Introduction
Amazon Rekognition is a cloud-based software as a service (SaaS) computer vision platform that was launched in 2016.
It used deep learning to identify objects, scenes, persons, emotions in images or in video.
To compare to my previous experience with Firebase MLKit, it offers similar services like :
- Text in Image
- Facial analysis
- Label Detection
But as Firebase MLKit is more specialized in text identification and language, Amazon Rekognition offers a better variety of image recognition.
- Image moderation
- Celebrity recognition
- Face comparison
- PPE(Personal Protective Equipment) detection
But the best point is about
- Video analysis
Let's study each point.
Text in Image
Text Detection is about identifying text in a photo.
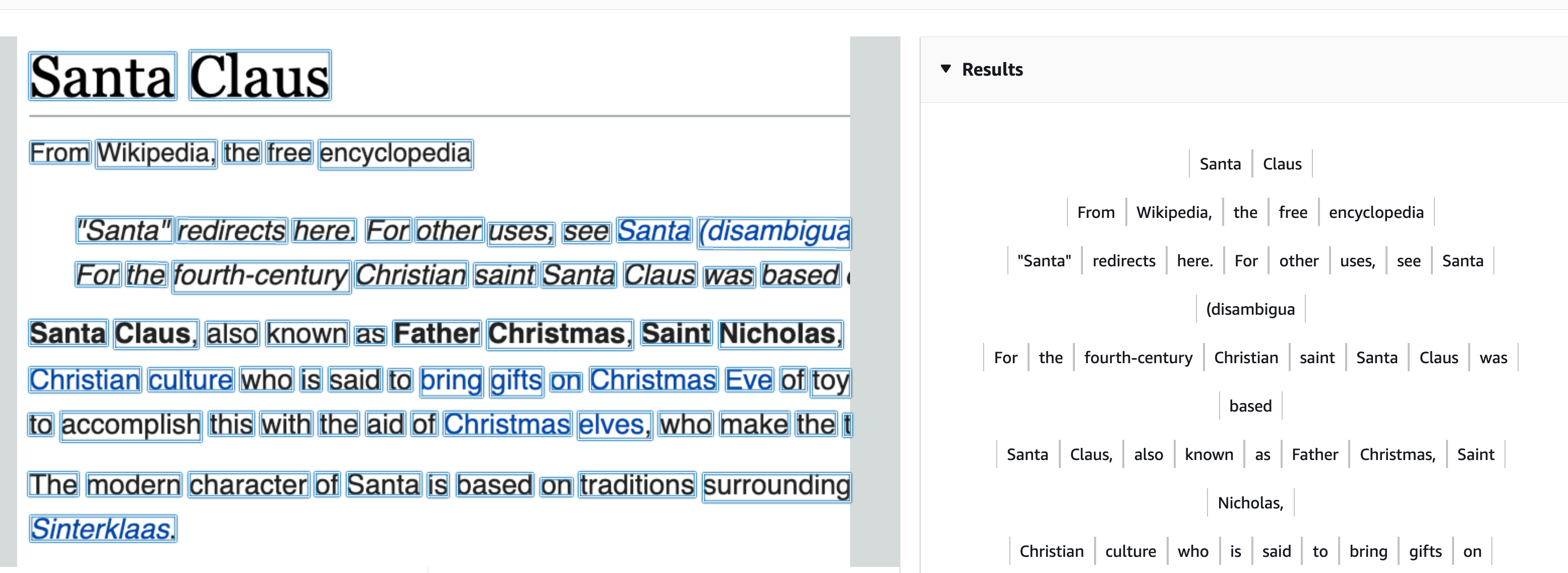
So first we create an Image object based on a local image. (We can also use an image stored in s3 bucket)
Next we just call the detectText service.
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
DetectTextRequest textRequest = DetectTextRequest.builder()
.image(souImage)
.build();
DetectTextResponse textResponse = rekClient.detectText(textRequest);
List<TextDetection> textCollection = textResponse.textDetections();
textCollection will contain a lot of information like detectedText, confidence score, type (LINE or WORD) and geometry (that contains the bounding box and the polygons points ~ text can be rotated)
Facial analysis
Face Detection is about describing face in a photo.
