はじめに
興味はあるもののなかなか手出しできなかったiPhoneのAudioプログラミングに挑戦してみました。
題材は、マイクからのオーディオ取得とFFTを使った楽器(主にギター?)チューナです。
楽器チューナは、下図のようにマイクから音を取り込み、FFTで周波数軸のデータを取り出し、所定の周波数と合致しているかを判定することで、おおよその機能が実現します。
技術要素
マイク入力の音声データを取得する
マイク入力のための資料は、あるようで実は絶望的に少なかったです。
Appleの資料だけでは、何をどう組み立てれば良いのか、ほぼ暗中模索状態でした。
最終的には、下記のコードが大変参考になりました。ありがとうございます。
github:gist hotpaw2/RecordAudio.swift 1
以下に、マイクからPCMデータを取得するための手順を説明していきます。
iOSで音を取得するためには、下記のような手順を実施する必要があります。
- マイク入力の許可リクエスト
- PCM入力のAVAudioSessionを開始
- AudioUnitを設定
マイク入力の許可リクエスト
private var micPermission = false
private func requestRecordPermission(handler: @escaping ((Bool) -> Void)) {
let audioSession = AVAudioSession.sharedInstance()
if micPermission {
handler(true)
} else {
audioSession.requestRecordPermission { (granted: Bool) in
self.micPermission = granted
handler(granted)
}
}
}
AVAudioSessionを開始
ハードウェアのサンプリングレート(サンプリング周波数)は、44.1KHzの場合と、48KHzの場合があります。
よく知られているように、CDでのサンプリングレートは44.1kHzです。
44.1kHzは音楽業界の標準で、48kHzは映像業界の音の標準だそうです。
この数値は、人間の耳の可聴領域(人間の耳が聞きとれる音の周波数範囲)が、20Hzから20KHzであることから来ています。
サンプリングレートがおおよそ倍になっているのは、標本化定理(サンプリング定理)によるもので、20KHzまでの信号をデジタル化(サンプリング)しても情報を失わないためには、2倍以上のサンプリングレートが必要となっています。
逆に言うと、デジタル化されたデータをアナログ信号に復元する場合は、サンプリングレートの半分の周波数(これをナイキスト周波数と呼ぶ)までしか復元できません。
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(AVAudioSession.Category.record)
// ハードウェアのサンプリングレートを取得
let hardwareSamplingRate = audioSession.sampleRate
// サンプル数
let samplingNumber: Double = 4_096
let preferredSampleRate: Double
switch hardwareSamplingRate {
case 48_000.0:
preferredSampleRate = 48_000.0
default:
preferredSampleRate = 44_100.0
}
/*
ハードウェアのサンプリングレートは、44.1KHzの場合と、48KHzの場合があります。
44.1KHzの場合に、4096点のサンプリングに要する時間は、0.093秒
48KHzの場合に、4096点のサンプリングに要する時間は、0.086秒
となります。
*/
let preferredIOBufferDuration: TimeInterval = 1.0 / preferredSampleRate * 4_096
// 入力および出力オーディオサンプルレートの変更を要求
try audioSession.setPreferredSampleRate(preferredSampleRate)
// I/O バッファの持続時間の変更を要求
try audioSession.setPreferredIOBufferDuration(preferredIOBufferDuration)
sampleRate = audioSession.sampleRate
// 略
try audioSession.setActive(true)
AVAudioSession.Categoryは、record です。このカテゴリは、ほぼすべての出力を無音にします。
また、ハードウェアのサンプリングレートを取得を取得し、サンプル数から計算したI/O バッファの持続時間の変更を要求しています。
注意が必要なのが、サンプル数です。サンプル数をいくつにするかで、後で出てくるFFTの解析精度が決まります。こちらは、FFTの項で説明します。
最後に、audioSessionをアクティブにして処理を開始します。
AudioUnitを設定
- AudioUnitの取得
- マイク入力を有効化
- 入出力フォーマットを設定
- Bufferを確保
- 音を取得するコールバック関数を設定
AudioUnitの取得
最初に、AudioUnitを取得します。
AudioUnitは、オーディオ入出力や信号処理などを行うオーディオ処理プラグインを実装するためのインタフェースです。
所定のAudioUnitを取り出すために、AudioComponentFindNext() 関数を用います。
AudioComponentFindNext()に渡すパラメータは下記のようになります。
// kAudioUnitType_Output、kAudioUnitSubType_RemoteIO は、
// ハードウェアを意味している
var componentDesc: AudioComponentDescription
= AudioComponentDescription(
componentType: OSType(kAudioUnitType_Output),
componentSubType: OSType(kAudioUnitSubType_RemoteIO),
componentManufacturer: OSType(kAudioUnitManufacturer_Apple),
componentFlags: UInt32(0),
componentFlagsMask: UInt32(0)
)
kAudioUnitType_Output、kAudioUnitSubType_RemoteIO は、オーディオハードウェアを意味しており、
さらにApple製のものを指定しています。
// 指定されたオーディオコンポーネントの次に、
// AudioComponentDescription 構造体に合致するコンポーネントを検索する
// ここでは、最初に見つかったコンポーネントを返す
let component: AudioComponent! = AudioComponentFindNext(nil, &componentDesc)
// 新しいオーディオコンポーネントを作成
var tempAudioUnit: AudioUnit?
