目次
1. 概要
2. 環境
3. 使用するライブラリ
4. 全体の作成フロー
5. 各フローの説明
6. 作成した穴埋め問題に対する自己評価
7. ネットで紹介されていた手法を用いて問題文を生成してみた
8. 全体を通しての振り返り
9. 最後に
1. 概要
私は現在、自然言語処理技術について勉強しています。勉強をしていく中で、自然言語処理技術を使って「任意のテキストから様々な問題文を自動で作成できれば面白いのではないか?」と思いました。そこで今回は、問題作成の第一歩として「ネットワーク分析を用いた自然な穴埋め問題の作成」にチャレンジしたいと思います。そして、作成の振り返り、アウトプットとして本記事に作成手順や結果を書いていきたいと思います。
「ネットワーク分析を用いた自然な穴埋め問題の作成」を選んだ理由は、以下の通りです。
- ネットワーク分析により媒介中心性の高い単語を抽出できれば、穴埋め問題が出来そうだと思ったため
- 自然な穴埋め問題を作成する過程の中で、キーワード・固有表現の抽出についての知識が深められると思ったため
- キーワードの抽出手法を学び、より高度な問題(キーワードに基づくクイズ、類似問題、画像や動画に基づいた問題)の生成に繋げていきたいため
2. 環境
実行環境:Google Colaboratory
ブラウザ:Google Chrome
OS: Windows
プログラミング言語:Python3
3. 使用するライブラリ
import MeCab
import numpy as np
import pandas as pd
import networkx as nx
import re
import textwrap
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import TfidfVectorizer
Google Colabratory 環境には形態素解析ライブラリであるMeCabが入っていないので、下記コードによりインストールする必要があります。今回、辞書は mecab-ipadic-NEologdを使用します。
# 形態素分析ライブラリーMeCab と 辞書(mecab-ipadic-NEologd)のインストール
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
!pip install mecab-python3 > /dev/null
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
【参考にした記事】
Google ColabにMeCabとipadic-NEologdをインストールする
4. 全体の作成フロー
穴埋め問題作成までの流れは以下の通りです。
①原文(穴埋め前の文章)の用意
②原文の不要な文字・記号を削除
③分かち書き
④TF-IDF値による重みありの単語文書行列を作成
⑤相関行列を作成
⑥「相関係数が高い単語のペア」と「ペアの相関係数の値」を取得
⑦無向グラフを作成
⑧媒介中心性の高い単語を取得
⑨単語の品詞を限定し、穴埋め対象の単語(キーワード)を取得
⑩穴埋め対象の単語の穴埋め(穴埋めされた文章完成!)
5. 各フローの説明
それでは、上記のフローについて順を追って説明していきます。
①原文(穴埋め前の文章)の用意
本記事では、以下の文を原文として説明していきます。
text = """サッカー(米: soccer、英: football)は、丸い球体を用いて1チームが11人の計2チームの間で行われるスポーツ競技の一つである。
アソシエーション・フットボール(英: association football; 協会式フットボールの意)ないしはアソシエーション式フットボール[注釈 1]
とも呼ばれている。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球とも言う。サッカーは、210を越える国
と地域で、多くの選手達によってプレーされており、4年に一度行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えており[1]、
世界で最も人気のあるスポーツ[2]といえる。試合は、それぞれの短い方の辺の中央にゴールがある長方形のフィールドでプレーされる。試合の目的は、
相手ゴールにボールを入れ得点することである。"""
※原文の引用元:Wikipedia_サッカー
②原文の不要な文字・記号を削除
今回は()、[ ] で囲まれた文字は削除します。
# text から不要な文字列を削除
text = re.sub("\(.+?\)|\[.+?\]|\n", "", text)
削除後の文章は以下の通りです。
サッカーは、丸い球体を用いて1チームが11人の計2チームの間で行われるスポーツ競技の一つで
ある。 アソシエーション・フットボールないしはアソシエーション式フットボール とも呼ばれて
いる。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球と
も言う。サッカーは、210を越える国 と地域で、多くの選手達によってプレーされており、4年
に一度行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えており、
世界で最も人気のあるスポーツといえる。試合は、それぞれの短い方の辺の中央にゴールがある長方
形のフィールドでプレーされる。試合の目的は、 相手ゴールにボールを入れ得点することである。
③分かち書き
②で得られた文章を分かち書きします。そして、一文章区切りで分割しリスト化します。
この時、リストの最後の要素に改行文字「\n」があったり、文章の両端に空白文字があるので削除しておきます。
# MeCabで分かち書き、1文章ごとにリスト化、不要な文字削除
words = MeCab.Tagger("-Owakati").parse(text) # 分かち書き