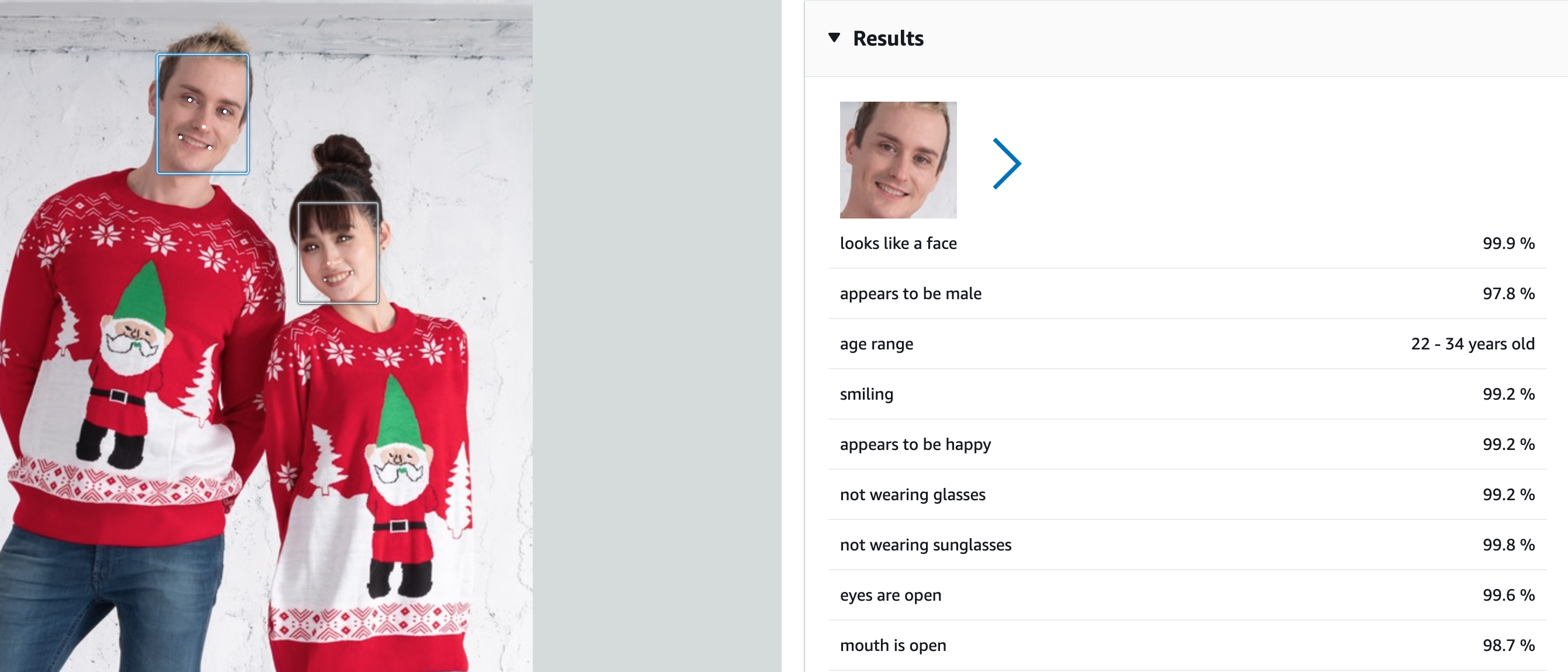
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
DetectFacesRequest facesRequest = DetectFacesRequest.builder()
.attributes(Attribute.ALL)
.image(souImage)
.build();
DetectFacesResponse facesResponse = rekClient.detectFaces(facesRequest);
List<FaceDetail> faceDetails = facesResponse.faceDetails();
faceDetails will contain a lot of information for each face detected, like boundingBox, ageRange, confidence score, emotions, and Physical description (mustache, gender, sunglasses, smile, beard... )
Label Detection
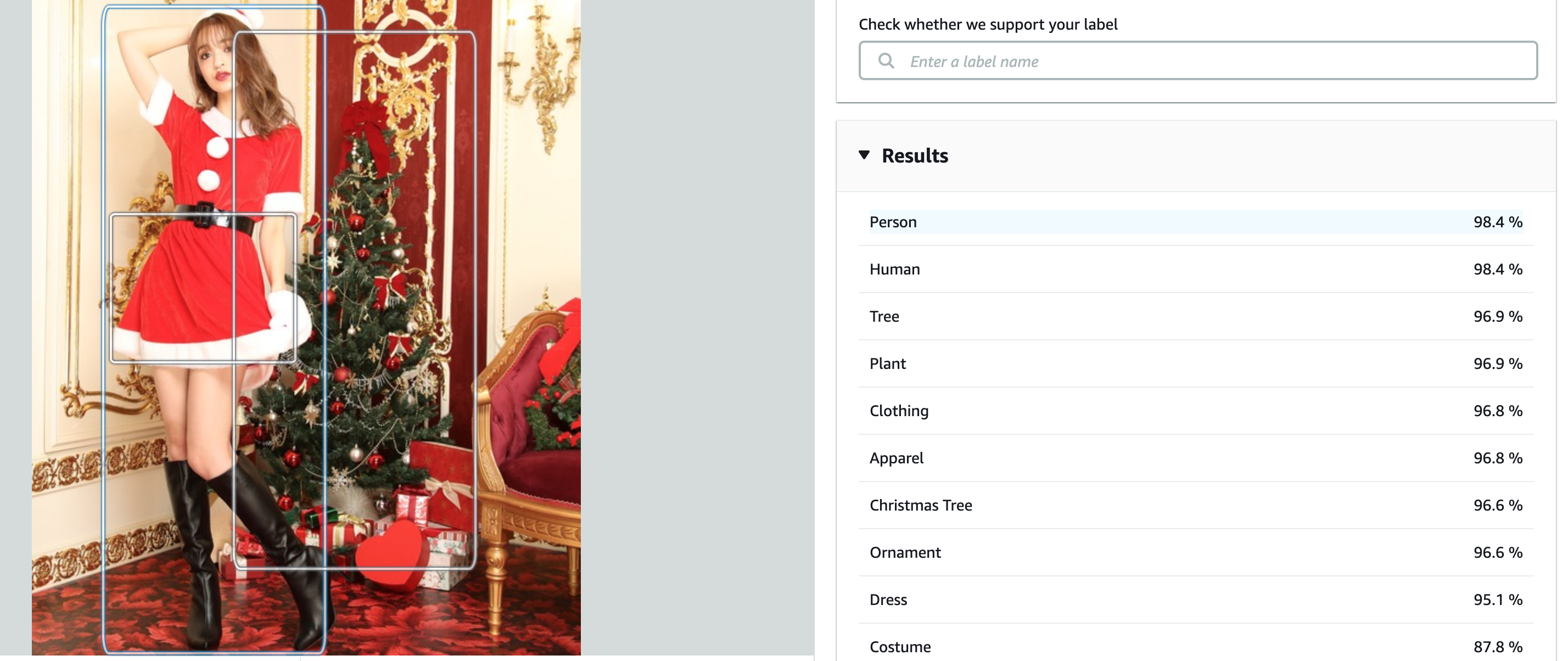
Label detection is about describing what is displayed in the photo.
