目的
青空文庫にあるテキストデータから、それっぽい文字列を生成していくモデルをRNNとLSTMとでつくる。
PART1では
- Recurrent Neural Network/Long Short Term Memoryの仕組み
- RNNで起こる勾配の消失・爆発問題とLSTMによる改善
- Beautiful Soupを使ったテキストデータのマイニング
- LSTMを用いた言語モデルの学習
PART2では
単純なRNNを使った言語モデルの学習をしてから
- PART1で作ったLSTMとのアウトプットの違い
- 勾配の消失・爆発問題を体験?する
- 上記問題の改善するための手法 (Gradient Clipping/Identity RNN etc.)
などの理解や実装が軽くできればなと思います。
速習RNNとLSTM
いろんなサイトから引用しますが、その都度出典を明記するので参考にしてください。
Recurrent Neural Network(RNN)
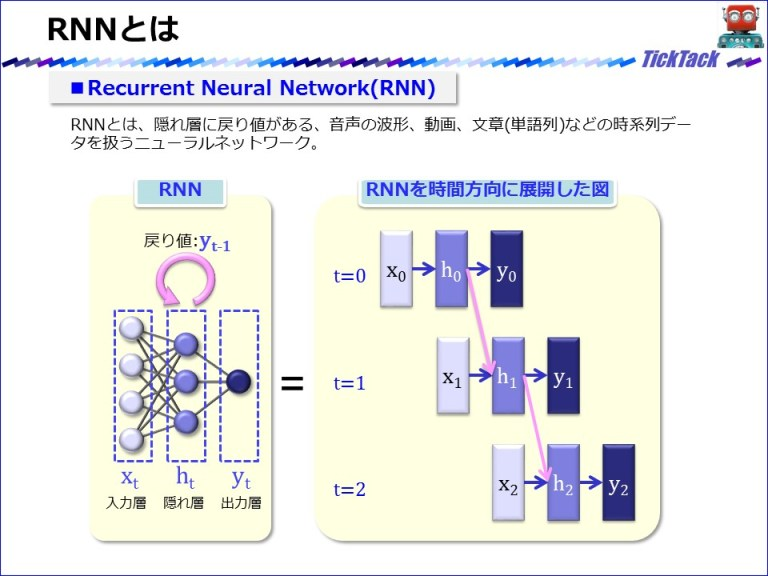
http://gagbot.net/machine-learning/ml4より
RNNに関しては以下の文献がわかりやすい
- http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9
- https://www.deeplearningbook.org/contents/rnn.html
