はじめに
こんにちは.私は普段,機械知能研究室に所属し,画像の品質評価に関する研究をしています.研究室のHPはこちらです.
生成AIの進化は留まることを知らず,日々新しいモデルが発表されてしますが,2026年4月にリリースされた「ChatGPT Images 2.0」は,大きなインパクトを与えています.
これまでStable Diffusion,DALL・E 3などで画像生成をしてきた際,多くの人が一度は悩んだ経験があるのではないでしょうか.
「日本語の文字がどうしても化けてしまう」
「複雑な構図を指定しても,細部が指示通りにならない」
「生成するたびにキャラクターの顔やスタイルが変わってしまう」
こうした課題に対して,ChatGPT Images 2.0は「Thinking(推論)モード」という強力な武器を携えて登場しました.単にプロンプトを解釈して絵を描くだけでなく,生成前にWeb検索や自己検証を行うこのモデルは,果たして我々の開発や制作ワークフローにどれほどの変革をもたらすのでしょうか.
本記事では,ChatGPT Images 2.0の概要を整理した上で,実際にいくつかのプロンプトを試し,その実力を検証します.
最新モデルの実力に興味がある方,これから業務や個人開発に画像生成を組み込みたいと考えている方の参考になれば幸いです.
目次
ChatGPT-Images-2について
2026年4月21日,OpenAIから発表された最新の画像生成モデル「ChatGPT Image 2.0(モデル名:GPT-image-2)」は,従来のモデルからアーキテクチャが刷新され,「推論(Thinking)モデル」とネイティブに統合された初の画像生成モデルです.
また,APIを通じて比較的容易に利用できる点も特徴の1つです.
現在,GPT-image-2はChatGPT経由のみでの使用になっています.しかし,APIが近いうちにワークフロー自動化に組み込めるのではと考えています.
では,GPT-image-2の特徴について理解していきたいと思います.
早速,ChatGPT Images 2.0で画像を生成してみたい方はこちらから!
ChatGPT Images 2.0の公式HP
GPT Image 2の画像生成ページ
ChatGPT Images 2.0のモデルのアーキテクチャは公開されていませんが,「旧モデル(DALL・E 3)とは異なり,アーキテクチャごと刷新された全く新しいモデル」であることは明らかになっています.
ChatGPT Images 2.0の特徴としては以下があげられます.
-
文字描画のパラダイムシフト
画像生成AIの弱点で最大の課題であった「日本語の文字描画」の精度が約99%に達しました.漢字,ひらがな,カタカナが崩れずに出力されるため,ポスター,インフォグラフィック,UIモックアップなど,これまで「後から文字を足す」しかなかった作業が,生成段階で完結するようになりました.
日本語だけでなく,非ラテン系文字全般で精度が向上しています.
-
生成前に「計画」するThinkingモード(有料)
従来の生成AIは,プロンプトを直接ピクセル情報へと変換していましたが,GPT-image-2は違います.
GPT-image-2は,OpenAI初となる推論機能を備えた画像生成モデルです.ユーザーがプロンプトを入力すると,モデルはまず「何を生成すべきか(構図,テキストの内容,色彩の意図)」を論理的に推論します.必要であれば,Web検索を実行して最新のビジュアルトレンドや事実情報を参照し,「設計図」を作ってから生成を開始します.これにより,以前は苦手だった「指示への忠実度」や「論理的な配置」が劇的に向上しました.
-
クリエイティブ面の強化(スペックの向上)
-
高解像度出力:
- 最大2kの解像度に対応
-
柔軟なアスペクト比:
- 16:9のワイド構図から3:1~1:3まで自由に指定可能
-
マルチターン編集:
- 同一キャラクターのポーズや表情を変えて生成する「一貫性制御」
- 画像内の特定部位を指定して修正する「リージョン制御」が追加
-
同時複数生成:
- 1つのプロンプトから最大8枚の画像を同時生成
- 3×3のグリッドでストーリーボード(絵コンテ)形式の出力が可能
特徴 旧モデル(DALL・E 3) ChatGPT Images 2.0 思考プロセス 即時生成 推論(Thinking)後に生成(有料プラン) 日本語描画 誤字・脱字が頻発 正確(実用レベル) 活用領域 イラスト・アート・趣味 業務資料・バナー・プロトタイプ 知識ソース 学習データのみ Web検索統合による最新事実の反映 -
高解像度出力:
ChatGPT Images 2.0の画像生成方法(使い方)
現状,ChatGPT経由での画像生成はGPT-Image-2に完全移行しています.
