はじめに
Python Advent Calendar 2019 25日目![]() です。
です。
去年のPython Advent Calendar 2018 の同じ25日目に、Pythonで学ぶ統計学&おうちで作るデータ分析環境という記事を書きました。記事の中では転職ドラフトの第15回ドラフト参加ユーザーランキングより、提示年収最高額のデータを取得して簡単なデータ分析を行いました。
本記事では、第22回ドラフト参加ユーザーランキングのデータを使用し、エンジニア市場についてデータ分析を行った結果についてまとめています。
年の瀬を感じる今日この頃ですが、2020年に向けてエンジニア市場の今を見て見ましょう。
スクレイピング
去年書いたコードは最高額しか取得していなかったため、ユーザーランキングのデータから全てのデータをスクレイピングして取得する様に修正しました。
まずは以下のプログラムを実行し、データ分析に必要なデータを取得(※)します。
なお、本記事の環境はラズパイで動かしています。
(※)スクレイピングする際は対象サービスの利用規約を確認し、サービス側への負荷を配慮しましょう。
- draft_users.py
# ! /usr/bin/env python3
# -*- coding: utf-8 -*-
# スクレイピングに必要なモジュールをインポート
import csv
import sys
sys.path.append('/home/pi/.local/lib/python3.5/site-packages/')
import time
import traceback
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
# Headless Chromeを使うためのオプション
options = webdriver.chrome.options.Options()
options.add_argument('--headless')
# ドライバー設定
browser = webdriver.Chrome(executable_path="/usr/lib/chromium-browser/chromedriver", chrome_options=options)
# ログイン情報
USER = “user”
PASS = “pass”
# ログイン画面を表示
url_login = "https://job-draft.jp/sign_in"
browser.get(url_login)
time.sleep(1)
print("ログインページにアクセスしました")
# フォームにメールアドレスとパスワードを入力
e = browser.find_element_by_id("user_email")
e.clear()
e.find_element_by_id("user_email").send_keys(USER)
e = browser.find_element_by_id("user_password")
e.clear()
e.find_element_by_id("user_password").send_keys(PASS)
time.sleep(1)
# フォームを送信
e.find_element_by_xpath("//*[@id=\"new_user\"]/div[4]").click()
print("ログインしました")
# 関数
list = []
dict = {}
page = ""
last = 50
