はじめに
去年から,量子機械学習の研究をすることになった学生です.今回,量子CNNに関する論文調査で気になった論文があったため,内容をまとめつつコードを書いてみることにしました.
論文のリンク:https://arxiv.org/pdf/2304.09224
論文の概要
Quantum machine learning for image classification [A.Senokosov+, Machine Learning: Science and Technology'24] では,HQNN-ParallelとHQNN-Quanvという2種類の手法が提案されています.
-
HQNN-Parallel(並列量子層を持つHQNN)
- 構成
- 古典的な畳み込み層で特徴抽出
- その後に複数の並列パラメータ化量子回路 (PQC)を配置
- 各量子層の出力を統合して全結合層で分類
- 構成
-
HQNN-Quanv(量子畳み込み層を持つHQNN)
- 構成
- 量子回路を畳み込み演算に利用
- 測定結果から特徴マップを生成
- 構成
今回は,HQNN-Quanvについてまとめます.
HQNN-Quanv
HQNN-Quanvは,入力画像に対し量子回路で実装されたカーネル(Quanvolutional層)で畳み込み処理を行い,測定結果を古典的な全結合層に入力して分類を行うモデルです.
本論文ではHQNN-Quanvと比較するための古典CNN (CNN1, CNN4) により,MNIST ($14\times14$にリサイズ)において性能が比較されています.比較対象のCNN1はHQNN-Quanvと同じパラメータ数を持ち,CNN4は4倍のパラメータ数を持ちます.
以下にモデル構造の流れを簡単に示します.
- Quanvolutional層
- 特徴マップ生成
- Flatten
- 全結合層
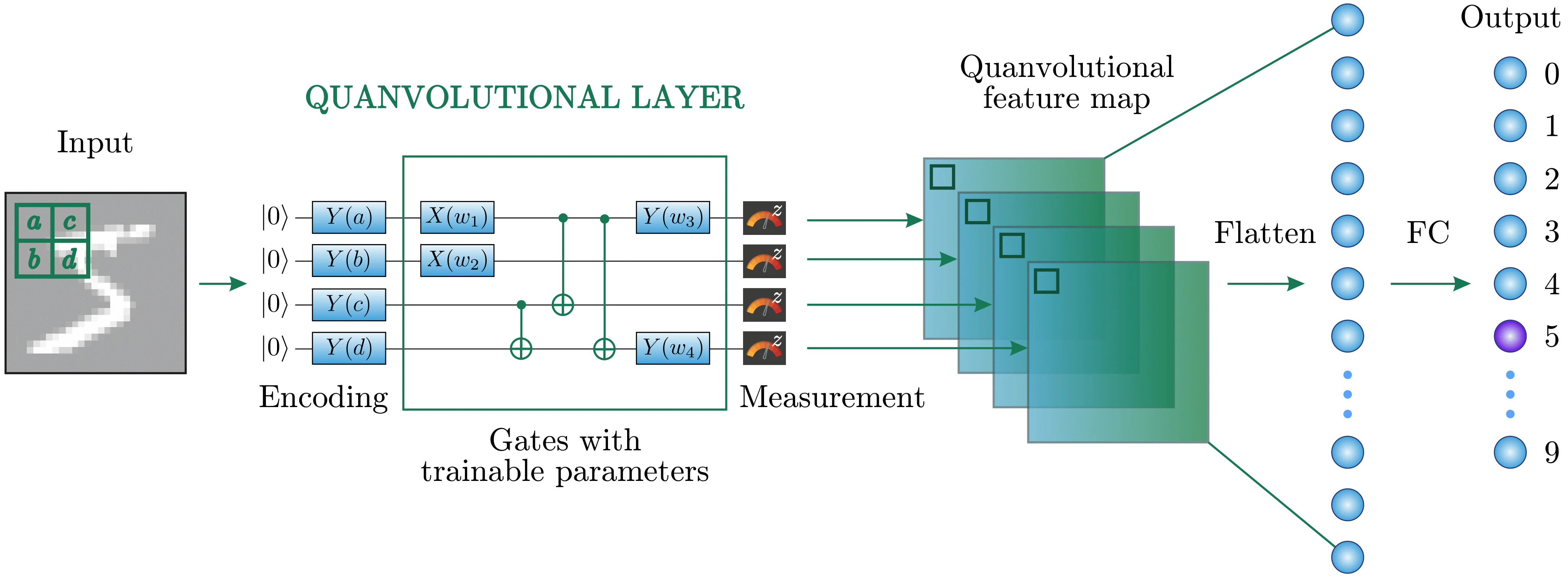
Quantum machine learning for image classification [A.Senokosov+, Machine Learning: Science and Technology'24]
上図がモデルの全体像です.この図にあるQuanvolutional層と特徴マップの生成について解説します.
