概要
前回の記事では単一の映画.comから選んだ映画のレビューや評価値を取得する方法を紹介しました.スクレイピングの解説をという意見があったので,解説を多めにしました.
今回は,映画のレビューを入手できるURLの一覧を取得する方法を紹介します1.闇雲に映画のリストを取得するのも大変ですので,映画.comのalltime-bestからタイトルのURLリストを抽出したいと思います.
最終的に次のような形のレビューや評価値などの詳細データを入手できるURLのCSVファイルを取得することを目標とします.
review_url
0 https://eiga.com/movie/41841/review/
1 https://eiga.com/movie/56301/review/
2 https://eiga.com/movie/5134/review/
3 https://eiga.com/movie/6279/review/
4 https://eiga.com/movie/43303/review/
5 https://eiga.com/movie/45293/review/
6 https://eiga.com/movie/15376/review/
alltime-bestのページでは,年代ごとに代表的な映画が掲載されています.おすすめの映画を探すには適していると言えます.
ALLTIME BESTについて
「映画.com ALLTIME BEST」は、映画.comスタッフ・映画.comに寄稿いただいている映画評論家の方々のセレクト・映画.comユーザーのレビューや5つ星スコアなどを総合し、「いつ見ても素晴らしい、時代を超えて愛される名作映画」1200本を選出したものです。
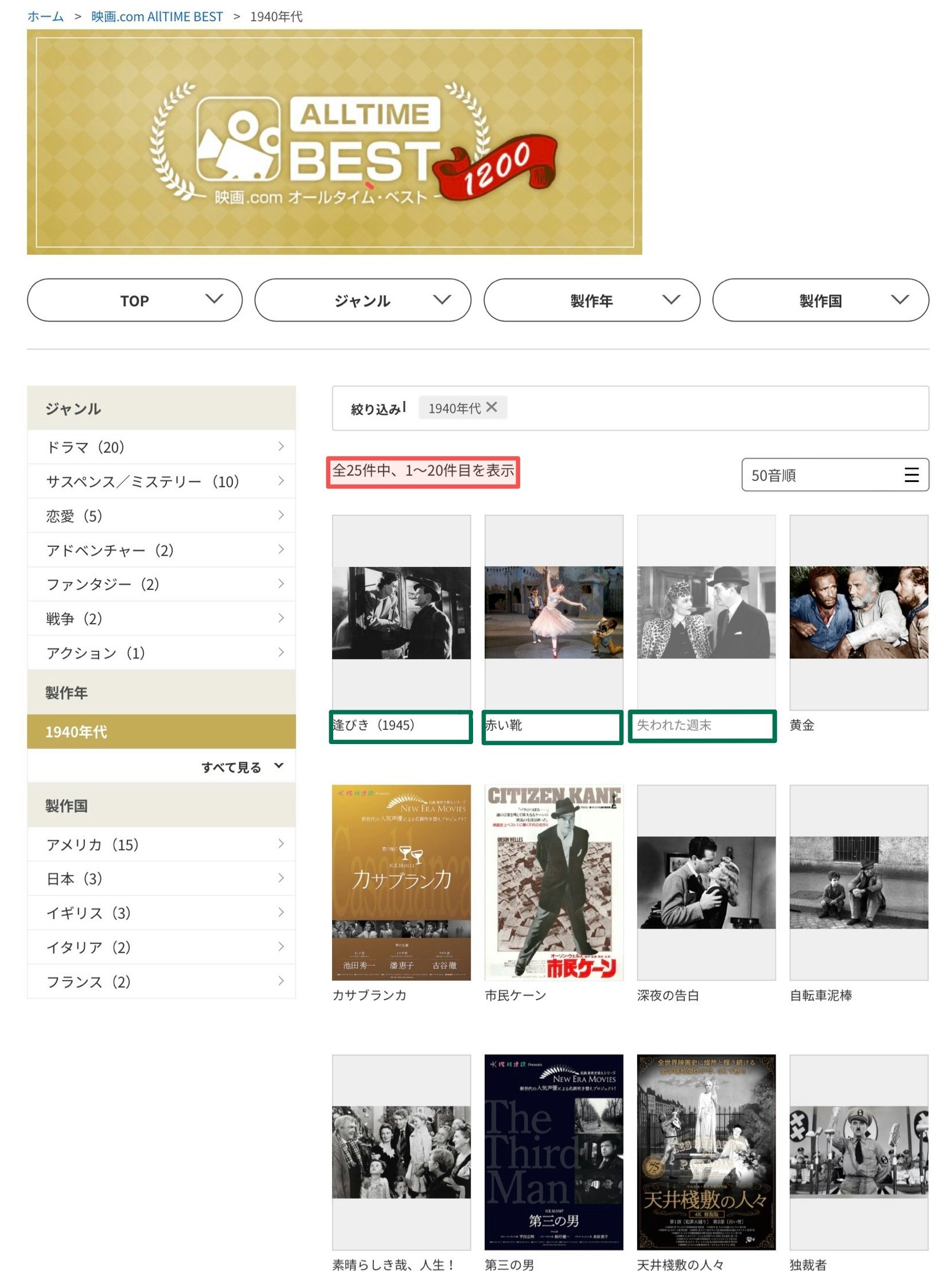
公式にある説明の通りで,alltime-bestの映画情報は,興味ある映画をお薦めする「推薦システム」の練習に良さそうなデータとなりそうです.この記事では,1940年代の映画レビューのURLを具体例に用いて,スクレイピングの方法を紹介します.実際のページの様子は下図のようになっています.レジェンドクラスの映画が,画像とともに整然と並んでいます.例として最初の3つを緑色で囲んでいます.表示されている映画のURLをすべて取得するのが今回の主要なテーマとなります.