- https://arxiv.org/pdf/1404.7828.pdf
Long Short Term Memory(LSTM)
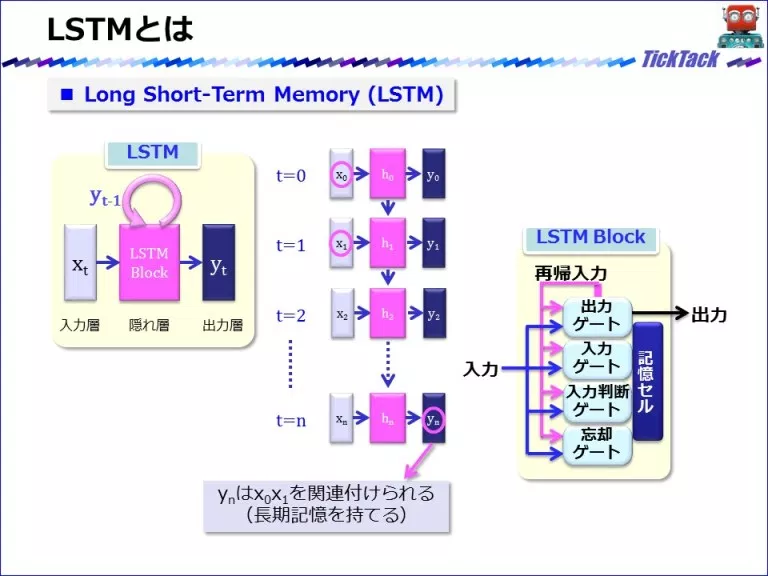
http://gagbot.net/machine-learning/ml4
LSTMに関しては以下の文献がわかりやすい
- https://qiita.com/t_Signull/items/21b82be280b46f467d1b
- https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
勾配の消失・爆発
一言でいうと__RNNで長期依存する情報を学習しようとすると、勾配が消失・爆発する__。
長期依存とは
例えば、
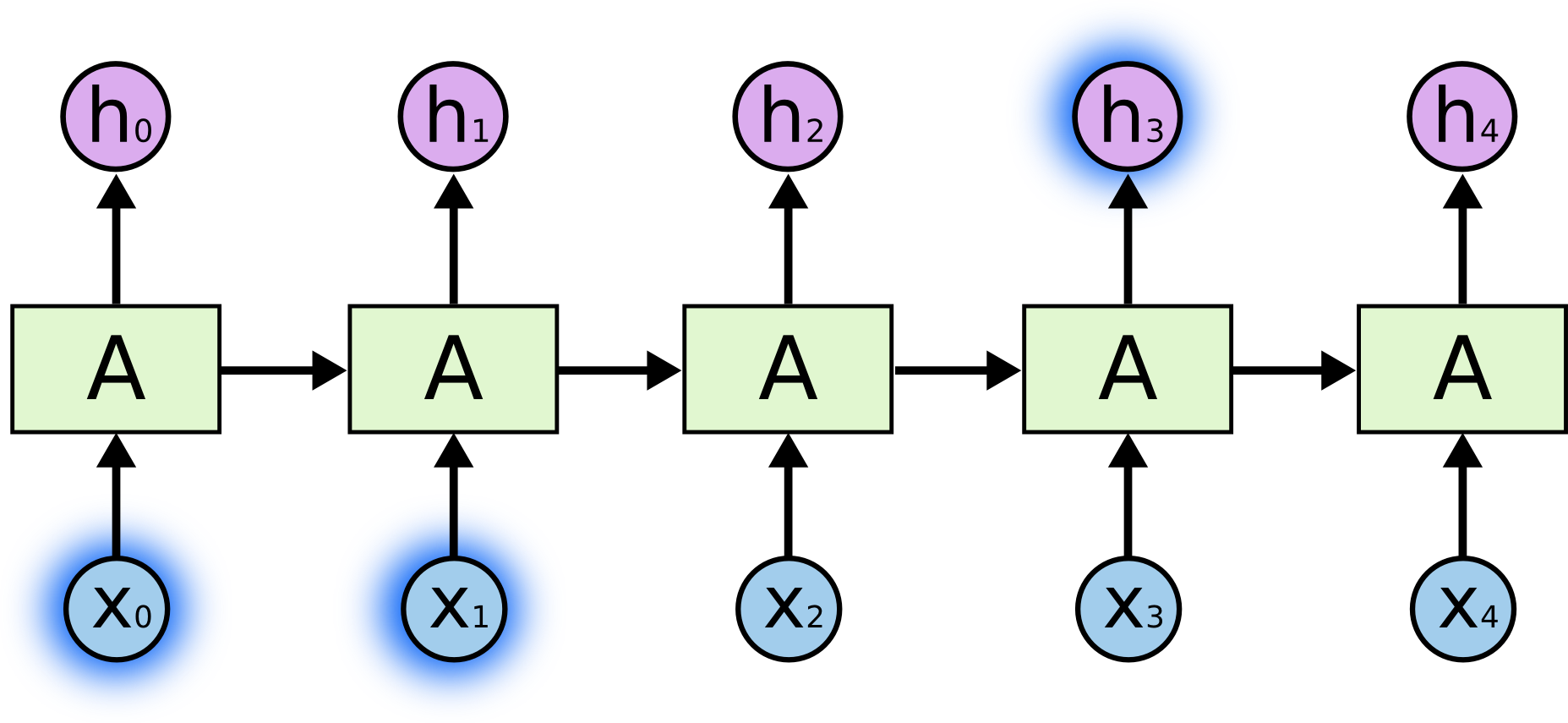
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
「今日は真夏日なので、気温が_高い_」であれば、気温_高い_はずであるということを予測するのには数文字前の真夏日が大きなヒントとなります。
上記の図でいうと、x0あたりが「真夏日」でh3が「高い」というイメージですね。これは短期依存の例です。
反対に長期依存はもっと長い文章、例えば
「私はイギリスで生まれた。そして、9歳のときに日本へ引っ越してきた。引っ越してから15年たった今でも母国語である、英語(は流暢に喋れる)」
