はじめに
最近よく聞く「RAG(Retrieval-Augmented Generation)」ですが、
- ベクトルDBを使う
- embeddingを使う
- あれを入れて、これを使う…
など、いきなり高度な話から入ることが多く、
「なんか良く分からないけどAIの魔法なのかなぁ」
という認識で終わってしまう方も少なくないのではないでしょうか?
確かに、テキストの埋め込みなど理論的に少し難解な部分はあります。
しかし、実のところ実装にあたっては呆気ないほどシンプルに、「RAG検索システム」が実現できてしまうのです。
この記事ではあえて、
👉 ベクトルDBを使わずに、普通のRDB(PostgreSQL)だけでRAGを実装
することで、
👉 RAGの本質(検索 → 生成)を理解する
ことを目的とします。
その後、
- pgvectorを導入(postgresqlを本格的なRAG-DBにする拡張機能)
- ハイブリッド検索(より実用的な検索手法)
- LLMを使って回答を生成 (※要APIキー)
まで段階的に進めます。
対象ユーザ
- RAGって良く聞くけど一体何物?くらいな認識を持っている方
- ほんの少しPythonが触れる
- ほんの少しRDB(SQL)理解している
RAGとは何か(ユーザー目線で)
RAGを一言でいうと、
👉 「自分のデータを使って、AIに答えさせる仕組み」 です。
( 「自分のデータ」 というのはプレーンテキスト、ワード、エクセル、PDF、HTML、etc... テキストに変換出来るものなら何でも行けます)
例えば、ChatGPTに社内情報や業務マニュアル、ニッチな専門的情報などを聞いても答えてくれませんよね?(当然ですが…)
しかしRAGを使うと
- 社内ドキュメントをもとに回答できる
- 自分のデータベースを参照できる
- 最新の情報を使った回答ができる
という形で自社(自分)専用の 「カスタマイズされたAI」 を作ることが出来ます。
そのため、内部に大量の情報を蓄積している企業や団体でのニーズが高い技術となっております。
もうひとつRAG検索には優れた特徴があって、一般にRAGでは 「キーワード」 でなく 「意味」 で検索します。
例えば、「DB」に関する情報を検索したい場合、「データベース」と検索しても「DB」に関する記事がヒットします。
「データベース」と「DB」の意味が同義だからです。
同じく、「クラウドサービス」と検索すると「AWS」や「S3」や「GCP」がヒットするはずです。
この場合「クラウドサービス」と「AWS」「S3」「GCP」の意味が関連し合っているからです。
なぜこういう検索が出来るかというと、RAGでは単語を 「ベクトル化」 することによって、単語間の意味の違いを数学的に計算することができるからなのですが、この部分については後で触れます。
RAGの仕組み(超シンプル)
RAGは以下の2ステップです。
1. 関連する情報をベクトル検索する
2. その情報をもとにLLMが回答する
もう少し具体的な流れは以下です。
👉 ポイント
「ベクトル検索」 が8割、あとは結果の「まとめ、整理」
環境をつくろう(Docker)
まずはPostgreSQLだけ用意します(追って必要なものを追加していきます)。
すでにPostgreSQLを導入済みの方はそのまま使っていただいて構いませんが、ここでは Docker での環境構築を案内します。
Dockerを使う理由としては、メインの環境を汚さずに済むということと、Mac/Windows/Linuxで共通の手順が使えるからです。
ただし、Docker(Docker Desktop)自体のインストールについては本稿では割愛させていただきます。
「Docker インストール mac」「Docker インストール windows」などと検索していただければ🙇
※Windowsの場合はWSL2のセットアップが必要になりますが、これも導入記事に書かれているはずですなので指示に従って導入してください
もちろん、非Dockerでも普通に試せる内容となっておりますので、お好きな方で進めてください。
まず、適当な場所でディレクトリを切って、中に移動します。
mkdir ragdb
cd ragdb
その中に、以下のようなファイルを作成します。
services:
db:
working_dir: /app
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: ragdb
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:
次にコンテナを起動します。
docker compose up -d
ビルドが始まり、最終的に起動されます
% docker compose up -d
[+] Running 15/15
✔ db Pulled 13.3s
✔ 78bf6908b207 Pull complete 0.8s
✔ e7b8c52f4a23 Pull complete 2.6s
✔ 27f5539a48bf Pull complete 1.0s
✔ 53196b1f47bd Pull complete 2.4s
✔ 3224fed94736 Pull complete 0.9s
✔ c2eef6a4035a Pull complete 1.0s
✔ 9828e938e223 Pull complete 5.2s
✔ 692f4d409b9b Pull complete 2.5s
✔ 701da5374449 Pull complete 1.0s
✔ a5b0243f1eb8 Pull complete 1.3s
✔ 648d91503191 Pull complete 1.0s
✔ 5b17b00a9f95 Pull complete 1.7s
✔ 332f4836e54c Pull complete 1.0s
✔ 30c3e1e5e7cc Pull complete 1.0s
[+] Running 2/2
✔ Network ragdb_default Created 0.0s
✔ Container ragdb-db-1 Started 0.7s
'Started'が確認できればOKです。
その左の'ragdb-db-1'というのが今回のコンテナ名になりますので覚えておきましょう。
ちなみに、Docker Desktopを使っている方はアプリでビジュアルに確認できます。

コンテナの「中」に入ります。
docker exec -it ragdb-db-1 bash
postgresqlクライアント(psql)を使ってDBに接続します。
psql -U user -d ragdb
以下のような表示になるはずです。
root@fbac47f08deb:/# psql -U user -d ragdb
psql (15.17 (Debian 15.17-1.pgdg13+1))
Type "help" for help.