def get_user_data():
url = "https://job-draft.jp/festivals/22/users?page="
url = url+str(page)
browser.get(url)
count = 12
if page == 49:
count = 8
num = 2
while num < count:
try:
user = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-3 > div:nth-child(2) > a > span")
age = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-3 > div:nth-child(3) > span")
name = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-9 > div.row > div.col-xs-4.col-sm-3.col-md-3.col-lg-3 > span.f-w-bold.u-font-ml")
max_amount = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-9 > div.row > div:nth-child(2) > span.f-w-bold.u-font-ml")
cum_avg = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-9 > div.row > div:nth-child(3) > span.f-w-bold.u-font-ml")
ambition = browser.find_elements_by_css_selector("#page-wrapper > div.wrapper-content > div > div > div.col-xs-12.col-sm-12.col-md-8.col-lg-8 > div.ibox > div > div > div:nth-child("+(str(num))+") > div > div.col-xs-9 > div.u-m-t-5 > div:nth-child(1) > span.f-w-bold.u-font-mm")
except NoSuchElementException:
print("要素がありませんでした")
sys.exit(1)
for user, age, name, max_amount, cum_avg, ambition in zip(user, age, name, max_amount, cum_avg, ambition):
user = user.text
age = age.text
name = name.text
max_amount = max_amount.text
max_amount = max_amount.replace('万円', '')
cum_avg = cum_avg.text
cum_avg = cum_avg.replace('万円', '')
ambition = ambition.text
print(user)
print(age)
print(name)
print(max_amount)
print(cum_avg)
print(ambition)