記事で利用するライブラリ
利用するライブラリ
pip install beautifulsoup4
pip install requests
pip install lxml
記事で利用するbeautifulsoupの基本的なメソッド
find(): タグと属性の条件に一致する要素を1つ探す
find_all() : タグと属性の条件に一致する全ての要素をリストにする
select() : CSSセレクタで指定された条件に一致する全ての要素をリストにする
get() : 属性の値を抽出する
1. Webページデータの取得
最初に,1940年代のHTMLを取得して,構造を簡単に把握します.前回の記事同様,requestsとBeautifulSoupを利用します.
import requests
from bs4 import BeautifulSoup
url = "https://eiga.com/alltime-best/results/?y=1940" # 1940年代
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
soupを表示すると,Webブラウザーでページのソースを表示させたときと同様,横に長いテキストになります.
<!DOCTYPE html>
<html lang="ja"> <head> <meta content="ie=edge" http-equiv="x-ua-compatible"/> <meta content="width=1060" name="viewport"/> <meta charset="utf-8"/> <title>映画.com ALLTIME BEST : 1940年代</title> <meta content="「映画.com ALLTIME BEST」は、映画.comスタッフ・映画評論家のセレクトとユーザーレビューなどを総合し、「いつ見ても素晴らしい、時代を超えて愛される名作映画」1200本を選出したものです。" name="description"/>...
わかりにくいので,コードを整形してくれるエディターか,オンラインのHTML Formatterを利用して見た目を綺麗にしてみます.
<!DOCTYPE html>
<html lang="ja">
<head>
<meta content="ie=edge" http-equiv="x-ua-compatible" />
<meta content="width=1060" name="viewport" />
<meta charset="utf-8" />
<title>映画.com ALLTIME BEST : 1940年代</title>
<meta content="「映画.com ALLTIME BEST」は、映画.comスタッフ・映画評論家のセレクトとユーザーレビューなどを総合し、「いつ見ても素晴らしい、時代を超えて愛される名作映画」1200本を選出したものです。" name="description" />
~~~ 中略 ~~~
<div id="resut_title_area">
<div id="result_title_header">
<p id="result_count">全25件中、1~20件目を表示</p>
<div class="dropdown">
<div class="select"> <span>50音順</span> </div>
<ul class="dropdown-menu">
<li data-url="/alltime-best/results/?so=kana&y=1940">50音順</li>
<li data-url="/alltime-best/results/?so=checkin&y=1940">Check-in数が多い</li>
<li data-url="/alltime-best/results/?so=checkin_asc&y=1940">Check-in数が少ない</li>
<li data-url="/alltime-best/results/?so=year&y=1940">製作年が新しい</li>
<li data-url="/alltime-best/results/?so=year_asc&y=1940">製作年が古い</li>
</ul>
</div>
</div>
<div id="result_contents">
<ul class="clearfix">
<li><a href="/movie/41841/"> <span><img alt="逢びき(1945)" loading="lazy" src="https://eiga.k-img.com/images/movie/41841/photo/3d99bebbf6f00684.jpg?1396887720"/></span> <span>逢びき(1945)</span> </a></li>
<li><a href="/movie/56301/"> <span><img alt="赤い靴" loading="lazy" src="https://eiga.k-img.com/images/movie/56301/photo/e1a90c6515d6d3be.jpg?1396887076"/></span> <span>赤い靴</span> </a> </li>
<li><a href="/movie/5134/"> <span><img alt="失われた週末" loading="lazy" src="https://eiga.k-img.com/images/movie/5134/photo/e3ef6426291591e6.jpg?1593652028"/></span> <span>失われた週末</span> </a> </li>
<li><a href="/movie/6279/"> <span><img alt="黄金" loading="lazy" src="https://eiga.k-img.com/images/movie/6279/photo/c966fd49bc205e0f.jpg?1593992989"/></span> <span>黄金</span> </a> </li>
<li><a href="/movie/43303/"> <span><img alt="カサブランカ" loading="lazy" src="https://eiga.k-img.com/images/movie/43303/photo/afcd7f922e7381d9.jpg?1618300590"/></span> <span>カサブランカ</span> </a> </li>
<li><a href="/movie/45293/"> <span><img alt="市民ケーン" loading="lazy" src="https://eiga.k-img.com/images/movie/45293/photo/ca55afc303860948.jpg?1469168017"/></span> <span>市民ケーン</span> </a> </li>
<li><a href="/movie/15376/"> <span><img alt="深夜の告白" loading="lazy" src="https://eiga.k-img.com/images/movie/15376/photo/d6a7689238d89f81.jpg?1589886306"/></span> <span>深夜の告白</span> </a> </li>