GPT-Image-1/1.5を使用して
ChatGPT Images 2.0は,ChatGPTのサイドバー,またはモデル選択から「Image 2.0(Thinking)」(※有料プランの場合.無料版は通常モデル)を選択します.
もちろん,通常のチャット(GPT-4o/o1等)において,「画像を生成して」と頼むだけでも自動的に最適なツールとして呼び出されます.
-
プロンプトの書き方
高品質な画像を生成するためには,より具体的で構造化されたプロンプトが推奨されています.-
テキストの明示:画像内に文字を入れたい場合は,
「 」や""で囲み,明示します.日本語の描画精度が99%に向上しているため,複雑なキャッチコピーも指定可能です. -
アスペクト比の指定:
--ar 16:9のようなパラメータ指定も可能ですが,「スマホの壁紙サイズで」といった自然言語での指定が可能となりました.(3:1の超ワイドから1:3の超縦長まで対応) - スタイルの指定:「水彩画」や「フィルム風」などの画像スタイルの指定が可能
-
テキストの明示:画像内に文字を入れたい場合は,
-
Thinking Mode(推論モード)の発動
複雑な指示を投げると,生成ボタンを押した後にThinking Modeが発動します.- モデルが内部で「どのような構図にするか」「テキストの配置はどうするか」を組み立てる
- AIがWeb検索を行い,最新の情報を収集・検証して描画プロセスに入るため,より現実に即した,トレンドを抑えた画像を生成する
-
同時複数生成とストーリーボード機能
これまで,1回の指示で1~2枚でしたが,Image 2.0では1回のプロンプトで最大8枚まで同時生成可能になりました.
最大数である「8枚」を一度に生成したい場合は,プロンプトで明示的に指定する必要があります.「サイバーパンク風の東京の街並みを,異なる構図で8枚生成して」「ロゴデザインのアイデアを8パターン提案して」
複数のコマ割りを一度に作りたい場合も,プロンプトによって明示する必要があります.最大8~9枚の画像をストーリー仕立てで一括生成することも可能です.
3×3のグリッドで絵コンテを作って
-
生成後の「対話型編集(マルチターン編集)」
デフォルトでは,1回のプロンプトに対して,「1枚」の画像が生成されます.生成された画像に対し,一部分を拡大して再生成したり,部分的に編集したりできます.- リージョン(領域)制御:生成された画像の一部をクリック・タップして範囲指定し,部分的な修正指示を送ることができます.
「この部分に時計を追加して」
「背景をボカして」- 一貫性の保持:バリエーションを増やす際にも追加プロンプトで指示をします.マルチターンの指示が,専用の参照レイヤーによって大幅に強化されているようです.
「前回の画像のキャラクターを,別のシチュエーションで出して」
Tips: 一気に8枚生成して効率化
従来は1〜2枚ずつ様子を見ながら生成していましたが,Images 2.0では「8パターン見せて」と頼むのがおすすめです.Thinkingモードが『被らないように』バリエーションを考えてくれるので,一度のプロンプトで理想に近い画像に辿り着ける確率が上がりました.
実際に生成してみた
実際に画像を生成してみてChatGPT Images 2.0の性能を体験してみたいと思います.
ここでは,3つのシナリオで「旧モデル(DALL・E 3)」「GPT-image-2(無料版)」と「GPT-image-2(有料版)」の比較検証を行います.
現在は完全に Images 2.0 への移行が進んでおり,チャットUIから旧モデル(DALL·E 3)を呼び出すのは困難です.
今回は,インフォグラフィック(図解)という 「正確な配置と情報の階層」 が求められるタスクで比較しました.
検証1: 【 世代間比較 】旧モデル vs GPT-image-2(無料版)
検証1:世代間比較
まずは,従来のDALL・E 3(拡散モデル)と最新の GPT-image-2 の無料版(自己回帰型モデル)の差を比較します.
有料版にある「Thinking(推論)」ステップを通さない即時生成でも,モデル自体の基礎能力にどれほど差が出ているかを検証します.