dict = {"user": user, "age": age, "name": name, "max_amount": max_amount, "cum_avg": cum_avg, "ambition": ambition }
list.append(dict)
with open('./user_ranking.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow(dict.values())
num += 1
def main():
print("データスクレイピングを開始します")
global page
global last
try:
if not page:
get_user_data()
page = 2
time.sleep(3)
# 最後のページまでループ
while page < last:
get_user_data()
page += 1
time.sleep(3)
except Exception as e:
traceback.print_exc()
sys.exit(99)
# ドライバを終了し、関連するすべてのウィンドウを閉じる
browser.quit()
print("データスクレイピングが正常終了しました")
# 処理
if __name__ == '__main__':
main()
前処理
上記プログラムを実行して取得したCSVファイルをJupyter Notebookから読み込みます。
pandasで引数を設定しない場合は、1行目がheaderとして認識されます。
取得したデータはheaderが存在しません。header=Noneを指定すれば、自動的に数字でheaderを付けてくれますが、分かりやすいようにheaderを指定します。
import numpy as np
import pandas as pd
# csvファイルの読み込み
df = pd.read_csv("/tmp/user_ranking.csv", names=("年齢", "最高額", "ユーザー名", "指名数", "野望", "累計平均"))
データフレームの先頭部分を確認し、読み込まれたことを確認します。
df.head()
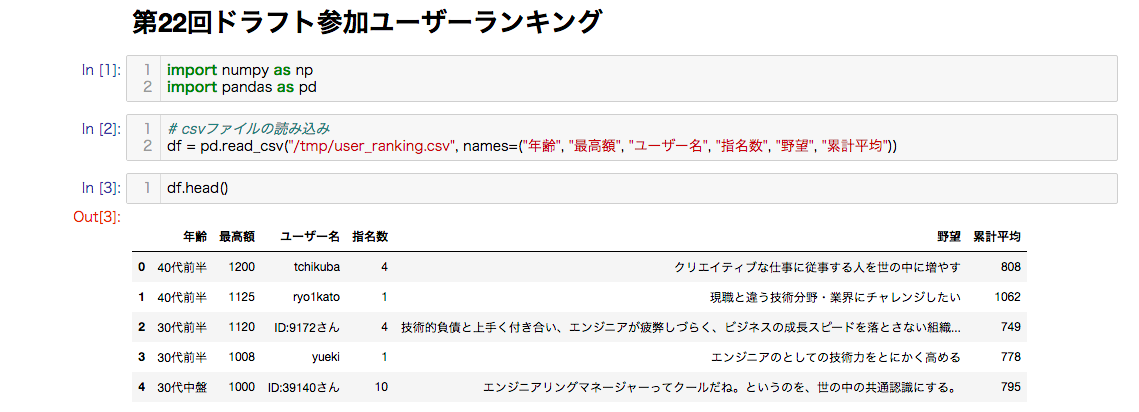
スクレイピングしたデータはdictで保存しているため、キーの並びがずれています。少し見づらいのでWebサイトと同じ並びにするために、キーの並び変えを行います。
# 並び替え
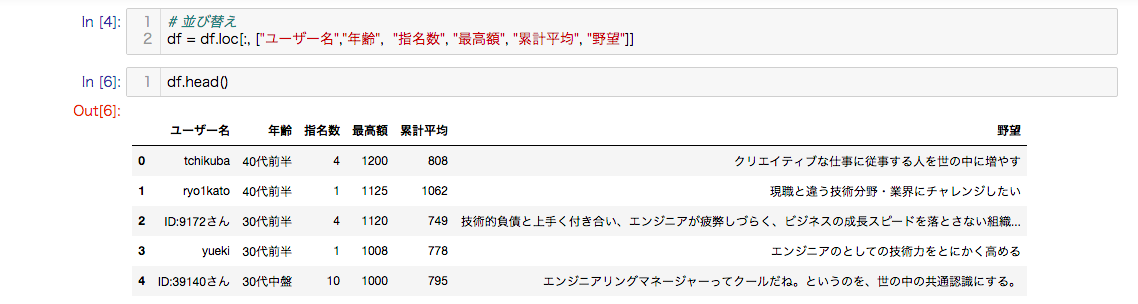
df = df.loc[:, ["ユーザー名","年齢", "指名数", "最高額", "累計平均", "野望"]]
並び変えが行われて見やすくなりました。これで準備OKです。
データ分析
統計学の基本的な考え方は以下になります。
- すべての統計的現象は、確率分布をする。
- 全ての統計的現象は、母集団を観察する代わりに標本を観察して、それをもとに母集団の特性を推測して分析する。
統計量
第22回ドラフトは、486人参加。その内、320人が指名され、166人が指名なしです。
去年の記事にも書きましたが、「指名なし」を含むか含まないかで大分平均値が変わってきます。
入札結果に記載されている平均提示年収は、「指名なし」を除く人で算出していると思われため、今回も「指名なし」を除いたデータを基に分析していきます。
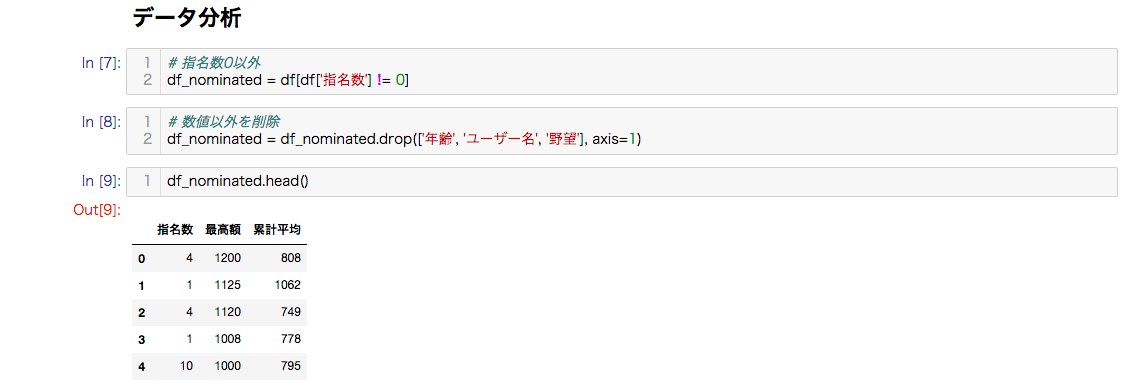
統計量を求めるため、データフレームから数値以外のカラムを削除します。