words = words.split("。") # 「。」を基準にして文章を分割する(= 1文章ごとにリスト化する)
words.pop(-1) # リストの最後の要素には「改行」が入っている。不要なので削除。
doc = []
for docs in words:
doc.append(docs.strip()) # 文章の両端の空白文字を削除する
上記の処理を実行後は以下のリストが作成されます。
文章が分かち書きされた状態で1文章ごとにリストに格納されていることが分かります。
['サッカー は 、 丸い 球体 を 用い て 1 チーム が 11 人 の 計 2 チーム の 間 で 行わ れる スポーツ 競技 の 一つ で ある',
'アソシエーション ・ フットボール ないしは アソシエーション 式 フットボール と も 呼ば れ て いる',
'他 の フットボール コード と 比較 し て 、 手 の 使用 が 極端 に 制限 さ れる という 特徴 が ある',
'蹴球 と も 言う',
'サッカー は 、 210 を 越える 国 と 地域 で 、 多く の 選手 達 によって プレー さ れ て おり 、 4 年 に 一度 行わ れる '
'FIFA ワールドカップ の テレビ 視聴 者 数 は 全 世界 で 通算 310 億 人 を 超え て おり 、 世界 で 最も 人気 の ある '
'スポーツ と いえる',
'試合 は 、 それぞれ の 短い 方 の 辺 の 中央 に ゴール が ある 長方形 の フィールド で プレー さ れる',
'試合 の 目的 は 、 相手 ゴール に ボール を 入れ 得点 する こと で ある']
④TF-IDF値による重みありの単語文書行列を作成
③までの工程で文章の前処理は完了しました。続いて、文章を数値データへ変換します。
今回はTF-IDF値によって重みづけされた単語文書行列を作成します。TF-IDF値は「ある単語の文書内における重要度」を表しています。したがって、TF-IDF値で重みづけすることによって「単語の重要度を加味した単語文書行列」を作成することができます。
# TF-IDF値による重みありの単語文書行列を作成
words_array = np.array(doc) # リスト形式からNumPy配列へ変換(arrayのほうが計算速度が速いため)
tfidf_vec = TfidfVectorizer(use_idf=True) # TfidfVectorizer()を用いた変換器を生成
words_tfidf_vecs = tfidf_vec.fit_transform(words_array) # fit_transform() で words_array の学習と、重み付けされた単語の出現回数を配列に変換
words_tfidf_array = words_tfidf_vecs.toarray() # toarray()によって出力をNumPyのndarray配列に変換
上記コードを実行した結果、以下の単語文書行列(words_tfidf_array)が得られます。
※出力結果を制限して表示させています。以下の出力結果は、1文章目と2文章目に対する単語文書行列です。今回の例では7文章あるので、実際は7文章分の行列が出来ています。
疎な行列であることがすこし気になりますが、単語文書行列は作成できました。
[[0.28019018 0. 0. 0. 0.15119504 0.
0. 0. 0. 0. 0. 0.
0. 0. 0.17260259 0. 0. 0.
0.23258191 0.23258191 0.56038036 0. 0. 0.
0. 0. 0. 0.28019018 0. 0.
0. 0.28019018 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0.28019018 0.28019018 0. 0.
0. 0.28019018 0.23258191 0. 0. 0.
0. 0. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0.32015502 0. 0. 0. 0. 0.
0.32015502 0. 0. 0.64031004 0. 0.
0. 0. 0. 0. 0. 0.53151232
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0.32015502 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. ]]
⑤相関行列を作成
④で作成した単語文書行列から相関行列を作成します。
データの解析をしやすくするため、まずは単語文書行列をデータフレーム形式に変換します。
その後、相関行列を作成します。
dtm = pd.DataFrame(words_tfidf_array, columns=tfidf_vec.get_feature_names(),
index=words) # 「TF-IDF値による重みありの単語文書行列」をDataFrame形式に変換。カラム(列)は単語、インデックス(行)は文章の行列ができる
corr_matrix = dtm.corr().abs() # 各列には単語の分散表現が格納されている
# 各列間(各単語間)の相関係数を算出し、相関行列を作成、abs()により値は絶対値へ
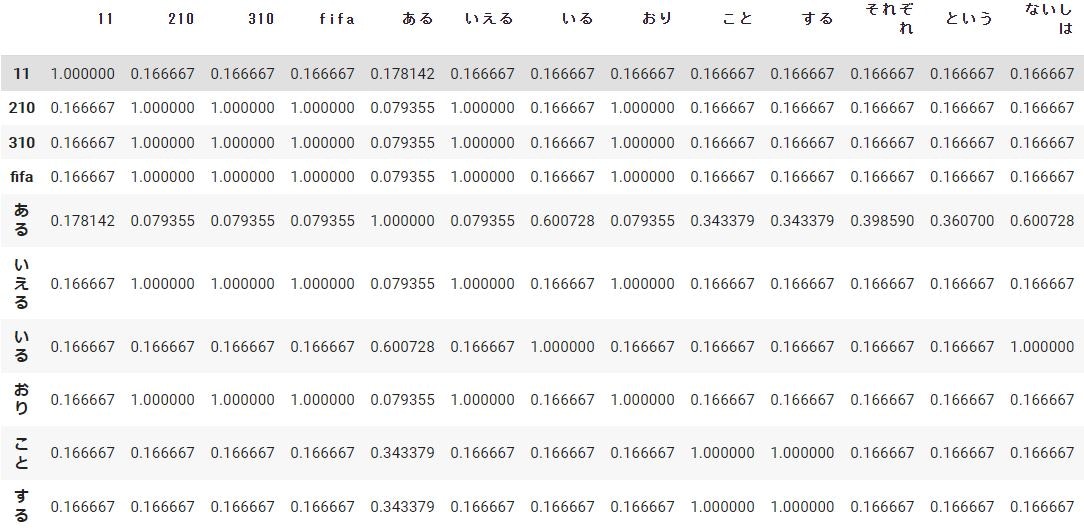
得られた相関行列は以下の通りです。(一部抜粋)
相関行列は得られましたが、相関係数が似たような値ばかりになっています。これは、おそらく文章数(データ)が少ないためであると考えられます。もう少し文章数を増やせば、相関係数の値もばらついてくるかと思います。
⑥「相関係数が高い単語のペア」と「ペアの相関係数の値」を取得
得られた相関行列から「相関係数が高い単語のペア」とそのペア同士の「相関係数の値」を取得します。
今回は相関係数の値が「0.5以上1.0未満」である単語のペアを取得することにします。