ragdb=#
これでDBに接続できたので、DBの管理コマンドやSQLを発行することが出来ます。
テーブルを作りましょう。
テーブル名は'documents'で、連番型のカラムidと、文字列型のカラムcontentを持ちます。
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT
);
続いて、サンプルデータを挿入していきます。
サンプルデータについて
「Q&A」のようなテキスト100件を素材としました。
もちろん、この形でないとRAGが出来ないわけはなく、およそどんな形式のテキストでもRAGデータとして扱えるのですが、検索のテストとして使いやすそうなのでこの形で揃えました。
内容はIT用語が中心ですが、あえて「ラーメン」や「猫」のような無関係な用語も「ノイズ」として混入してあります。
実際にRAGで使われるデータも必ずしも純度の高いものではないので、このような「ノイズ」もデータのリアリティを高めるのに好都合です。
これもバーっと流しちゃってください。
INSERT INTO documents (content) VALUES
('Q: HTMLとは何ですか? A: Webページの構造を定義するマークアップ言語です'),
('Q: CSSとは何ですか? A: Webページの見た目を整えるスタイルシート言語です'),
('Q: JavaScriptとは何ですか? A: ブラウザで動作するプログラミング言語です'),
('Q: TypeScriptとは何ですか? A: JavaScriptに型を追加した言語です'),
('Q: Javaとは何ですか? A: オブジェクト指向のプログラミング言語です'),
('Q: Pythonとは何ですか? A: シンプルで読みやすいプログラミング言語です'),
('Q: Goとは何ですか? A: Googleが開発した高速なプログラミング言語です'),
('Q: Rustとは何ですか? A: 安全性と高速性を重視した言語です'),
('Q: SQLとは何ですか? A: データベースを操作するための言語です'),
('Q: PostgreSQLとは何ですか? A: オープンソースのリレーショナルデータベースです'),
('Q: MySQLとは何ですか? A: 人気のあるリレーショナルデータベースです'),
('Q: Oracle Databaseとは何ですか? A: 商用の高性能データベースです'),
('Q: SQL Serverとは何ですか? A: Microsoftのデータベース製品です'),
('Q: SQLiteとは何ですか? A: 軽量な組み込み型データベースです'),
('Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです'),
('Q: MongoDBとは何ですか? A: ドキュメント指向データベースです'),
('Q: Redisとは何ですか? A: インメモリ型の高速データストアです'),
('Q: Cassandraとは何ですか? A: 分散型NoSQLデータベースです'),
('Q: Snowflakeとは何ですか? A: クラウド型データウェアハウスです'),
('Q: BigQueryとは何ですか? A: Googleの分析用データ基盤です'),
('Q: Redshiftとは何ですか? A: AWSのデータウェアハウスです'),
('Q: Elasticsearchとは何ですか? A: 高速検索エンジンです'),
('Q: OpenSearchとは何ですか? A: Elasticsearch由来の検索エンジンです'),
('Q: Dockerとは何ですか? A: コンテナ仮想化技術です'),
('Q: Kubernetesとは何ですか? A: コンテナ管理ツールです'),
('Q: AWSとは何ですか? A: Amazonのクラウドサービスです'),
('Q: Azureとは何ですか? A: Microsoftのクラウドサービスです'),
('Q: GCPとは何ですか? A: Googleのクラウドサービスです'),
('Q: EC2とは何ですか? A: 仮想サーバーサービスです'),
('Q: S3とは何ですか? A: オブジェクトストレージです'),
('Q: Lambdaとは何ですか? A: サーバーレス実行環境です'),
('Q: CloudFrontとは何ですか? A: CDNサービスです'),
('Q: VPCとは何ですか? A: 仮想ネットワークです'),
('Q: IAMとは何ですか? A: アクセス管理サービスです'),
('Q: APIとは何ですか? A: システム間連携のインターフェースです'),
('Q: RESTとは何ですか? A: Web APIの設計スタイルです'),
('Q: GraphQLとは何ですか? A: 柔軟なAPIクエリ言語です'),
('Q: LLMとは何ですか? A: 大規模言語モデルです'),
('Q: GPTとは何ですか? A: 生成型AIモデルです'),
('Q: RAGとは何ですか? A: 検索と生成を組み合わせた手法です'),
('Q: embeddingとは何ですか? A: テキストをベクトルに変換する技術です'),
('Q: ベクトル検索とは何ですか? A: 意味で検索する技術です'),
('Q: cosine類似度とは何ですか? A: ベクトルの角度で類似度を測る方法です'),
('Q: 正規化とは何ですか? A: データの冗長性を減らす手法です'),
('Q: インデックスとは何ですか? A: 検索を高速化する仕組みです'),
('Q: トランザクションとは何ですか? A: データの整合性を保つ単位です'),
('Q: ACIDとは何ですか? A: トランザクションの性質です'),
('Q: JOINとは何ですか? A: テーブル結合の操作です'),
('Q: GROUP BYとは何ですか? A: 集計処理です'),
('Q: LIMITとは何ですか? A: 取得件数の制限です'),
('Q: Pythonのリストとは何ですか? A: 複数の値を保持する構造です'),
('Q: JavaScriptのPromiseとは何ですか? A: 非同期処理を扱う仕組みです'),
('Q: async/awaitとは何ですか? A: 非同期処理を簡潔に書く構文です'),
('Q: Gitとは何ですか? A: バージョン管理システムです'),
('Q: GitHubとは何ですか? A: ソースコード共有サービスです'),
('Q: CI/CDとは何ですか? A: 自動ビルドとデプロイの仕組みです'),
('Q: テストコードとは何ですか? A: プログラムの品質を確認するコードです'),
('Q: ユニットテストとは何ですか? A: 小さな単位のテストです'),
('Q: E2Eテストとは何ですか? A: 全体の動作確認テストです'),
('Q: キャッシュとは何ですか? A: 高速化のための一時保存です'),
('Q: CDNとは何ですか? A: コンテンツ配信ネットワークです'),
('Q: HTTPとは何ですか? A: Web通信のプロトコルです'),
('Q: HTTPSとは何ですか? A: 暗号化された通信です'),
('Q: TCPとは何ですか? A: 信頼性のある通信プロトコルです'),
('Q: UDPとは何ですか? A: 軽量な通信プロトコルです'),
('Q: JSONとは何ですか? A: データ交換フォーマットです'),
('Q: YAMLとは何ですか? A: 設定ファイル形式です'),
('Q: XMLとは何ですか? A: マークアップ形式です'),
('Q: CSVとは何ですか? A: カンマ区切りのデータ形式です'),
('Q: ラーメンとは何ですか? A: スープと麺の料理です'),
('Q: カレーとは何ですか? A: スパイス料理です'),
('Q: 牛丼とは何ですか? A: 牛肉の丼料理です'),
('Q: 寿司とは何ですか? A: 日本の伝統料理です'),
('Q: ピザとは何ですか? A: チーズを使った料理です'),
('Q: パスタとは何ですか? A: 麺料理の一種です'),
('Q: ハンバーガーとは何ですか? A: パンと肉の料理です'),
('Q: コーヒーとは何ですか? A: カフェイン飲料です'),
('Q: 紅茶とは何ですか? A: 茶葉の飲み物です'),
('Q: 水とは何ですか? A: 生命に必要な液体です'),
('Q: サッカーとは何ですか? A: ボールを使うスポーツです'),
('Q: 野球とは何ですか? A: バットを使うスポーツです'),
('Q: バスケとは何ですか? A: ゴールにボールを入れるスポーツです'),
('Q: 映画とは何ですか? A: 映像作品です'),
('Q: 音楽とは何ですか? A: 音を楽しむ文化です'),
('Q: 本とは何ですか? A: 知識を記録した媒体です'),
('Q: スマホとは何ですか? A: 携帯型コンピュータです'),
('Q: PCとは何ですか? A: 個人用コンピュータです'),
('Q: AIとは何ですか? A: 人工知能です'),
('Q: 機械学習とは何ですか? A: データから学習する技術です'),
('Q: 深層学習とは何ですか? A: ニューラルネットを用いた学習です'),
('Q: データサイエンスとは何ですか? A: データ分析の分野です'),
('Q: BIとは何ですか? A: ビジネスインテリジェンスです'),
('Q: KPIとは何ですか? A: 重要業績評価指標です'),
('Q: マネジメントとは何ですか? A: 組織を管理することです'),
('Q: プロジェクトとは何ですか? A: 目的を持った活動です'),
('Q: スケジュールとは何ですか? A: 計画表です'),
('Q: 会議とは何ですか? A: 複数人での話し合いです'),
('Q: 犬とは何ですか? A: 人に飼われることが多い動物です'),
('Q: 猫とは何ですか? A: 小型で俊敏な動物です'),
('Q: 魚とは何ですか? A: 水中で生活する生き物です');
中身を確認してみましょう
SELECT * FROM documents;
まずはベクトル検索でない「普通の」検索を試してみましょう。
ワイルドカードが使えるLIKE句を使ってみます。
ragdb=# SELECT * FROM documents WHERE content LIKE '%SQL%';
id | content
----+-------------------------------------------------------------------------------
9 | Q: SQLとは何ですか? A: データベースを操作するための言語です
10 | Q: PostgreSQLとは何ですか? A: オープンソースのリレーショナルデータベースです
11 | Q: MySQLとは何ですか? A: 人気のあるリレーショナルデータベースです
13 | Q: SQL Serverとは何ですか? A: Microsoftのデータベース製品です
14 | Q: SQLiteとは何ですか? A: 軽量な組み込み型データベースです
15 | Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです
18 | Q: Cassandraとは何ですか? A: 分散型NoSQLデータベースです
(7 rows)
ここまでが「普通の」RDBの使い方です。
ところが、この「普通の」検索、困ったことが起こり得ます。
例えば、あなたが「DB」に関連するデータを抽出したいと思った場合、以下のようなSQLクエリを投げると思います。
SELECT * FROM documents WHERE content LIKE '%DB%';
そして今回のサンプルDBの場合だと、以下のような結果が返ってきます。
id | content
----+--------------------------------------------------------------
