この記事の目的
Chainerを使って、自分のパソコンのCPU、GPUの性能を評価してみる。
+プログラミング練習
コードはすべてこのレポにあります!!!
何をするのか
目的通りだが、
- cpu
- gpu
- gpu 2つで
の3種類を使って、次のデータ(モデル)を使って、速度評価をします。
- mnist(MLP) → 全結合NN
- cifar10(LeNet5) → CNN
- sine wave(LSTM) → RNN
みたいな感じでやっていきます。
自分の開発環境
Software
OSはUbuntu使ってます。
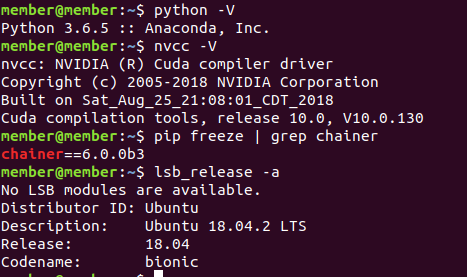
Ubuntu, chainer, python, cudaのバージョンは以下のとおりです。
Hardware
CPU -
Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz
6 core, 12 threads
GPU -
gp102 titan x 2つ
https://www.techpowerup.com/gpu-specs/titan-x-pascal.c2863
下準備
使うライブラリは以下のとおり:
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training
from chainer.training import extensions
from chainer import Chain
mnist(MLP)
mnistについて
MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセットです。さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセットです。
https://udemy.benesse.co.jp/ai/mnist.html より

MLPについて
多層パーセプトロン(たそうパーセプトロン、英: Multilayer perceptron、略称: MLP)は、順伝播型(英語版)ニューラルネットワークの一分類である。MLPは少なくとも3つのノードの層からなる。入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロンである。MLPは学習のために誤差逆伝播法(バックプロパゲーション)と呼ばれる教師あり学習手法を利用する[1][2]。その多層構造と非線形活性化関数が、MLPと線形パーセプトロンを区別している。MLPは線形分離可能ではないデータを識別できる[3]。
https://ja.wikipedia.org/wiki/多層パーセプトロン より

ということで、Chainer docsにあるMLPを参考にして、次のようにモデルを定義しました。
class MLP(chainer.Chain):
def __init__(self, n_units, n_out):
super(MLP, self).__init__()
with self.init_scope():
# Chainerがそれぞれの層を大きさを推測する
self.l1 = L.Linear(None, n_units) # n_in -> n_units
self.l2 = L.Linear(None, n_units) # n_units -> n_units
self.l3 = L.Linear(None, n_out) # n_units -> n_out
def forward(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
結果
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。
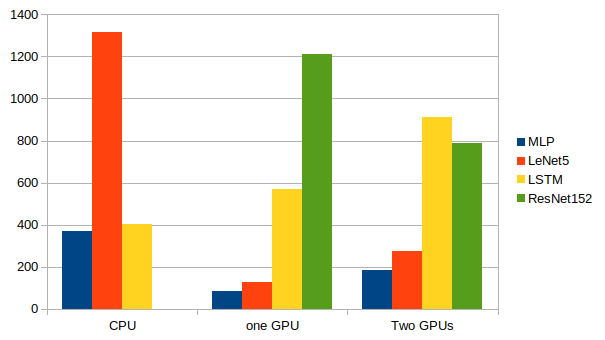
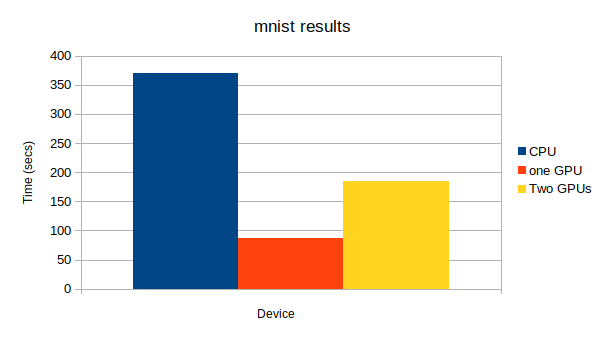
上から、CPU、GPU1つ、GPU2つになっています。
GPU: -1, None
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
20 0.000392997 0.112276 1 0.9802 131.866
GPU: 0, None
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
20 0.000861154 0.0953411 1 0.9835 34.7934
GPU: 0, 1
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
20 0.00679889 0.0958061 1 0.9843 75.3378
cifar-10(LeNet5)
cifar-10について
CIFAR-101)はAlexNetで有名なAlexさんらが構築したもので80 million tiny imagesから
・飛行機、犬など10クラス
・学習用データ5万枚
・評価用データ1万枚
を抽出したデータセットです。
http://starpentagon.net/analytics/cifar-10_dataset/ より

LeNet5について
LeNet(5)とは1990年代に作成された一番初めにConvolutional Neural Netowrkの基礎にあたるものを提案し使用したネットワーク.MNISTにおいて当時から高い精度を出していた.