# データセットの作成
corr_stack = corr_matrix.stack() # stack()によりデータフレームからリストへ変換(列方向から行方向へ変換)
index = pd.Series(corr_stack.index.values) # 単語のペアを取得
value = pd.Series(corr_stack.values) # 相関係数の値を取得(単語のペアと対応している)
# 相関係数が0.5以上1.0未満のものを抽出
tmp3 = [] # 相関係数が0.5以上1.0未満の値を持つindex値のリスト
tmp4 = [] # 相関係数が0.5以上1.0未満のvalue値のリスト
for i in range(0, len(index)):
if value[i] >= 0.5 and value[i] < 1.0:
tmp1 = str(index[i][0]) + ' ' + str(index[i][1])
tmp2 = tmp1.split()
tmp3.append(tmp2)
tmp4 = np.append(tmp4, value[i])
上記コードを実行後、tmp3には「相関係数が0.5以上1.0未満の値を持つ単語のペアのリスト」、tmp4には「ペア同士の相関係数の値」が格納されます。
その後、tmp3とtmp4をデータフレーム形式に変換し、列方向へ連結させます。
tmp3 = pd.DataFrame(tmp3) # データフレームへ変換
tmp3 = tmp3.rename(columns={0: 'node1', 1: 'node2'}) # カラム名を変更
tmp4 = pd.DataFrame(tmp4) # データフレームへ変換
tmp4 = tmp4.rename(columns={0: 'weight'}) # カラム名を変更
df_corlist = pd.concat([tmp3, tmp4], axis=1) # 列方向へ連結
上記コードを実行して得られたdf_corlistの中身は以下の通りです(一部抜粋)。
「相関係数が高い単語のペア」と「ペアの相関係数の値」をデータフレーム形式で取得することが出来ました。

⑦無向グラフを作成
⑥で得られたデータ(df_corlist)を基に無向グラフを作成します。
# 無向グラフを作成(node1 と node2 の相関係数を基に無向グラフを作成)
G_corlist = nx.from_pandas_edgelist(df_corlist, 'node1', 'node2', ['weight'])
それでは、作成したグラフを可視化してみたいと思います。
# 作成したグラフを可視化する(可視化したくない場合はコメントアウト)
pos = nx.spring_layout(G_corlist) # 各ノードの最適な表示位置を決める
nx.draw_networkx(G_corlist, pos) # ネットワークを表示
plt.show()
上記コードを実行後、下記の出力結果(グラフ)が得られました。
しかし、このグラフを見ただけでは特徴や特性を把握することが難しいです。そのため、次の工程で指標を用いてグラフの特徴を把握していきたいと思います。
⑧媒介中心性の高い単語を取得
得られた無向グラフから媒介中心性の高い単語を取得します。
媒介中心性の定義は以下の通りです。(引用元:グラフ理論入門:ソーシャル・ネットワークの分析例)
媒介中心性(Betweenness)は、あるノードが他のノードの最短経路である度合いを指標にしたものです。値が高ければ高いほど常に情報流通の中にいることを表しています。
つまり、媒介中心性の高いノード(単語)はネットワークにおいて中心的な役割を持っていると解釈することができます。
そのため、今回は媒介中心性の高い単語=重要な単語として穴埋め対象の単語とします。
各単語の媒介中心性を求めるコードは以下です。
weightには、相関係数の値を指定します。
# 媒介中心性の計算
bc = nx.betweenness_centrality(G_corlist, weight = "weight")
続いて、単語を媒介中心性が高い順番に並び替えます。
下記コードを実行後、単語を媒介中心性が高い順番に並び替えたリスト(keywords)が得られます。
keywords = [] # 媒介中心性の高い単語が降順で格納されるリスト
for k, v in sorted(bc.items(), key=lambda x: -x[1]): # k: 単語, v: 単語kの値
# print(str(k) + ': ' + str(v))
keywords.append(str(k)) # 値の高い単語順でリストに格納していく
keywordsの中身は下記の通りです。
これで媒介中心性の高い単語を取得することができました。この単語郡が穴埋め対象の単語の候補となります。
['ある', 'ゴール', '試合', 'れる', 'プレー', 'サッカー', 'スポーツ', '行わ', 'いる', 'ないしは', 'アソシエーション', '呼ば', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技', '言う', '蹴球', 'フットボール', 'こと', 'する', 'それぞれ', 'フィールド', '中央', '短い', '長方形', 'ボール', '入れ', '得点', '目的', '相手']
【参考】様々な指標との比較
⑧の工程では媒介中心性を指標として単語を並び替えました。しかし、媒介中心性以外にもいくつか指標はあります。
今回は参考程度にはなりますが、他の指標も用いて単語を並び替えてみました。ここでは、各指標ごとの出力結果の違いを確認してみたいと思います。
各指標の考え方は下記の記事が参考になります。
グラフ理論入門:ソーシャル・ネットワークの分析例
グラフ・ネットワーク分析で遊ぶ(3):中心性(PageRank, betweeness, closeness, etc.)