It maybe useful to add some metadata to a photo, or describe it for blind people.
Still Firebase MLKit looks more efficient.
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
DetectLabelsRequest detectLabelsRequest = DetectLabelsRequest.builder()
.image(souImage)
.maxLabels(10)
.build();
DetectLabelsResponse labelsResponse = rekClient.detectLabels(detectLabelsRequest);
List<Label> labels = labelsResponse.labels();
Label contains just a label and confidence and optionally a bounding box.

Image moderation
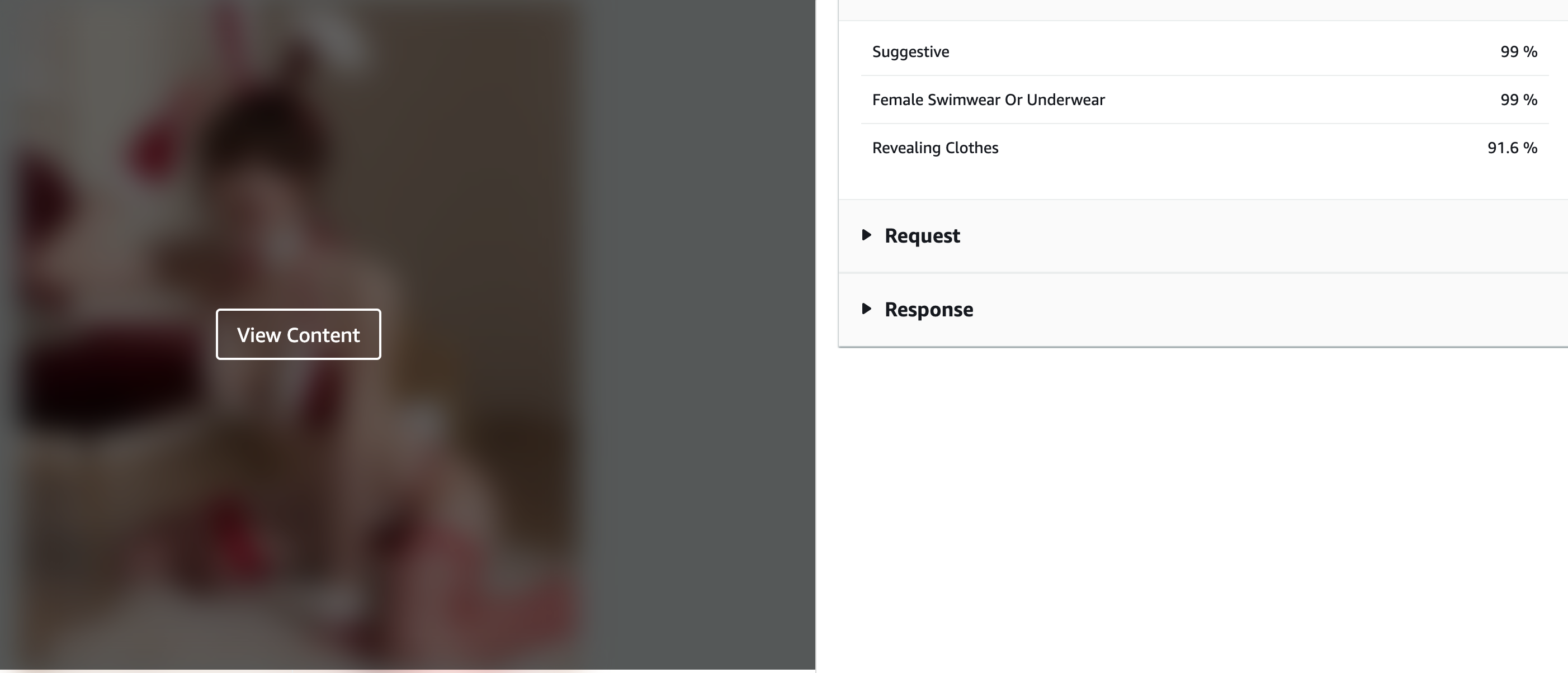
Image moderation service check an image based on a dictionary of word related to "unsafe content" (inappropriate, unwanted, or offensive content).
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
DetectModerationLabelsRequest moderationLabelsRequest = DetectModerationLabelsRequest.builder()
.image(souImage)
.minConfidence(60F)
.build();
DetectModerationLabelsResponse moderationLabelsResponse = rekClient.detectModerationLabels(moderationLabelsRequest);
List<ModerationLabel> labels = moderationLabelsResponse.moderationLabels();
The list contains all the label where the confidence is over 60% (as mentioned in api parameter)
ModerationLabel contains a label that enter in the category of "unsafe content" and a confidence score.