15 | Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです
16 | Q: MongoDBとは何ですか? A: ドキュメント指向データベースです
(2 rows)
2件だけ返ってきて、「ふーん、そんなもんか」と。
「あれ?もっと出てきてほしいのに…」と感じるはずです
そして、ここでキーワードを「データベース」に変更すると・・・
SELECT * FROM documents WHERE content LIKE '%データベース%';
id | content
----+-------------------------------------------------------------------------------
9 | Q: SQLとは何ですか? A: データベースを操作するための言語です
10 | Q: PostgreSQLとは何ですか? A: オープンソースのリレーショナルデータベースです
11 | Q: MySQLとは何ですか? A: 人気のあるリレーショナルデータベースです
12 | Q: Oracle Databaseとは何ですか? A: 商用の高性能データベースです
13 | Q: SQL Serverとは何ですか? A: Microsoftのデータベース製品です
14 | Q: SQLiteとは何ですか? A: 軽量な組み込み型データベースです
15 | Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです
16 | Q: MongoDBとは何ですか? A: ドキュメント指向データベースです
18 | Q: Cassandraとは何ですか? A: 分散型NoSQLデータベースです
(9 rows)
多数のデータがヒットします。
「DB」も「データベース」も同義なので、出来れば一発でこの結果を出したいものです。
しかし、同義語も含めて検索しようとすると、考えられる限りの表記のバリエーションを思い浮かべ、クエリに仕込む必要が出てきます。例えば、
SELECT * FROM documents
WHERE
content LIKE '%db%' OR
content LIKE '%データベース%' OR
content LIKE '%Database%' OR
content LIKE '%database%'
;
のようなクエリを毎回発行することになり、大変な手間がかかります。
また、想定外の表記ゆれが存在することによる「抽出漏れ」も十分にありえます。
要するに、人間は 「意味」 で検索するが、SQLは 「文字列」 で検索するので、期待した結果とのズレが生じるわけです。
そこで、「普通の」検索ではない 「ベクトル検索」 の出番になります。
いよいよ、「ベクトル検索」ワールドへ
準備:コンテナにPython関係を含める
embedding(埋め込み)を扱うために、Pythonとライブラリを使えるようにします。
これまではpostgresqlのみだったので必要がなかったのですが、ここからはPythonを使いますのでPython本体、および必要なライブラリを追加する設定を加えます。
docker-compose.ymlと同じ階層にDockerfileというファイル(拡張子不要)を追加し、以下の内容を書き込んでください。
FROM postgres:15
RUN apt-get update && apt-get install -y python3 python3-pip python3-venv
RUN python3 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
RUN pip install sentence-transformers numpy psycopg2-binary
※ Pythonは仮想環境(venv)上で動くようにしています(安全にライブラリを管理するため)
一応導入するライブラリのざっくりとした説明
sentence-transformers 👉 embedding(埋め込み)をするやつ
numpy 👉 数値演算をするやつ
psycopg2-binary 👉 postgresqlに接続するやつ
次に、docker-compose.ymlを修正して以下の形にします。
services:
db:
build: .
working_dir: /app
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: ragdb
ports:
- "5432:5432"
volumes:
- ./app:/app
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:
コンテナを止め、再構築(再ビルド)します。
docker compose down
docker compose up -d --build
注意
ライブラリの容量がそこそこ大きく、転送量もそれなりにあるので余裕のある回線を使用してください
以下のように進行します。そこそこ時間がかかります。私が試したときは6分くらいかかっています。
docker compose up -d --build
WARN[0000] /Users/.../ragdb/docker-compose.yml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion
[+] Building 365.0s (10/10) FINISHED
=> [internal] load local bake definitions 0.0s
=> => reading from stdin 484B 0.0s
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 256B 0.0s
=> [internal] load metadata for docker.io/library/postgres:15 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> CACHED [1/4] FROM docker.io/library/postgres:15@sha256:31224c60946ea75ee9522e0f4d02eb202e7475 0.0s
=> => resolve docker.io/library/postgres:15@sha256:31224c60946ea75ee9522e0f4d02eb202e74754adea42 0.0s
=> [2/4] RUN apt-get update && apt-get install -y python3 python3-pip python3-venv 11.6s
=> [3/4] RUN python3 -m venv /opt/venv 1.0s
=> [4/4] RUN pip install sentence-transformers numpy psycopg2-binary 135.8s
=> exporting to image 215.9s
=> => exporting layers 144.0s
=> => exporting manifest sha256:747a9a442ab725beeb5f9ec7c806f362f42c2f9169b1376e65b84f56511948b9 0.0s
=> => exporting config sha256:30fb7ed40ff98ad49e8cd70d35c7d0f551aef02fa8ddd3b691404c761ae5f782 0.0s
=> => exporting attestation manifest sha256:2019bb6eb9f15bd16926e7c340d3dda9d81475a135e5ef118a27 0.0s
=> => exporting manifest list sha256:bbcb7d39edeff08cd9d13d4caa7895b2f96f1ac48f058a94918f7e8b383 0.0s
=> => naming to docker.io/library/postgres:15 0.0s
=> => unpacking to docker.io/library/postgres:15 71.7s
=> resolving provenance for metadata file 0.0s
[+] Running 3/3
✔ postgres:15 Built 0.0s
✔ Network ragdb_default Created 0.1s
✔ Container ragdb-db-1 Started 1.5s
今回も、'Started'が確認できればOKです。
※ もしエラーが出た場合は、ログを確認して再度 docker compose up --build を実行してください
文章を「ベクトル」に変換してみる
ベクトル検索をする場合、まずはデータを 「ベクトル」 に変換しないと何も始まりません。
「ベクトル」 とは、ここでは 決められた数の「数値のグループ」 くらいに思ってもらって構いません。Pythonで言えば 「配列」 に数値がセットされたものになります。
では、前回と同じようにコンテナに入って、
docker exec -it ragdb-db-1 bash
Pythonを対話モードで起動します。
python3
以下のコードを一行ずつ入力していきます。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
vec = model.encode("S3とは何ですか?")
print(vec)
実際の実行イメージは以下
# python3
Python 3.13.5 (main, Jun 25 2025, 18:55:22) [GCC 14.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer('all-MiniLM-L6-v2')
modules.json: 100%|█████████████████████████████████████████████████████| 349/349 [00:00<00:00, 878kB/s]
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
(略)
>>> vec = model.encode("S3とは何ですか?")
>>> print(vec)
[-4.59674979e-03 5.07573560e-02 -4.34153201e-03 -1.01657892e-02
-1.63941365e-02 8.36044699e-02 1.02968320e-01 2.58232318e-02
2.65241903e-03 -5.06820576e-03 9.46014449e-02 -1.11212328e-01
6.22262657e-02 -4.94585074e-02 2.49237549e-02 -1.23501159e-01
1.32657597e-02 -1.86691512e-04 -5.74023277e-02 5.41601423e-03
(略)
-3.09597813e-02 -2.44353116e-02 -9.77887064e-02 3.12831998e-02
-4.79910672e-02 1.18579939e-02 -6.60223737e-02 3.92491259e-02
4.66296747e-02 3.34242918e-02 3.74791399e-02 2.62165479e-02
-1.69011932e-02 7.28103891e-02 -1.29167914e-01 2.70906538e-02]
大量の数値が表示されましたね?