http://www.thothchildren.com/chapter/59bf6f7ee319b7394d662311 より
ということで、Chainer docsにあるLeNet5を参考にして、次のようにモデルを定義しました。
Mnistに使うって書いてあるのになんで、cifar-10かというと、ただただ気分です。あとでResNetも使って実装しますから、怒らないでください笑
class LeNet5(Chain):
def __init__(self):
super(LeNet5, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(
in_channels=None, out_channels=6, ksize=5, stride=1)
self.conv2 = L.Convolution2D(
in_channels=6, out_channels=16, ksize=5, stride=1)
self.conv3 = L.Convolution2D(
in_channels=16, out_channels=120, ksize=4, stride=1)
self.fc4 = L.Linear(None, 84)
self.fc5 = L.Linear(84, 10)
def forward(self, x):
h = F.sigmoid(self.conv1(x))
h = F.max_pooling_2d(h, 2, 2)
h = F.sigmoid(self.conv2(h))
h = F.max_pooling_2d(h, 2, 2)
h = F.sigmoid(self.conv3(h))
h = F.sigmoid(self.fc4(h))
if chainer.config.train:
return self.fc5(h)
return F.softmax(self.fc5(h))
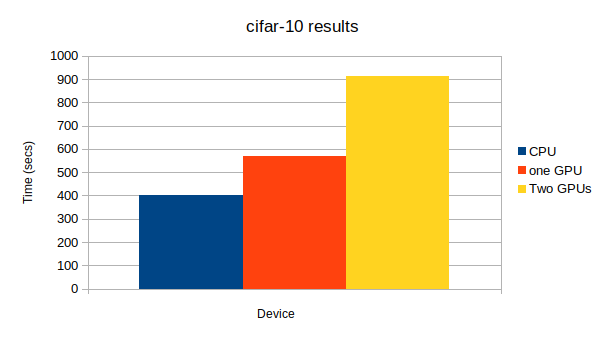
結果
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。
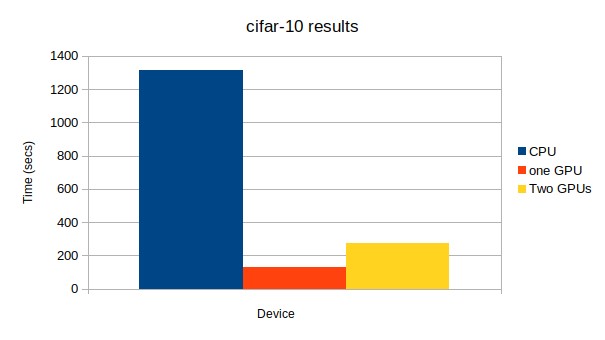
上から、CPU、GPU1つ、GPU2つになっています。
GPU: -1, None
# Minibatch-size: 100
# epoch: 50
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
50 1.00791 1.92314 0.64 0.6087 1313.48
GPU: 0, None
# Minibatch-size: 100
# epoch: 50
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
50 1.26838 1.9345 0.62 0.6039 127.483
GPU: 0, 1
# Minibatch-size: 100
# epoch: 50
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
50 1.02486 1.94677 0.6 0.5919 273.38
Sine Wave(LSTM)
ここのパートは以前書いた記事https://qiita.com/AtomJamesScott/items/41c4a3bd85a851f02770 の実装結果を使っていきたいと思います。
Sine Waveについて
サイン波です。
LSTMについて
LSTMとは時系列のデータを扱うRNN(再起的ニューラルネットワーク)の一種で、普通のRNNだと起こる勾配が爆発・消失する問題がないので、よく使われている。

class LSTM(Chain):
n_input = 1