Celebrity recognition
Celebrity recognition is a service to retrieve celebrities in an image.

Well... Not working so well ... Zozo new president is not included as "celebrity" !
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
RecognizeCelebritiesRequest request = RecognizeCelebritiesRequest.builder()
.image(souImage)
.build();
RecognizeCelebritiesResponse result = rekClient.recognizeCelebrities(request) ;
List<Celebrity> celebs=result.celebrityFaces();
List<ComparedFace> unrecognizedFaces=result.unrecognizedFaces();
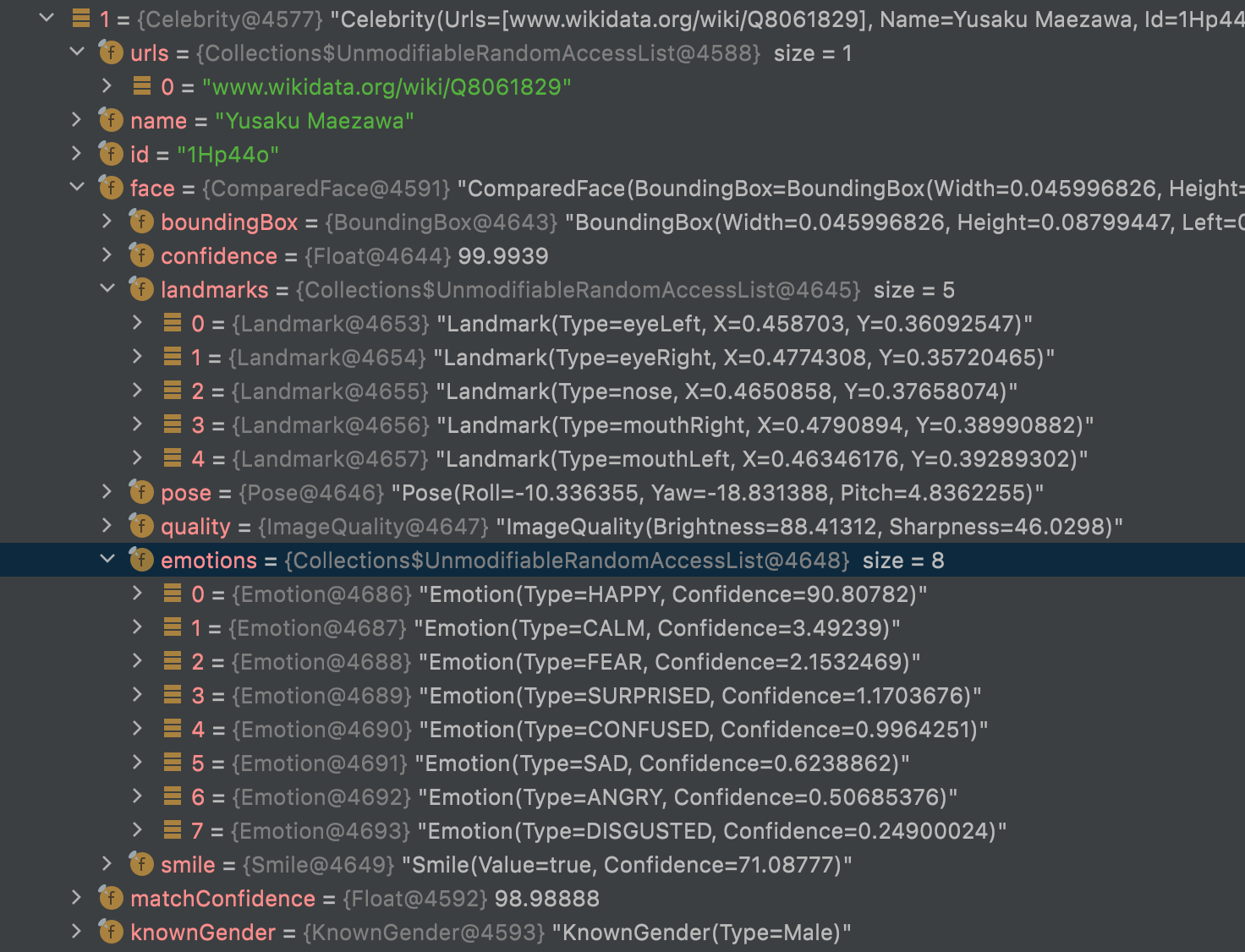
celebs contains only the recognized face on the current image.
It describes the name, the knownGender, a link for further explanation, the boundingBox for face, the landmarks (To describe the position of face elements) but also some information about emotions (Happy, angry, sad...) with a confidence score.
