はじめに
こんな記事書いてる人です。
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり2/28
【毎秒1万リクエスト!?】Go言語で始める爆速Webスクレイピング【Golang】
スクレイピングが大好きで、スクレイピングするためにAWSやVPS、Docker、サーバーレスなどなど1から勉強したりする人です。(もちろん遊びの範囲で)
今回はそんな毎日スクレイピングしている自分がされたら嫌だなぁって思う現実的なスクレイピング対策を教えます。(Flash使えばいいじゃんとか極論はNG)
※この記事はスクレイピングの対策であって、SEO的に不利になったりすることもあります。ご注意を
趣味で一つのVPS環境で複数のドメイン・サイトを管理できるCMSを作ったりもしてます。
1 サイトマップ・RSSフィードを公開しない
なんでサイトマップの公開がいけないかってのは、スクレイピングは基本的にタグ等の位置を指定してから値を取得するのですが、このサイトマップやRSSフィードがあると楽にスクレイピングできちゃいます。
例えば、新しいURL追加されていればサイトが更新されたかと新しく追加されたページのURLがわかります。
RSSフィードだったりすると、URLはもちろんタイトル、抜粋、カテゴリなどなどの情報も簡単に取得できますし、型が決まっているのでフィードのタイプをどのような形式に変更されてもライブラリがいい感じ読み込んでくれるので最初の開発も楽、そしてメンテが不要なんです。大変お世話になっています。
とはいえ公開しないってのは語弊があって、誰にでもぽんぽん見せるべきではないって意味です。
Google Search Consoleにはサイトマップを教えてあげないとクローリングをあんまりしてくれなかったりするのでサイトマップ自体を無くすのではなく、見るべき者だけが見られるようにしましょう。
ポイント
サイトマップのURLをデフォルトのままで使用しない
/sitemap.xml
/sitemaps.xml
など簡単に推測できるような文字列で管理するのではなく
/saitomap.xml
/sitemap-qwertyuiopasdfghjklzxcvbnm.xml
のように簡単には文字列から推測できないようにファイル名を変更したりすると意外と良かったりします。
HTMLのHeadにRSSのURLを記載しない
HTMLのHeadにこのような要素が基本的にどんなウェブサイトでもあります。
<link rel="alternate" type="application/rss+xml" title="あずにゃんペロペロ日記 » フィード" href="https://azunyan1111.com/feed/">
はい、一瞬でRSSを覗かれます。
パクられやすいジャンルのサイト群約3000をスクレイピングしてこの要素が存在しているか確認したところ、98%のウェブサイトでこの要素がありました。
おかげで簡単にパクリサイトを作ることができます。
サイトマップも同様に乗せないようにしましょう。
クローラー以外はブロックする(意外と重要)
グーグルのクローラーの場合ユーザーエージェントは公開されてます。
Google クローラ
これらのユーザーエージェント意外のユーザーエージェントの場合は403なり404なりを返すなどしてブロックしましょう。
そこの君!ユーザーエージェントなんて簡単に変えられるから無意味とか言ってると足元をすくわれるよ
こういったURLはスクレイピングする人が直接ブラウザからアクセスして存在を確認してからプログラムに落とし込んでいく場合が多い。
そこでクローラー以外からは404を返すようにすればそもそも存在してないとスクレイピングする人を騙すこともできるかもしれない。
meta要素で何でもかんでも教えない
ここら辺はSEOとかも関わってくるのできわどい所です。
私が言っているmeta要素とはどういうことか、例えば今編集しているQiitaのHeadに書いてあるmeta要素を見てみましょう。
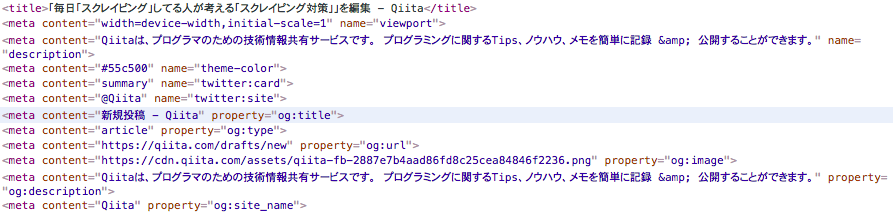
