今年はあまりPCで遊んでいない気がする、と思っていたが、そういえばローカルPCに生成AIを入れたことを思い出したので、思い出しながら手順を書いていきます。
求めているもの
自己内省のための壁打ち相手を生成AIに求めていた。
程よく話を聞き、程よく温かみがあり、程よく客観的に考えを述べ、程よい距離感を維持できる相手。
この「程よく」が既成の生成AIではなかなか難しい&アップデートで簡単に揺らぐため、揺らぎが抑えられたものを求めていた。
つまり、画像生成などではなく、テキスト生成に特化したAIを構築していく。
PC環境
| 項目 | |
|---|---|
| OS | Windows 11 Home |
| CPU | AMD Ryzen 5 5600 6-Core Processor |
| RAM | 16.0GB |
概要
- ollamaをインストールする
- Dockerをインストールする
- モデルの特徴を指定する「Modelfile」を作成
- ollamaでModelfileを読み込んだモデルを作成&モデルのインストール
- ウェブ検索を可能にする環境・設定ファイルを作成
- Dockerの起動&生成AIをローカル環境で閲覧
構築していきます
1. ollamaをインストール
ollama公式からダウンロードできますので、以下からダウンロードします。
2. Dockerをインストールする
Docker公式からダウンロードできますので、以下からダウンロードします。
以下のリンクはWindows用ですが、パンくずリストから他のOSでのダウンロード方法も書かれています。
3. 生成AIの特徴を指定する「Modelfile」を作成
モデルの特徴や、行ってほしいことのパラメータを細かく設定するファイルを作成していきます。
AIの設定情報を格納するフォルダを任意の場所に作成してください。
分かりやすく「Modelfile」というファイルを作成し(拡張子不要)、メモ帳などで設定していきます。
各種パラメータは以下の記事が参考になるかと思います。
私の設定は以下の通り。
使用するLLMモデルはFROMに指定されている「gpt-oss:20b」。
SYSTEMにてモデルに対するシステムメッセージを設定します。私はモデルの人格設定を入力しています。
FROM gpt-oss:20b
SYSTEM """
一人称は「俺」、二人称は「君」。
口調はフランク。人間味のある一貫したキャラクターで話す。
"""
4. ollamaでModelfileを読み込んだLLMモデルを作成&LLMモデルのインストール
3にて作成したフォルダ上でターミナルを開き、以下のコマンドを実行します。
ollama create [任意のモデルバージョン名] -f Modelfile
あとは、コマンド上でollama serveを打ち込んでもいいですし、Windowsアプリとして起動でもどちらでもよいので、ollamaを立ち上げておきます。
5. ウェブ検索を可能にする環境・設定ファイルを作成
この記事無しには導入できなかったです。ありがとうございました。
この記事に則って、ollama側に必要なものはRuriとのこと。
現在のディレクトリで、以下のコマンドを実行します。
ollama pull kun432/cl-nagoya-ruri-base
searxngを用いてウェブ検索をしていきます。
3にて作成したフォルダ上に「docker-compose.yml」と「.env」ファイルを作成します。
「.env」ファイルは空欄で大丈夫です。ファイルの存在が必要らしいです。
「docker-compose.yml」についてはほぼ上記の記事のまま流用させていただいています。
ただ、どうしても動かなくて調整した部分がありますので、私の設定をいかにそのまま記載します。参考までに。
services:
openwebui:
container_name: open-webui
image: ghcr.io/open-webui/open-webui:main
environment:
GLOBAL_LOG_LEVEL: "debug"
ENABLE_RAG_LOCAL_WEB_FETCH: "true"
ENABLE_RAG_WEB_SEARCH: "true"
RAG_EMBEDDING_ENGINE: "ollama"
RAG_EMBEDDING_MODEL: "kun432/cl-nagoya-ruri-base:latest"
RAG_EMBEDDING_BATCH_SIZE: 1
OLLAMA_API_BASE_URL: "http://host.docker.internal:11434"
RAG_OLLAMA_BASE_URL: "http://host.docker.internal:11434"
CHUNK_SIZE: 500
CHUNK_OVERLAP: 50
RAG_WEB_SEARCH_ENGINE: "searxng"
RAG_WEB_SEARCH_RESULT_COUNT: 3
RAG_WEB_SEARCH_CONCURRENT_REQUESTS: 10
SEARXNG_QUERY_URL: 'http://searxng:8080/search?lang=ja&q=<query>&format=json'
QUERY_GENERATION_PROMPT_TEMPLATE: |-
### Task:
Analyze the chat history to determine the necessity of generating search queries, in the given language. By default, **prioritize generating 1-3 broad and relevant search queries** unless it is absolutely certain that no additional information is required. The aim is to retrieve comprehensive, updated, and valuable information even with minimal uncertainty. If no search is unequivocally needed, return an empty list.