# 指名数0以外
df_nominated = df[df['指名数'] != 0]
# 数値以外を削除
df_nominated = df_nominated.drop(['年齢', 'ユーザー名', '野望'], axis=1)
数値のみであることを確認します。
df_nominated.head()
次にデータ型を確認します。
最高額と累計平均がobjectであるのが確認できます。
# データ型を確認
df_nominated.dtypes

このままでは統計量が確認できないため、int型に変更します。
指名数のデータ型と合わせてint64型に変更します。
# データ型変換
df_nominated.loc[:, "最高額"] = df_nominated.loc[:, "最高額"].astype(np.int64)
df_nominated.loc[:, "累計平均"] = df_nominated.loc[:, "累計平均"].astype(np.int64)

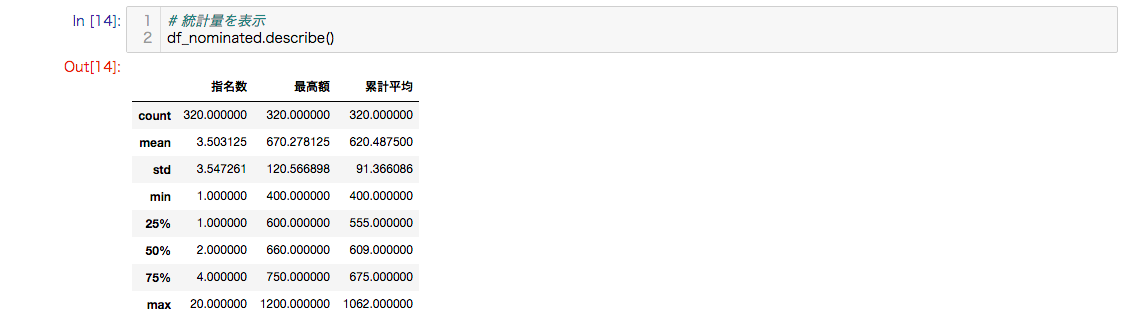
データ型がint64にそろったので統計量を確認します。
最高額の平均は670万円、標準偏差は120万円です。
おおよそ、550万円から790万円で市場が動いています。
# 統計量を表示
df_nominated.describe()
次に相関係数を確認してみましょう。
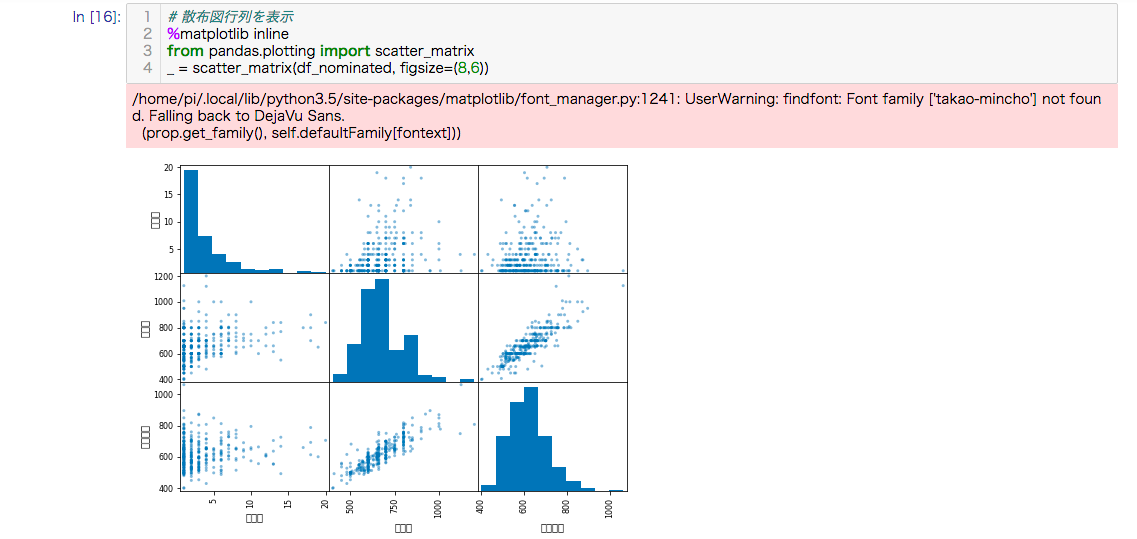
見ての通りですが最高額と累計平均は強い正の相関があります。
# 相関係数を表示
df_nominated.corr()

カラムごとのデータの関係を散布図行列で確認します。
グラフの大きさはfigsizeで変更できます。単位はインチです。
# 散布図行列を表示
%matplotlib inline
from pandas.plotting import scatter_matrix
_ = scatter_matrix(df_nominated, figsize=(8,6))
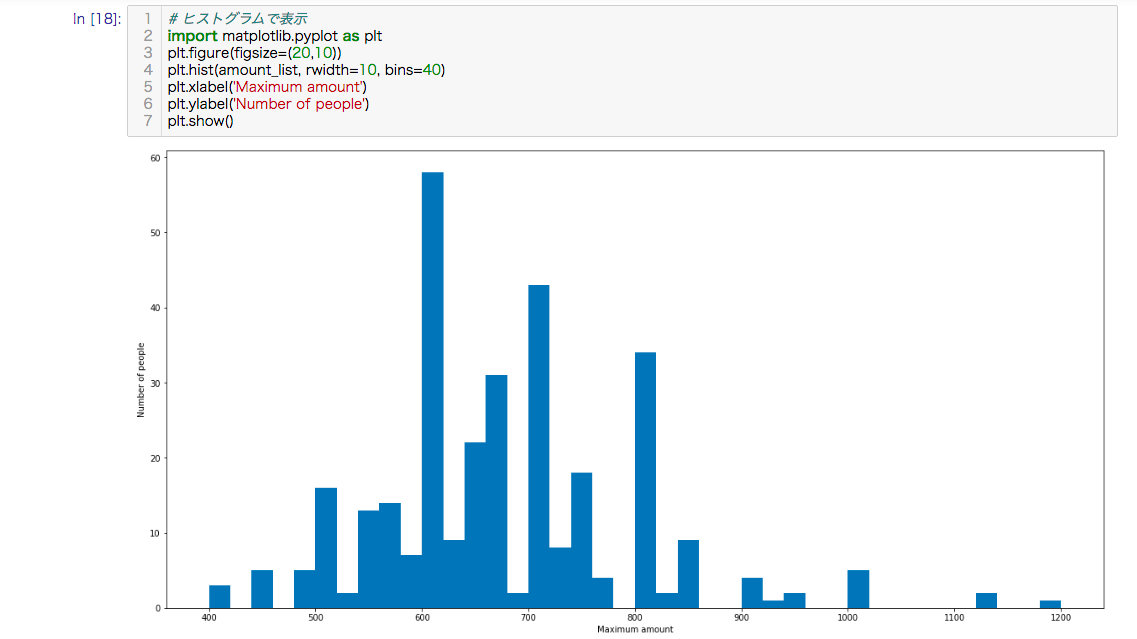
ヒストグラム
ヒストグラムで最高額について、大小を比較してみます。
データフレームから最高額を抽出します。
# 昇順に並び変え
df_aomount = df_nominated.sort_values(by="最高額")
# データフレームから最高額を抽出してリストに追加
amount_list = []
for a in df_aomount["最高額"]:
amount_list.append(a)

600万円台が多いのがわかります。
# ヒストグラムで表示
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
plt.hist(amount_list, rwidth=10, bins=40)
plt.xlabel('Maximum amount')
plt.ylabel('Number of people')
plt.show()
ヒストグラム(複数)
各年代ごとに分けてヒストグラムで確認します。
また、データフレームからデータを用意します。
import re
# 昇順に並び変え
df_age = df.sort_values(by="最高額")
df_age = df_age[df_age['指名数'] != 0]
s10_list = []
s20_list = []
s30_list = []