<li><a href="/movie/45253/"> <span><img alt="自転車泥棒" loading="lazy" src="https://eiga.k-img.com/images/movie/45253/photo/b5562438a29a8691.jpg?1417169983"/></span> <span>自転車泥棒</span> </a> </li>
<li><a href="/movie/16876/"> <span><img alt="素晴らしき哉、人生!" loading="lazy" src="https://eiga.k-img.com/images/movie/16876/photo/2b78e85df062f961.jpg?1396889534"/></span> <span>素晴らしき哉、人生!</span> </a> </li>
<li><a href="/movie/46413/"> <span><img alt="第三の男" loading="lazy" src="https://eiga.k-img.com/images/movie/46413/photo/eab56ddd73c6e95d.jpg?1597814308"/></span> <span>第三の男</span> </a> </li>
<li><a href="/movie/47114/"> <span><img alt="天井棧敷の人々" loading="lazy" src="https://eiga.k-img.com/images/movie/47114/photo/459b33c11efc33d5.jpg?1599031632"/></span> <span>天井棧敷の人々</span> </a> </li>
<li><a href="/movie/46767/"> <span><img alt="独裁者" loading="lazy" src="https://eiga.k-img.com/images/movie/46767/photo/828d48d219ac02ef.jpg?1664868531"/></span> <span>独裁者</span> </a> </li>
<li><a href="/movie/23193/"> <span><img alt="野良犬" loading="lazy" src="https://eiga.k-img.com/images/movie/noposter.png?1659325570"/></span> <span>野良犬</span> </a> </li>
<li><a href="/movie/47804/"> <span><img alt="ハイ・シェラ" loading="lazy" src="https://eiga.k-img.com/images/movie/47804/photo/ec55539ab928338e.jpg?1590399102"/></span> <span>ハイ・シェラ</span> </a> </li>
<li><a href="/movie/38932/"> <span><img alt="晩春" loading="lazy" src="https://eiga.k-img.com/images/movie/38932/photo/b4b3cdd83b84dfc8.jpg?1664179853"/></span> <span>晩春</span> </a> </li>
<li><a href="/movie/48336/"> <span><img alt="美女と野獣(1946)" loading="lazy" src="https://eiga.k-img.com/images/movie/48336/photo/99c37b9d83da8d02.jpg?1670652400"/></span> <span>美女と野獣(1946)</span> </a> </li>
<li><a href="/movie/28984/"> <span><img alt="マルタの鷹" loading="lazy" src="https://eiga.k-img.com/images/movie/noposter.png?1659325570"/></span> <span>マルタの鷹</span> </a> </li>
<li><a href="/movie/29291/"> <span><img alt="三つ数えろ" loading="lazy" src="https://eiga.k-img.com/images/movie/29291/photo/f0fffc468c77ab0c.jpg?1396887300"/></span> <span>三つ数えろ</span> </a> </li>
<li><a href="/movie/50017/"> <span><img alt="無防備都市" loading="lazy" src="https://eiga.k-img.com/images/movie/noposter.png?1659325570"/></span> <span>無防備都市</span> </a> </li>
<li><a href="/movie/30914/"> <span><img alt="醉いどれ天使" loading="lazy" src="https://eiga.k-img.com/images/movie/noposter.png?1659325570"/></span> <span>醉いどれ天使</span> </a> </li>
</ul>
<ul id="Pagination">
<li class="prev"><a href="/alltime-best/results/?page=1&y=1940">前へ</a></li>
<li><a class="active" href="/alltime-best/results/?page=1&y=1940">1</a></li>
<li><a href="/alltime-best/results/?page=2&y=1940" rel="next">2</a></li>
<li class="next"><a href="/alltime-best/results/?page=2&y=1940" rel="next">次へ</a></li>
</ul>
</div>
</div>
~~~ 以下略 ~~~
中略以降の部分に,映画タイトルやURLが記載された部分が見つかります.具体的には,
<li><a href="/movie/41841/"> <span><img alt="逢びき(1945)" loading="lazy" src="https://eiga.k-img.com/images/movie/41841/photo/3d99bebbf6f00684.jpg?1396887720"/></span> <span>逢びき(1945)</span> </a></li>
のような形の部分です.このhrefである/movie/41841/のような部分を取得することで,各映画のレビューURLを知ることができます.