生成時に使用したプロンプト
「Webアプリケーションの仕組みを説明するインフォグラフィック.左に『クライアント』,中央に『APIサーバー』,右に『データベース』を配置し,それぞれを双方向の矢印で繋いで.各要素に日本語ラベルを付けて.」
生成された画像
生成された画像
従来のDALL・E 3
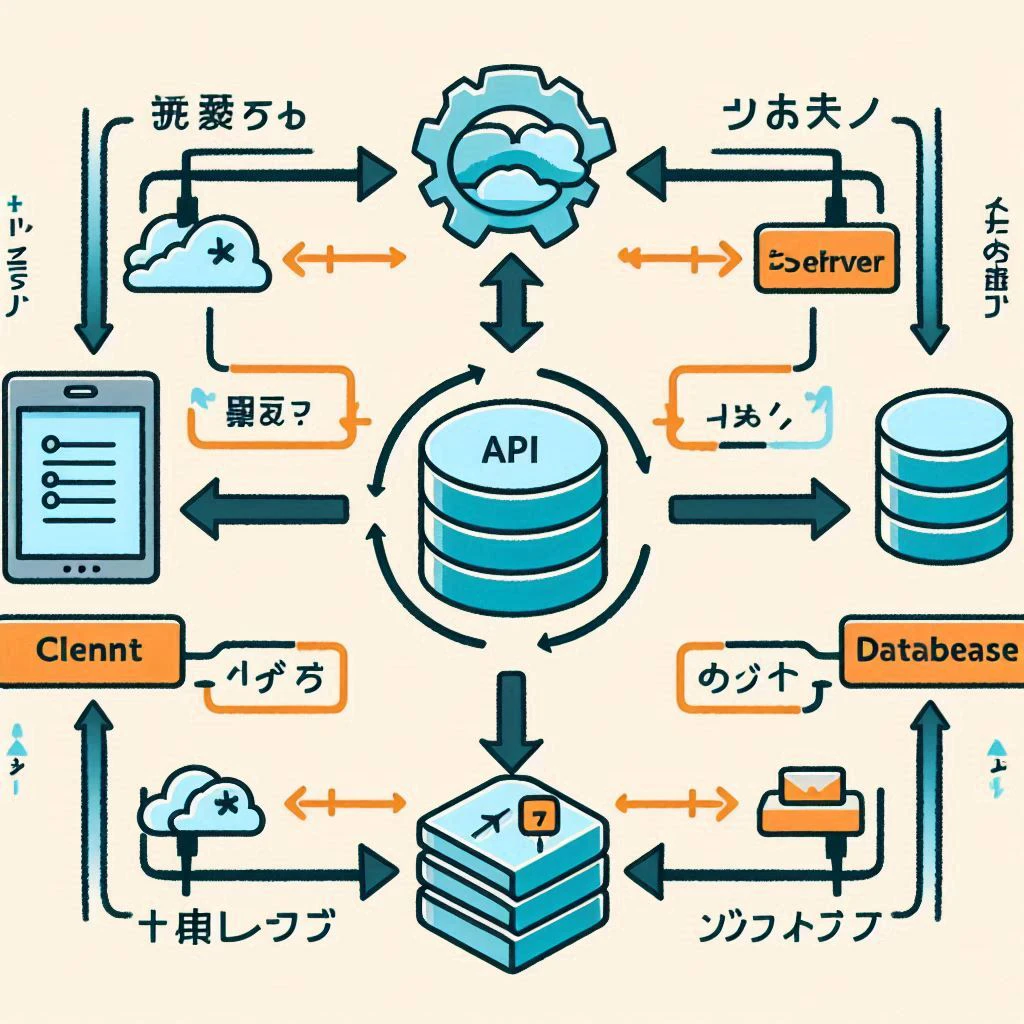
無料
検証・比較結果
| 比較項目 | 従来の DALL·E 3 | GPT-image-2 (無料版) |
|---|---|---|
| 文字の正確性 | 記号化してしまい判読不能 | 完璧な日本語として描画 |
| レイアウトの論理性 | 接続が複雑で混乱している | 3要素が明確に整理されている |
| 資料としての実用性 | 不可(アート目的) | 即戦力(資料作成に利用可能) |
結果は一目瞭然です.
- テキストの描画精度
- 従来のDALL・E 3(旧モデル): 「Clennt」「Databease」といった英語のスペルミスに加え,指示した日本語ラベルは意味をなさない記号(文字化け)として出力されています.