s40_list = []
s50_list = []
s60_list = []
# データフレームから年齢ごとに抽出してリストに追加
for age, amount in zip(df_age["年齢"], df_age["最高額"]):
if type(amount) is str:
amount = np.int64(amount)
if re.match('10代', age):
s10_list.append(amount)
elif re.match('20代', age):
s20_list.append(amount)
elif re.match('30代', age):
s30_list.append(amount)
elif re.match('40代', age):
s40_list.append(amount)
elif re.match('50代', age):
s50_list.append(amount)
elif re.match('60代', age):
s60_list.append(amount)
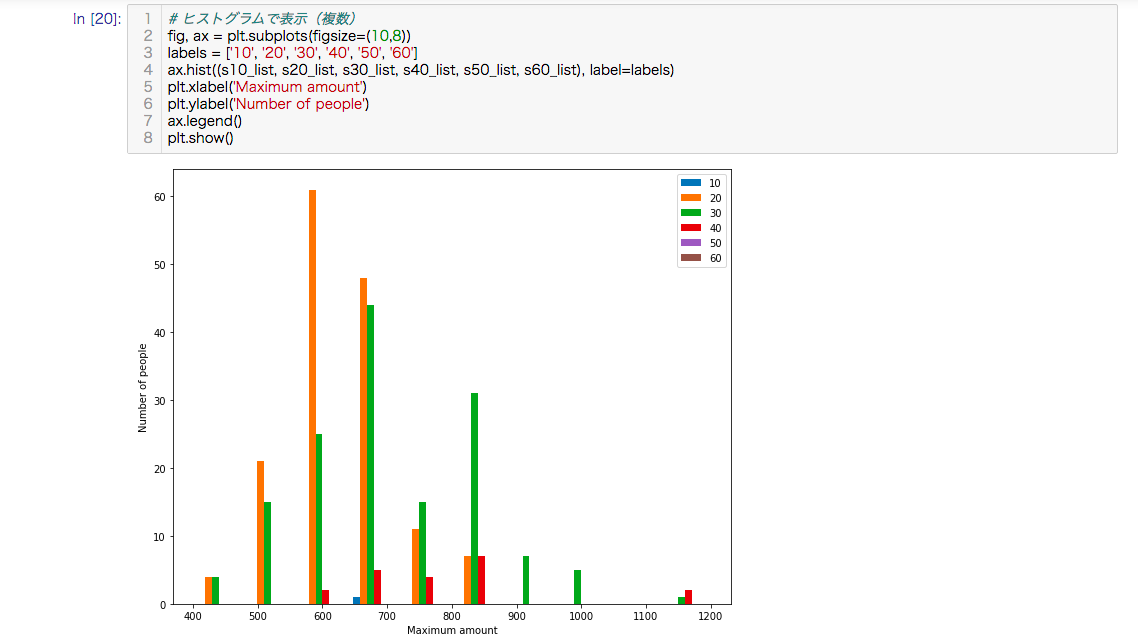
ヒストグラムで表示します。
# ヒストグラムで表示(複数)
fig, ax = plt.subplots(figsize=(10,8))
labels = ['10', '20', '30', '40', '50', '60']
ax.hist((s10_list, s20_list, s30_list, s40_list, s50_list, s60_list), label=labels)
plt.xlabel('Maximum amount')
plt.ylabel('Number of people')
ax.legend()
plt.show()
元々の標本数も少ないですが、50代、60代は指名がありません、想定の範囲ですが市場を多くしめるのは20代と30代ということが分かります。
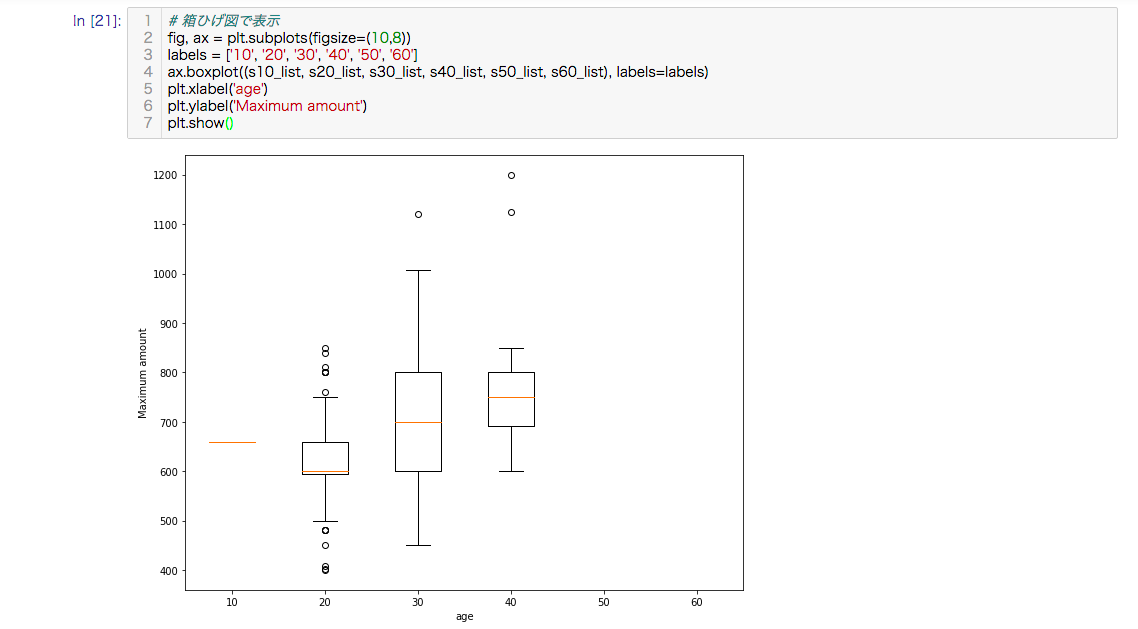
箱ひげ図
箱ひげ図を確認します。
はずれ値をみつけたいときに箱ひげ図は最適です。
# 箱ひげ図で表示
fig, ax = plt.subplots(figsize=(10,8))
labels = ['10', '20', '30', '40', '50', '60']
ax.boxplot((s10_list, s20_list, s30_list, s40_list, s50_list, s60_list), labels=labels)
plt.xlabel('age')
plt.ylabel('Maximum amount')
plt.show()
1000万円クラスははずれ値として検出されているのが分かります。
興味深いのは30代の年収のでしょうか。
各年代で範囲の差が一番大きいです。
30代で年収の差が開いてくるというのがデータが物語っています。
また、40代の最低ラインも600万円というのが分かります。
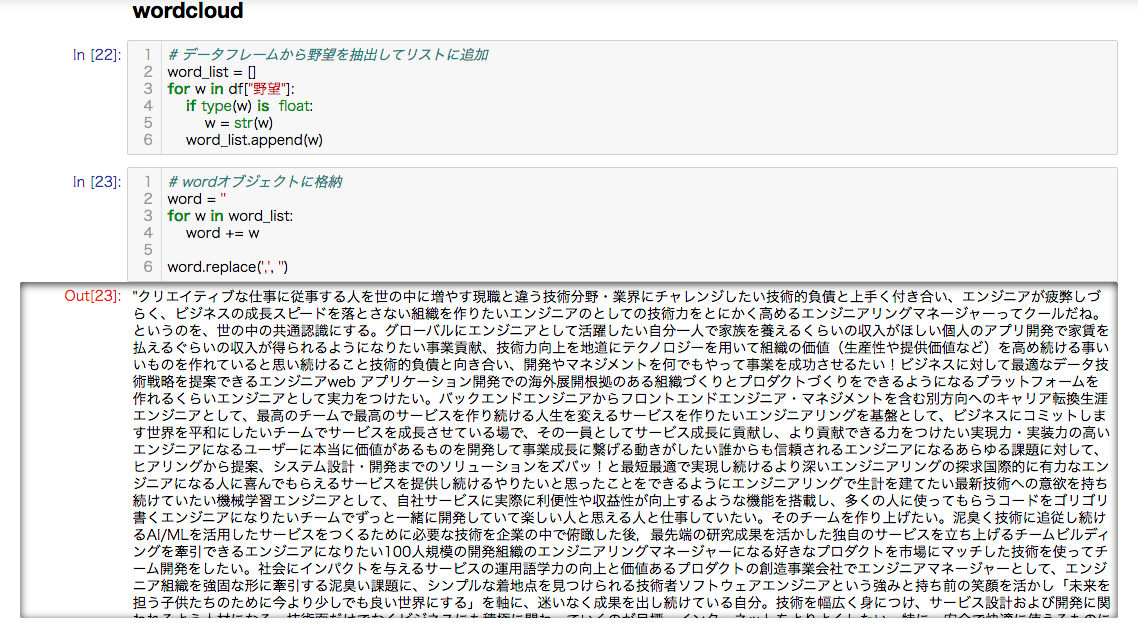
wordcloud
スクレイピングしたデータの中の野望を抽出し、ワードクラウドで表示させ可視化します。
ワードクラウドを使用するために、以下のコマンドを実行して環境を構築(※)します。本記事では、日本語フォントにfonts-takao-minchoを使用しています。
(※)本記事の環境はラズパイ
$ pip3 install wordcloud