2. hrefの値を取得
2種類の方法を考えてみました.
- findメソッドを使う形
- CSSセレクターを使う形
2.1. findメソッドを使う形
抽出したいhrefの値は,<div id="result_contents">の中にある<ul class="clearfix">のaタグのhrefの値であるという情報を利用して,BeautifulSoupのfindを繰り返し利用するのが第一の方法です.
- divタグのid属性がresult_contents
- ulタグのクラス属性がclearfix
という条件を使い,findで検索していきます.最後にhref部分の抽出です.すべて抽出する必要があるので,find_allを使います.
- clearfix_elementの中にある,aタグのhref部分を抽出
find_allメソッドとhref部分を抽出するためにhref=Trueのオプションを利用します.これで,aタグに一致する全ての要素がリストとして抽出されます.抽出された要素から順番にhref部分を取り出せば良いので,get("href")メソッドを利用することとなります.
以上をまとめると,以下のようになります.次のコードに登場する変数のsoupは1940年代のページのHTMLを表しています.
result_contents_element = soup.find("div", id="result_contents")
clearfix_element = result_contents_element.find("ul", class_="clearfix")
a_tag_list = clearfix_element.find_all("a", href=True)
for a_tag in a_tag_list:
print(a_tag.get("href"))
# printの例
# /movie/41841/
# /movie/56301/
# /movie/5134/
2.2 CSSセレクターを使う形
selectメソッドを利用する方法となります.抽出したいURLは,id属性の値がresult_contentsである要素のaタグ部分に相当するので,selectを利用して,一括で抽出できるはずです.例えば,
result_contents = soup.select("#result_contents a")
としてみます.soup内でid="result_contents"というIDを持つ要素を探し,その中からaタグを選択し,リストにします.selectメソッドで属性を指定している部分#result_contentsと#があるのを忘れずに.#result_contents aはid属性が"result_contents"である要素の中にあるすべての<a>要素を選択することを意味しています.
![]() aタグのhref部分には,
aタグのhref部分には,
<a href="/alltime-best/results/?page=1&y=1940">前へ
<a class="active" href="/alltime-best/results/?page=1&y=1940">1</a>
などが含まれるために,きれいに取得できません.(数行前の自信ありげな力説に![]() )
)
正規表現で/alltime-best/results/ で始まるURLのパターンを除く必要があります.(一行で終えられるという考えが甘かった!!)
- selectを利用して,result_contens a に一致する部分を抽出
- hrefの値が/alltime-best/results/で始まらない部分のみ表示
という方針でコードを記したものが次の形になります.
import re
pattern = re.compile(r'^/alltime-best/results/')
result_contents = soup.select("#result_contents a")
for link in result_contents:
if not pattern.match(link.get("href")):
print(link.get("href"))
# printの例
# /movie/41841/
# /movie/56301/
# /movie/5134/
重要な部分をfor文,if文を内包表記で無理やり1行化で記述できます.
# /alltime-best/results/ で始まるURLのパターン
pattern = re.compile(r'^/alltime-best/results/')
urls = [link.get("href") for link in soup.select("#result_contents a") if not pattern.match(link.get("href"))]
print(urls)
# printの例
# ['/movie/41841/', '/movie/56301/', '/movie/5134/', '/movie/6279/',...
短いのですが,読みにくい.