osErr = AudioComponentInstanceNew(component, &tempAudioUnit)
audioUnit = tempAudioUnit
上記のように、AudioComponentから、AudioComponentInstanceであるAudioUnitを取得します。
AudioComponentはプラグインの定義であり、実際に動作させるにはAudioComponentInstanceを取得する必要があります。
iPhoneの場合は、下記のようなコードで次のハードウェアを検索してもnextComponentはnilが返ってくるので、1つのハードウェアしかないようです。
let nextComponent = AudioComponentFindNext(component, &componentDesc)
マイク入力を有効化
上記で作成した新しいオーディオコンポーネントのAudioUnitを設定していきます。
I/Oユニットのバス1は、マイクからの録音など、入力ハードウェアに接続します。
入力はデフォルトで無効になっています。
入力を有効にするには、次のようにバス1の入力スコープを有効にする必要があります。
enableFlagは 1 、UInt32型で設定します。
private let outputBus: UInt32 = 0 // スピーカなど
private let inputBus: UInt32 = 1 // マイクなど
var enableFlag: UInt32 = 1
// マイク入力を有効にする
osErr = AudioUnitSetProperty(audioUnit,
kAudioOutputUnitProperty_EnableIO,
kAudioUnitScope_Input,
inputBus,
&enableFlag,
UInt32(MemoryLayout<UInt32>.size))
入出力フォーマットを設定
入出力データフォーマットは、リニアPCM、Float型を指定します。
最終的に片チャネルしか使わないですが、一応2チャンネルステレオで取得します。
// オーディオフォーマットの設定
// サンプリングレート、データフォーマットとしてリニアPCM、Float型
var streamFormatDesc: AudioStreamBasicDescription = AudioStreamBasicDescription(
mSampleRate: Double(sampleRate),
mFormatID: kAudioFormatLinearPCM,
mFormatFlags: kAudioFormatFlagsNativeFloatPacked,
mBytesPerPacket: UInt32(SoundInput.numberOfChannels
* MemoryLayout<UInt32>.size),
mFramesPerPacket: 1,
mBytesPerFrame: UInt32(SoundInput.numberOfChannels
* MemoryLayout<UInt32>.size),
mChannelsPerFrame: UInt32(SoundInput.numberOfChannels),
mBitsPerChannel: UInt32(8 * (MemoryLayout<UInt32>.size)),
mReserved: UInt32(0)
)
入力、出力共に同じ設定を行います。
/// 入力フォーマットを設定
osErr = AudioUnitSetProperty(audioUnit,
kAudioUnitProperty_StreamFormat,
kAudioUnitScope_Input,
outputBus,
&streamFormatDesc,
UInt32(MemoryLayout<AudioStreamBasicDescription>.size))
/// 出力フォーマットを設定
osErr = AudioUnitSetProperty(audioUnit,
kAudioUnitProperty_StreamFormat,
kAudioUnitScope_Output,
