はじめに
本記事はクラウドの利用費をJupyter Notebookで可視化する方法について記載しています。
Google Cloud Platform(以下、GCP)のコスト分析を行うために、Cloud Billingを用いて費用を確認していたところ、以下の課題がありました。
- レポート画面で期間を指定してコスト推移の分析はできるが、アウトプット機能が乏しい
- 料金明細画面で費用の詳細の表示及びCSVのダウンロードができるが、請求月の指定が1ヶ月単位になるため、期間の範囲を指定したコスト推移の分析がしにくい
GCPのCloud Billingは、AWSのCost Explorerに相当する機能ですが、AWSの場合は期間の範囲を指定してCSVのダウンロードが可能なため、使い勝手に困っていました。
ソリューションとして、料金明細画面から分析したい期間のCSVファイルのダウンロードを行い、Jupyter Notebookで分析します。
Jupyter Notebookで可視化する
本記事ではPythonの仮想環境上で動かしていますが、Jupyter Notebookは環境に応じて以下のような様々な手段があります。
クラウド環境については、Jupyter Notebookの民主化によって、以下に示す主要なパブリッククラウドサービス以外でも利用することができます。
- Local環境
- Pythonの仮想環境
- Docker
- Cloud環境
- Colaboratory
- AWS Deep Learning AMI/SageMaker
- Azure Machine Learning
ライブラリ
本記事で使用しているPythonのバージョンは、3.8.2です。
また使用しているライブラリは以下の通りです。
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
CSVファイルの読み込み
Jupyter NotebookからCSVファイルを格納したフォルダが認識されているか、シェルコマンドを実行して確認します。
シェルコマンドは、先頭に!を付与することで実行できます。
%を付けてマジックコマンドとして実行することもできます。
# ファイルチェック
! ls csv_sample
注意点として、シェルコマンドの出力はソートされて表示されるものの、os.listdirでオブジェクトを作成した場合は適切にソートされません。
このままだと、後述するpandasを用いてデータを取り出す際に影響が出るため、以下の例ではsorted関数を使用して名前順にソートしています。
csv_list = os.listdir('csv_sample')
csv_list = sorted(csv_list)
for _ in csv_list:
print(_)
分析データの抽出
分析するデータの準備ができたら、pandasを用いてデータを抽出するための関数を作成します。
以下の関数はCSVファイルのリスト、プロジェクト名、SKU IDを引数にして抽出した費用を返す場合のコードです。
SKU IDは、GCPのサービスに関するリソースを意味するSKUのIDです。
def calc_cost(csv_list, pj_name, skuid=None):
cost_list = []
for _ in csv_list:
