=df.loc[:,['cnt','weekday','hr']], index = 'hr', columns = 'weekday', aggfunc='mean')
p_table2.columns=['Sun.','Mon.','Tue.','Wed.','Thr.','Fri.','Sat.']
p_table2
曜日('weekday') x 時間('hr')で表したければindexを'weekday'にして、columnsを'hr'にします。
p_table3 = pd.pivot_table(data=df.loc[:,['cnt','weekday','hr']], index = 'weekday', columns = 'hr', aggfunc='mean')
p_table3.index=['Sun.','Mon.','Tue.','Wed.','Thr.','Fri.','Sat.']
p_table3
でコードを書きます。
どちらの表もaggfunc='mean'なので平均値で出力しています。
グラフ
グラフを描く事で、データの特徴や傾向をビジュアルで理解できるようになります。上で出力したクロス集計表をグラフで示すともっとわかりやすくなります。
利用状況をグラフにしてみました。.plot()を最後に付け足すだけです。
p_table2 = pd.pivot_table(data=df.loc[:,['cnt','weekday','hr']], index = 'hr', columns = 'weekday', aggfunc='mean')
p_table2.columns=['Sun.','Mon.','Tue.','Wed.','Thr.','Fri.','Sat.']
p_table2.plot
やはり、グラフにした方がわかりやすいですね。
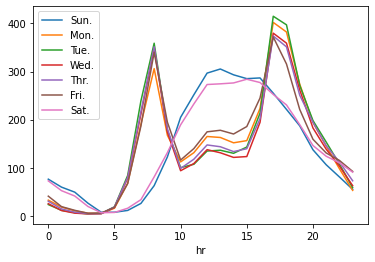
土日と平日で傾向がはっきり分かれていますね。
曜日('weekday')はカテゴリーデータです。pivot_tableを実行してグラフにしましたので、このようにグラフを描く事ができました。pivot_tableを実行しないで、そのまま変数を投入すると期待しているグラフが出力されません。カテゴリーデータでグラフを描くにはひと工夫必要です。詳しくは「生データ(raw data)のカテゴリーデータからグラフを作る - グルーピング」をご覧ください。グルーピングという作業が必要です。