inputBus,
&streamFormatDesc,
UInt32(MemoryLayout<AudioStreamBasicDescription>.size))
Bufferを確保
AudioUnitが次に説明するコールバックのために使用する内部バッファを用意します。コールバックを持たない場合、バッファを作成する必要はありません。
enableFlagは 1 、UInt32型で設定します。
/// Bufferを確保
osErr = AudioUnitSetProperty(
audioUnit,
AudioUnitPropertyID(kAudioUnitProperty_ShouldAllocateBuffer),
AudioUnitScope(kAudioUnitScope_Output),
inputBus,
&enableFlag,
UInt32(MemoryLayout<UInt32>.size))
音を取得するコールバック関数を設定
前述のAudioUnitを設定の内容に加えて、データを取り出すためのコールバック関数を登録します。
/// コールバック構造体
var inputCallbackStruct
= AURenderCallbackStruct(inputProc: recordingCallback,
inputProcRefCon:
UnsafeMutableRawPointer(Unmanaged.passUnretained(self).toOpaque()))
/// コールバックを設定
osErr = AudioUnitSetProperty(
audioUnit,
AudioUnitPropertyID(kAudioOutputUnitProperty_SetInputCallback),
AudioUnitScope(kAudioUnitScope_Global),
inputBus,
&inputCallbackStruct,
UInt32(MemoryLayout<AURenderCallbackStruct>.size))
コールバック関数は
/// 音を取得するコールバック関数
let renderCallback: AURenderCallback = {
inRefCon, // コールバックをAudioUnitに登録する際のカスタムデータ
ioActionFlags, // このコンテキストについて詳しく説明するためのフラグ
inTimeStamp, // AudioUnitのレンダリングのタイムスタンプ
inBusNumber, // AudioUnitのレンダリングのバス番号
frameCount, // サンプリングされたフレームの数
_ -> OSStatus in
let audioObject
= unsafeBitCast(inRefCon, to: SoundInput.self)
var err: OSStatus = noErr
var bufferList = AudioBufferList(
mNumberBuffers: 1,
mBuffers: AudioBuffer(
mNumberChannels: UInt32(numberOfChannels),
mDataByteSize: 16,
mData: nil
)
)
if let au = audioObject.audioUnit {
err = AudioUnitRender(
au,
ioActionFlags,
inTimeStamp,
inBusNumber,
frameCount,
&bufferList)
}
audioObject.processMicrophoneBuffer(
inputDataList: &bufferList,
frameCount: UInt32(frameCount))
return 0
}
AudioUnitを開始します。
osErr = AudioUnitInitialize(audioUnit)
if osErr != noErr { return }
osErr = AudioOutputUnitStart(audioUnit)
FFT
FFTの概要
音の周波数を評価するために、FFTを用います。