csv_df = pd.read_csv(f'csv_sample/{_}')
csv_df = csv_df.rename(columns={'SKU ID':'SKUID'})
if skuid is None:
csv_df_r = csv_df.query('プロジェクト名 == @pj_name')
else:
csv_df_r = csv_df.query('プロジェクト名 == @pj_name & SKUID == @skuid')
cost = csv_df_r["費用(¥)"].sum()
cost_list.append(cost)
return cost_list
pandasのqueryメソッドを使用して変数を取得する場合は@を使用します。
またsum()メソッドを用いてレコードの集計を行うことができます。
アウトプット
上記で作成したcalc_cost関数を使用して、matplotlibで出力します。
使用するデータは便宜上、架空のデータです。
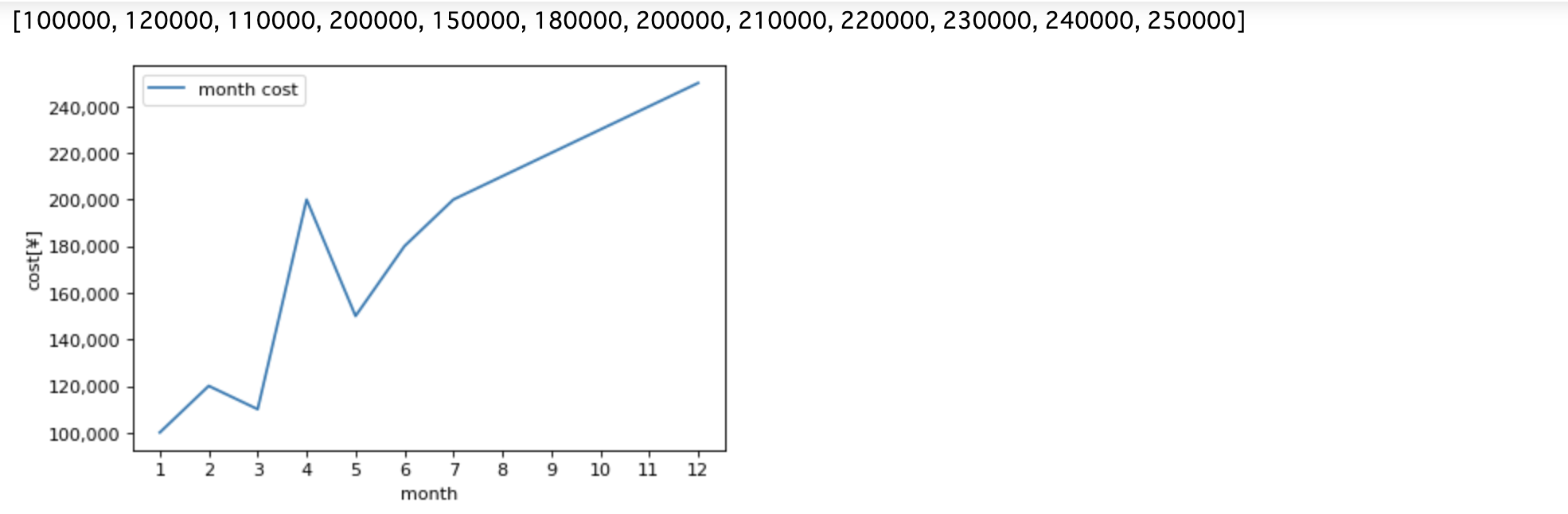
month = list(range(1,13))
cost_list = calc_cost(csv_list, 'pj-hpge')
print(cost_list)
fig, ax = plt.subplots(dpi=80)
ax.plot(month, cost_list, label='month cost')
# ラベル
ax.legend(loc='best')
ax.set_xlabel('month')
ax.set_ylabel('cost[¥]')
# y軸の数字を3桁区切りで出力
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
# x軸の目盛り調整
ax.set_xticks( np.arange(1, 13))
plt.show()
# 保存
fig.savefig('cost.png')
以下のようにグラフをエクスポートできます。
またエクスポートした画像の保存もできます。
matplotlibはグラフを描画するために各種関数を実行するMATLABスタイルと、描画オブジェクトに対してサブスロットを追加すしてグラフを描画するオブジェクト指向スタイルの2種類があります。
機械学習で回帰分析し、コストを予測する
説明変数が大きくなるにつれて、目的変数が大きくなる関係性について予測したい場合、線形回帰は一つのソリューションです。
例えば、何らかのログデータが対数的に増加する際、コストも増加するなど回帰直線を求めることができれば、それに基づいて予測を行うことができます。
クラウドの利用費のような1つの結果を予測するのに、相関関係がある単一の予測因子を用いるケースには最適ではないでしょうか。
ライブラリ
scikit-learnのLinearRegressionクラスを用いて試してみましょう。
from sklearn.linear_model import LinearRegression
分析データの抽出
説明変数となるリソースの使用量を取得する関数を新たに作成します。
GCPのCloud Billingで出力したCSVファイルは、データフレームに変換すると使用量のデータ型がObject型になっているので、to_numeric()メソッドを用いてを数値型に変換しています。