用いる指標は以下の通りです。
- 次数中心性
- 近接中心性
- 固有ベクトル中心性
- PageRank
下記にそれぞれの指標を求めるコードを記述します。
# 次数中心性の計算
dc = nx.degree_centrality(G_corlist)
# 近接中心性の計算
cc = nx.closeness_centrality(G_corlist)
# 固有ベクトル中心性
ec = nx.eigenvector_centrality_numpy(G_corlist, weight = "weight")
# PageRankの計算
pr = nx.pagerank(G_corlist, weight = "weight")
それでは、各指標ごとの出力結果を確認してみます。
※実行毎に作成される無向グラフに多少の違いがあるので、出力結果が少し変わる可能性もあります。
出力結果を見てみると、どの指標を用いてもあまり単語の順番に変化はないように見えます。
文章数が少ないため、あまり違いが生まれないのかもしれません。どの指標が適切であるかは、他の文章などを用いて検証してみる必要がありそうです。
媒介中心性
['ある', 'ゴール', '試合', 'れる', 'プレー', 'サッカー', 'スポーツ', '行わ', 'いる', 'ないしは', 'アソシエーション', '呼ば', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技', '言う', '蹴球', 'フットボール', 'こと', 'する', 'それぞれ', 'フィールド', '中央', '短い', '長方形', 'ボール', '入れ', '得点', '目的', '相手']
次数中心性
['ゴール', '試合', 'ある', 'プレー', 'サッカー', 'スポーツ', '行わ', 'れる', 'フットボール', 'それぞれ', 'フィールド', '中央', '短い', '長方形', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技', 'いる', 'ないしは', 'アソシエーション', '呼ば', 'こと', 'する', 'ボール', '入れ', '得点', '目的', '相手', '言う', '蹴球']
近接中心性
['ゴール', '試合', 'ある', 'プレー', 'れる', 'それぞれ', 'フィールド', '中央', '短い', '長方形', 'こと', 'する', 'ボール', '入れ', '得点', '目的', '相手', 'いる', 'ないしは', 'アソシエーション', '呼ば', '言う', '蹴球', 'サッカー', 'スポーツ', '行わ', 'フットボール', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技']
固有ベクトル中心性
['試合', 'ゴール', 'プレー', '長方形', 'それぞれ', 'フィールド', '中央', '短い', 'れる', 'ある', 'する', 'こと', 'ボール', '入れ', '得点', '目的', '相手', 'アソシエーション', 'いる', 'ないしは', '呼ば', 'フットボール', '蹴球', '言う', '一つ', 'チーム', '用い', '11', '丸い', '球体', '競技', 'スポーツ', 'サッカー', '行わ']
PageRank
['ゴール', '試合', 'ある', 'プレー', 'サッカー', 'スポーツ', '行わ', 'フットボール', 'れる', 'それぞれ', 'フィールド', '中央', '短い', '長方形', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技', 'いる', 'ないしは', 'アソシエーション', '呼ば', 'こと', 'する', 'ボール', '入れ', '得点', '目的', '相手', '言う', '蹴球']
⑨単語の品詞を限定し、穴埋め対象の単語(キーワード)を取得
⑧では媒介中心性の高い単語を取得し、穴埋め対象となる単語の候補を得ることができました。
そのまま得られたリスト(keywords)の上位の単語を穴埋め対象の単語にしてもいいのですが、ここでもう一工夫してみたいと思います。
ここでもう一度、⑧で得られた単語のリストを見てみます。
媒介中心性
['ある', 'ゴール', '試合', 'れる', 'プレー', 'サッカー', 'スポーツ', '行わ', 'いる', 'ないしは', 'アソシエーション', '呼ば', '11', 'チーム', '一つ', '丸い', '球体', '用い', '競技', '言う', '蹴球', 'フットボール', 'こと', 'する', 'それぞれ', 'フィールド', '中央', '短い', '長方形', 'ボール', '入れ', '得点', '目的', '相手']
ここでこのリストの中の上位5単語を穴埋め対象の単語とすると、「ある」、「ゴール」、「試合」、「れる」、「プレー」が該当単語になります。この単語郡の中の「ある」や「れる」という単語は穴埋め対象の単語としては不自然に感じます。
そこで今回は、下記の条件を満たす単語を穴埋め対象の単語とします。
- 「名詞」である
- 品詞細分類1が「接尾」ではない
- 品詞細分類1が「非自立」ではない
今回は単語の形態素解析結果を見たうえで、不必要だと思う単語の品詞、品詞細分類を自分なりに判断しました。
この条件は色々変えてみることで、より良い条件が見つかるかもしれません。
それでは、上記の条件を満たす単語を取得してみます。
# キーフレーズをそれぞれ形態素解析
KeyPhrase = " ".join(keywords) # 空白文字を間に挿入して、連結する(後ほど、形態素解析をするため)
tagger = MeCab.Tagger()
tagger.parse("")
node = tagger.parseToNode(KeyPhrase)
# 「品詞が名詞」かつ「品詞細分類1が接尾、非自立以外」のキーフレーズを取得
KeyPhrase_noun = [] # キーフレーズ(名詞のみ)が入るリスト
while node:
if node.feature.split(",")[0].startswith("名詞") and not (node.feature.split(",")[1].startswith("非自立") or node.feature.split(",")[1].startswith("接尾")):
word = node.surface # node の表層形を取得
KeyPhrase_noun.append(word)
node = node.next
上記コードを実行後、得られたリスト(KeyPhrase_noun)は以下の通りです。
これらの単語郡であれば、穴埋め対象にしても不自然ではないと思います。
['ゴール', '試合', 'プレー', 'サッカー', 'スポーツ', 'アソシエーション', '11', 'チーム', '一つ', '球体', '競技', '蹴球', 'フットボール', 'それぞれ', 'フィールド', '中央', '長方形', 'ボール', '得点', '目的', '相手']
⑩穴埋め対象の単語の穴埋め(穴埋めされた文章完成!)
