はじめに
過去の記事(ウィキペディアのデータを使ってword2vecをしてみる{4. モデル応用編})では、word2vecモデルの多次元ベクトルを用いて単語の非階層型クラスタリングをしました。
今回は、非階層型クラスタリングの結果を見せ方を変えて、3D散布図を描画します。
最終的に、以下のようなモノを作ります。
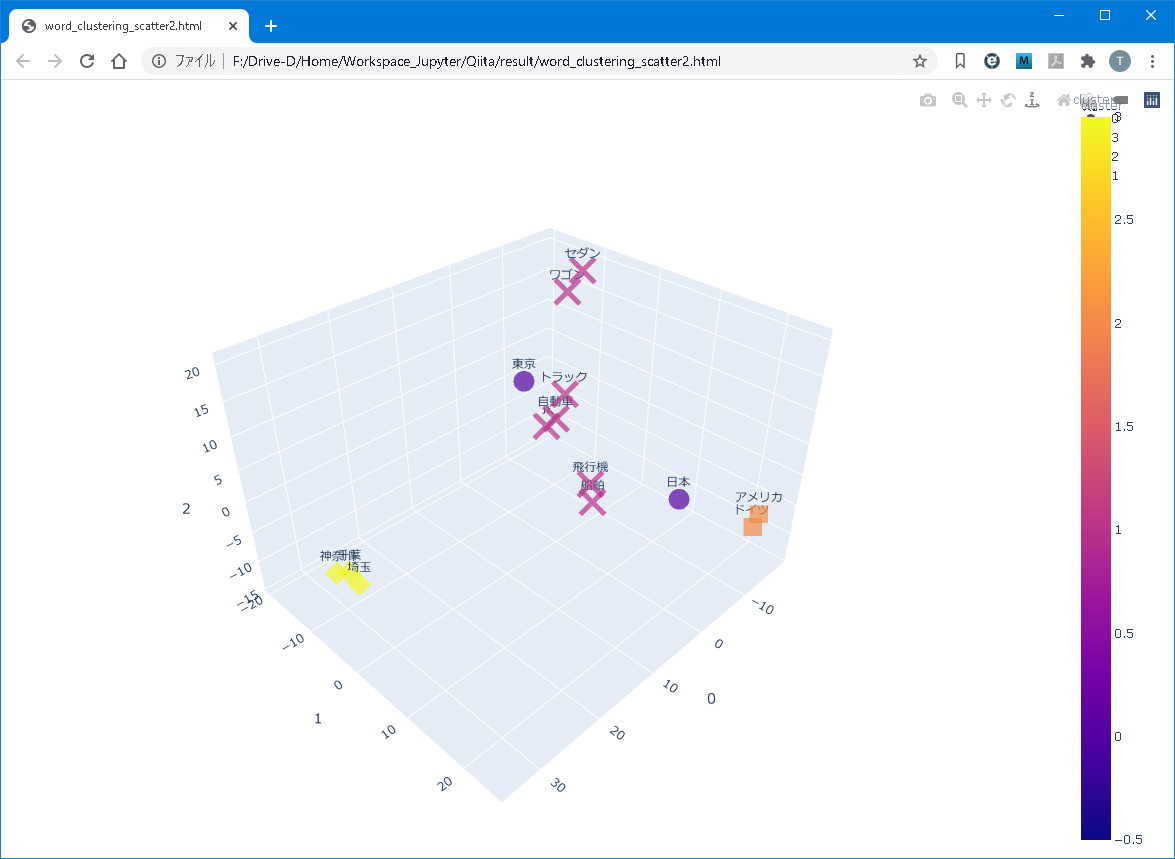
本稿で紹介すること
- 3D散布図の描画
Plotly Python Graphing Library | Python | Plotly
本稿で紹介しないこと
- Pythonライブラリの使い方
- scikit-learn
- pandas
- matplotlib
- plotly ※グラフ描画用のPythonライブラリ
サンプルコード
非階層型クラスタリングを実行するところまでは、過去の記事を参考されたし。
クラスタリングの結果から、可視化しいてゆくCodeに焦点を絞って
Codeを紹介
まずは、PCAで次元圧縮をする部分です。
次元数の指定を変えて、実行するだけです。
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
# PCAで3次元に圧縮
pca = PCA(n_components=3)
pca.fit(df.iloc[:, :-2])