$ sudo apt-get install fonts-takao-mincho
データフレームから野望を抽出してリストに追加します。
# データフレームから野望を抽出してリストに追加
word_list = []
for w in df["野望"]:
if type(w) is float:
w = str(w)
word_list.append(w)
リストの要素をwordオブジェクトにまとめます。
# wordオブジェクトに格納
word = ''
for w in word_list:
word += w
word.replace(',', '')
ワードクラウドを作成します。このとき、日本語表示させる場合は、フォントのパスを指定します。
from wordcloud import STOPWORDS, WordCloud
# ワードクラウド作成
wordcloud = WordCloud(width=1200, height=900, background_color='white', colormap='winter', font_path='/usr/share/fonts/truetype/fonts-japanese-mincho.ttf')
wordcloud.generate(word)
wordcloud.to_file('wordcloud.png')

作成したワードクラウドを表示します。
# 画像の表示
from IPython.display import Image
Image("./wordcloud.png")

エンジニア市場をデータ分析して見えたもの
それは、知識を習得しエンジニアになるといういつの時代も変わらない本質的かつ普遍的なものでした。
データ分析2
上記プログラムを少し改良し、取得した他のデータについても分析します。
累計参加企業一覧
累計参加企業一覧のデータをランキングにして、どの様な企業が人気があるのか調査します。同じ手順でデータフレームを用意します。
以下は、指名を降順でソートして上位10まで表示します。
指名数が多い順なので、採用活動に力を入れている企業ということが分かります。
# csvファイルの読み込み
df_com = pd.read_csv("/tmp/companies_list.csv", names=("企業名", "シンシ度", "指名", "ラブコール数", "承諾(承諾率)"))
# 指名を降順でソートして上位10まで表示
df_com.sort_values(by="指名", ascending=False).head(10)
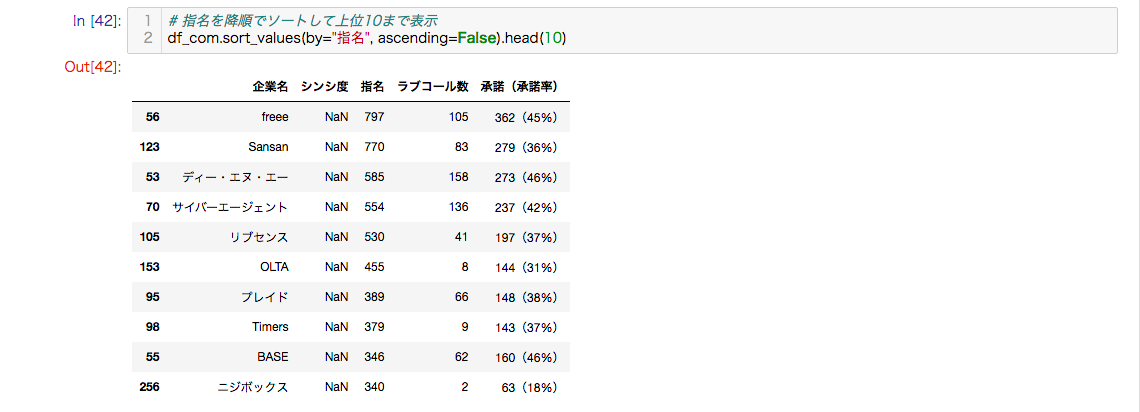
(※)シンシ度がNaNになっているのは、データの属性がhidden-xs.hidden-smであるため、本プログラムが何らかのデバイスと認識され表示され取得できなかったためです。
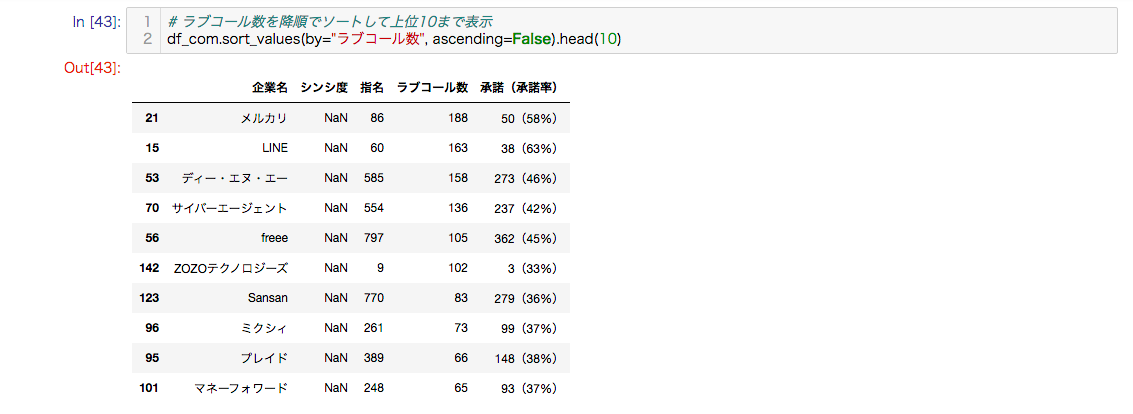
以下は、ラブコールを降順でソートして上位10まで表示します。
ラブコールが多い順なので、人気がある企業ということが分かります。
# ラブコール数を降順でソートして上位10まで表示
df_com.sort_values(by="ラブコール数", ascending=False).head(10)
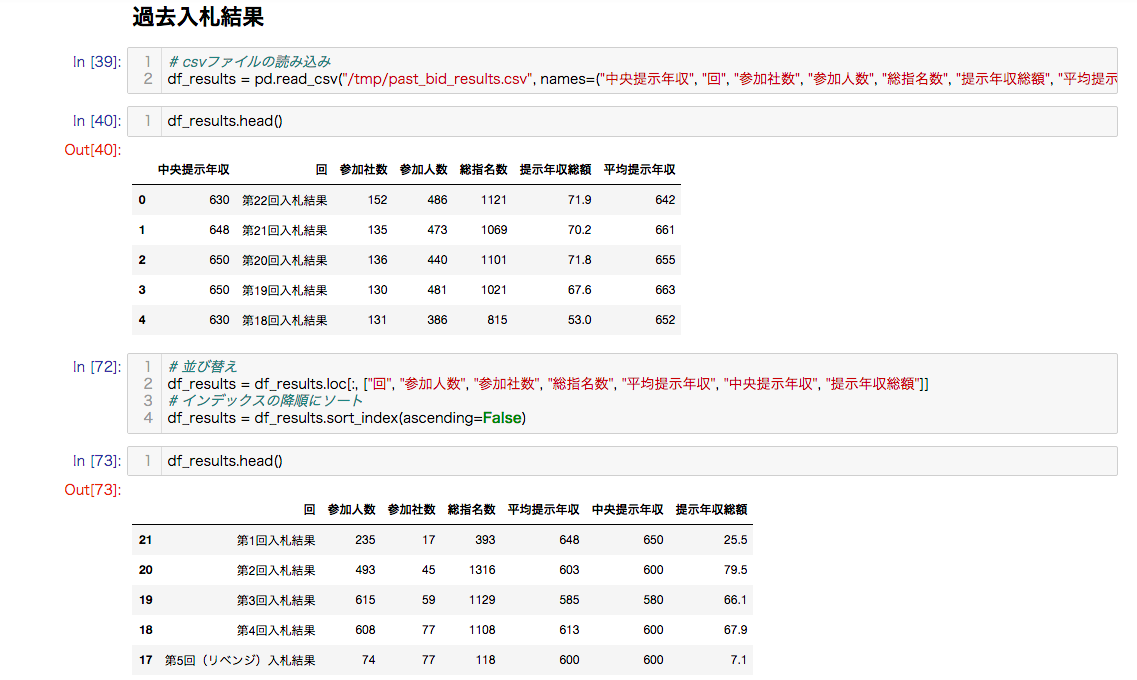
過去入札結果(参加人数/参加社数/総指名数)
過去入札結果について調査します。
