はじめに
Cognitive Servicesでは、様々なAPIが提供されていますが、今回はそのうちの「Speaker Recognition API」にて話者識別を試してみました。
(日本ではあまり流行ってないっぽいですが。。)
ちなみに話者識別とは「いま誰が話しているのか」を識別してくれるもので、試した感じ、なかなかの精度かも。。と感じました。(まぁ自分の声でしか試してないんですけどね)
という訳で、早速検証していきたいと思います!
事前準備
まずはAzureにリソースを準備していきます。
Azureにログインして「リソースの作成」をクリックします。

画面左上の検索boxに Speaker Recognition と入力します。

以下の画面で「作成」をクリックします。
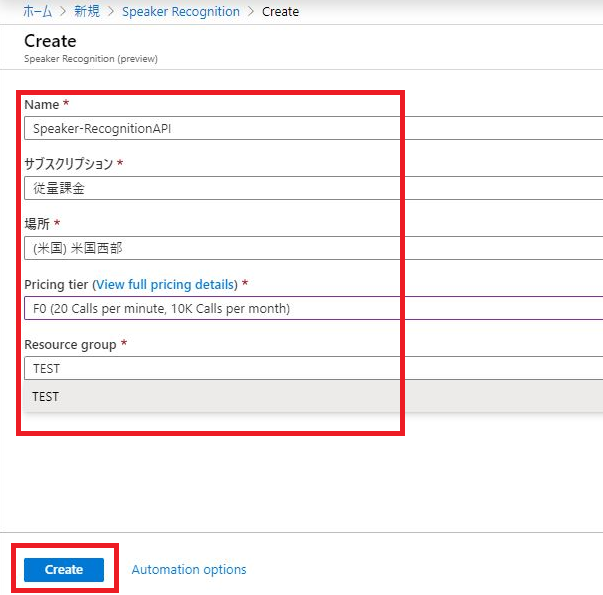
作成画面に移動するので、各項目を入力していきます!
ちなみにF0だと10,000 無料トランザクション / 月とのこと(検証には十分ですね)
入力が完了したら、画面下部の「Create!」をクリックします。
リソースのデプロイが完了したので、「リソースに移動」をクリックします。
サブスクリプションキーが表示されました。
これは後で使うので、コピーボタンを押して保管しておきます!
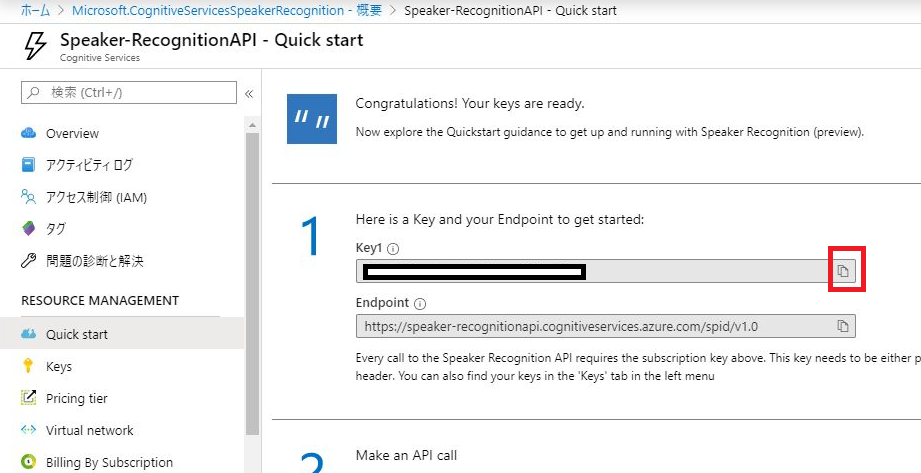
これでSpeaker Recognition APIを使用する準備が整いました。
見づらくなりそうなので、実際の処理は次の記事に記載します!
次の記事(実際の検証)
Azure CognitiveServicesのSpeakerRecognition APIによる話者識別をPythonで検証してみた。#2