"""
## 49. 名詞間の係り受けパスの抽出[Permalink](https://nlp100.github.io/ja/ch05.html#49-名詞間の係り受けパスの抽出)
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がiiとjj(i<ji<j)のとき,係り受けパスは以下の仕様を満たすものとする.
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を”` -> `“で連結して表現する
- 文節iiとjjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iiから構文木の根に至る経路上に文節jjが存在する場合: 文節iiから文節jjのパスを表示
- 上記以外で,文節iiと文節jjから構文木の根に至る経路上で共通の文節kkで交わる場合: 文節iiから文節kkに至る直前のパスと文節jjから文節kkに至る直前までのパス,文節kkの内容を”` | `“で連結して表示
「ジョン・マッカーシーはAIに関する最初の会議で人工知能という用語を作り出した。」という例文を考える. CaboChaを係り受け解析に用いた場合,次のような出力が得られると思われる.
'''
Xは | Yに関する -> 最初の -> 会議で | 作り出した
Xは | Yの -> 会議で | 作り出した
Xは | Yで | 作り出した
Xは | Yという -> 用語を | 作り出した
Xは | Yを | 作り出した
Xに関する -> Yの
Xに関する -> 最初の -> Yで
Xに関する -> 最初の -> 会議で | Yという -> 用語を | 作り出した
Xに関する -> 最初の -> 会議で | Yを | 作り出した
Xの -> Yで
Xの -> 会議で | Yという -> 用語を | 作り出した
Xの -> 会議で | Yを | 作り出した
Xで | Yという -> 用語を | 作り出した
Xで | Yを | 作り出した
Xという -> Yを
'''
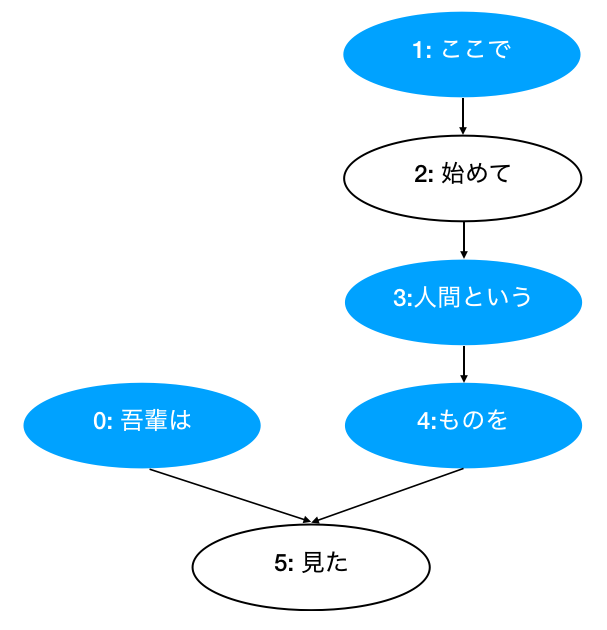
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(始め), Morph(て)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(人間), Morph(という)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(見), Morph(た), Morph(。)] )]
'''
Pattern 1 (Without root)
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root):
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
'''
"""
from collections import defaultdict
from typing import List
def read_file(fpath: str) -> List[List[str]]:
"""Get clear format of parsed sentences.
Args:
fpath (str): File path.
Returns:
List[List[str]]: List of sentences, and each sentence contains a word list.
e.g. result[1]:
['* 0 2D 0/0 -0.764522',
'\u3000\t記号,空白,*,*,*,*,\u3000,\u3000,\u3000',
'* 1 2D 0/1 -0.764522',
'吾輩\t名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ',
'は\t助詞,係助詞,*,*,*,*,は,ハ,ワ',
'* 2 -1D 0/2 0.000000',
'猫\t名詞,一般,*,*,*,*,猫,ネコ,ネコ',
'で\t助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ',
'ある\t助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル',
'。\t記号,句点,*,*,*,*,。,。,。']
"""
with open(fpath, mode="rt", encoding="utf-8") as f:
sentences = f.read().split("EOS\n")
return [sent.strip().split("\n") for sent in sentences if sent.strip() != ""]
class Morph:
"""Morph information for each token.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
surface (str): 表層形(surface)
base (str): 基本形(base)
pos (str): 品詞(base)
pos1 (str): 品詞細分類1(pos1)
"""
def __init__(self, data):
self.surface = data["surface"]
self.base = data["base"]
self.pos = data["pos"]
self.pos1 = data["pos1"]
def __repr__(self):
return f"Morph({self.surface})"
def __str__(self):
return "surface[{}]\tbase[{}]\tpos[{}]\tpos1[{}]".format(
self.surface, self.base, self.pos, self.pos1
)
class Chunk:
"""Containing information for Clause/phrase.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
chunk_id (int): The number of clause chunk (文節番号).
morphs List[Morph]: Morph (形態素) list.
dst (int): The index of dependency target (係り先文節インデックス番号).
srcs (List[str]): The index list of dependency source. (係り元文節インデックス番号).
