"""
36. 頻度上位10語
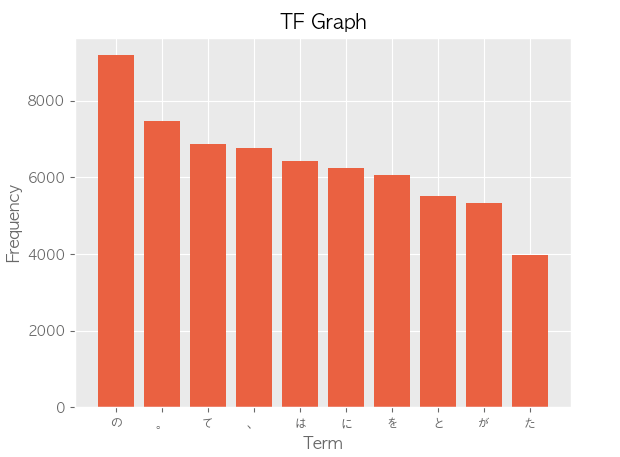
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
data:
[[{'surface': '', 'base': '*', 'pos': 'BOS/EOS', 'pos1': '*'},
{'surface': '一', 'base': '一', 'pos': '名詞', 'pos1': '数'},
{'surface': '', 'base': '*', 'pos': 'BOS/EOS', 'pos1': '*'}],
[{'surface': '', 'base': '*', 'pos': 'BOS/EOS', 'pos1': '*'},
{'surface': '吾輩', 'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞'},
{'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '係助詞'},
{'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '一般'},
{'surface': 'で', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'},
{'surface': 'ある', 'base': 'ある', 'pos': '助動詞', 'pos1': '*'},
{'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'},
{'surface': '', 'base': '*', 'pos': 'BOS/EOS', 'pos1': '*'}],
Memo:
- matplotlibで日本語を表示
"""
from collections import Counter
from typing import List
import matplotlib.pyplot as plt
import utils
plt.style.use("ggplot")
plt.rcParams["font.family"] = "Hiragino Mincho ProN" # 日本語対応
def get_tf(sentence_list: List[List[dict]]) -> list:
words = [word["surface"] for sent in sentence_list for word in sent[1:-1]]
c = Counter(words)
return c.most_common()
def plot_tf(x: list, y: list) -> None:
x_pos = [i for i, _ in enumerate(x)]
plt.bar(x, y)
plt.xlabel("Term")
plt.ylabel("Frequency")
plt.title("TF Graph")
plt.xticks(x_pos, x)
plt.show()
data = utils.read_json("30_neko_mecab.json")
counter = get_tf(data)
# [('の', 9194), ('。', 7486)]
x = [word[0] for word in counter[:10]]
y = [word[1] for word in counter[:10]]
plot_tf(x, y)
# 
More than 5 years have passed since last update.
Register as a new user and use Qiita more conveniently
- You get articles that match your needs
- You can efficiently read back useful information
- You can use dark theme