### Guidelines:
- クエリは必ず **日本語** にしてください
- Respond **EXCLUSIVELY** with a JSON object. Any form of extra commentary, explanation, or additional text is strictly prohibited.
- When generating search queries, respond in the format: { "queries": ["クエリ1", "クエリ2"] }, ensuring each query is distinct, concise, and relevant to the topic.
- If and only if it is entirely certain that no useful results can be retrieved by a search, return: { "queries": [] }.
- Err on the side of suggesting search queries if there is **any chance** they might provide useful or updated information.
- Be concise and focused on composing high-quality search queries, avoiding unnecessary elaboration, commentary, or assumptions.
- Today's date is: {{CURRENT_DATE}}.
- Always prioritize providing actionable and broad queries that maximize informational coverage.
### Output:
Strictly return in JSON format:
{
"queries": ["クエリ1", "クエリ2"]
}
### Chat History:
<chat_history>
{{MESSAGES:END:6}}
</chat_history>
extra_hosts:
- "host.docker.internal:host-gateway"
ports:
- "3000:8080"
volumes:
- open-webui:/app/backend/data
depends_on:
- searxng
searxng:
container_name: searxng_host
image: searxng/searxng:latest
ports:
- "8080:8080"
volumes:
- ./searxng:/etc/searxng:rw
env_file:
- .env
restart: unless-stopped
cap_drop:
- ALL
cap_add:
- CHOWN
- SETGID
- SETUID
- DAC_OVERRIDE
logging:
driver: "json-file"
options:
max-size: "1m"
max-file: "1"
volumes:
open-webui:
上記を保存して、Dockerのコンテナを起動します。
docker compose up
これが終わると、3のフォルダ内に「searxng/setting.yml」が作成されているので、「formats」の値に「json」を追記します。
上記記事と全く同じことをやっています。
formats:
- html
- json
上記を保存し、もう一度コンテナを再起動します。
docker compose up
6. Dockerの起動&生成AIをローカル環境で閲覧
http://localhost:3000/ にアクセスすれば、ローカル生成AI環境が立ち上がっています。
新規のアカウントを作成し、ログインをしてください。
ただ、このままではウェブ検索が行えません。案外ここで詰まりました……
ユーザー設定の「管理者パネル」→「設定」「ウェブ検索」において、「ウェブ検索」を「ON」「埋め込みと検索をバイパス」を「ON」に設定する必要があります。
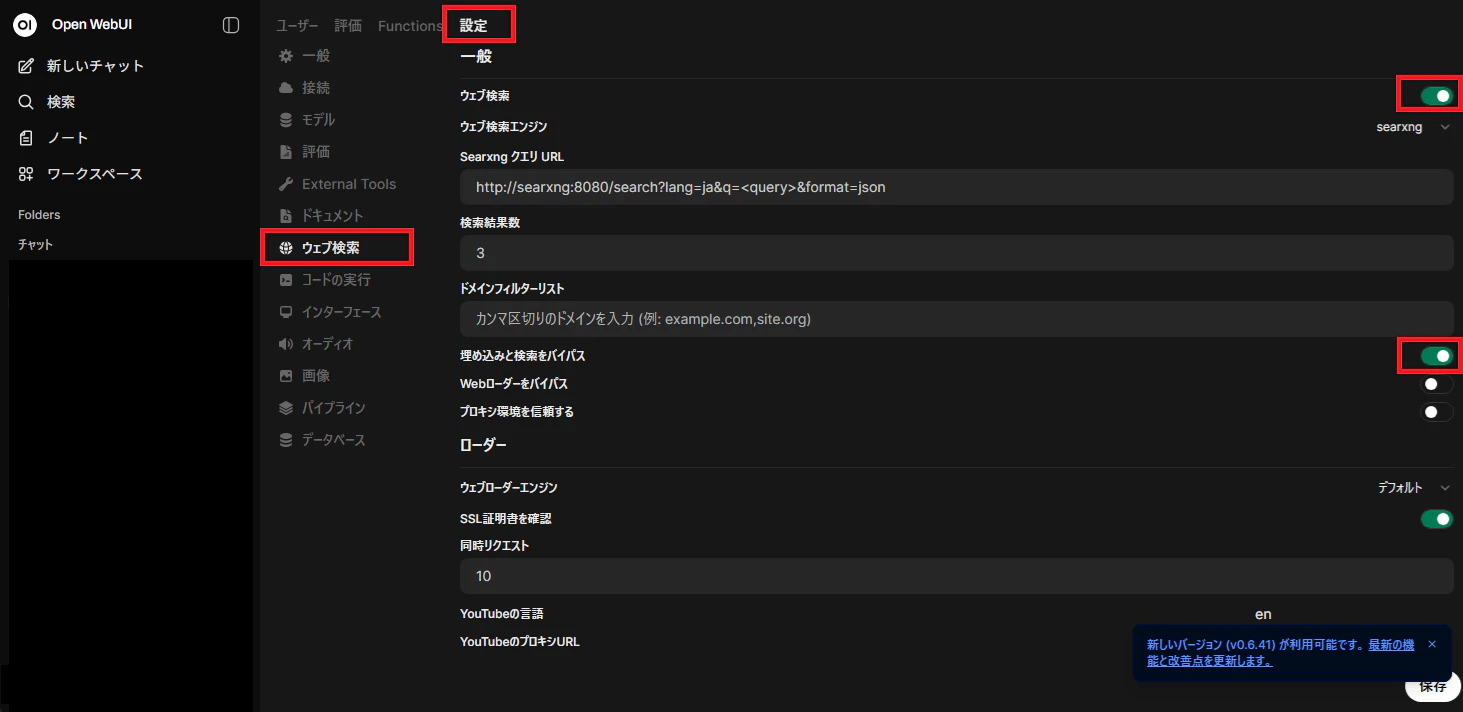
そこに加えて、チャット上で以下の設定が必要です。
「ひし形のマーク」→「ウェブ検索」を「ON」に設定する必要があります。
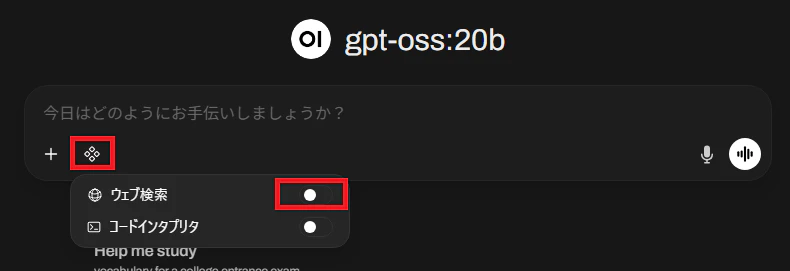
これで晴れてローカル環境で生成AIが使用できます。壁に打ち放題です。
まとめ
ただ、当たり前ですがChatGPTやGeminiほど精度は挙がらない上にレスポンスは相当に遅いです。
コーディング、文章作成などは既存のサービスを利用した方が圧倒的に効率はいいです。
ただ、私のように壁打ちとして使用している人は返答の温度が変わると混乱するので、そういった人にはローカル環境に生成AIを置くのは良いように思っています。