ここまでで、穴埋め対象となる単語の候補の抽出は完了しました。
最後は、⑨で得られたリスト(KeyPhrase_noun)の中から実際に穴埋め対象となる単語を取得し、穴埋め問題を作成します。
それでは、穴埋め問題を作成する関数を作成します。
今回は任意で穴埋め対象の単語数を決めたかったので、引数で指定するようにしました。
def QuestionGen(num):
if num > 10:
print("穴埋め個数の最大値は10です。10以下の数字を設定してください。")
else:
number = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
keyword = KeyPhrase_noun[:num]
Question_text = text
for i, word in enumerate(keyword):
Question_text = re.sub(word, "「 {} 」".format(number[i]), Question_text)
Question_text = re.sub("\n", "", Question_text)
Original = textwrap.wrap(text, 45)
Question_text = textwrap.wrap(Question_text, 45)
print()
print("(原文)")
print("\n".join(Original))
print()
print("(穴埋め問題)")
print("\n".join(Question_text))
print()
print("(答え)")
for i in range(len(keyword)):
print("{} : {}".format(number[i], keyword[i]))
最後にこの関数を実行してみます。
QuestionGen(3)
実行結果は下記の通りです。今回は、原文、作成できた穴埋め問題、答えを表示させるようにしています。
これでネットワーク分析による穴埋め問題の作成が完了しました!
(原文)
サッカーは、丸い球体を用いて1チームが11人の計2チームの間で行われるスポーツ競技の一つで
ある。アソシエーション・フットボールないしはアソシエーション式フットボールとも呼ばれている
。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球とも言
う。サッカーは、210を越える国と地域で、多くの選手達によってプレーされており、4年に一度
行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えており、世界で
最も人気のあるスポーツといえる。試合は、それぞれの短い方の辺の中央にゴールがある長方形のフ
ィールドでプレーされる。試合の目的は、相手ゴールにボールを入れ得点することである。
(穴埋め問題)
サッカーは、丸い球体を用いて1チームが11人の計2チームの間で行われるスポーツ競技の一つで
ある。アソシエーション・フットボールないしはアソシエーション式フットボールとも呼ばれている
。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球とも言
う。サッカーは、210を越える国と地域で、多くの選手達によって「 3 」されており、4年に
一度行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えており、世
界で最も人気のあるスポーツといえる。「 2 」は、それぞれの短い方の辺の中央に「 1 」が
ある長方形のフィールドで「 3 」される。「 2 」の目的は、相手「 1 」にボールを入れ
得点することである。
答え
1 : ゴール
2 : 試合
3 : プレー
6 作成した穴埋め問題に対する自己評価
ここでは、様々な文章を基に作成した穴埋め問題文を見て自分なりの評価・考察をしていきたいと思います。
穴埋めする単語数は「5」に設定します。
作成結果① Wikipedia_サッカー
原文の引用元:Wikipedia_サッカー
【自己評価】
- 穴埋め箇所はそれほど不自然ではない。
- サッカーの記事であるため、サッカー独自の穴埋め単語(例:FIFAワールドカップ、蹴球)が穴埋めされてほしい。これは重要な単語の判断基準(固有名詞を優先するなど)を変えれば解決できそう。
(原文)
サッカーは、丸い球体を用いて1チームが11人の計2チームの間で行われるスポーツ競技の一つで
ある。アソシエーション・フットボールないしはアソシエーション式フットボールとも呼ばれている
。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球とも言
う。サッカーは、210を越える国と地域で、多くの選手達によってプレーされており、4年に一度
行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えており、世界で
最も人気のあるスポーツといえる。試合は、それぞれの短い方の辺の中央にゴールがある長方形のフ
ィールドでプレーされる。試合の目的は、相手ゴールにボールを入れ得点することである。
(穴埋め問題)
「 4 」は、丸い球体を用いて1チームが11人の計2チームの間で行われる「 5 」競技の一
つである。アソシエーション・フットボールないしはアソシエーション式フットボールとも呼ばれて
いる。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球と
も言う。「 4 」は、210を越える国と地域で、多くの選手達によって「 3 」されており、