"""
def __init__(self, chunk_id, dst):
self.id = int(chunk_id)
self.morphs = []
self.dst = int(dst)
self.srcs = []
def __repr__(self):
return "Chunk( id: {}, dst: {}, srcs: {}, morphs: {} )".format(
self.id, self.dst, self.srcs, self.morphs
)
def get_surface(self) -> str:
"""Concatenate morph surfaces in a chink.
Args:
chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)]
Return:
e.g. '吾輩は'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos != "記号":
res += morph.surface
return res
def validate_pos(self, pos: str) -> bool:
"""Return Ture if '名詞' or '動詞' in chunk's morphs. Otherwise, return False."""
morphs = self.morphs
return any([morph.pos == pos for morph in morphs])
def get_noun_masked_surface(self, mask: str) -> str:
"""Get masked surface.
Args:
mask (str): e.g. X or Y.
Returns:
str: '吾輩は' -> 'Xは'
'人間という' -> 'Yという'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos == "名詞":
res += mask
elif morph.pos != "記号":
res += morph.surface
return res
def convert_sent_to_chunks(sent: List[str]) -> List[Morph]:
"""Extract word and convert to morph.
Args:
sent (List[str]): A sentence contains a word list.
e.g. sent:
['* 0 1D 0/1 0.000000',
'吾輩\t名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ',
'は\t助詞,係助詞,*,*,*,*,は,ハ,ワ',
'* 1 -1D 0/2 0.000000',
'猫\t名詞,一般,*,*,*,*,猫,ネコ,ネコ',
'で\t助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ',
'ある\t助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル',
'。\t記号,句点,*,*,*,*,。,。,。']
Parsing format:
e.g. "* 0 1D 0/1 0.000000"
| カラム | 意味 |
| :----: | :----------------------------------------------------------- |
| 1 | 先頭カラムは`*`。係り受け解析結果であることを示す。 |
| 2 | 文節番号(0から始まる整数) |
| 3 | 係り先番号+`D` |
| 4 | 主辞/機能語の位置と任意の個数の素性列 |
| 5 | 係り関係のスコア。係りやすさの度合で、一般に大きな値ほど係りやすい。 |
Returns:
List[Chunk]: List of chunks.
"""
chunks = []
chunk = None
srcs = defaultdict(list)
for i, word in enumerate(sent):
if word[0] == "*":
# Add chunk to chunks
if chunk is not None:
chunks.append(chunk)
# eNw Chunk beggin
chunk_id = word.split(" ")[1]
dst = word.split(" ")[2].rstrip("D")
chunk = Chunk(chunk_id, dst)
srcs[dst].append(chunk_id) # Add target->source to mapping list
else: # Add Morch to chunk.morphs
features = word.split(",")
dic = {
"surface": features[0].split("\t")[0],
"base": features[6],
"pos": features[0].split("\t")[1],
"pos1": features[1],
}
chunk.morphs.append(Morph(dic))
if i == len(sent) - 1: # Add the last chunk
chunks.append(chunk)
# Add srcs to each chunk
for chunk in chunks:
chunk.srcs = list(srcs[chunk.id])
return chunks
class Sentence:
"""A sentence contains a list of chunks.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(始め), Morph(て)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(人間), Morph(という)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(見), Morph(た), Morph(。)] )]
"""
def __init__(self, chunks):
self.chunks = chunks
self.root = None
def __repr__(self):
message = f"""Sentence:
{self.chunks}"""
return message
def get_root_chunk(self):
chunks = self.chunks
for chunk in chunks:
if chunk.dst == -1:
return chunk
def get_noun_path_to_root(self, src_chunk: Chunk) -> List[Chunk]:
"""Get path from noun Chunk to root Chunk.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(始め), Morph(て)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(人間), Morph(という)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(見), Morph(た), Morph(。)] )]
Args:
src_chunk (Chunk): A Chunk. e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
Returns:
List[Chunk]: The path from a chunk to root.
The path from 'ここで' to '見た': ここで -> 人間という -> ものを -> 見た
So we should get: ['ここで', '人間という', 'ものを', '見た']
"""
chunks = self.chunks
path = [src_chunk]
dst = src_chunk.dst
while dst != -1:
dst_chunk = chunks[dst]
if dst_chunk.validate_pos("名詞") and dst_chunk.dst != -1:
path.append(dst_chunk)
dst = chunks[dst].dst
return path
def get_path_between_nouns(self, src_chunk: Chunk, dst_chunk: Chunk) -> List[Chunk]:
"""[summary]

Example:
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(始め), Morph(て)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(人間), Morph(という)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(見), Morph(た), Morph(。)] )]
Two patterns:
Pattern 1 (Without root): save as a list.
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root): save as a dict.