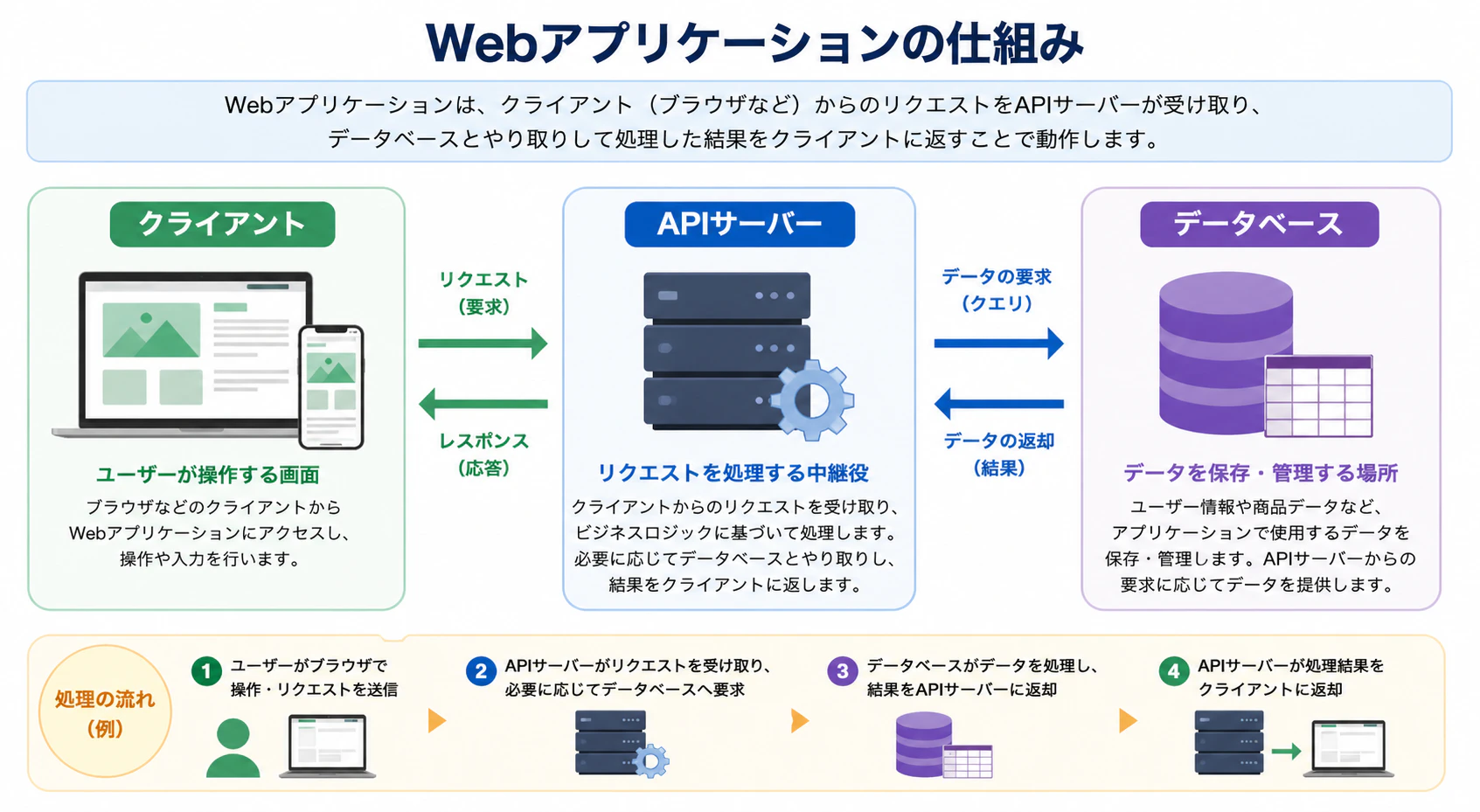
- GPT-image-2(無料版): 「クライアント」「APIサーバー」「データベース」というラベルが一字のミスもなく完璧に描画されています.さらには,プロンプトで指示していない「ユーザー情報や商品データなど…」といった詳細な解説文までもが,極めて正確な日本語で生成されています.
- 図解の論理構成と指示の遵守
- 従来のDALL・E 3(旧モデル): 「左・中央・右」という配置指示が無視され,要素が円状に散らばった非常に分かりにくい構成になっています.
- GPT-image-2(無料版): 指示通り左から右へのフローが正確に再現されています.また,「リクエスト/レスポンス」や「データの要求/返却」といった双方向の矢印に適切なラベルが付与されており,インフォグラフィックとしての論理的整合性が極めて高いです.