4年に一度行われるFIFAワールドカップのテレビ視聴者数は全世界で通算310億人を超えてお
り、世界で最も人気のある「 5 」といえる。「 2 」は、それぞれの短い方の辺の中央に「
1 」がある長方形のフィールドで「 3 」される。「 2 」の目的は、相手「 1 」にボー
ルを入れ得点することである。
(答え)
1 : ゴール
2 : 試合
3 : プレー
4 : サッカー
5 : スポーツ
作成結果② Wikipedia_天気予報
原文の引用元:Wikipedia_天気予報
【自己評価】
- 重要そうな単語をしっかり穴埋めできている。
- 形態素解析により形態素に分解されてしまうため、「名詞+名詞」で一つの意味を成している文字列(天気予報、数値予報、情報収集)を上手く認識できていない。その結果、不自然な穴埋め箇所がある(天気「 5 」、「 3 」収集など)。
(原文)
日常生活や業務に対して天気が与える影響は非常に大きく、19世紀に近代気象学が生まれると同時
に科学的な天気予報の試みが行われてきた。現代における天気予報は、気象のメカニズムを解明する
気象学の発達と並んで、多種多様で世界的な気象観測網の構築、コンピューターの発展に支えられた
数値予報インフラの整備、そして情報を一般に広く伝えるマスメディアによって支えられ、運用され
ている。地球の大気の挙動は、カオスそのものであるため、初期値鋭敏性が高く、大気シミュレーシ
ョンの計算誤差が、反復計算により指数関数的に増大するため、長期間の予測は極めて難しい。しか
し、予測の初期値を得る大気計測やスーパーコンピュータによるモデルの高精度化により、継続的に
予報精度の改善は達成されている。数値予報が台頭してくるまで、天気予報は観測記録をもとにした
過去のノウハウや経験則の蓄積に頼る部分が大きく、予報官の経験に左右されるところが大きかった
。数値予報の登場によって解析業務の負担が軽減されるとともに、精度が向上して予報の幅も広がっ
てきている。また、観測の自動化・無人化も急速に進んでいる。気象観測・情報収集・研究に関して
は、世界気象機関などの国際機関、世界各国の気象機関や防災担当の国家機関、研究機関や大学など
によって連携して行われている。世界各国で法的な規定をもって責任機関を定め、気象に関する業務
を担当させている。国によっては予報業務の自由化も進められているが、国際的には、国連の世界気
象機関が、1995年の第12回世界気象会議議決事項40附属書3において、「関係する加盟国が
認めた場合を除き、商業セクターの気象業務提供者は、その活動する国及び海域において、生命及び
財産の安全に関わる予報及び警報を公表してはならない。商業セクターが公表する生命及び財産の安
全に関わる予報及び警報は、国家気象・水文気象機関等の公的機関が公共的な業務に係る責務として
実施するものと矛盾しないものでなければならない」との指針を示している。現代の天気予報は、ゲ
リラ豪雨や激化する猛暑などに代表される気象災害の増加・変化やニーズの変化への対応、ENSO
やAO等の最新知見を取り入れた予報精度の向上などが大きなテーマとされている。そのため、そう
いった豪雨などの異常気象、ENSOやAOなどの気候パターン、地球温暖化などの気候変動の解明
が求められているほか、気象機関は市民に対して天気や気候変動に関する説明・解説を行う一定の責
任も負っている。
(穴埋め問題)
日常生活や業務に対して天気が与える影響は非常に大きく、19世紀に近代気象学が生まれると同時
に科学的な天気「 5 」の試みが行われてきた。現代における天気「 5 」は、気象のメカニズ
ムを解明する気象学の発達と並んで、多種多様で世界的な気象観測網の構築、コンピューターの発展
に支えられた数値「 5 」インフラの整備、そして「 3 」を一般に広く伝えるマスメディアに
よって支えられ、運用されている。「 2 」の大気の挙動は、カオスそのものであるため、初期値
鋭敏性が高く、大気シミュレーションの計算誤差が、反復計算により指数関数的に増大するため、長
期間の予測は極めて難しい。しかし、予測の初期値を得る大気計測やスーパーコンピュータによるモ
デルの高精度化により、継続的に「 5 」精度の改善は達成されている。数値「 5 」が台頭し
てくるまで、天気「 5 」は観測記録をもとにした過去のノウハウや経験則の蓄積に頼る部分が大
きく、「 5 」官の経験に左右されるところが大きかった。数値「 5 」の登場によって解析業
務の負担が軽減されるとともに、精度が向上して「 5 」の幅も広がってきている。また、観測の
自動化・無人化も急速に進んでいる。気象観測・「 3 」収集・研究に関しては、世界気象機関な
どの「 1 」機関、世界各国の気象機関や防災担当の国家機関、研究機関や大学などによって連携
して行われている。世界各国で法的な規定をもって責任機関を定め、気象に関する業務を担当させて
いる。国によっては「 5 」業務の自由化も進められているが、「 1 」的には、国連の世界気
象機関が、1995年の第12回世界気象会議議決事項40附属書3において、「関係する加盟国が
認めた場合を除き、商業セクターの気象業務提供者は、その活動する国及び海域において、生命及び
財産の安全に関わる「 5 」及び警報を公表してはならない。商業セクターが公表する生命及び財
産の安全に関わる「 5 」及び警報は、国家気象・水文気象機関等の公的機関が公共的な業務に係
る責務として実施するものと矛盾しないものでなければならない」との指針を示している。現代の天
気「 5 」は、ゲリラ豪雨や激化する猛暑などに代表される気象災害の増加・変化やニーズの変化
への対応、ENSOやAO等の最新知見を取り入れた「 5 」精度の向上などが大きなテーマとさ