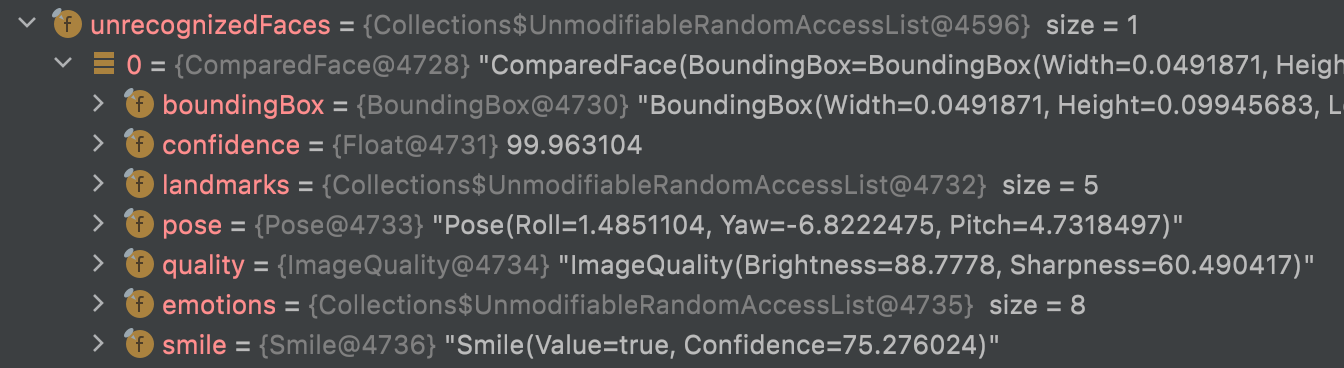
There are also some information about others unrecognized faces on the image.
unrecognizedFaces contains the same informations than celebs except for name, url and knownGender
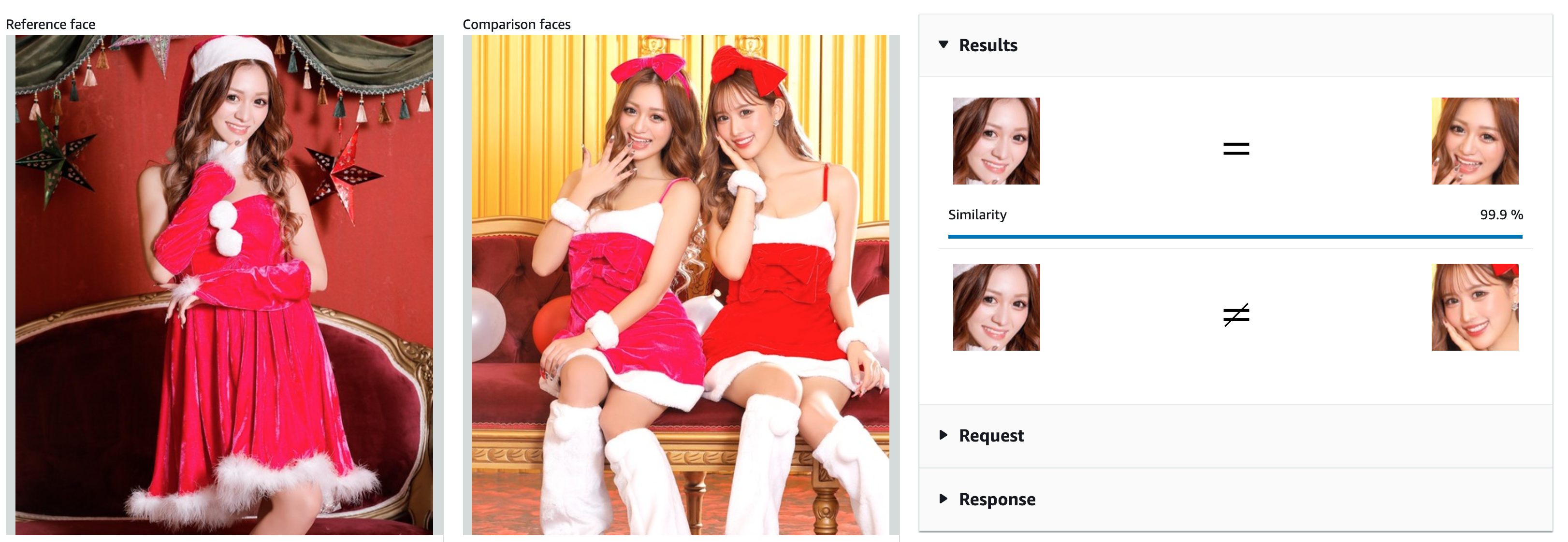
Face comparison
Similar to Celebrity recognition. This time we provide a photo of the person we want to search in another photo.
InputStream sourceStream = new FileInputStream(sourceImage);
InputStream tarStream = new FileInputStream(targetImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
SdkBytes targetBytes = SdkBytes.fromInputStream(tarStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
Image tarImage = Image.builder()
.bytes(targetBytes)
.build();
CompareFacesRequest facesRequest = CompareFacesRequest.builder()
.sourceImage(souImage)
.targetImage(tarImage)
.similarityThreshold(similarityThreshold)
.build();
CompareFacesResponse compareFacesResult = rekClient.compareFaces(facesRequest);
List<CompareFacesMatch> faceDetails = compareFacesResult.faceMatches();
List<ComparedFace> unmatched = compareFacesResult.unmatchedFaces();
So we try to detect if the reference face (contained in the sourceImage) is found in the targetImage.
faceDetails will return the faces found where the similarity score is over 70% (similarityThreshold here is 70F)
unmatched will contain the face details where similarity score is lower than 70%.
Both of them will contain a ComparedFace object and as we seen previously it describe :
the boundingBox for face, the landmarks (to describe the position of face elements) but also some informations about emotions (Happy, angry, sad...) with a confidence score.