この画像の例えばプロパティがog:imageの所にはQiitaのロゴマークが入ってますが、基本的にWordpressなどのCMSを使っているとアイキャッチ画像のURLが入ってきます。
これもまたタグを指定することなくアイキャッチ画像のURLを取得することができます。
他にも下記のような者があればタグの位置を指定する必要がなくなります。
<meta property="og:description" content="記事の概要" />
<meta name="keywords" content="キーワードA,キーワードB,キーワードC" />
keywordsは区切ればカテゴリーにもつながります。
RSSを公開してなくてもサイトマップとmeta要素があるだけでRSSと同等・それ以上の情報が入手できたりしちゃったりするんです。
CSSのIDやclassは定期的に名前を変える&タグの囲い方にも気を付ける
スクレイピングする時に基本的にcssセレクターを使ってスクレイピングします。
例えば、重要な値114514がこのようなHTML<div>日経平均株価<p id="yajusenpai">114514</p>円</div>で表示されていた場合スクレイピングする人は#yajusenpaiと入力するだけで簡単に重要な値を取得出来ます。
もし、idが無かったとしてもこのサイトにp要素が一つしか無かった場合findAll("p")で全てのp要素を抽出してやれば重要な値を取得出来ます。
なのでこれを<div>日経平均株価114514円</div>みたいにすればやりにくくなったりします。
デザインはデザイナーと相談してください。
JavaScriptを使ってサイトをレンダリングする
詳しくは知らないですが、SPAなどに使われるreactだったりでブラウザで動的に要素を追加したりするとスクレイピングする側はSeleniumだったりChromeのヘッドレスを使わないといけなかったり何かと面倒です。
Selenium環境をVPSとかに構築するのは割と面倒です。やってみてください。
画像などの外部ファイルはリファラを使って直リンクを阻止(超重要)
.htaccessやnginxの設定などを使えば自分のドメイン意外からのアクセスをブロックすることが出来ます。
これが本当に超重要なんです。
例えばオリジンがazunyan1111.comでコピペサイトがyajusenpai.comだった場合
直リンクが可能な状態だと
<img src="//azunyan1111.com/prpr.jpg">
みたいな要素の場合
このタグをyajusenpai.comにそのまま張り付けるだけで画像が表示されます。
さらに悪質なことに、ブラウザの仕組み上yajusenpai.comにアクセスしているにもかかわらずazunyan1111.comから画像をダウンロードしているのです。
これだと自分のサイトアクセスが一つも来てないのにパクった人の画像配信処理を肩代わりすることになります。
面倒ですが、これを設定するとyajusenpai.comには画像が表示されなくなり、yajusenpai.comは文字列だけの醜いサイトになり効果的な一撃となります。
PubSubHubbub/WebSubを使って我こそが最初の発信者と自己主張する
Wordpressを導入していたらWebSub/PubSubHubbub なるプラグインを導入すれば簡単に実装が可能です。
これ使うとどうなるかというと、検索エンジンに新しい記事配信したから見に来てとお知らせするものだが
全く同じ記事が別のサーバーで配信されていた場合どちらを本物のコンテンツ配信者と見極めるかはどちらが早く配信したかで決まります。(投稿した時刻ではなく、WebSub or クーリングで検索エンジンが記事を発見した時刻)
つまり、WebSubを導入してないオリジナルサイトよりWebSubを導入しているパクリサイト方を本物のコンテンツ配信者は見る場合もあります。
コンテンツの中身を観覧する場合CAPTCHAをさせる
ユーザーの利便性を欠いてまでスクレイピングされたくないのであればどうぞ
ブラウザが開発者モードになるとデバックスクリプトみたいなのが走る奴を使う。