れている。そのため、そういった豪雨などの異常気象、ENSOやAOなどの「 4 」パターン、
「 2 」温暖化などの「 4 」変動の解明が求められているほか、気象機関は市民に対して天気
や「 4 」変動に関する説明・解説を行う一定の責任も負っている。
(答え)
1 : 国際
2 : 地球
3 : 情報
4 : 気候
5 : 予報
作成結果③ Wikipedia_自然言語処理
原文の引用元:Wikipedia_自然言語処理
【自己評価】
- 穴埋め対象の単語が文章内に多く存在しているがゆえに、穴埋め箇所が多くなりすぎてしまっている。そのため、穴埋め問題としては適切ではない。
- 複数の名詞が連なって意味を成している単語(自然言語処理、計算言語学など)を認識できていない。
(原文)
自然言語処理は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり
、人工知能と言語学の一分野である。「計算言語学」との類似もあるが、自然言語処理は工学的な視
点からの言語処理をさすのに対して、計算言語学は言語学的視点を重視する手法をさす事が多い。デ
ータベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な表現に変換するといっ
た処理が含まれる。応用例としては予測変換、IMEなどの文字変換が挙げられる。自然言語の理解
をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、自然言語処理の差は
、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解析手法が広められた為、パ
ーサなどが一段と精度や速度が上がり、その意味合いは違ってきている。もともと自然言語の意味論
的側面を全く無視して達成できることは非常に限られている。このため、自然言語処理には形態素解
析と構文解析、文脈解析、意味解析などをSyntaxなど表層的な観点から解析をする学問である
が、自然言語理解は、意味をどのように理解するかという個々人の理解と推論部分が主な研究の課題
になってきており、両者の境界は意思や意図が含まれるかどうかになってきている。
(穴埋め問題)
自然「 1 」「 4 」は、人間が日常的に使っている自然「 1 」をコンピュータに「 4
」させる一連の技術であり、人工知能と「 1 」学の一分野である。「計算「 1 」学」との類
似もあるが、自然「 1 」「 4 」は工学的な視点からの「 1 」「 4 」をさすのに対し
て、計算「 1 」学は「 1 」学的視点を重視する「 3 」をさす事が多い。データベース内
の情報を自然「 1 」に「 5 」したり、自然「 1 」の文章をより形式的な表現に「 5
」するといった「 4 」が含まれる。応用例としては予測「 5 」、IMEなどの文字「 5
」が挙げられる。自然「 1 」の理解をコンピュータにさせることは、自然「 1 」理解とされ
ている。自然「 1 」理解と、自然「 1 」「 4 」の差は、意味を扱うか、扱わないかとい
う説もあったが、最近は数理的な「 1 」「 2 」「 3 」が広められた為、パーサなどが一
段と精度や速度が上がり、その意味合いは違ってきている。もともと自然「 1 」の意味論的側面
を全く無視して達成できることは非常に限られている。このため、自然「 1 」「 4 」には形
態素「 2 」と構文「 2 」、文脈「 2 」、意味「 2 」などをSyntaxなど表層的
な観点から「 2 」をする学問であるが、自然「 1 」理解は、意味をどのように理解するかと
いう個々人の理解と推論部分が主な研究の課題になってきており、両者の境界は意思や意図が含まれ
るかどうかになってきている。
(答え)
1 : 言語
2 : 解析
3 : 手法
4 : 処理
5 : 変換
7. ネットで紹介されていた手法を用いて問題文を生成してみた
今回自分が試した手法以外の手法で穴埋め問題を作成し完成度の比較をしてみたいと思い、ネットに掲載されていたコードを参考に自分なりに工夫して作成してみました。
ここでは作成できた結果だけを記載し、コードについては今後別記事で記載したいと考えています。
【参考にした記事】
文章埋め込みを用いた教師なしキーフレーズ抽出EmbedRankの実装とその評価
【初心者向け】自然言語処理ツール「GiNZA」を用いた言語解析(形態素解析からベクトル化まで)
どの作成結果を見ても完成度が高いです。各記事のテーマにおける固有表現を正確に抽出し穴埋めできていることが分かります。どうみても自分の手法は完敗ですね。ですが、自分の手法もまだ改善できる余地はあると思うので、今後改善できればと思います。
作成結果① Wikipedia_サッカー
(穴埋め問題)
「 5 」は、丸い球体を用いて1チームが11人の「 2 」の間で行われるスポーツ競技の一つ
である。アソシエーション・フットボールないしはアソシエーション式フットボールとも呼ばれてい
る。他のフットボールコードと比較して、手の使用が極端に制限されるという特徴がある。蹴球とも
言う。「 5 」は、「 4 」を越える国と地域で、多くの「 3 」達によってプレーされてお
り、4年に一度行われる「 1 」のテレビ視聴者数は全世界で通算310億人を超えており、世界
で最も人気のあるスポーツといえる。試合は、それぞれの短い方の辺の中央にゴールがある長方形の
フィールドでプレーされる。試合の目的は、相手ゴールにボールを入れ得点することである。
(答え)
1 : FIFAワールドカップ
2 : 計2チーム
3 : 選手
4 : 210
5 : サッカー