Quanvolutional層
この層では,入力画像($14\times14$にリサイズ)に対し,量子回路で実装されたカーネル ($2\times2$) が畳み込み処理を行います.以下に流れを示します.
- Angle Embeddingにより量子状態にエンコード.このとき,$|0\rangle$で初期化された量子ビットを画素値に対応する角度だけブロッホ球上でY軸方向に回転
- 量子回路を適用し,畳み込み処理を実行
- パウリZ演算子により量子ビットを測定(測定結果は-1~1の範囲に収まる)
Quanvolutional層に実装されている回路では,RXゲートとRYゲートのパラメータがモデルの学習により最適化されます.
特徴マップ生成
量子回路の各量子ビットから測定値を得ることで,4つの異なる特徴マップ(今回は$4\times4$ピクセル)が生成されます.
PennyLaneとPyTorchによる実装
実験条件は以下の通りとなっています.
| 項目 | 条件 |
|---|---|
| 損失関数 | Cross Entropy Loss |
| 最適化手法 | Adam |
| エポック数 | 20 |
| バッチサイズ | 4 |
| 学習率 | 0.001 |
| データセット | MNIST |
| 訓練用 | 500枚 |
| テスト用 | 100枚 |
コード
古典CNN
CNN1
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Subset
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
#--- パラメータ設定 ---#
n_epochs = 20 # エポック数
batch_size = 4 # バッチサイズ
n_train = 500 # 訓練データ数
n_test = 100 # テストデータ数
lr = 0.001 # 学習率
image_size = 14 # 画像サイズ
#--- 乱数シードの固定 ---#
torch.manual_seed(42)
np.random.seed(42)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
#--- デバイス設定 ---#
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
#--- データセットの準備 ---#
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
])
train_data = torchvision.datasets.MNIST(root='../../../data', train=True, download=True, transform=transform)
test_data = torchvision.datasets.MNIST(root='../../../data', train=False, download=True, transform=transform)
train_data = Subset(train_data, range(n_train))
test_data = Subset(test_data, range(n_test))
#--- データローダーの作成 ---#
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
#--- CNN1のモデル定義 ---#
class CNN1(nn.Module):
def __init__(self):
super(CNN1, self).__init__()
self.conv1 = nn.Conv2d(1, 4, kernel_size=2, stride=4)
self.fc1 = nn.Linear(4 * 4 * 4, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
model = CNN1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
#--- 訓練と評価 ---#
for epoch in range(n_epochs):
start_time = time.time()
#--- 訓練モードに設定 ---#
model.train()
running_loss = 0.0
train_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = correct_train / total_train
#--- テストモード ---#
model.eval()
test_loss = 0.0
correct_test = 0
total_test = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_test += labels.size(0)
correct_test += (predicted == labels).sum().item()
test_loss = test_loss / len(test_loader)
test_acc = correct_test / total_test
end_time = time.time()
epoch_duration = end_time - start_time
print(f'Epoch [{epoch+1}/{n_epochs}], Train Acc: {train_acc:.4f}, Train Loss: {train_loss:.4f}, Test Acc: {test_acc:.4f}, Test Loss: {test_loss:.4f}, Time: {epoch_duration:.2f}s')
CNN4
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Subset
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
#--- パラメータ設定 ---#
n_epochs = 20 # エポック数
batch_size = 4 # バッチサイズ
n_train = 500 # 訓練データ数