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] )
Path:
From 'ここで' to 'ものを': ここで -> 人間という -> ものを
Returns:
List[Chunk]: [Chunk(人間という)]
Pattern 2:
src_chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(吾輩), Morph(は)] ),
dst_chunk (Chunk): e.g. Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(人間), Morph(という)] )
Path:
From Chunk(吾輩は) to Chunk(人間という):
0 | 3 -> 4 | 5
- Chunk(吾輩は) -> Chunk(見た)
- Chunk(人間という) -> Chunk(ものを) -> Chunk(見た)
Returns:
Dict: {'src_to_root': [Chunk(吾輩は)],
'dst_to_root': [Chunk(人間という), Chunk(ものを)]}
"""
chunks = self.chunks
pattern1 = []
pattern2 = {"src_to_root": [], "dst_to_root": []}
if src_chunk.dst == dst_chunk.id:
return pattern1
current_src_chunk = chunks[src_chunk.dst]
while current_src_chunk.dst != dst_chunk.id:
# Pattern 1
if current_src_chunk.validate_pos("名詞"):
pattern1.append(src_chunk)
# Pattern 2
if current_src_chunk.dst == -1:
pattern2["src_to_root"] = self.get_noun_path_to_root(src_chunk)
pattern2["dst_to_root"] = self.get_noun_path_to_root(dst_chunk)
return pattern2
current_src_chunk = chunks[current_src_chunk.dst]
return pattern1
def write_to_file(sents: List[dict], path: str) -> None:
"""Write to file.
Args:
sents ([type]):
e.g. [[['吾輩は', '猫である']],
[['名前は', '無い']],
[['どこで', '生れたか', 'つかぬ'], ['見当が', 'つかぬ']]]
"""
# convert_frame_to_text
lines = []
for sent in sents:
for chunk in sent:
lines.append(" -> ".join(chunk))
# write_to_file
with open(path, "w") as f:
for line in lines:
f.write(f"{line}\n")
def get_pattern1_text(src_chunk, path_chunks, dst_chunk):
"""
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ここ), Morph(で)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(もの), Morph(を)] )
Path:
From 'ここで' to 'ものを': ここで -> 人間という -> ものを
path_chunks:
List[Chunk]: [Chunk(人間という)]
"""
path = []
path.append(src_chunk.get_noun_masked_surface("X"))
for path_chunk in path_chunks:
path.append(path_chunk.get_surface())
path.append(dst_chunk.get_noun_masked_surface("Y"))
return " -> ".join(path)
def get_pattern2_text(path_chunks, sent):
"""
Path:
From Chunk(吾輩は) to Chunk(人間という):
0 | 3 -> 4 | 5
- Chunk(吾輩は) -> Chunk(見た)
- Chunk(人間という) -> Chunk(ものを) -> Chunk(見た)
path_chunks:
Dict: {'src_to_root': [Chunk(吾輩は)],
'dst_to_root': [Chunk(人間という), Chunk(ものを)]}
"""
path_text = "{} | {} | {}"
src_path = []
for i, chunk in enumerate(path_chunks["src_to_root"]):
if i == 0:
src_path.append(chunk.get_noun_masked_surface("X"))
else:
src_path.append(chunk.get_surface())
src_text = " -> ".join(src_path)
dst_path = []
for i, chunk in enumerate(path_chunks["dst_to_root"]):
if i == 0:
dst_path.append(chunk.get_noun_masked_surface("Y"))
else:
dst_path.append(chunk.get_surface())
dst_text = " -> ".join(dst_path)
root_chunk = sent.get_root_chunk()
root_text = root_chunk.get_surface()
return path_text.format(src_text, dst_text, root_text)
def get_paths(sent_chunks: List[Sentence]):
paths = []
for sent_chunk in sent_chunks:
sent = Sentence(sent_chunk)
chunks = sent.chunks
for i, src_chunk in enumerate(chunks):
if src_chunk.validate_pos("名詞") and i + 1 < len(chunks):
for j, dst_chunk in enumerate(chunks[i + 1 :]):
if dst_chunk.validate_pos("名詞"):
path_chunks = sent.get_path_between_nouns(src_chunk, dst_chunk)
if isinstance(path_chunks, list): # Pattern 1
paths.append(
get_pattern1_text(src_chunk, path_chunks, dst_chunk)
)
if isinstance(path_chunks, dict): # Pattern 2
paths.append(get_pattern2_text(path_chunks, sent))
return paths
fpath = "neko.txt.cabocha"
sentences = read_file(fpath)
sent_chunks = [convert_sent_to_chunks(sent) for sent in sentences] # ans41
# ans49
paths = get_paths(sent_chunks)
for p in paths[:20]:
print(p)
# Xは | Yで -> 人間という -> ものを | 見た
# Xは | Yという -> ものを | 見た
# Xは | Yを | 見た
# Xで -> Yという
# Xで -> Yを
# Xという -> Yを
More than 5 years have passed since last update.
Register as a new user and use Qiita more conveniently
- You get articles that match your needs
- You can efficiently read back useful information
- You can use dark theme