これが「S3とは何ですか?」という日本語の文を「ベクトル化」したものです。
Python(正確にはnumpy)の配列の形になっていて、384個の数値が並んでいるはずです。
数値の範囲は-1から1までの間に収まっています('e-0*'は指数表記、*桁分小数点が左にずれます)。
元の文字数よりもはるかに数値の個数が多くなっていますが、これは正常です。どんな文章をベクトル化しても同じ数の数値がセットされます。
さて どういうルールで文字が数値化されているのか? についてはいったん後回しにしたいと思います。今は 「AIのモデルがうまいことベクトルに変換してくれた」 くらいの理解で大丈夫です。
ベクトルをRDBに保存するための準備
こうして変換されたベクトルをDBのテーブルに保存する処理を行います。
その前に、テーブルにカラムを追加する必要があります。
DBにアクセスし、
psql -U user -d ragdb
以下のクエリを流します。
ALTER TABLE documents ADD COLUMN embedding FLOAT[];
embeddingという 浮動小数点の配列型 のカラムを追加しています。
このようなデータ型を初めて見るかも知れませんが、今どきのRDBは配列データを扱うこともできるようになっています。
DBを抜けるには以下のコマンドを使います。
\q
Pythonでテキストをベクトルに変換し、DBに保存する
ragdb/app/配下に、Pythonファイルを作成します。ここではembed.pyという名前にしておきます。
ここからの作業は、Vscodeなどお好みのテキストエディタで行ってください
内容は以下です。
import psycopg2
from sentence_transformers import SentenceTransformer
# 埋め込みモデルを読み込む
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# RDBに接続
conn = psycopg2.connect(
host="localhost",
database="ragdb",
user="user",
password="password"
)
cur = conn.cursor()
# RDBから全件データを取得
cur.execute("SELECT id, content FROM documents")
rows = cur.fetchall()
for row in rows:
id, text = row
vec = model.encode(text).tolist() # データをベクトルに変換
# `embedding`カラムにベクトルを保存
cur.execute(
"UPDATE documents SET embedding = %s WHERE id = %s",
(vec, id)
)
conn.commit()
# 接続を切断
cur.close()
conn.close()
実行します。
コンテナに入って実行するか、
docker exec -it ragdb-db-1 bash
# python3 embed.py
ローカルから直接実行します
docker exec -it ragdb-db-1 python3 /app/embed.py
実行の状況は以下です。
# python3 embed.py
modules.json: 100%|████████████████████████████████████| 349/349 [00:00<00:00, 1.07MB/s]
config_sentence_transformers.json: 100%|████████████████| 116/116 [00:00<00:00, 492kB/s]
README.md: 10.5kB [00:00, 12.0MB/s]
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
sentence_bert_config.json: 100%|██████████████████████| 53.0/53.0 [00:00<00:00, 351kB/s]
config.json: 100%|█████████████████████████████████████| 612/612 [00:00<00:00, 1.75MB/s]
model.safetensors: 100%|███████████████████████████| 90.9M/90.9M [00:03<00:00, 29.5MB/s]
Loading weights: 100%|█████████████████████████████| 103/103 [00:00<00:00, 10057.11it/s]
BertModel LOAD REPORT from: sentence-transformers/all-MiniLM-L6-v2
Key | Status | |
------------------------+------------+--+-
embeddings.position_ids | UNEXPECTED | |
Notes:
- UNEXPECTED: can be ignored when loading from different task/architecture; not ok if you expect identical arch.
tokenizer_config.json: 100%|███████████████████████████| 350/350 [00:00<00:00, 1.88MB/s]
vocab.txt: 232kB [00:00, 24.6MB/s]
tokenizer.json: 466kB [00:00, 41.7MB/s]
special_tokens_map.json: 100%|██████████████████████████| 112/112 [00:00<00:00, 368kB/s]
config.json: 100%|██████████████████████████████████████| 190/190 [00:00<00:00, 867kB/s]
表示されているログは主にファイルのロードに関するもので、何が起こっているのかが良く分かりません。
DBテーブルをSELECTして、ベクトルが保存されていることを確認してみましょう。
DBにログインして、以下のクエリを投げてみます。
ここでembedding[1]と添字を付けていますが、全要素を表示させると大変な量の数値が出てきてしまうので、最初の要素のみを抽出しています。
※Postgresqlの配列型では、添字は'1'から始まる仕様になっています。
SELECT embedding[1] from documents;
embedding
------------------------
0.04353516921401024
0.02411266788840294
-0.017524437978863716
-0.036162201315164566
...(略)
全件ベクトルがセットされてますね!
次はいよいよ検索です。
ベクトル検索してみる
検索するためのコードを準備します。
ベクトル検索は(現段階では)psqlからSQLクエリを投げるのでなく、Python側から行います。
ファイル名はsearch.pyとでもしておきましょう。
import numpy as np
import psycopg2
from sentence_transformers import SentenceTransformer
# 埋め込みモデルを読み込む
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# RDBに接続
conn = psycopg2.connect(
host="localhost",
database="ragdb",
user="user",
password="password"
)
cur = conn.cursor()
# -----------------------------
# 検索クエリ
# -----------------------------
query = "DB" # ←←← ここを色々と変えてみる
# クエリもベクトルに変換
q_vec = model.encode(query)
# -----------------------------
# DBから全件データ取得
# -----------------------------
cur.execute("SELECT id, content, embedding FROM documents")
rows = cur.fetchall()
scores = []
# -----------------------------
# 類似度計算
# -----------------------------
for row in rows:
id, text, vec = row
# DBから取得したembeddingをnumpy配列に変換
vec = np.array(vec)
# cosine類似度(スコア)を計算(1に近い方が「似ている」)
score = np.dot(q_vec, vec) / (
np.linalg.norm(q_vec) * np.linalg.norm(vec)
)
# スコアとテキストを保存
scores.append((score, text))
# -----------------------------
# スコア順に並び替え
# -----------------------------
scores.sort(reverse=True)
# 上位5件表示
print(f"検索クエリ「{query}」")
print("🔍 検索結果(上位10件)\n")
for score, text in scores[:10]:
print(f"{score:.4f} : {text}")
検索実行!!
まずはクエリキーワードを、冒頭の部分と同じdbで検索してみます。
python3 search.py
すると、こんな検索結果が得られます。
# python3 search.py
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
Loading weights: 100%|█████████████████████████████| 199/199 [00:00<00:00, 12166.26it/s]
検索クエリ「DB」
🔍 検索結果(上位10件)
0.4988 : Q: MongoDBとは何ですか? A: ドキュメント指向データベースです
0.4923 : Q: Oracle Databaseとは何ですか? A: 商用の高性能データベースです
0.4826 : Q: SQLとは何ですか? A: データベースを操作するための言語です
0.4797 : Q: SQL Serverとは何ですか? A: Microsoftのデータベース製品です
0.4594 : Q: MySQLとは何ですか? A: 人気のあるリレーショナルデータベースです
0.4503 : Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです
0.4101 : Q: トランザクションとは何ですか? A: データの整合性を保つ単位です
0.4006 : Q: Cassandraとは何ですか? A: 分散型NoSQLデータベースです
0.3929 : Q: EC2とは何ですか? A: 仮想サーバーサービスです
0.3912 : Q: VPCとは何ですか? A: 仮想ネットワークです
これは、類似度のトップ10件を示しています。
少なくとも上位8件は「DB」という単語を含んでいなくても「データベース」に関連するレコードが抽出できています。
冒頭の「普通の」検索と比べると実用性において段違いですね。
この結果だけでも、「普通の」検索と「ベクトル検索」の差が実感できるかと思います。
せっかくなので色々クエリキーワードを変えて試してみましょう。
例えば、キーワードをAWSにするとどうでしょうか?