n_test = 100 # テストデータ数
lr = 0.001 # 学習率
image_size = 14 # 画像サイズ(14x14 MNIST)
#--- 乱数シードの固定 ---#
torch.manual_seed(42)
np.random.seed(42)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
#--- デバイス設定 ---#
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
#--- データセットの準備 ---#
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
])
train_data = torchvision.datasets.MNIST(root='../../../data', train=True, download=True, transform=transform)
test_data = torchvision.datasets.MNIST(root='../../../data', train=False, download=True, transform=transform)
train_data = Subset(train_data, range(n_train))
test_data = Subset(test_data, range(n_test))
#--- データローダーの作成 ---#
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
#--- CNN4のモデル定義 ---#
class CNN4(nn.Module):
def __init__(self):
super(CNN4, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=2, stride=4)
self.fc1 = nn.Linear(256, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
model = CNN4().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
#--- 訓練と評価 ---#
for epoch in range(n_epochs):
start_time = time.time()
#--- 訓練モードに設定 ---#
model.train()
running_loss = 0.0
train_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader) if len(train_loader) > 0 else 0.0
train_acc = correct_train / total_train if total_train > 0 else 0.0
#--- テストモード ---#
model.eval()
test_loss = 0.0
correct_test = 0
total_test = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_test += labels.size(0)
correct_test += (predicted == labels).sum().item()
test_loss = test_loss / len(test_loader) if len(test_loader) > 0 else 0.0
test_acc = correct_test / total_test if total_test > 0 else 0.0
end_time = time.time()
epoch_duration = end_time - start_time
print(f'Epoch [{epoch+1}/{n_epochs}], Train Acc: {train_acc:.4f}, Train Loss: {train_loss:.4f}, Test Acc: {test_acc:.4f}, Test Loss: {test_loss:.4f}, Time: {epoch_duration:.2f}s')
HQNN-Quanvの量子回路
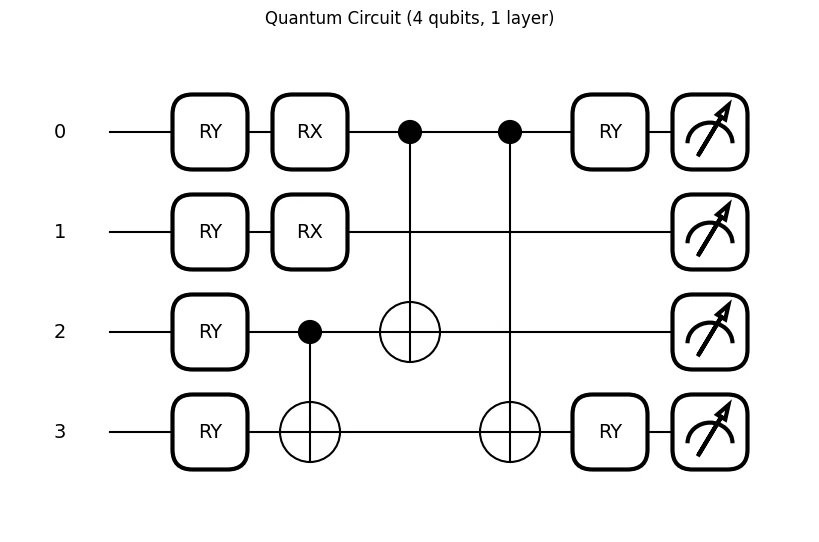
論文に記載されている量子回路をそのまま実装しました.
import pennylane as qml
from pennylane import numpy as np
n_weights = 4 # 各層のパラメータ数
def quanv_circuit(weights, wires):
num_qubits = len(wires) # 使用する量子ビット数
num_layers = len(weights) # 回路を繰り返す層の数
for l in range(num_layers):
layer_weights = weights[l] # 各ゲートのパラメータ
# qubit0: RX
qml.RX(layer_weights[0], wires=wires[0])
# qubit1: RX
qml.RX(layer_weights[1], wires=wires[1])
# CNOT: control=qubit2, target=qubit3
qml.CNOT(wires=[wires[2], wires[3]])
# CNOT: control=qubit0, target=qubit2
qml.CNOT(wires=[wires[0], wires[2]])
# CNOT: control=qubit0, target=qubit3
qml.CNOT(wires=[wires[0], wires[3]])
# qubit0: RY
qml.RY(layer_weights[2], wires=wires[0])
# qubit3: RY
qml.RY(layer_weights[3], wires=wires[3])
回路の可視化結果です.RYゲートによるAngle Embeddingと測定以外が実装した部分となっています.CNOTゲートの位置が異なりますが,表示上の問題で実行には問題ありません.