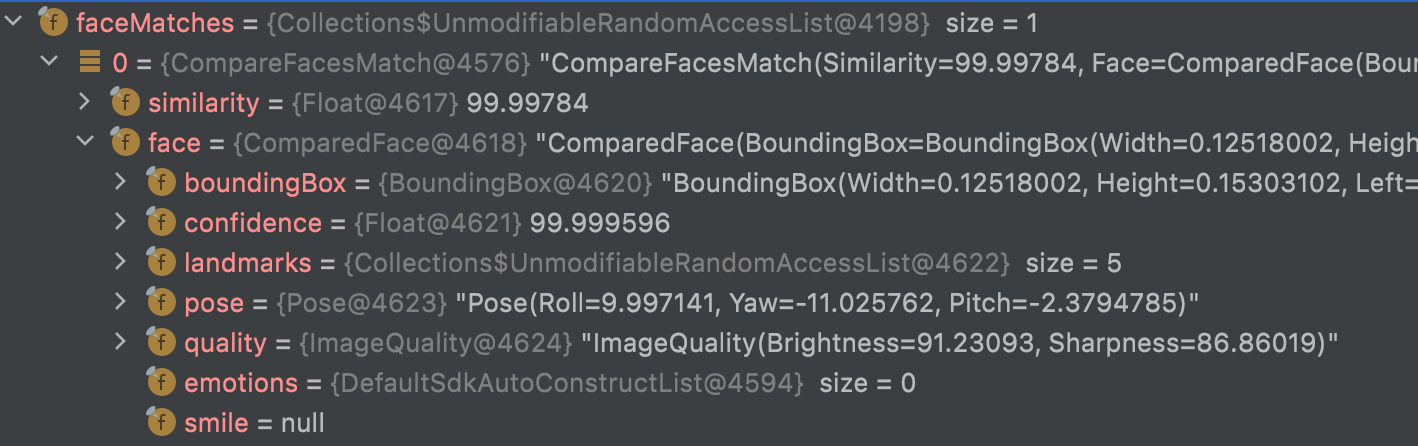
I am not sure why here emotions or smile were not returned.
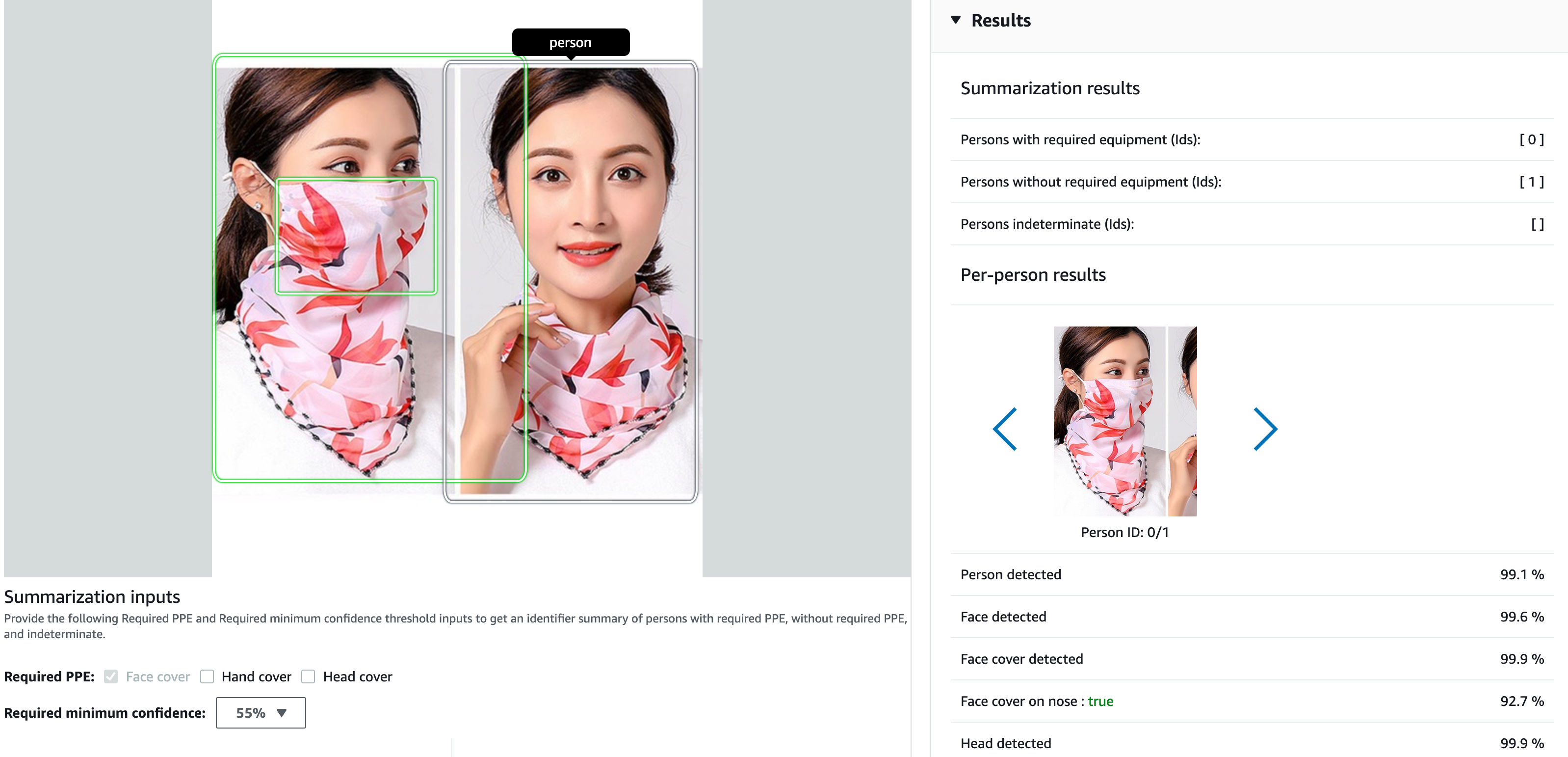
PPE(Personal Protective Equipment) detection
Here it detect the protective equipment used by a person on an image.