以下の行を編集して再実行します。
query = "AWS" # ←←← ここを色々と変えてみる
すると、
検索クエリ「AWS」
🔍 検索結果(上位10件)
0.5609 : Q: AWSとは何ですか? A: Amazonのクラウドサービスです
0.5018 : Q: Redshiftとは何ですか? A: AWSのデータウェアハウスです
0.4287 : Q: IAMとは何ですか? A: アクセス管理サービスです
0.4128 : Q: S3とは何ですか? A: オブジェクトストレージです
0.3838 : Q: DynamoDBとは何ですか? A: AWSのNoSQLデータベースです
0.3756 : Q: Redisとは何ですか? A: インメモリ型の高速データストアです
0.3706 : Q: YAMLとは何ですか? A: 設定ファイル形式です
0.3552 : Q: RAGとは何ですか? A: 検索と生成を組み合わせた手法です
0.3123 : Q: 牛丼とは何ですか? A: 牛肉の丼料理です
0.3099 : Q: EC2とは何ですか? A: 仮想サーバーサービスです
1位から5位までは、良い感じに「AWS」関連のレコードを抽出できてますね!
しかし、9番目に注目すると、
「牛丼 」!?!?
一体 「牛丼」 と 「AWS」 にどんな関連があるのでしょうか!?
どう考えても何の関わりがないので、 「ノイズ」 とみなして良さそうです。
さらに「AWS」と関わりの深い「EC2」のレコードが下位に来ています。
このような順位になってしまった理由は色々推察することは出来ますが、とにかく
ベクトル検索は完璧ではない ということも念頭に入れておいた方が良さそうです。
これで実用に耐えるのだろうかと不安を感じるかも知れませんが、ご安心ください。
RAGでは通常、抽出された結果を LLM(大規模言語モデル) に送り、ノイズデータの削除やデータの並べ替えをする処理が行われます。
この処理により、最終的には実用的な検索結果がユーザのもとに届けられます。
非IT系単語を検索してみる
では、せっかくなのでIT用語でない、一般的な単語を検索してみましょう。
クエリを猫とします。
検索クエリ「猫」
🔍 検索結果(上位10件)
0.7674 : Q: 猫とは何ですか? A: 小型で俊敏な動物です
0.3786 : Q: カレーとは何ですか? A: スパイス料理です
0.3481 : Q: 犬とは何ですか? A: 人に飼われることが多い動物です
0.3475 : Q: 牛丼とは何ですか? A: 牛肉の丼料理です
0.3354 : Q: Pythonとは何ですか? A: シンプルで読みやすいプログラミング言語です
0.2990 : Q: PCとは何ですか? A: 個人用コンピュータです
0.2983 : Q: CSVとは何ですか? A: カンマ区切りのデータ形式です
0.2875 : Q: CI/CDとは何ですか? A: 自動ビルドとデプロイの仕組みです
0.2827 : Q: 映画とは何ですか? A: 映像作品です
0.2825 : Q: Pythonのリストとは何ですか? A: 複数の値を保持する構造です
確かに1位は目的の文書が出てきていますが、それ以降がどうもしっくり来ません。
クエリをもう一工夫してみましょう。
今度は普通に質問する様な形で、自然言語でクエリを投げてみましょう。
クエリを猫はどういう動物ですか?とします。
すると、
検索クエリ「猫はどういう動物ですか?」
🔍 検索結果(上位10件)
0.8392 : Q: 猫とは何ですか? A: 小型で俊敏な動物です
0.5756 : Q: 犬とは何ですか? A: 人に飼われることが多い動物です
0.4547 : Q: 魚とは何ですか? A: 水中で生活する生き物です
0.4065 : Q: 牛丼とは何ですか? A: 牛肉の丼料理です
0.4057 : Q: PCとは何ですか? A: 個人用コンピュータです
0.4056 : Q: Pythonとは何ですか? A: シンプルで読みやすいプログラミング言語です
0.3960 : Q: カレーとは何ですか? A: スパイス料理です
0.3633 : Q: Pythonのリストとは何ですか? A: 複数の値を保持する構造です
0.3472 : Q: CSVとは何ですか? A: カンマ区切りのデータ形式です
0.3358 : Q: コーヒーとは何ですか? A: カフェイン飲料です
今度は上位3位が「動物シリーズ」で占められました!
4位の「牛丼」は「牛」という単語で引っ張られたのだと推測できます。
よって今回の場合、実用的な検索結果は「トップ3件」ということが言えそうです。
自然言語でのクエリの場合はより類似度が上がり、短い単語のクエリだと結果がブレやすくなるということも確認出来ました。
この違いは、次の章でお話する「埋め込み(embedding)」の仕組みを知ることによって考察できそうです。
ベクトル検索結果のまとめ
ここまでいくつか検索を試してみましたが、結果をまとめると以下のような特徴が見えてきます。
✅ベクトル検索の「良い点」
- 「DB」→「データベース」がヒットする
- 自然な文章でも検索できる
- 関連する概念(猫 → 犬 → 魚)も取得できる
👉 意味ベース で検索できている
❌ベクトル検索の「気になる点」
- 「牛丼」などのノイズが混ざる
- 順位が直感と少しズレることがある
- クエリの書き方によって結果が変わる
つまり
👉 「かなり賢いが、完璧ではない」 検索
なぜこのようなことが起きるのか?
ここが重要なポイントです。
これらの挙動はすべて、
「embedding(埋め込み)」の仕組み
によって説明することができます。
⸻
次の章では、
- 文字がどのようにベクトルに変換されるのか?
- なぜ意味で検索できるのか?
について、直感的に理解できるように解説していきます
embeddingとは何か(直感的に理解する)
ここまでの実践で、
- 文章を 「意味」 で検索できる
- スコアで順位がつく(ヒットするかorしないか、ではない)
ということが分かりました。
では、なぜこのようなことが可能なのでしょうか?
その原理を少しだけ解明していきたいと思います。
言葉を「ベクトル」に変換する
前半の部分で、「文章」→「ベクトル」のコードを動かしてみましたが、この部分をもう少し深掘りしていきます。
まず、そもそも ベクトルとは一体何なのか? について
「ベクトル」とは、見かけ上は「数値」のグループです。
[2, 3, 9, 1, ...]
[0.1, 0.4, 0.3, 0.1, ...]