FFTとはFast Fourier Transformation(高速フーリエ変換)2です。
通常のフーリエ変換と異なるのは、サンプリング数が2の累乗であるという条件を満たせば、
普通のフーリエ変換 O(n^2) に対し、O(n*log n) と高速に演算できるところです。
フーリエ変換をざっくり言うと、音も含めて時間軸と強さの軸を持つ関数は、複数のsin波、cos波を合成したものと考えることができます。
f(x) = \frac{1}{2}a_0+\sum_{n=1} ^{\infty}(a_ncos(nx)+b_nsin(nx))
たとえば矩形波をフーリエ変換すると、周期の異なる(奇数倍)のsin波の合成でできていることが分かります。
この場合は、cos波は必要ありません。
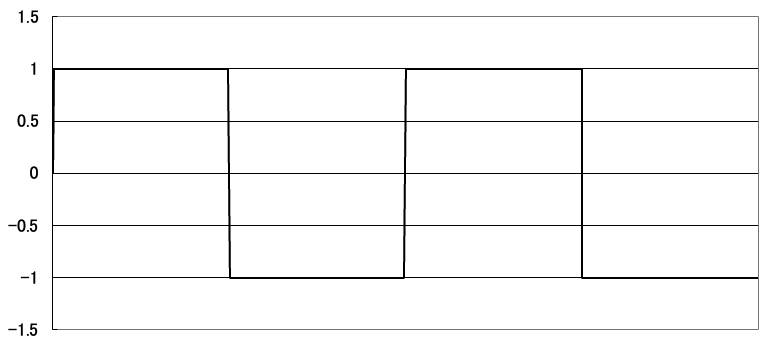
このような矩形波は、下図のような複数のsin波を合成していくと得られます。
周期は最初のsin波を1とすると2つ目は1/3です。

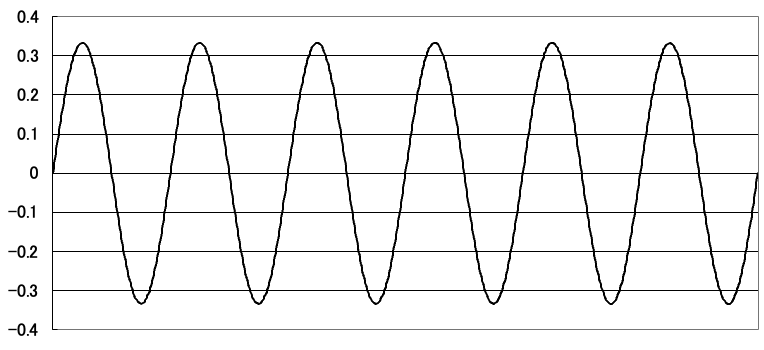
合成した結果はこちらです。

周期を奇数倍とするsin波を無限に合成していくことで、矩形波が得られます。
とは言え、無限に足していくことは難しいので、4つ程度のsin波を足し合してみます。
下記のような数式に従って4つのsin波を足し合わせます。
f(x) = \frac{4}{\pi}
\left\{
sin(x)+\frac{1}{3}sin(3x)+\frac{1}{5}sin(5x)+\frac{1}{7}sin(7x)+ ・・・
\right\}
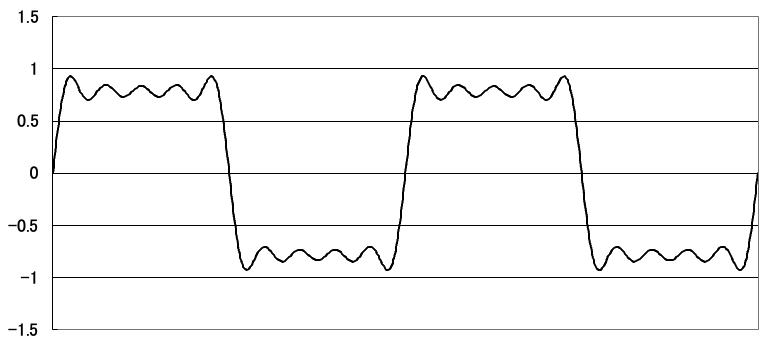
FFTでは上記の逆方向、つまり波形からそれぞれのsin波、cos波を求めます。
人間の声は複雑な波形なので多くの波の合成からできていますが、電子機器などは単一の周波数の音を出していることが多く、このような場合は、周波数軸から見ると下図のように特定の周波数のパワーとなって現れます。
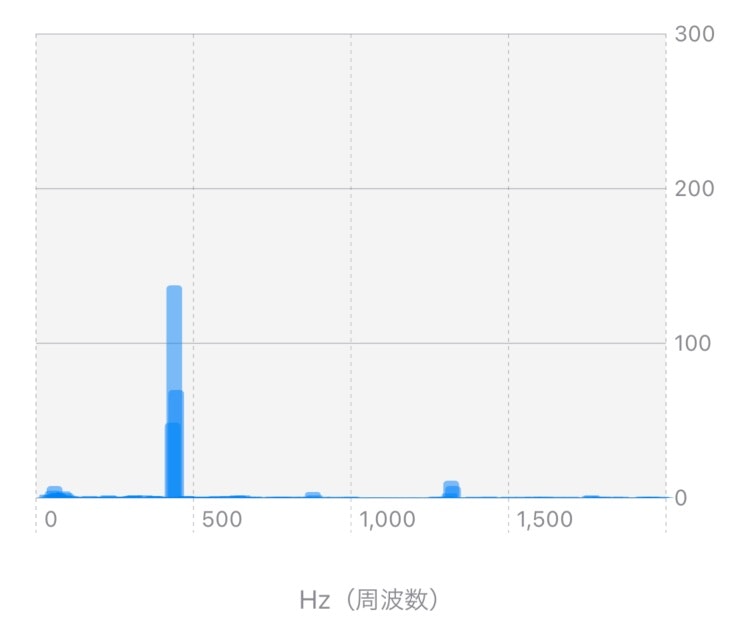
FFTを用いることで、音を構成する周波数を比較し、同じ音であるかどうかを評価することが容易になります。
周波数の分解能は、AVAudioSessionの項で出てきたサンプル数に依存しています。
サンプリングレートが、44.1KHzでサンプル数が4096であるということは、周波数分解能は10.8Hzです。
10.8Hz = 44.1KHz / 4096
10.8Hz単位で音のパワーを取得できると言うことです。サンプル数を増加させれば分解能は上がっていきますが、FFTの演算時間を考慮する必要があります。
窓関数
FFTでは連続した波の一部分を切り取って演算します。このため切り取った区間の端の連続性が問題になり、周波数分析結果に影響を与えます。
これに対する解決策として、窓関数3を適用して両端の不連続性を低減することができます。
窓関数には、何種類かあるのですがここでは、ハミング窓を使っています。
w(t) = 0.54 - 0.4 cos 2\pi \frac{t}{T} \ , 0 \leq t < T
サンプル数が4096と言うことは、データが格納された [Float] 配列に対して、 T = 4096, t = 配列のindex となります。
vDSP
このFFT演算では、iOS 14から利用可能になったvDSP.FFTを利用しています。
vDSPフレームワークは、フーリエ変換や二次フィルタリングなどのデジタル信号処理、また乗加算などの関数や、和、平均、最大値などの縮小関数など演算処理が高速に可能です。
vDSP.FFTは、UnsafeMutablePointerを使って直接メモリーにアクセスします。
入出力は複素数の形になっていますが、入力は虚数部を0として与えます。
// vDSP.FFTインスタンスを生成する
let log2n = vDSP_Length(log2(Float(signal.count)) + 1)
let fft = vDSP.FFT(log2n: log2n, radix: .radix2
, ofType: DSPSplitComplex.self)!