結論:拡散モデルから自己回帰型モデルへの刷新,およびトレーニングデータの質の向上により,旧モデルの弱点は,無料版の時点ですでに完全に克服されていることが確認できました.
検証2: 【 機能間比較 】無料版 2.0 vs 有料版 2.0(Thinking Mode)
検証1:世代間比較
同じ最新の「GPT-image-2」モデルでありますが,無料版(Instant Mode)と有料版(Thinking Mode)の生成画像にどのような違いが出るのかを見てみたいと思います.
生成時に使用したプロンプト
「Webアプリケーションの仕組みを説明するインフォグラフィック.左に『クライアント』,中央に『APIサーバー』,右に『データベース』を配置し,それぞれを双方向の矢印で繋いで.各要素に日本語ラベルを付けて.」
生成された画像
生成された画像
無料版
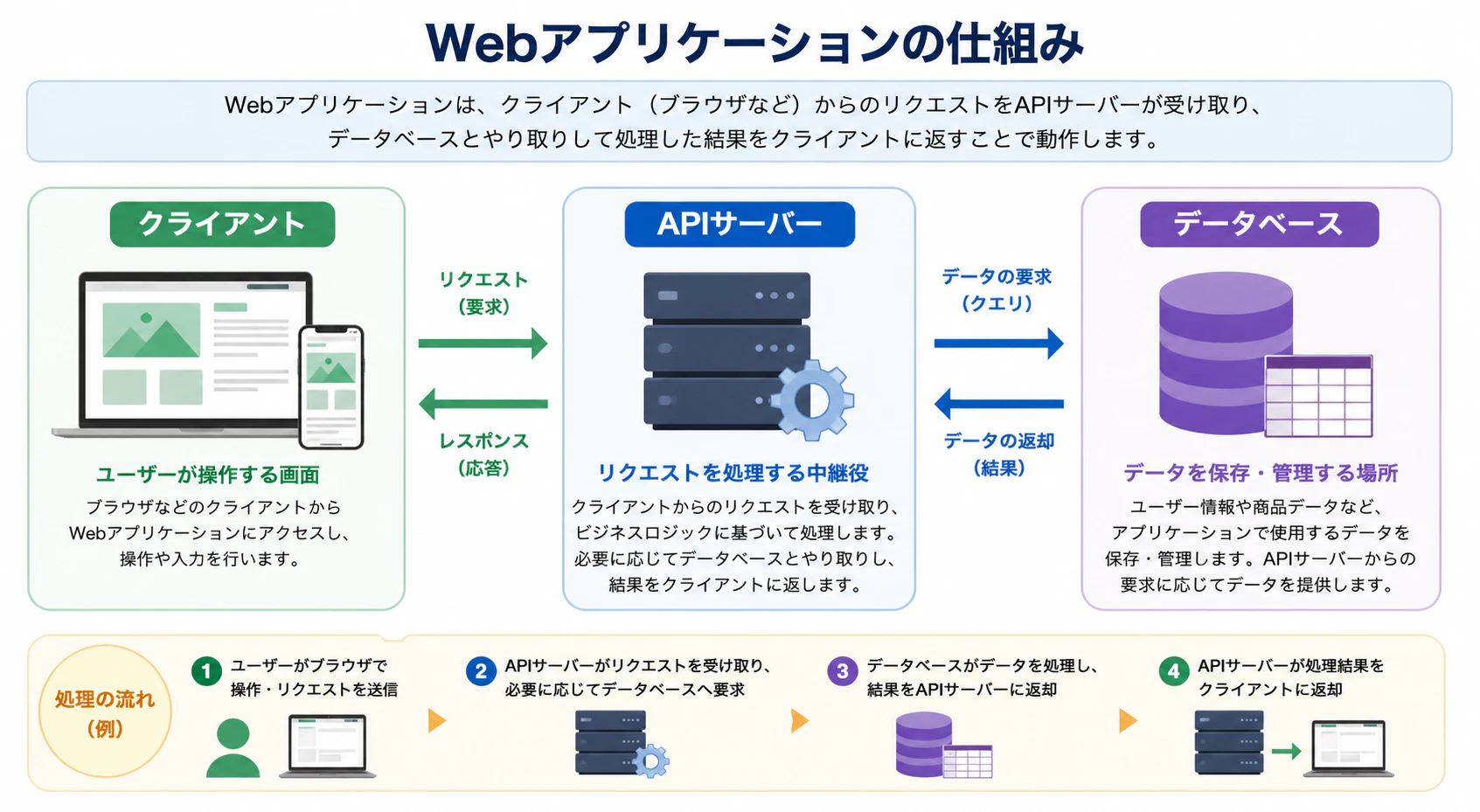
有料版
検証・比較結果
| 比較項目 | 無料版 (Instant) | 有料版 (Thinking) |
|---|---|---|
| 情報の構成 | 即時生成 | 最適化(目的の明確化) |
| デザイン性 | 教科書ようなレイアウト | 視認性を重視した構成 |
ここでは,生成プロセスの違い(即時生成 vs 推論後生成)によって,「情報の取捨選択」と「デザインの方向性」に差が現れました.