feature = pca.transform(df.iloc[:, :-2])
# 日本語フォントの指定
plt.rcParams["font.family"] = 'Yu Gothic'
# 散布図プロット
color = {0:"green", 1:"red", 2:"yellow", 3:"blue"}
colors = [color[x] for x in cluster_labels]
plt.figure(figsize=(20, 20))
for x, y, name in zip(feature[:, 0], feature[:, 1], df.iloc[:, -2]):
plt.text(x, y, name)
plt.scatter(feature[:, 0], feature[:, 1], color=colors)
plt.savefig("../result/word_clustering_scatter2.png")
plt.show()
当たり前ですが、2D散布図だと、結果は同じです。

次に、3D散布図のための、データ加工です。
feature_df = pd.DataFrame(feature)
# feature_df.head()
feature_df["word"] = words
feature_df["cluster"] = cluster_labels
# feature_df
そして、本稿の本題、3D散布図を描画します。
import plotly
import plotly.express as px
plotly.offline.init_notebook_mode(connected=False)
fig = px.scatter_3d(feature_df, x=0, y=1, z=2, text="word", color='cluster', symbol='cluster', opacity=0.7)
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0))
plotly.offline.plot(fig, filename='../result/word_clustering_scatter2.html', auto_open=True)
すると、冒頭で示した画面が表示されます。
Plotlyを利用した理由が、ここから発揮されます。
Plotlyで描画した3D散布図は、画面上で拡大・縮小はもちろん、回転もできてしまいます!
早速、回転をしてみると、matplotlibで描画した2D散布図と似たような断面が現れました。
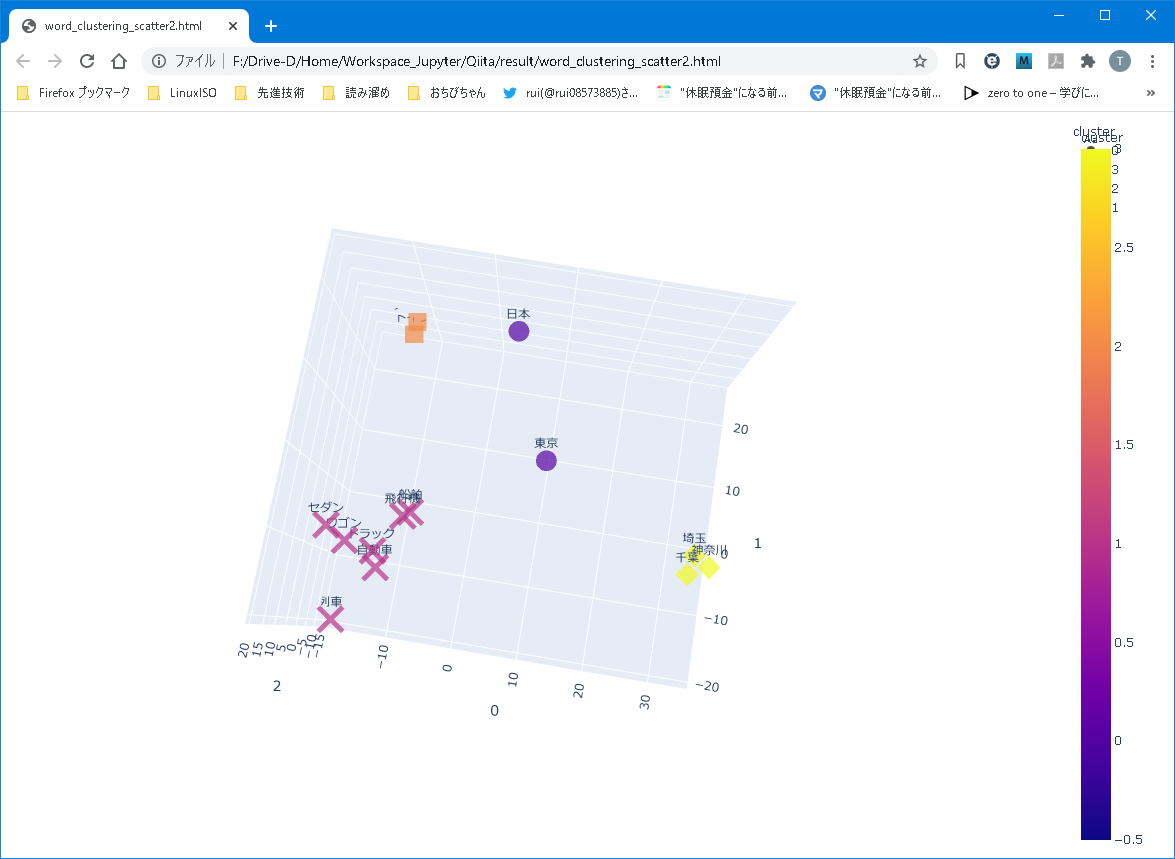
もう少し回転してみて、”東京”と”日本”、そして3都市(”神奈川”、”千葉”、”埼玉”)との位置関係を探ってみます。
まず、国(”日本”、”アメリカ”、”ドイツ”)は概ね同じ平面上に存在していました。