var signalArray = [Float](signal)
// UnsafeMutablePointerでメモリーをアロケート、初期化
let signalImagPtr = UnsafeMutablePointer<Float>.allocate(capacity: signal.count)
signalImagPtr.initialize(to: 0)
let outputRealPtr = UnsafeMutablePointer<Float>.allocate(capacity: signal.count)
outputRealPtr.initialize(to: 0)
let outputImagPtr = UnsafeMutablePointer<Float>.allocate(capacity: signal.count)
outputImagPtr.initialize(to: 0)
// FFTを実行
signalArray.withUnsafeMutableBufferPointer { signalPtr in
let input = DSPSplitComplex(realp: signalPtr.baseAddress!,
imagp: signalImagPtr)
var output = DSPSplitComplex(realp: outputRealPtr,
imagp: outputImagPtr)
fft.forward(input: input, output: &output)
}
演算結果は複素数で取得しますので、下記のようにパワーを演算して評価します。
let power = sqrt(pow(value.real, 2) + pow(value.imaginary, 2))
今回は、FFTの演算は、「[Swift] vDSPを利用して高速フーリエ変換する」4を参考にさせていただきました。ありがとうございます。
周波数特徴の認識
今回は、単純にパワーが大きい周波数が事前に登録した周波数と一致するかどうかで評価、判定しています。
ただし楽器は純粋な正弦波を出すことはないので、倍音5を含んでいます。
下記にギターの開放弦の周波数をあげています。例えば低音のEは82KHzですが、ギターの音は倍音として164KHzや246khzの音を含んでいます。それぞれの周波数のパワーを考慮して、主となる周波数が何かはある程度は推測できます。
| コード | 周波数 |
|---|---|
| E | 82Hz |
| A | 110Hz |
| D | 147Hz |
| G | 196Hz |
| B | 247Hz |
| E | 330Hz |
おわりに
技術要素としてはシンプルに見えるのですが、マイクからPCMデータを取り出すだけでも難しく、さまざまな資料やOSSをあたり苦戦しました。
またメモリー上にどのようにデータが配置されているかが明確ではないために、PCMデータからFFT演算し時間軸のデータと変換する部分でも、かなりドキドキしながらコードを書いていきました。
本稿が何かの参考になれば幸いです。
参考にさせていただいた記事やソースコードの作者に感謝いたします。
-
【github:gist】hotpaw2/RecordAudio.swift (https://gist.github.com/hotpaw2/ba815fc23b5d642705f2b1dedfaf0107) ↩
-
工学においては、変換後の関数f'はもとの関数fに含まれる周波数を記述していると考え、しばしばもとの関数fの周波数領域表現 (frequency domain representation) と呼ばれる。言い換えれば、フーリエ変換は関数fを正弦波・余弦波に分解するとも言える。 (https://ja.wikipedia.org/wiki/フーリエ変換)より ↩
-
窓関数(まどかんすう、英: window function)とは、ある有限区間(台)以外で0となる関数である。 ある関数や信号(データ)に窓関数が掛け合わせられると、区間外は0になり、有限区間内だけが残るので、無限回の計算が不要になり数値解析が容易になる。窓関数は、データから成分を抽出するアルゴリズムの中核に当たり、スペクトル分析、フィルタ・デザインや、音声圧縮に応用される。窓関数を単に窓 (window) ともいい、データに窓関数を掛け合わせることを窓を掛ける (windowing) という。
(https://ja.wikipedia.org/wiki/窓関数) より ↩ -
[Swift] vDSPを利用して高速フーリエ変換する(https://zenn.dev/moutend/articles/e39f4f162db475bea8c8) ↩
-
弦楽器や管楽器などの音を正弦波(サインウェーブ)成分の集合に分解すると、元の音と同じ高さの波の他に、その倍音が多数(理論的には無限個)現れる。ただし、現実の音源の倍音は必ずしも厳密な整数倍ではなく、倍音ごとに高めであったり低めであったりするのが普通で、揺らいでいることも多い。逆に、簡易な電子楽器の音のように完全に整数倍の成分だけの音は人工的な響きに感じられる。 (https://ja.wikipedia.org/wiki/倍音)より ↩