n_output = 1
n_units = 5
def __init__(self):
super(MLP, self).__init__(
l1 = L.Linear(self.n_input, self.n_units),
l2 = L.LSTM(self.n_units, self.n_units),
l3 = L.Linear(self.n_units, self.n_output),
)
def reset_state(self):
self.l2.reset_state()
def __call__(self, x):
h1 = self.l1(x)
h2 = self.l2(h1)
return self.l3(h2)
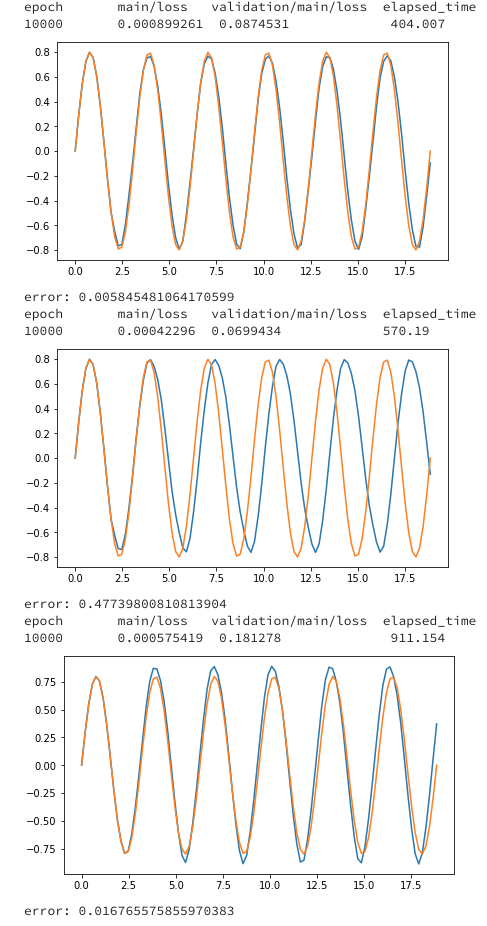
結果
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。特にLSTMの学習はBPTTがある関係でややこしく、ミスってる可能性あります。
上から、CPU、GPU1つ、GPU2つになっています。
補足 cifar-10(Resnet152)
Resnet152について
ResNetは、Microsoft Research(現Facebook AI Research)のKaiming He氏が2015年に考案したニューラルネットワークのモデルである。
CNNにおいて層を深くすることは重要な役割を果たす。層を重ねるごとに、より高度で複雑な特徴を抽出していると考えられているからだ。
Convolution層はフィルタを持ち、Pooling層と組み合わせて何らかの特徴を検出する役割を持っている。低・中・高レベルの特徴を多層形式で自然に統合し、認識レベルを強化することができる。
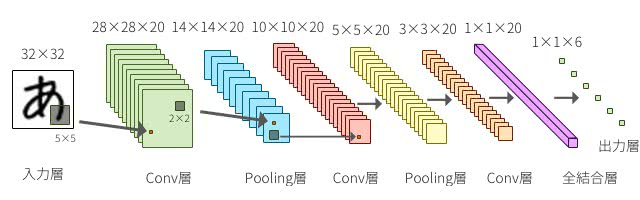
https://deepage.net/deep_learning/2016/11/30/resnet.html より
モデルに関してこちらを参考にしてください。
https://docs.chainer.org/en/stable/examples/cnn.html
結果
GPU: 0, None
# Minibatch-size: 2048
# epoch: 50
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
50 0.0734697 6.44621 0.975586 0.474124 1211.89
GPU: 0, 1
# Minibatch-size: 2048
# epoch: 50
epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time
50 0.0985431 6.45934 0.962891 0.459237 789.439
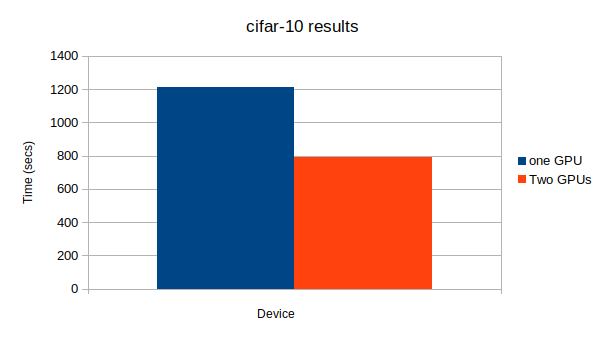
結論
複数のGPUを有効活用するのは難しいことが分かりました。
調べたところ
- Use a very small network. 小さいネットワークを使う
- Use very small batch size. 小さいバッチサイズを使う
- Create overhead for updating parameters across multiple GPUs. パラメータ更新のオーバーヘッドを大きくする
という3つのことをやってしまうと、複数のGPUを有効活用できないそうだ。
この記事でも最後に使ったResNet152が一番大きなネットワークになっており、唯一複数GPUを使ったほうが計算が早く終了した。
(CPUで実験をしなかったのはLeNet5の例から分かるとおり、conv netでCPUを使うとすごく時間かかるからです。)