スクレイピングしたデータは第22回のデータが先頭にきているため、インデックスの降順にソートします。
# csvファイルの読み込み
df_results = pd.read_csv("/tmp/past_bid_results.csv", names=("中央提示年収", "回", "参加社数", "参加人数", "総指名数", "提示年収総額", "平均提示年収"))
# 並び替え
df_results = df_results.loc[:, ["回", "参加人数", "参加社数", "総指名数", "平均提示年収", "中央提示年収", "提示年収総額"]]
# インデックスの降順にソート
df_results = df_results.sort_index(ascending=False)
過去入札結果の参加人数、参加社数、総指名数について、時系列で確認します。
x = ['1', '2', '3', '4', '5', '6' , '7' , '8' , '9' , '10' , '11' , '12' , '13' , '14' , '15' , '16' , '17' , '18' , '19' , '20' , '21' , '22']
y = []
y2 = []
y3 = []
for i in df_results["参加人数"]:
y.append(i)
for i in df_results["参加社数"]:
y2.append(i)
for i in df_results["総指名数"]:
y3.append(i)
fig, ax = plt.subplots()
ax.plot(x, y, label='Number of participants')
ax.plot(x, y2, label='Number of participating companies')
ax.plot(x, y3, label='Total nominations')
ax.legend(loc='best')
plt.xlabel('time')
plt.ylabel('number')
plt.show()
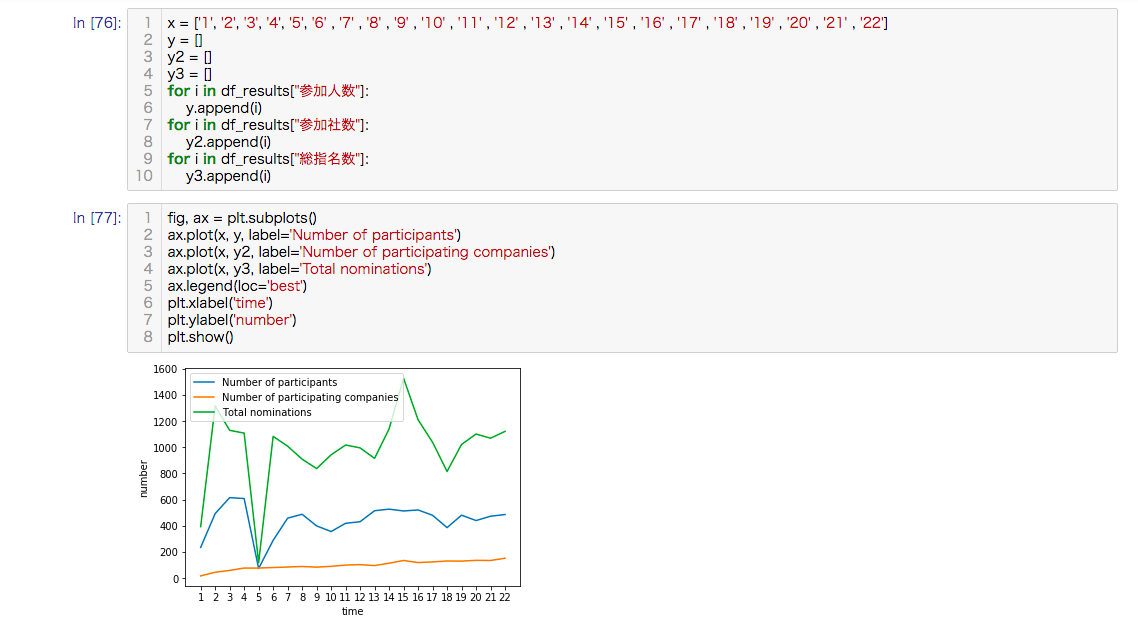
参加人数はおおむね横ばいで推移し、参加社数は少しずつ上昇しています。
総指名数については、去年と同じ時期に開催された第15回との変化率(※)で計算すると-36%下降しています。
変化率 = \frac{(基準時点-各時点の基準時点)}{基準時点} × 100
過去入札結果(平均提示年収/中央提示年収)
過去入札結果の平均提示年収と中央提示年収について、時系列で確認します。
x = ['1', '2', '3', '4', '5', '6' , '7' , '8' , '9' , '10' , '11' , '12' , '13' , '14' , '15' , '16' , '17' , '18' , '19' , '20' , '21' , '22']
y = []
y2 = []
for i in df_results["平均提示年収"]:
y.append(i)
for i in df_results["中央提示年収"]:
y2.append(i)
fig, ax = plt.subplots()
ax.plot(x, y, label='Average presented annual income')
ax.plot(x, y2, label='Centrally presented annual income')