3. 次へボタン
紹介されている映画が1ページに収まりきらない場合,ページの末尾に2ページ目へのリンクや「次へ」ボタンが出現します.

力技で次のページのURLを探し出して,スクレイピングしてもよいのですが,1ページ20件表示であること,1ページ目のURLにはpage=1を,2ページ目のURLにはpage=2を付加すれば良いことを利用して半手動で準備します.
手動で入力(おすすめ)
取得したい年代がわかっているので,直接入力するのが早い可能性があります.
url_list = [
"https://eiga.com/alltime-best/results/?page=1&y=1940",
"https://eiga.com/alltime-best/results/?page=2&y=1940"
]
全件数などをスクレイピングする方法(思いの外面倒)
ページの冒頭に紹介される映画の全件数が表示されています.1940年代の例だと全25件とわかります.画像の赤枠の部分になります.
1ページ最大20件の映画タイトルが表示されるので,25件ということは,
- 1ページ目:1〜20件
- 2ページ目:21〜25件
このような形で,区切りをつけていけば良いことになります.全件数が表示されている部分のHTMLは
<p id="result_count">全25件中、1~20件目を表示</p>
という形をしています.いくつか方法があると思いますが,
- pタグのid属性の値がresult_countによってテキスト部分を抽出
- 正規表現を利用して,最初の数字を探す
この2段階によって全件数の値を知ることができそうです.
num_tag = soup.find('p', id='result_count')
numbers = re.findall(r'\d+', num_tag.text)
if numbers:
num = numbers[0] # 最初の数字が全件数
print(f"全件数: {num}")
1ページ20件ですので,全件数の25を20で割り算して
25/20 = 1.25
これを切り上げて,最大ページ数が2ページと特定できます.全件数を取得して,最大ページ数を特定する部分は,次のようになります.
import math
num_tag = soup.find('p', id='result_count')
numbers = re.findall(r'\d+', num_tag.text)
if numbers:
num = numbers[0] # 最初の数字が全件数
print(f"全件数: {num}")
max_page_num = math.ceil(int(num)/20)
print(f"最大ページ数: {max_page_num}")
最大ページ数がわかったので,映画の一覧を取得するURLのリストを作成することができます.
URLの基本的な形は,
だったので,番号と年に数字を代入していけば完成となります.
url_list = []
base_url = "https://eiga.com/alltime-best/results/"
for i in range(1, max_page_num+1):
url_list.append(base_url+"?page="+str(i)+"&y=1940")
結果的に素朴に
url_list = [
"https://eiga.com/alltime-best/results/?page=1&y=1940",
"https://eiga.com/alltime-best/results/?page=2&y=1940"
]
と入力したほうが綺麗ですし簡単です.
4. まとめ(レビュー取得可能URLの一覧を取得)
映画のレビューを取得できるURLの形が
という形になっていることを利用して,1と2で紹介した方法を組み合わせるて,映画レビュー取得可能なURLの一覧を得ることができます.
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
# 手動入力したURLリストを使ってしまった
url_list = [
"https://eiga.com/alltime-best/results/?page=1&y=1940",
"https://eiga.com/alltime-best/results/?page=2&y=1940"
]
headers = {"User-Agent": "Mozilla/5.0"}
# 2.2.CSSセレクターを使う形を利用しています
def get_title_urls(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# /alltime-best/results/ で始まるURLのパターンを除きたい
pattern = re.compile(r'^/alltime-best/results/')
urls = [link.get('href') for link in soup.select('#result_contents a') if not pattern.match(link.get('href'))]
return urls
#---- ここからが本題
title_url_list = []
# url_listから順番にurlを読み込んで,映画のurlを取得する.
# title_url_listに,映画urlを追記
for url in url_list:
urls = get_title_urls(url)
title_url_list.extend(urls)
time.sleep(2)
print(f"{url}から取得中")
# レビューを取得可能なURLに変換
# https://eiga.com/取得した映画URL/review/
review_url_list = []
for title_url in title_url_list:
url = "https://eiga.com"+title_url+"review/"
review_url_list.append(url)
# データフレームに変換して,CSVファイルとして保存
data = pd.DataFrame({'review_url': review_url_list})
data.to_csv("movie_review_url.csv", index=False)
紹介した方法以外にも,もっと効率的な方法や高速な方法,可読性の高い方法など様々あると思います.馴染む方法で情報を取得するのが最適だと感じます.
注
-
1の記事と合わせて,映画レビューと評価値などの情報を取得することが可能となります. ↩