のようになっていて、同じ目的の「ベクトル」であれば、この数値の個数は固定されているのが普通です。
この数値の個数のことを 「次元数」 と呼びます。
この「次元」は、日常でもよく使われる「2次元(=平面)」とか「3次元(=空間)」、「4次元(=超空間?)」と同じです。
しかし、数学やAIの世界ではこれを超える次元数が平気で出て来ます。
例えば、前半で使用した埋め込みモデルの場合、「384次元」のベクトルを使いますし、精度の高いモデルだと「1536次元」「3072次元」を取り扱ったりします。
ここまで来ると、「空間」からイメージする事は難しいので(不可能)、 「ベクトル」は「決まった個数の数値の配列」 という理解で全然問題ありません。
※「並び順」が重要なので「グループ」というよりは「配列」で理解した方が良さそうです
とにかく、embedding(=埋め込み)とは
「文章」を「決まった数の数値の配列」に変換すること
なのです。
では、どのようなルールで「数値に変換」しているのでしょうか?まさかデタラメにやっているわけではありません。
ただこのルールは 「モデル自身が学習によって身に付けたルール」 なので、他人に説明するのが大変難しいことになっています。
「学習」とは、具体的にはとてつもない量(数億〜数兆)のテキスト(コーパス)を読み込むことを指しています。
「学習」をすることで、単語の意味が分からなくても、単語同士の類似関係が推測できるようになります。
例えば、
猫を飼っている。
という文書が大量にあったとします(実際たくさんありそうです)
同じく
犬を飼っている。
という文書もまた大量にあったとすると、
『よく分からないが、「猫」と「犬」は「飼うもの」なんだな』
『じゃ似たようなものなんだな』
という推測が成り立ちます。
さらに
ペットを飼っている
ペットショップで魚が泳いでいる
という文章が見つかれば、
『「猫」とか「犬」というのは「ペット」と呼ばれるものなんだな』
『だったら「魚」も近いんじゃなかろうか』
と連想が繋がっていきます。
そこで、モデルは「猫」「犬」「魚」を良い感じに、お互い近くに配置(埋め込み)していきます。
実際は「高次元」に埋め込まれますが、イメージとして2次元で表すとこんな感じです。

そして、「関連のなさそうな単語」は離れた場所に埋め込みしていきます。
「AWS」や「Redshift」といったIT用語を埋め込むと以下のようなイメージになります。
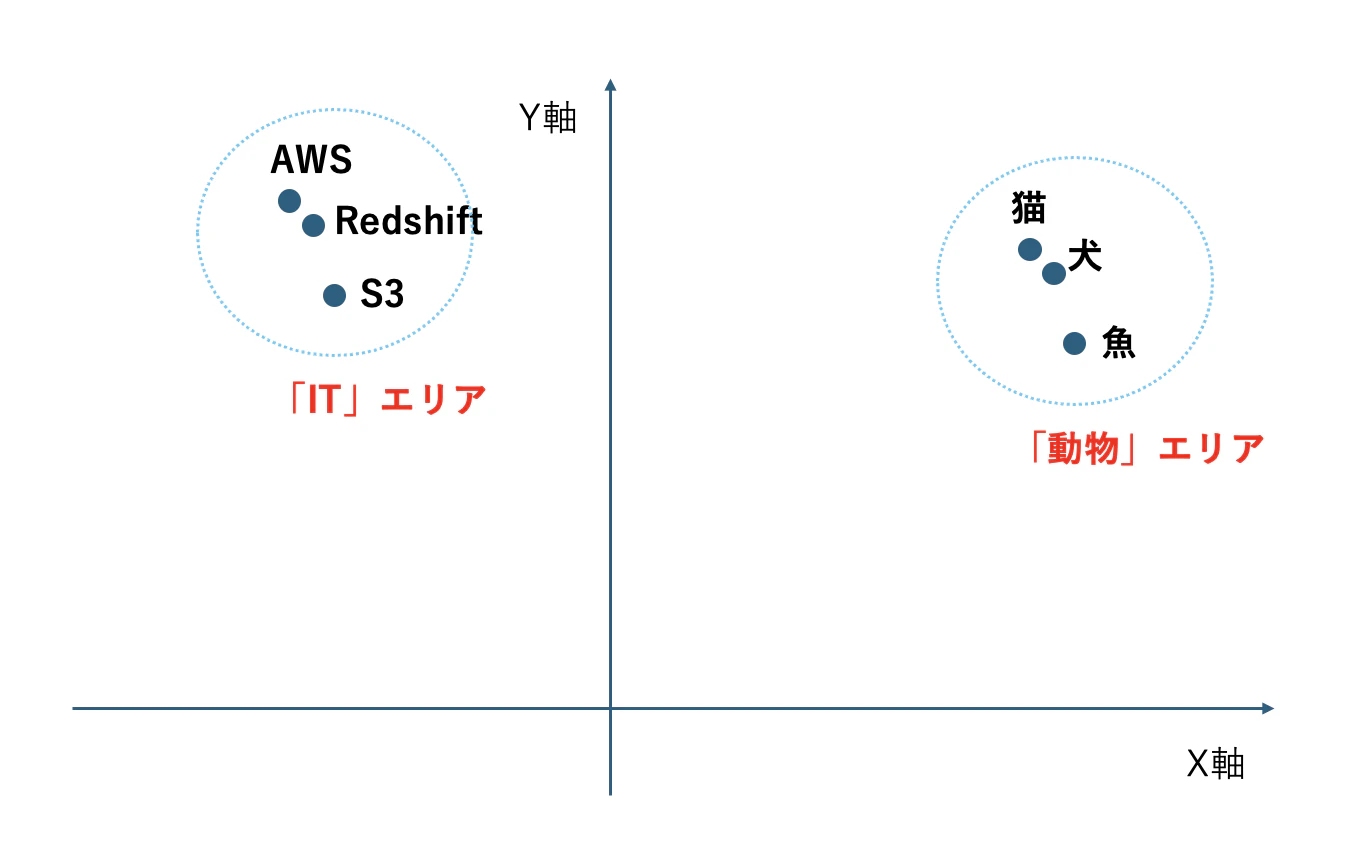
繰り返しますが、これはあくまでもザックリとした理解のためのイメージで、実際は「X軸」「Y軸」以外に「軸」がたくさん(数百〜数千)あり、人間には理解不能な「超空間」に埋め込まれます。
とは言え、超空間と言ってもただの「数値の集まり」なので恐れる必要はありません。
さらに、「埋め込みモデル」は「単語」だけではなく「文章」「文書」も一気にベクトルに変換(=埋め込み)することが出来ます。