ax.legend(loc='best')
plt.xlabel('time')
plt.ylabel('Amount of money')
plt.show()
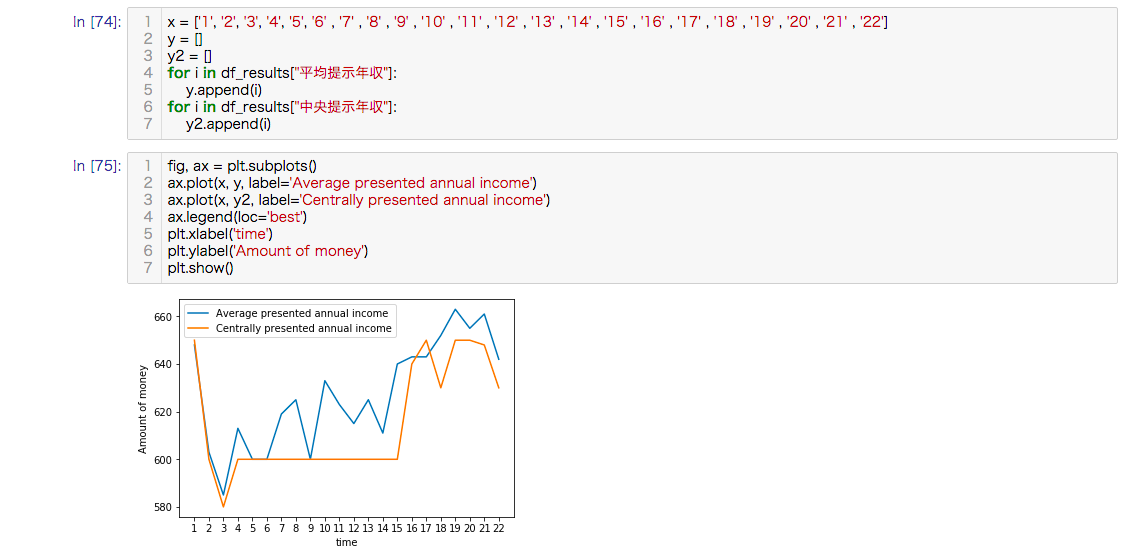
第3回から第19回までの平均提示年収及び中央提示年収は上昇傾向でしたが、第20回から今年最後に行われた第22回にかけて、下降気味になっているのが見受けられます。
エンジニア市場調査結果の要約
前提として参加企業を見るかぎり、SIer系は存在しない。ほとんどが事業会社で内訳的には、大企業、Web系のメガベンチャー、スタートアップに大別できる。また、ほとんどの企業の本拠地は東京を中心とした企業が多い。
よって、標本データから推測できるのは、事業会社のエンジニア市場価値と考える。
以上、前提を踏まえた上で調査結果に対する要約である。
- 事業会社を目指す関東のエンジニアは、600万クラスのエンジニアが多い。
- 年代的には20代と30代が活発。20代が特に多く、30代が一番範囲の差が大きい。40代は最低ラインが600万円。50代と60代については標本自体が少ない。
- 採用が活発な企業は採用に力を入れていると思われるが、人の流動性も高い考える。(勤続年数が短く離職率が高い)
- 人気がある企業はしっかりとしたプロダクトを持ち、世の中に価値を提供している企業が多い。
- 平均提示年収及び中央提示年収は、ここ数年では上昇傾向と思われる。
参考
IT人材白書2019で示す2018年度調査結果に基づく、国内IT人材の総数の合計は1,226,000となっている。その内、IT 企業 IT人材(IT 提供側)は938,000で、ユーザー企業 IT人材(IT 利用側)288,000である。
出典:IT人材白書2019 図表1-2-8 IT人材の総数推計
総務省の調査資料である労働力調査年報の「平成30年 労働力調査年報」を見ると、男性の正規の職員・従業員は2018年平均で500~699万円が22.8%(前年に比べ0.1ポイントの上昇)と最も高く、次いで300~399万円が19.8%(前年と同率)なっている。なお、男女計の場合は300~399万円が最も高い。
出典:統計表 II 詳細集計 「II-A-第3表」-「仕事からの収入(年間),雇用形態別雇用者数」
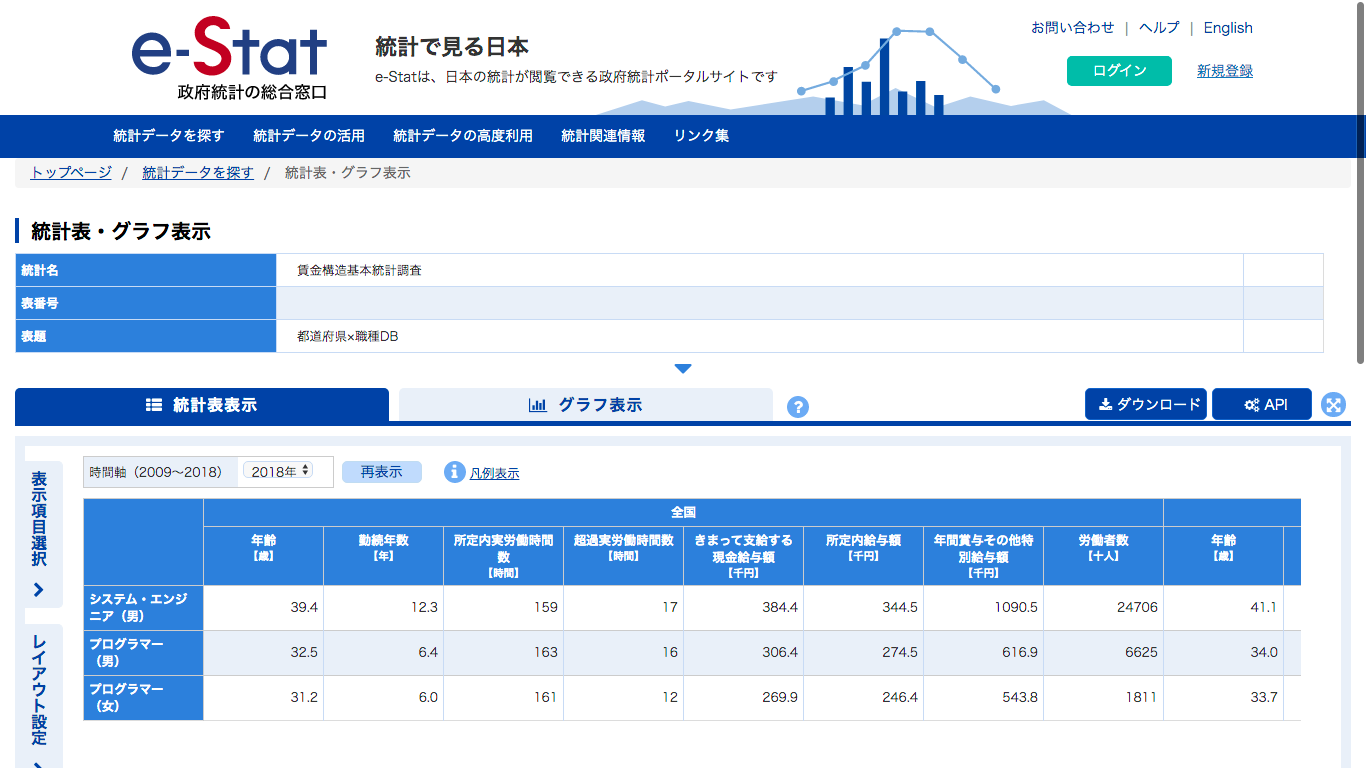
日本の統計が閲覧できる政府統計ポータルサイトのe-Statより、システム・エンジニアとプログラマーの賃金に関する統計情報について以下に示す。
おわりに
転職ドラフトで観測されるデータは、国内IT人材の総数の合計約120万人の内のほんの一部ということが分かります。
IT人材という言葉は広義で使われるため、システムエンジニアやプログラマーをはじめ、コンサルなども含まれています。ほとんどは情報通信業の情報サービス業や、インターネット付随サービス業に大別できますが、自動車製造などの自動車に搭載される組み込みを行うエンジニアは自動車製造業に分類されるため、業界全体での実態を推定するのは難しいことが分かりました。
総務省の労働力調査年報を見ると、男性の正規の職員・従業員の内、500〜699の階級が多いことや、e-statの賃金に関係する統計データを踏まえて、転職ドラフトで観測される600万円の市場価値は業界全体で見たら月並みかもしれません。
自分のスキル(得意なこと)が社会や会社の求めるものと一致したときに、お金はあとからついてくると思います。エッジを効かせていきましょう。