こちらのNotebookを摸写した上で、自分で考えたことを考えてデータ処理してみた。
※Titanic using Pipelined XGBoost & GridSearch
データの読み込み
# データ読み込み
X_y = pd.read_csv('train.csv', index_col = 'Passenger_id')
X_test = pd.read_csv('test.csv', index_col = 'Passenger_id')
# Survivedカラムに欠損値がある行を削除する。
X_y = X_y.dropna(subset=['Survived'], axis=0)
# yをXから分離する。
X = X_y.copy()
y = X.pop('Survived')
データクレンジング
def show_null_values(X, X_test)
# 変数Xの欠損値の数を数える。
null_values = pd.DataFrame(X.isnull().sum(), columns=['Train Data'])
# 変数X_testの欠損値の数を数える。
null_values['Test Data'] = X_test.isnull().sum().values
# null_values変数に、Train Data, Test Dataのどちらかが0ではないデータを抽出する。
null_values = null_values.loc[(null_values['Train Data']!=0 | (null_values['Test Data']!=0)]
# ソートする。
null_values = null_values(by=['Train Data', 'Test Data'], ascending=
False)
return null_values
# メソッド呼び出し
show_null_values(X, X_test)
下記のように、各カラムの欠損値の数を抽出することができた。
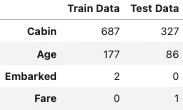
欠損値の数が多いカラムがあるため、半分以上の行が欠損値となっているカラムは除去してしまうことにする。
null_columns = [if for col in X.columns if X[col].isnull().sum() > len(X)/2]
null_columns

Cabinカラムが削除された。
外れ値を探す。
X.plot.box()
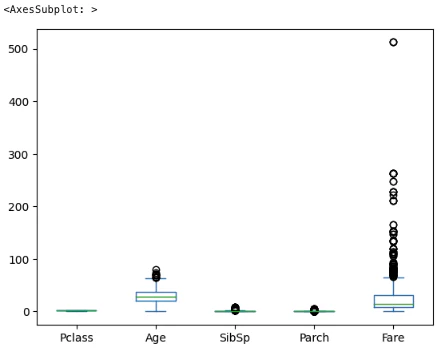
Fareの外れ値(?)がありそうなため確認する。
outlier = X.query('Fare >= 500')
outlier = outlier.sort_values('Fare', ascending=False)
outlier

Fareが500以上の行は削除してもよさそうだと感じた。
四分位範囲を利用して、外れ値か判断してみる。
Fareの統計量を出してみる。
X['Fare'].describe()
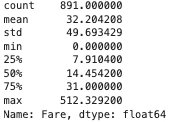
「第三四分位範囲から四分位範囲x1.5倍を足した値」以上のデータがありそう。
31 + (31-7.910400) x 1.5 = 65.6344なので、Fareが65以上の場合は外れ値と判断できる。
これで外れ値を判断すると大量のデータを除去することになってしまうので、他の方法を調べたところwinsorizationを使用して外れ値に対処している方がいらっしゃったため、自分も試してみた。
参考:winsorization で外れ値に対処する
# 小数データをヒストグラムで表示
def plot_float(df, column, bins=10):
sns.distplot(df[column], kde=True, rug=False, bins=bins)
plt.title(column)
plt.tight_layout()
plt.show()
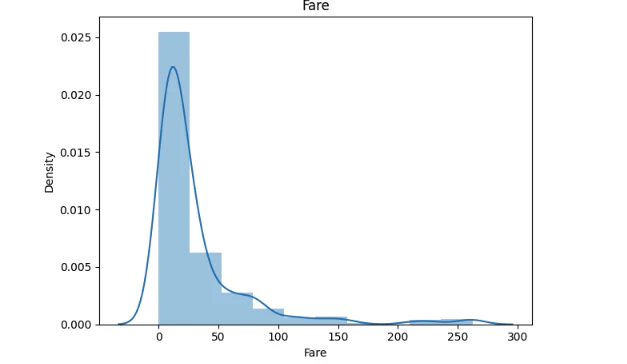
X["Fare"] = scipy.stats.mstats.winsorize(X["Fare"], limits=[0.01, 0.01])
# 外れ値を除外した結果をplot
plot_float(X, "Fare")
外れ値(Fareが500以上のデータ)が除去できていることを確認できた。
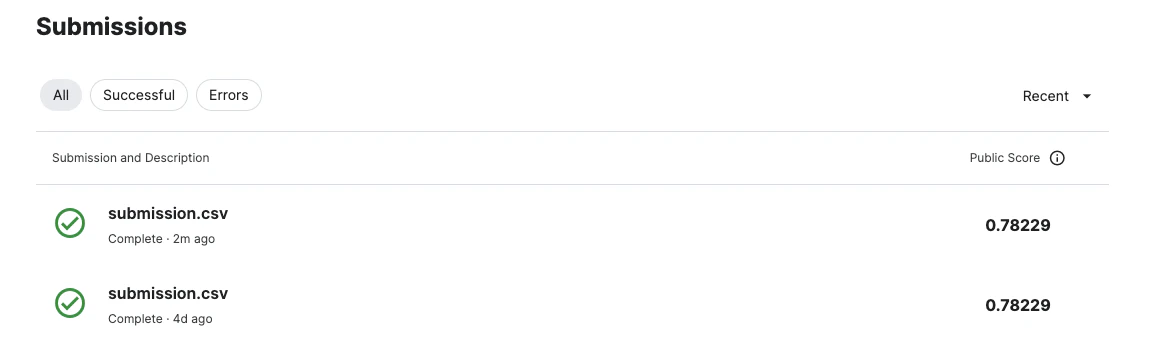
結果
しかし、Score(予測精度)を上げることはできなかった。。