メインコード
import pennylane as qml
from pennylane import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader, Subset
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import time
from pqc import quanv_circuit, n_weights
#--- パラメータ設定 ---#
n_epochs = 20 # エポック数
n_layers = 1 # 層数
n_train = 500 # 学習データ数
n_test = 100 # テストデータ数
batch_size = 4 # バッチサイズ
lr = 0.001 # 学習率
filter_size = 2 # フィルタサイズ
num_qubit = filter_size**2 # 使用する量子ビット数
image_size = 14 # リサイズ後の画像サイズ
#--- 乱数シードの固定 ---#
np.random.seed(42)
torch.manual_seed(42)
#--- デバイス設定 ---#
device = torch.device("cpu")
dev = qml.device("default.qubit", wires=num_qubit)
#--- データセットの準備 ---#
transform = transforms.Compose([
transforms.Resize(image_size), # 14x14にリサイズ
transforms.ToTensor(),
])
train_data = torchvision.datasets.MNIST(root='../data', train=True, download=True, transform=transform)
test_data = torchvision.datasets.MNIST(root='../data', train=False, download=True, transform=transform)
train_data = Subset(train_data, range(n_train))
test_data = Subset(test_data, range(n_test))
#--- Dataloaderの作成 ---#
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
#--- 量子回路の定義 ---#
@qml.qnode(dev, interface='torch', diff_method='backprop') # QNodeの定義
def circuit(inputs, weights):
qml.AngleEmbedding(inputs, wires=range(num_qubit), rotation='Y') # データのエンコーディング
quanv_circuit(weights, wires=range(num_qubit)) # 量子畳み込み回路の適用
return [qml.expval(qml.PauliZ(wires=i)) for i in range(num_qubit)] # 各量子ビットのZ測定値を返す
#--- 量子畳み込み処理 ---#
def quanv(image, weights):
batch_size = image.shape[0]
out = torch.zeros((batch_size, 4, 4, 4))
for i in range(batch_size):
for j in range(0, 14, 4):
for k in range(0, 14, 4):
q_results = circuit(
[
image[i, 0, j, k] * np.pi,
image[i, 0, j, k + 1] * np.pi,
image[i, 0, j + 1, k] * np.pi,
image[i, 0, j + 1, k + 1] * np.pi
],
weights
)
for l in range(num_qubit):
out[i, l, j // 4, k // 4] = q_results[l]
return out
#--- 量子畳み込み層の定義 ---#
class QuanvLayer(nn.Module):
def __init__(self):
super(QuanvLayer, self).__init__()
self.weights = nn.Parameter(
torch.from_numpy(np.random.uniform(0, 2*np.pi, (n_layers, n_weights))).float()
)
def forward(self, input):
expectation_z = quanv(input, self.weights)
x = expectation_z.to(device)
return x
#--- モデル定義 ---#
class HybirdCNN(nn.Module):
def __init__(self):
super(HybirdCNN, self).__init__()
self.qconv = QuanvLayer()
self.fc1 = nn.Linear(4 * 4 * 4, 10)
def forward(self, x):
x = self.qconv(x)
x = torch.flatten(x, start_dim=1)
out = F.relu(self.fc1(x))
return out
hybridcnn = HybirdCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(hybridcnn.parameters(), lr=lr)
#--- 訓練と評価 ---#
for epoch in range(n_epochs):
start_time = time.time()
#--- 訓練モード ---#
hybridcnn.train()
running_loss = 0.0
correct_train = 0
total_train = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = hybridcnn(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.detach().item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_acc = correct_train / total_train
#--- テストモード ---#
hybridcnn.eval()
test_loss = 0.0
correct_test = 0
total_test = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = hybridcnn(inputs)
loss = criterion(outputs, labels)
test_loss += loss.detach().item()
_, predicted = torch.max(outputs.data, 1)
total_test += labels.size(0)
correct_test += (predicted == labels).sum().item()
test_loss = test_loss / len(test_loader)
test_acc = correct_test / total_test
end_time = time.time()
epoch_duration = end_time - start_time
print(f'Epoch [{epoch+1}/{n_epochs}], train_acc: {train_acc:.4f}, train_loss: {train_loss:.4f}, test_acc: {test_acc:.4f}, test_loss: {test_loss:.4f}, time: {epoch_duration:.2f} sec')
結果
今後,記載する予定です.