It maybe useful in time of covid if a person is wearing a mask, gloves, hat...
InputStream sourceStream = new FileInputStream(sourceImage);
SdkBytes sourceBytes = SdkBytes.fromInputStream(sourceStream);
Image souImage = Image.builder()
.bytes(sourceBytes)
.build();
ProtectiveEquipmentSummarizationAttributes summarizationAttributes = ProtectiveEquipmentSummarizationAttributes.builder()
.minConfidence(80F)
.requiredEquipmentTypesWithStrings("FACE_COVER") // , "HAND_COVER", "HEAD_COVER"
.build();
DetectProtectiveEquipmentRequest request = DetectProtectiveEquipmentRequest.builder()
.image(souImage)
.summarizationAttributes(summarizationAttributes)
.build();
DetectProtectiveEquipmentResponse result = rekClient.detectProtectiveEquipment(request);
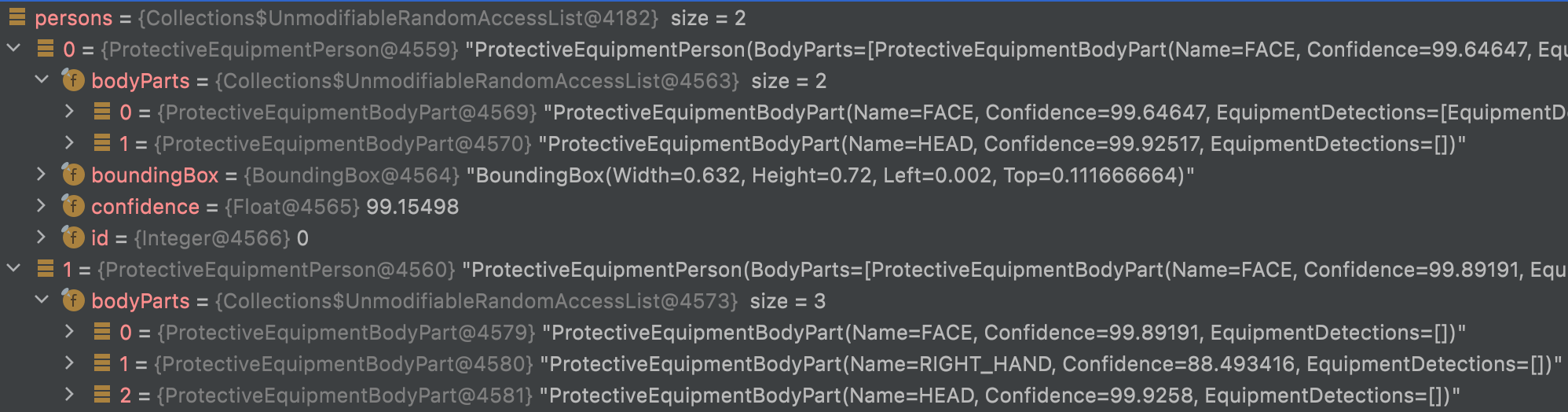
List<ProtectiveEquipmentPerson> persons = result.persons();
persons will contain a list of person found on the image.
For each person, it describes the bodyParts and for each body part what equipment is detected (or not) with a confidence score.