無料版(Instant Mode)は,プロンプトで支持していない「タイトル」や「導入文」,「処理の流れ(例)」などが自動生成されています.Notebool LMでの画像生成に近いものを感じます.
一方で,有料版(Thinking Mode)では,非常にシンプルかつ洗練された仕上がりであることがわかります.Thinking ステップを減ることで,情報を詰め込むのではなく,図解としてのわかりやすさ,視認性を優先したと考えられます.ビジネスの資料やスライドにそのまま組み込む用途には,こちらの方が適しているかと思います.
有料版の価値は,「デザインの意図を汲み取り,構成案を作成してくれる」点にあるのではないかと考えます.
検証3: 【 ポテンシャル比較 】8枚同時生成と一貫性
検証1:世代間比較
これまでは,「良い画像が出るまで何度も生成し続ける」作業でしたが,GPT-image-2は「論理的にバリエーションを設計し,一括で出力する」というワークフローへと進化しました.
生成時に使用したプロンプト
「『日本の四季と近未来都市』をテーマにしたコンセプトアート.春・夏・秋・冬,そして雨・嵐・夜・夜明けの8つの異なるシチュエーションを,同時に8枚生成して.すべての画像で,央に配置された『桜の形のホログラムタワー』のデザインと,都市の基盤となるレイアウトは共通にすること.」
生成された画像(生成時間 2m31s)

生成された画像群
一貫性のある画像を複数生成することができます.








検証・比較結果
| 比較項目 | 従来の手法 | Images 2.0 (Thinking Mode) |
|---|---|---|
| 作業効率 | 1枚ずつプロンプト調整が必要 | 1プロンプトで8枚を一括生成 |
| 一貫性 | 生成のたびに異なる | タワーの形状・配置を完全固定 |
| 編集 | 構図・スタイル・細部などが変わってしまう | 部分的な編集が可能 |
検証結果より,プロンプトで指示した 「中央に配置された桜の形のホログラムタワー」のデザインと都市の基本レイアウトが,全8枚の画像で完全に統一 されています.その上で,「春・夏・秋・冬」の季節感や,「雨・嵐・夜・夜明け」といった気象条件・時間帯の変化だけを正確に反映させています.これは,同一キャラクターや同一空間を舞台にしたストーリーボード制作において,決定的な解決策となります.
8枚同時生成と高度な一貫性の両立は,ゲームのコンセプトアート,漫画の背景設定,広告のバリエーション制作など,クリエイティブ現場の生産性を劇的に変えるポテンシャルを秘めていると考えます.
ちなみに,対話型編集(マルチターン編集)も試してみました.
同時生成された『桜の形のホログラムタワー』の画像群の中の1枚に,追加プロンプトで編集をお願いすると,,,
夕焼けにして.

構図は変わらぬまま要望にあった画像を生成してくれました.
さらに,リージョン(領域)制御では,以下のようにお願いすると,,,
選択部分を向日葵にして.

思ったより,向日葵の主張が強くなりました.
従来の画像生成では困難でしたが,個人の好みの画像をより効率的に,より容易に生成できるようになってると感じます.
まとめ
今回の検証を通じて,最新の「ChatGPT Images 2.0」が 「推論(Thinking)能力を伴ったデザイン・設計エージェント」 へと進化しているのだと感じました.
今後は,単に画像を生成するだけでなく,「AIにどのような思考プロセス(Thinking)をさせるか」というプロンプトエンジニアリングのスキルが,これまで以上に重要になっていくのだと触ってみて感じました.
皆さんも,ぜひ一度「Thinkingモード」で新しくなった画像生成技術を体験してみてください.