ここのロジックに関しては直感的な理解は難しいので、とにかく結果的に 「意味が似ている」「方向性が似ている」文章は近くに配置される 、ということを押さえておけば大丈夫です。
以上をまとめます。
👉 埋め込み(embedding)とは「意味を座標として配置すること」
👉 埋め込みモデルは、単語や文章の類似性を踏まえて「意味の空間」に配置してくれる
では、こうして埋め込まれたベクトルの「近さ」はどのようにして計算するのか?についてお話しします。
ベクトル間の「距離」を測る
ベクトル間の「距離」がすなわち単語間の 「意味の離れ具合」 を示していると考えられます。
なので、これを数学的に計算する必要があります。
真っ先に思い付くのが、 直線距離 です。
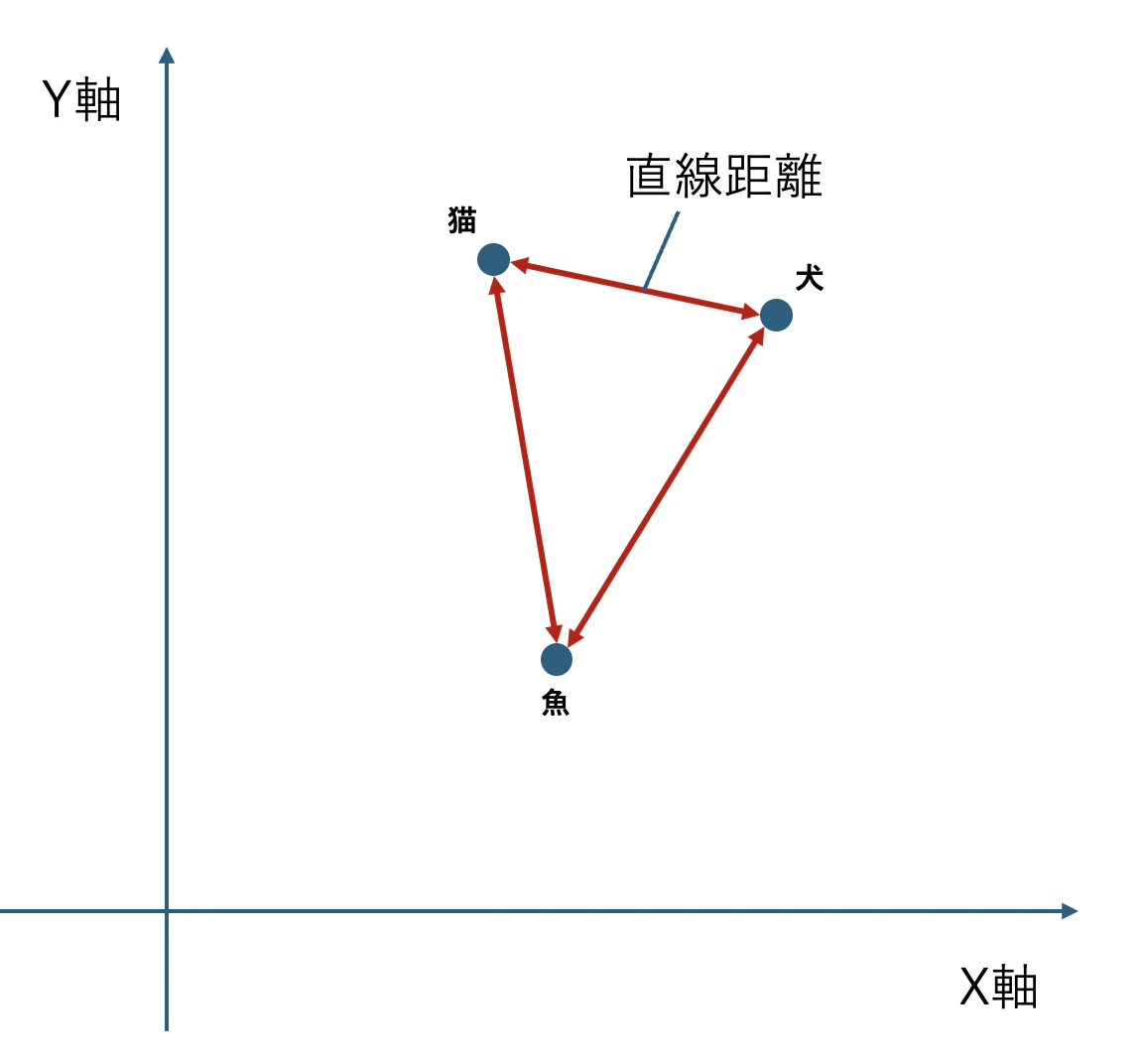
直線距離なら計算が簡単だし(各ベクトルの数値の差を取って2乗、これらを足し合わせて平方根を取る)、類似度を測るには一見最適に見えます。
しかし、実は落とし穴があります。
実際に埋め込みをしていくと、「方向性は合ってるんだけど、距離が大分離れている」というようなケースが出てくるのです。
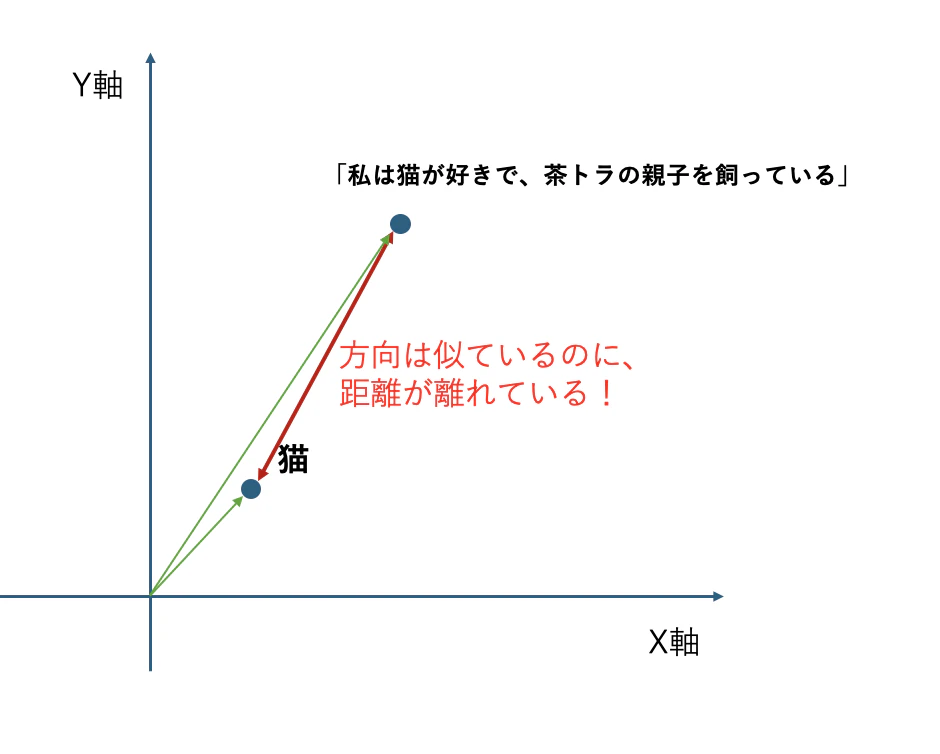
典型的な例としては、元の文章の「トークン数(いったん文字数と考えてください)」が大きく異なるとこのような結果になりやすいです。
猫
と
「私は猫が好きで、茶トラの親子を飼っている」
は「方向性」はだいぶ近いのですが、文章量が異なるため距離が離れてしまっています。
実際は文章量だけでなく、文脈や意味の強さによって距離が変わってきます
ではどうするか?
今度は「距離」ではなく 「角度」 で比較するのはどうでしょうか?
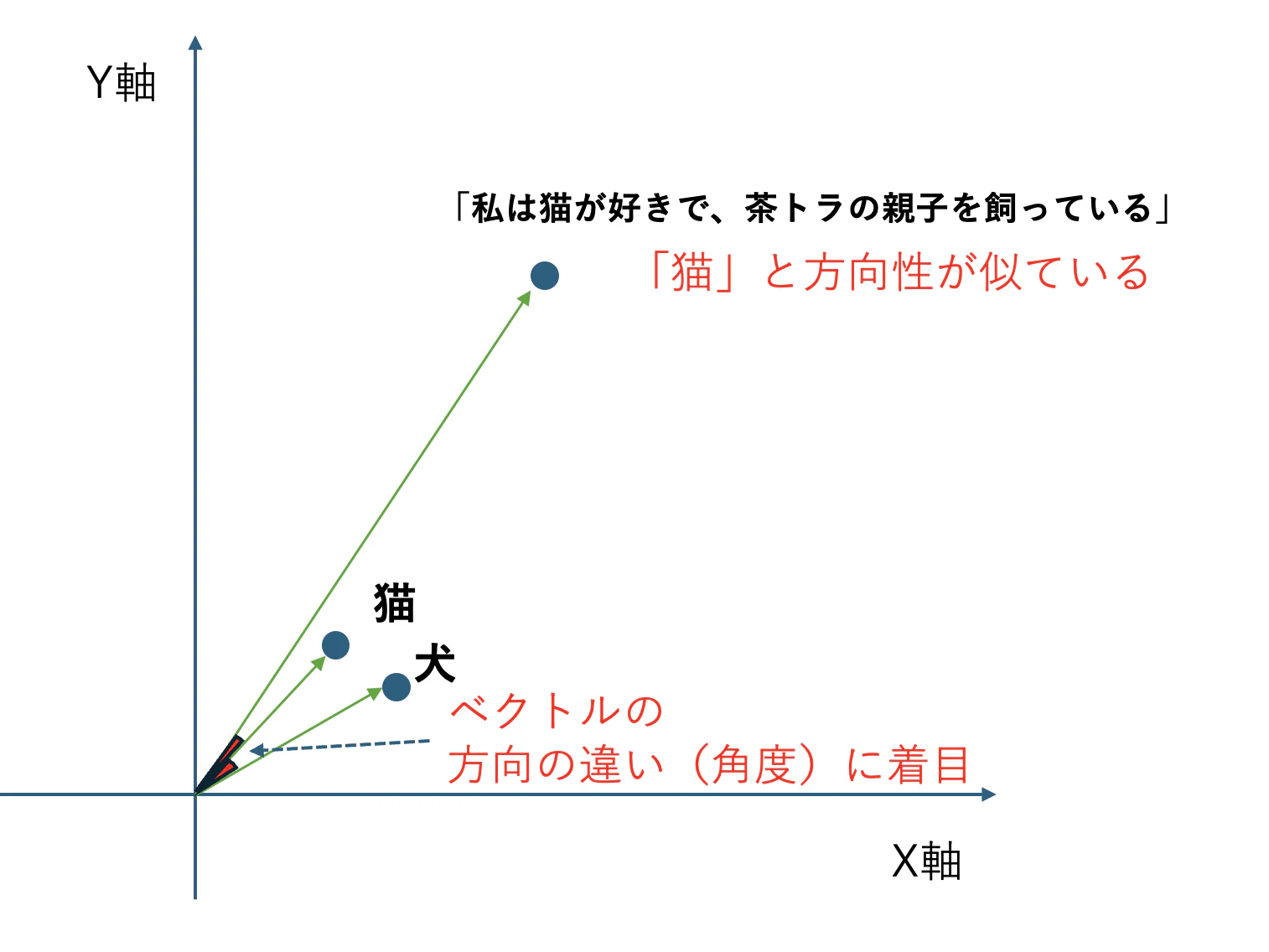
この図のように、ベクトルの「なす角度」を求めれば、「方向性は似ているけど長さが違う」文も比較しやすくなりそうです。
0° → ほぼ方向性が同じ(似ている)
30° → 少し似ている
90° → 全く似ていない
という具合です。
ただ、「なす角」の計算はちょっと面倒なので(逆コサイン関数が必要)、こうした場合角度の 「コサインを取る」 と便利です。
コサインを取ると角度が -1から1までの範囲内の数値になります。
そしてベクトルの数値があれば簡単な計算で求めることができるので、高速に類似度の計算も可能になります。
こうして計算された値は 「コサイン類似度」 と呼ばれ、RAGの検索において広く使われています。
まとめますと、
👉 ベクトルの「方向」=意味
👉 ベクトルの「長さ」=意味の強さや分布(文の長さに影響されることもある)
👉 RAGの検索では質問と回答の長さが異なる ⇨ 「方向」を見るのが重要
👉 「方向」の違いは「コサイン類似度」で簡単に計算できる
コサイン類似度の計算
コサイン類似度の計算は、ベクトルの値が分かっていれば驚くほどシンプルです。
大まかに言うと、
コサイン類似度 = ベクトルの内積 ÷ ベクトルの長さを掛けたもの
です。
では分解していきます。
ベクトルの内積とは?