def calc_cost_use(csv_list, pj_name, skuid):
cost_list = []
for _ in csv_list:
csv_df = pd.read_csv(f'csv_sample/{_}')
csv_df = csv_df.rename(columns={'SKU ID':'SKUID'})
csv_df_r = csv_df.query('プロジェクト名 == @pj_name & SKUID == @skuid')
csv_df_r['使用量'] = csv_df_r['使用量'].str.replace(',', '')
csv_df_r.loc[:, 'amount'] = csv_df_r.loc[:, '使用量'].apply(pd.to_numeric)
cost = csv_df_r["amount"].sum()
cost_list.append(cost)
return cost_list
アウトプット
Xに説明変数のリスト(リソースの使用量を取得する関数の実行結果)、yに目的変数のリスト(費用を取得する関数の実行結果)を代入して、機械学習で予測します。
使用するデータは便宜上、架空のデータです。
以下は例として説明変数に、リソースの使用量としてCloud StorageのSKU IDを指定しています。
cost_list = calc_cost(csv_list, 'pj-hoge')
cost_list_use = calc_cost_use(csv_list, 'pj-hoge', '2D3D-C91F-7E7C')
X = [[i] for i in cost_list_use]
y = [[i] for i in cost_list]
model = LinearRegression()
model.fit(X, y)
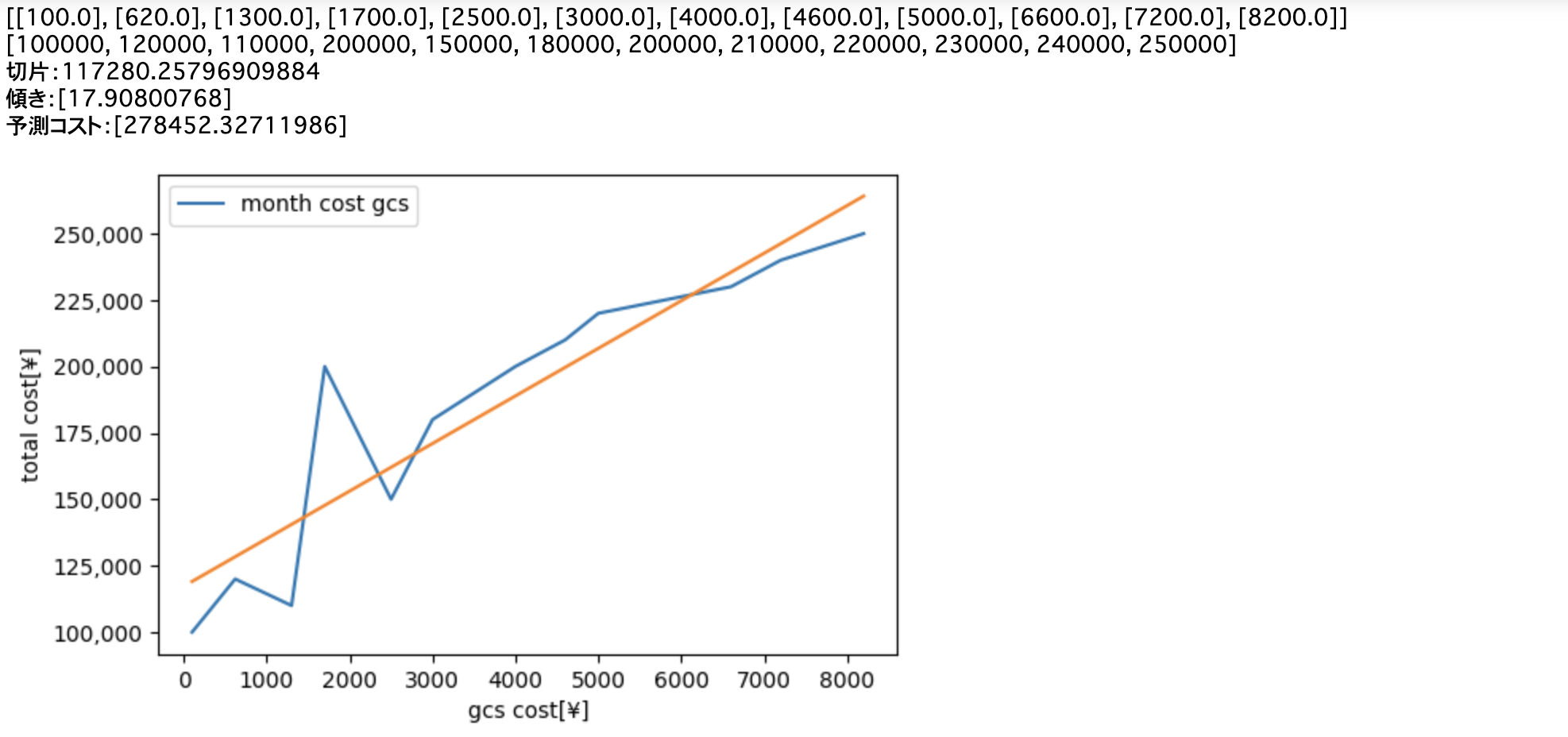
print(f'切片:{model.intercept_}')
print(f'傾き:{model.coef_}')
y_pred = model.predict([[9000]])
print(f'予測コスト:{y_pred}')
fig, ax = plt.subplots(dpi=100)
ax.plot(X, y, label='month cost gcs')
ax.plot(X, model.predict(X), linestyle="solid")
ax.legend(loc='best')
ax.set_xlabel('gcs cost[¥]')
ax.set_ylabel('total cost[¥]')
ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
plt.show()
以下のように回帰直線に従って、Cloud Storageに格納するデータが対数的に増加する場合のコストを予測することができました。
おわりに
Jupyter Notebookで可視化することで、そのままでは見えてこなかった新たな気づきを見つけることができました。
またデータサイエンスを応用することで、根拠のない経験則の見積りなど認知バイアスを取り除くことができます。
ChatGPTも実際の予測は行なってくれないので、データをどう使うかは人間の仕事ですね。