作成結果② Wikipedia_天気予報
(穴埋め問題)
日常生活や業務に対して天気が与える影響は非常に大きく、19世紀に近代気象学が生まれると同時
に科学的な天気予報の試みが行われてきた。現代における天気予報は、気象のメカニズムを解明する
気象学の発達と並んで、多種多様で世界的な気象観測網の構築、コンピューターの発展に支えられた
数値予報インフラの整備、そして情報を一般に広く伝えるマスメディアによって支えられ、運用され
ている。地球の大気の挙動は、カオスそのものであるため、初期値鋭敏性が高く、大気シミュレーシ
ョンの計算誤差が、反復計算により指数関数的に増大するため、長期間の予測は極めて難しい。しか
し、予測の初期値を得る大気計測やスーパーコンピュータによるモデルの高精度化により、継続的に
予報精度の改善は達成されている。数値予報が台頭してくるまで、天気予報は観測記録をもとにした
過去のノウハウや経験則の蓄積に頼る部分が大きく、「 3 」の経験に左右されるところが大きか
った。数値予報の登場によって解析業務の負担が軽減されるとともに、精度が向上して予報の幅も広
がってきている。また、観測の自動化・無人化も急速に進んでいる。気象観測・情報収集・研究に関
しては、「 1 」などの国際機関、世界各国の気象機関や防災担当の国家機関、研究機関や大学な
どによって連携して行われている。世界各国で法的な規定をもって責任機関を定め、気象に関する業
務を担当させている。国によっては予報業務の自由化も進められているが、国際的には、「 4 」
の「 1 」が、1995年の第12回世界気象会議議決事項40附属書3において、「関係する加
盟国が認めた場合を除き、商業セクターの気象業務提供者は、その活動する国及び海域において、生
命及び財産の安全に関わる予報及び警報を公表してはならない。商業セクターが公表する生命及び財
産の安全に関わる予報及び警報は、国家気象・水文気象機関等の公的機関が公共的な業務に係る責務
として実施するものと矛盾しないものでなければならない」との指針を示している。現代の天気予報
は、ゲリラ豪雨や激化する猛暑などに代表される気象災害の増加・変化やニーズの変化への対応、「
2 」やAO等の最新知見を取り入れた予報精度の向上などが大きなテーマとされている。そのた
め、そういった豪雨などの異常気象、「 2 」やAOなどの気候パターン、「 5 」などの気候
変動の解明が求められているほか、気象機関は市民に対して天気や気候変動に関する説明・解説を行
う一定の責任も負っている。
(答え)
1 : 世界気象機関
2 : ENSO
3 : 予報官
4 : 国連
5 : 地球温暖化
作成結果③ Wikipedia_自然言語処理
(穴埋め問題)
「 1 」は、「 3 」が日常的に使っている自然言語をコンピュータに処理させる一連の技術で
あり、人工知能と「 4 」の一分野である。「「 2 」」との類似もあるが、「 1 」は工学
的な視点からの言語処理をさすのに対して、「 2 」は「 4 」的視点を重視する手法をさす事
が多い。データベース内の情報を自然言語に変換したり、自然言語の文章をより形式的な表現に変換
するといった処理が含まれる。応用例としては予測変換、「 5 」などの文字変換が挙げられる。
自然言語の理解をコンピュータにさせることは、自然言語理解とされている。自然言語理解と、「
1 」の差は、意味を扱うか、扱わないかという説もあったが、最近は数理的な言語解析手法が広め
られた為、パーサなどが一段と精度や速度が上がり、その意味合いは違ってきている。もともと自然
言語の意味論的側面を全く無視して達成できることは非常に限られている。このため、「 1 」に
は形態素解析と構文解析、文脈解析、意味解析などをSyntaxなど表層的な観点から解析をする
学問であるが、自然言語理解は、意味をどのように理解するかという個々人の理解と推論部分が主な
研究の課題になってきており、両者の境界は意思や意図が含まれるかどうかになってきている。
(答え)
1 : 自然言語処理
2 : 計算言語学
3 : 人間
4 : 言語学
5 : IME
8. 全体を通しての振り返り
本記事では「ネットワーク分析による自然な穴埋め問題作成」を目標として、穴埋め問題作成までの手順説明から結果、自己評価までを行いました。本章では、穴埋め問題作成に取り組んだことで得られたこと、課題、今後の目標をまとめていきます。
【得られたこと】
- ネットワーク分析の知識(媒介中心性、固有ベクトル中心性など)
- 穴埋め問題を作成する場合、品詞の限定は重要な工程である
- ネットワーク分析より優れた手法がある
【課題】
- 複数の名詞が連なって意味を成している文字列の正確な抽出方法
- 媒介中心性以外の指標を使って作成した穴埋め問題の評価
- ネットワーク分析以外の手法を使って作成した穴埋め問題の評価
【今後の目標】
- 上記課題に取り組む
- 画像・動画から問題文を生成
- クイズ生成
9. 最後に
私の目標は「多種多様な問題文を自動で生成すること」です。
今回はそのための第一歩として穴埋め問題の作成に取り組んでみました。結果、ネットワーク分析を用いることで穴埋め問題の作成ができたことは良かったです。また、作成を通して自然言語処理技術の基本やネットワーク分析の知識も深めることができたのではないかと思っています。
現在、自然言語処理技術は注目を集めている技術であります。今後、さらに需要が増えていくことは間違いありません。そのため、自分も自然言語処理の世界に飛び込んで、日々学びを続けたいと思っています。そして、目標である「多種多様な問題文を自動で生成すること」に今後も挑戦していきたいと思います。
最後までお読みいただきありがとうございました。