画像からは分かりにくいかもしれませんが、東京も3都市も、国の平面とは異なる場所に位置しています。
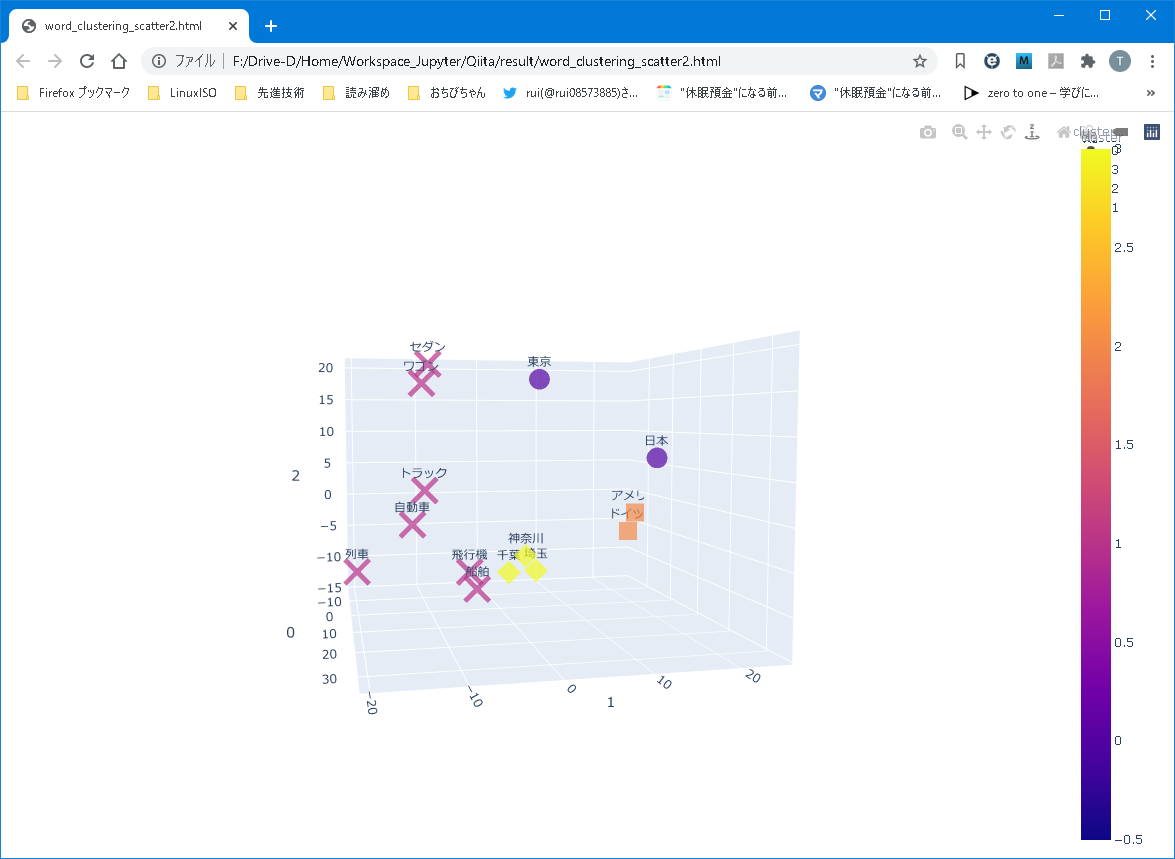
そして、異なるアングルから。
3都市は概ね同じ平面に存在していました。が、同じ平面状に”東京”は存在していませんでした。
”東京”は、国の平面とも、都市の平面とも、異なる場所に位置しています。
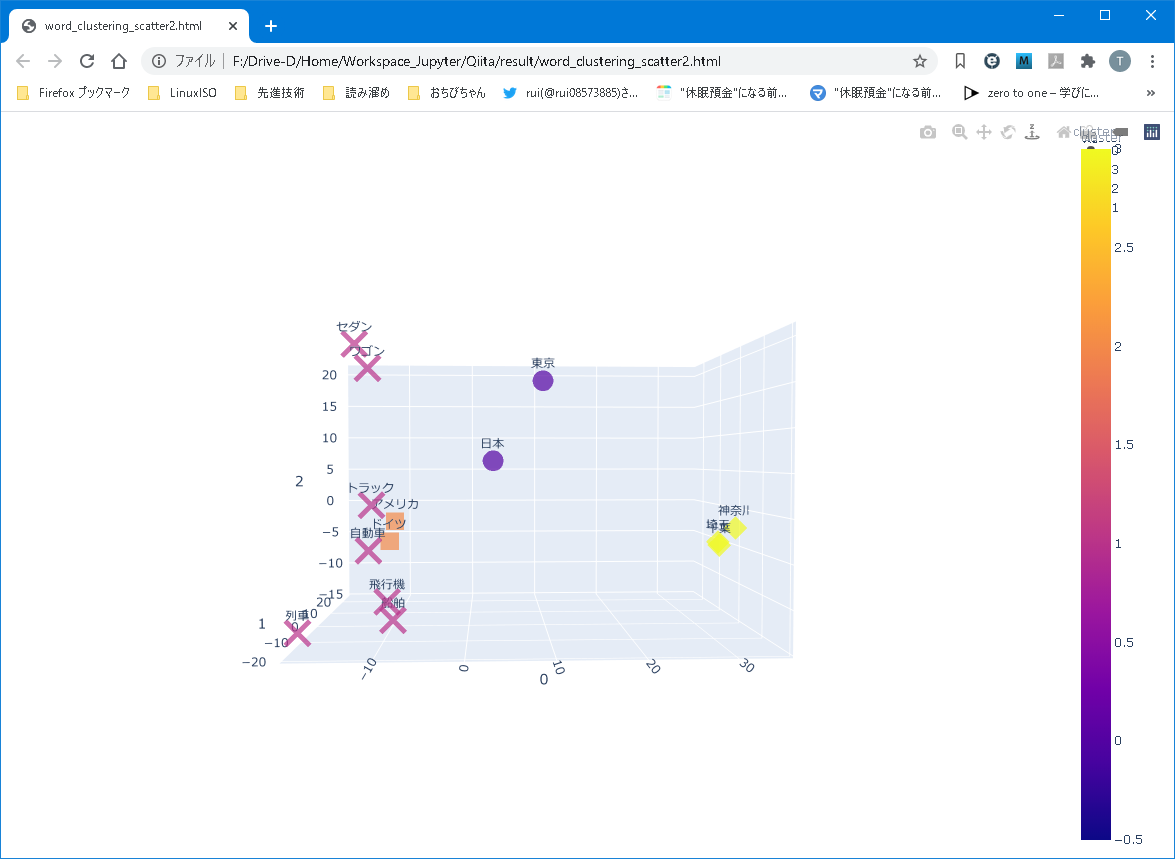
Plotly、非常に強力ですね。
3D散布図を取り上げましたが、それ以外の利用にも対応した、汎用的なグラフ化ツールです!!!
ちなみに
word2vecモデルでも単語の類似度はどうなっているかと言うと、、、以下の通りでした。
多次元ベクトル空間上でも、”東京”は3都市に比べて、”日本”の方が類似度が高くなっていました。
$ model.wv.similarity('東京', '日本')
0.329558
$ model.wv.similarity('東京', '神奈川')
0.2497174
$ model.wv.similarity('東京', '千葉')
0.25432715
$ model.wv.similarity('東京', '埼玉')
0.21400008
まとめ
word2vecモデル(多次元ベクトル)のクラスタリング結果を可視化する手法、3次元空間上に散布図を描画する方法を紹介。