自分も詳しくは知りませんが、某ビデオ配信サイトで開発者モードを開くとデバッグモードらしき物が走り出してセレクターが使いにくかったりNetworkタブを見にくくしたりとすごい妨害工作をするサイトです。
jsとかブラウザの仕様に詳しくないので解説は出来ませんがそういったサイトもあります。
DVDに付いてる規則的な文字列をそのまま検索にかけると大体そのサイトが出てきます。
得意な人は解説しろください。
対策したら検索エンジンからクローリングされないし収益下がったんだけど!?(半ギレ)
実は別にHTML内部にサイトマップやrss情報を入れなくてもクローリングはされます。
WebSubを送れば検索エンジンは一瞬で飛んできますし、sitemapをping送信すれば数分から数時間で飛んでやってきます。
具体的な方法は仕様書みたいなのがあるのでそれに沿ってコーディングすれば私と簡単に出来ます。
Wordpressなんかだと機能やプラグインでクリックだけで出来るからうらやましい。
ぶっちゃけ言えとスクレイピング対策なんてしなくていい
Googleがよく言うのはそういう面倒なところはウチがやるからキミ達は質の高いコンテンツを配信しろって奴
あれを信じて質の高いコンテンツを作れば大丈夫です。
ぶっちゃけ言うけど、スクレイピングサイトなんて儲からないしお金にならない。
コスパが悪い。
すんごい頑張ってスクレイピングしても1円2円くらいしか儲からない。
専業でガチでやれば月収数十万とか行くかもしれないけど、それができる人は別の仕事も出来る人であって全員ではない。
そんなんだったら業務委託とか受けてフリーランスとかしたほうが100%儲かるしスキル付く。
そんなことねーし!儲かってるし!って人へ
無職なので雇ってください。
もっといい対策あるよ
コメント or 編集リクエストしてください。
コメントの内容も追記
TakaakiFuruseさん
かなり具体的な対策のコメントありがとうございます。
いくつかありますが、個人的にGoodな奴をピックアップします。
データをPDFで提供する
これはなかなか強力です。
excelだったりwordだったりすると割と簡単にコピペ出来ますが、PDFだと普通にコピペしただけなのに変な空白が入っていたり、文字化けが発生したりとしんどいです。
ExcelやWordで作った資料を別のバージョンのExcelやWordに読み込ませてPDF出力とかするとお手軽アンパッカーみたいになるとか・・・聞いた話なので分かりません。.doc→PDF.doc→PDFみたいに変換しまくったら見た目は変わらなくても内部でゴニョゴニョ変わってコピペ出来なくなるとかならないとか。暇な人調べてみてください。
グラフは画像で
グラフに限らず可能な限りらず、なんでも画像に置き換えたらスクレイピングしにくくなります。
かなり手間ですけどね。。。
とはいえ、OCRを使えばある程度は読めちゃうので油断は禁物です。
Google翻訳の画像翻訳のOCRの精度は凄まじいですね。
無料でGoogle docsとかで使えるとか
Yougurutさん→再現性を低くする。
これもなかなか有効です。
例えば、値114514を表示する時に次のいずれかの方法で出力したり
<div>日経平均株価<b>114514<\b></div>
<div>日経平均株価<span>114514<\span></div>
<div>日経平均株価<div id="yaju">114514<\div></div>
または、カンマを入れる場合と入れない場合や空白を用意したり
<div>日経平均株価<b>114514<\b></div>
<div>日経平均株価<b>114,514<\b></div>
<div>日経平均株価<b>114 514<\b></div>
全てをランダムでやるのも良いですが、再現性低くするために
<b>の場合が一般的だな10%の確率で<span>、5%の確率で<div>になるのも有効です。
スクレイピングする人が開発している時に再現性がなかったら「今さっきは動いたのに今回は動かなかった。あれ?なんでだ?コードも変えて無いぞ?」みたいな状況に陥らせることができます。
割とコスパの高い対策方法で、例えば複数のパターンで相手を混乱させることができます。組み合わせの数だけパターンがあるってことですね。