A last object returned is summary who contains the list of person ID that match the requirements specified in parameters ("FACE_COVER", "HAND_COVER", "HEAD_COVER")

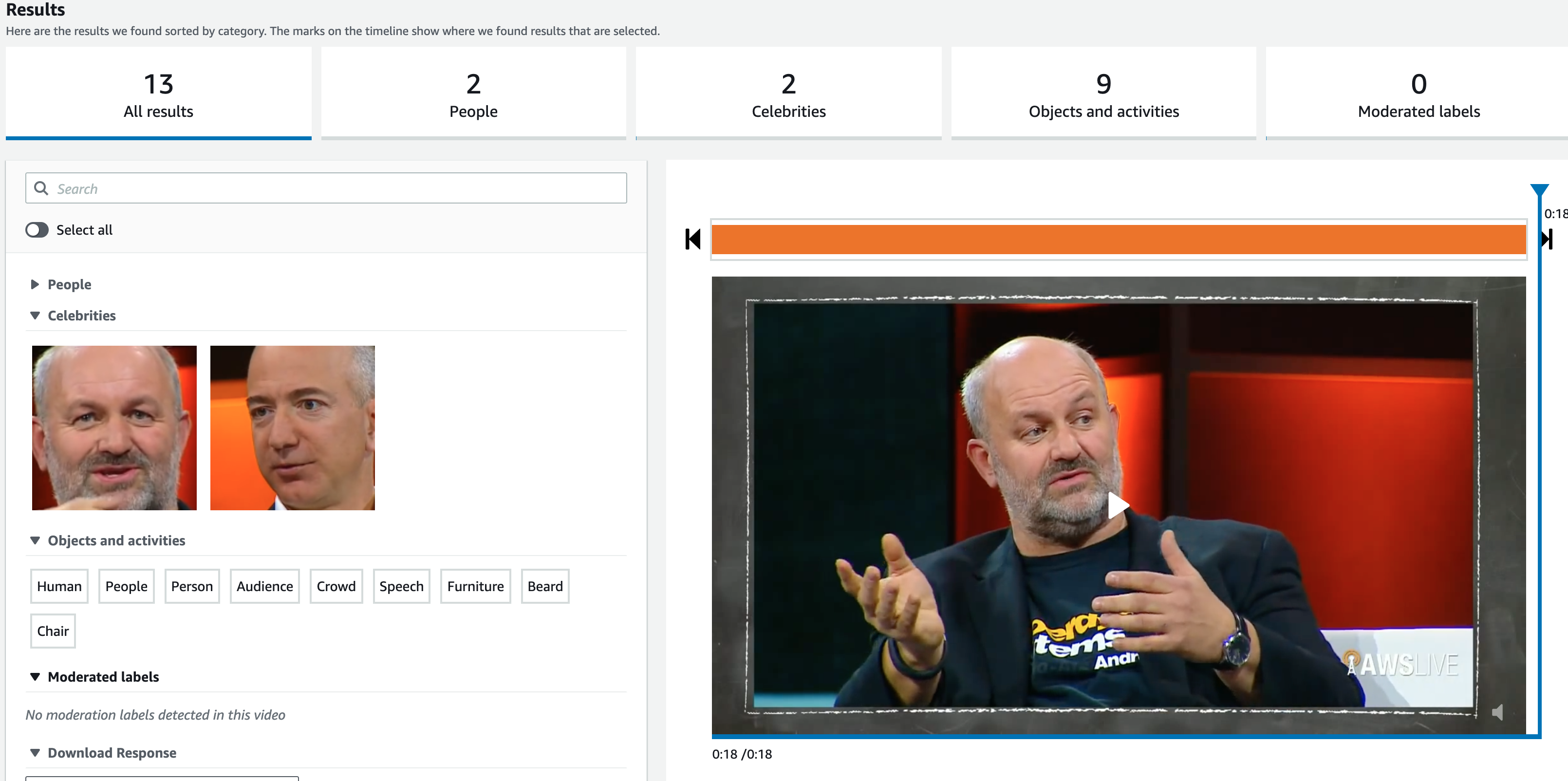
Video analysis
Video analysis is a compilation of all those functions.
The service is taking all the key frames (I guess) in a video and compile the results to a unique response.
S3Object s3Obj = S3Object.builder()
.bucket(bucket)
.name(video)
.build();
Video vidOb = Video.builder()
.s3Object(s3Obj)
.build();
StartLabelDetectionRequest labelDetectionRequest = StartLabelDetectionRequest.builder()
.jobTag("DetectingLabels")
.notificationChannel(channel)
.video(vidOb)
.minConfidence(50F)
.build();
StartLabelDetectionResponse labelDetectionResponse = rekClient.startLabelDetection(labelDetectionRequest);
startJobId = labelDetectionResponse.jobId();
The main differences with all those previous services are :
- This call is asynchronous, you have to wait for the job to be done.
- The video can be stored only on a S3 bucket and can't be uploaded
Also the UI presented here allows to do many different filters in same time.
In real you need to specify what kind of service you need for each call. In this sample ↑ it's about Label Detection.
Here ↓ similar code for Face Detection:
StartFaceDetectionRequest faceDetectionRequest = StartFaceDetectionRequest.builder()
.jobTag("Faces")
.faceAttributes(FaceAttributes.ALL)
.notificationChannel(channel)
.video(vidOb)
.build();
StartFaceDetectionResponse startLabelDetectionResult = rekClient.startFaceDetection(faceDetectionRequest);
startJobId=startLabelDetectionResult.jobId();
The result obtained is similar to previous services: a list of Object
In fact all the images composing the video are treated as one single image suppressing duplicate/similar items.
For the label result you will receive a list of objects describing :
label, confidence score and a timestamp.
cf : LabelDetection
Face Detection will return : a FaceDetection Object
Conclusion
Amazon Rekognition has a powerful number of service dedicated to image analysis.
But the data looks limited.
For exemple emotions concerned a limited number : Happy, Sad, Angry...
label looks also cheap and repetitive: "Person" "Human" "Tree" "Plant" (similar words are used and it's not pertinent)
Firebase MLKit was better for detecting a range label more important and pertinent.
Also as a "Deep learning" service it should work on text generation / completion like OpenAI GPT3 or Firebase MLKit, and language translation.
Firebase MLKit was also able to redirect user to google map when detecting a known place. Amazon can't benefit from this crossing service function.
Being able to analyse an entire video is a really good functionality that is not present in the concurrences.
Implementing those services are really easy and we can develop very quickly.