内積は、ベクトルの要素同士を掛け合わせたものを、さらに足し合わせたものです。
例えば、以下のような2つのベクトルがあったとします。
(※実際に埋め込まれるベクトルの数値は-1~1の範囲ですが、話を簡単にするために適当な整数にしてあります)
ベクトルA
[2,3,1,0]
ベクトルB
[1,0,5,3]
そうするとAとBの内積は
(2 x 1) + (3 x 0) + (1 x 5) + (0 x 3)
= 7
で求められます。
簡単ですね!
ベクトルの長さ
こちらはおなじみの「ピタゴラスの定理」の応用です。
直角三角形の斜辺の長さを求めたい時は、
底辺の2乗 + 高さの2乗 → ルート(平方根)を取る
でしたよね。
実は高次元でも全く同じで、
ベクトルの長さ = 各ベクトルの数値を2乗したものを足し合わせ、ルートをとる
で求められます。
これをA, B 両方求めておきます。
先ほどの例で言うと、
ベクトルA
[2,3,1,0]
長さは
ルート(2x2 + 3x3 + 1x1 + 0x0)
≒ 3.74
ベクトルB
[1,0,5,3]
長さは
ルート(1x1 + 0x0 + 5x5 + 3x3)
≒ 5.92
となります。
これらを先ほどの「ベクトルの内積 ÷ ベクトルの長さを掛けたもの」
に代入すると、
コサイン類似度 = ベクトルの内積 ÷ ベクトルの長さを掛けたもの
なので、
AとBのコサイン類似度 = 7 / (3.74 x 5.92)
= 0.316...
ということになります。
このように、電卓やエクセルで簡単に求められるのですがPythonプログラム上ではnumpyライブラリを使って以下の部分で計算をしています。
# cosine類似度(スコア)を計算(1に近い方が「似ている」)
score = np.dot(q_vec, vec) / (
np.linalg.norm(q_vec) * np.linalg.norm(vec)
)
こうして求められたコサイン類似度の値は -1 ~ 1 までの間の範囲を取り、以下のように類似度を数値で判断することが可能になります。
1 → ほぼ一致している(角度は0°)
0.7 → かなり似ている(角度は45°くらい)
0.5 → まあまあ似ている(角度は60°)
0.25 → あまり似ていない(角度は75°くらい)
0 → 全く似ていない(角度は90°)
-1 → 全く正反対(角度は180°、実際にはほぼ出ない)
ただし 0未満の値(負の値)は実際には非常に出にくく、0 ~ 1 までの値で判断すると思ってもらって構いません。
埋め込まれた数値の分布は、モデルの種類によって変化します。
今回用いた'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'
というモデルは、正の値に寄せるような設計になっているようです。
モデルによっては負の値が出てくることも考えられます。
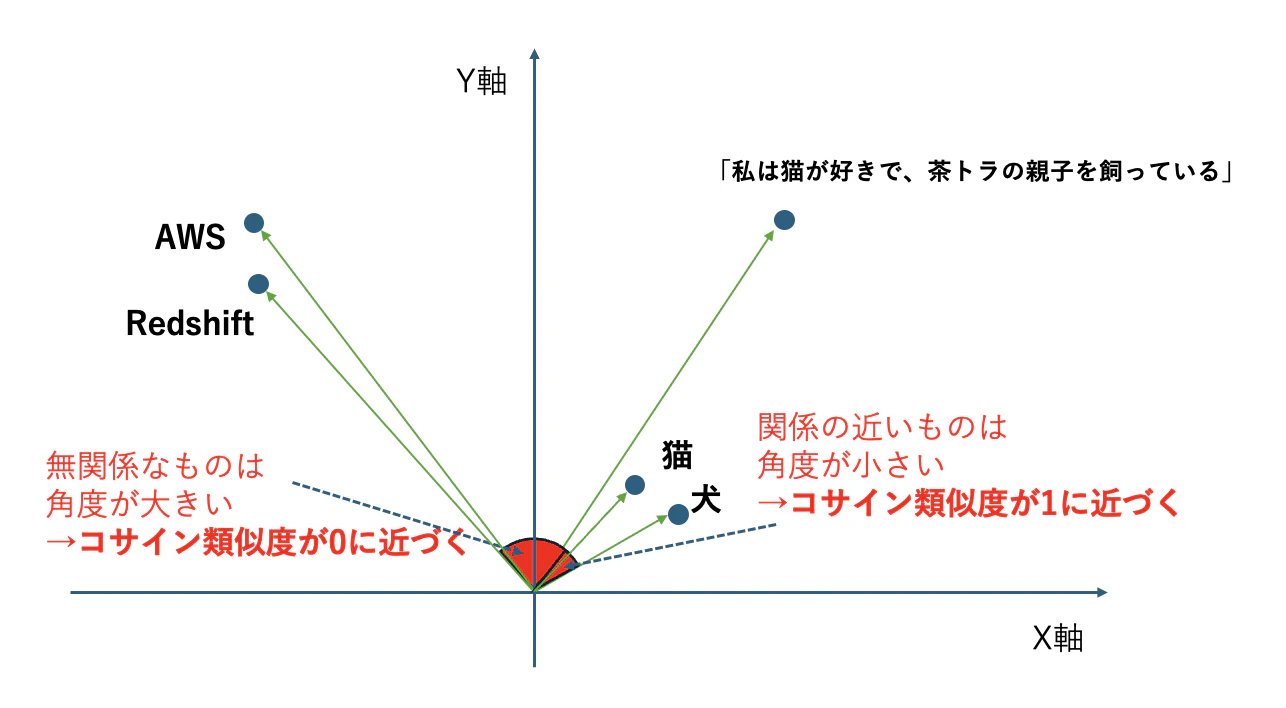
※ 角度が小さいほどコサイン類似度は1に近づく
まとめ
何となく、embeddingについてのイメージが湧きましたでしょうか?
RAG検索は「なかなか思い通りに行かない」&「地道な試行錯誤が重要」な技術であります。
その際に、「基本のキ」を押さえておくと対策も練りやすいし、無駄な努力をせずに済むと思います。
さて、つづきは次回👇に展開したいと思います。