なんて文章の「英語」という語句を予想するのには1文目のコンテクストが必要です。
下記の図でいうと、x0あたりがイギリス、ht+1が英語だとすると、ギャップがあるのが分かります。
RNNはこのギャップを学習することを苦手とします。
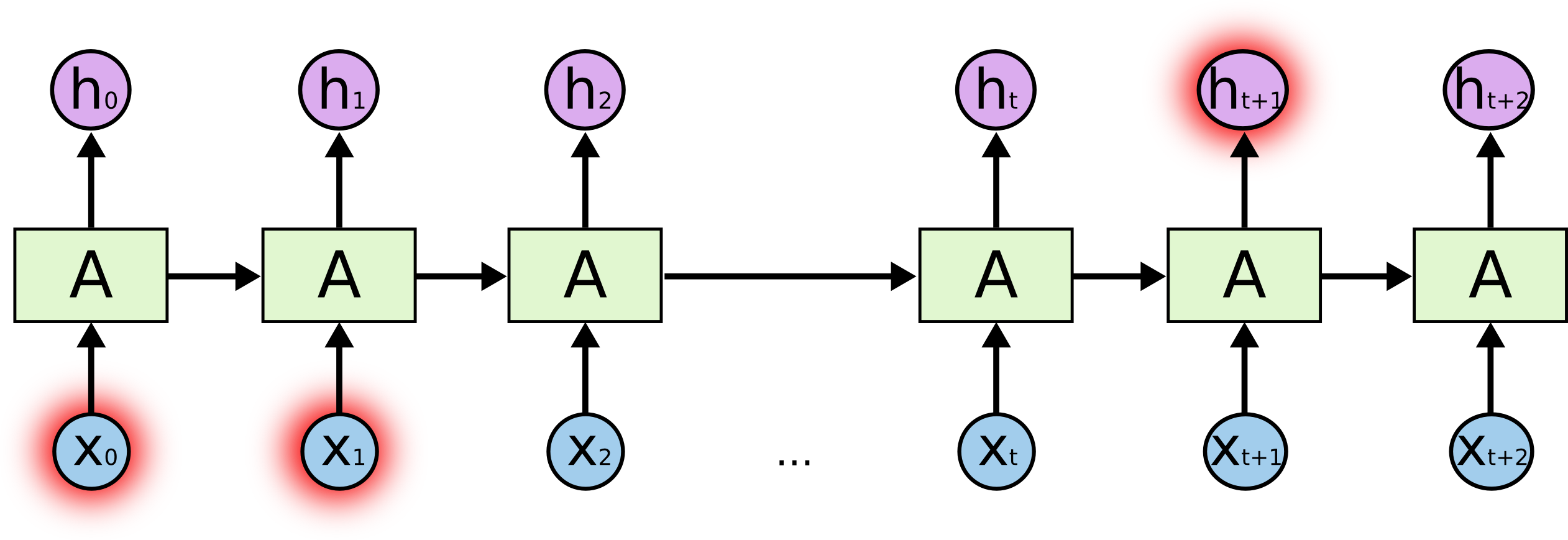
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
長期依存と勾配消失・爆発
問題が発生するのは、勾配がBPTT法(Backpropagation through time)により、何層も何層も伝搬されていくときです。
早期の層に近づくのに連れ、勾配が
- 小さいと(<1)指数関数的に減衰する
- 大きいと(>1)指数関数的に増加する
ので、計算的に無理が生じて学習が難しくなってしまいます。
勾配問題の解決方法
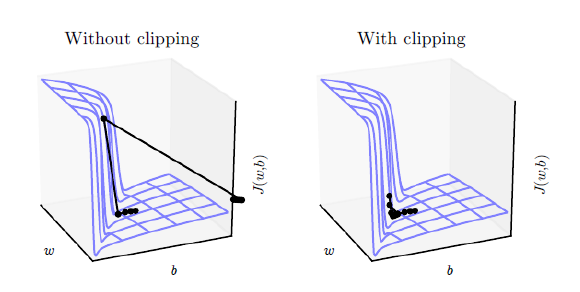
Gradient Clipping
閾値を設定して、勾配が小さくなりすぎる、もしくは大きくなりすぎることを防ぐようにする。

Identity RNN
ネットワークの重みを単位行列に初期化&活性化関数をReLUに設定することで、誤差導関数が0か1の2数になるため、勾配消失・爆発になりにくい。
※自分メモ:原論文を読むと良いかもhttps://arxiv.org/pdf/1504.00941.pdf
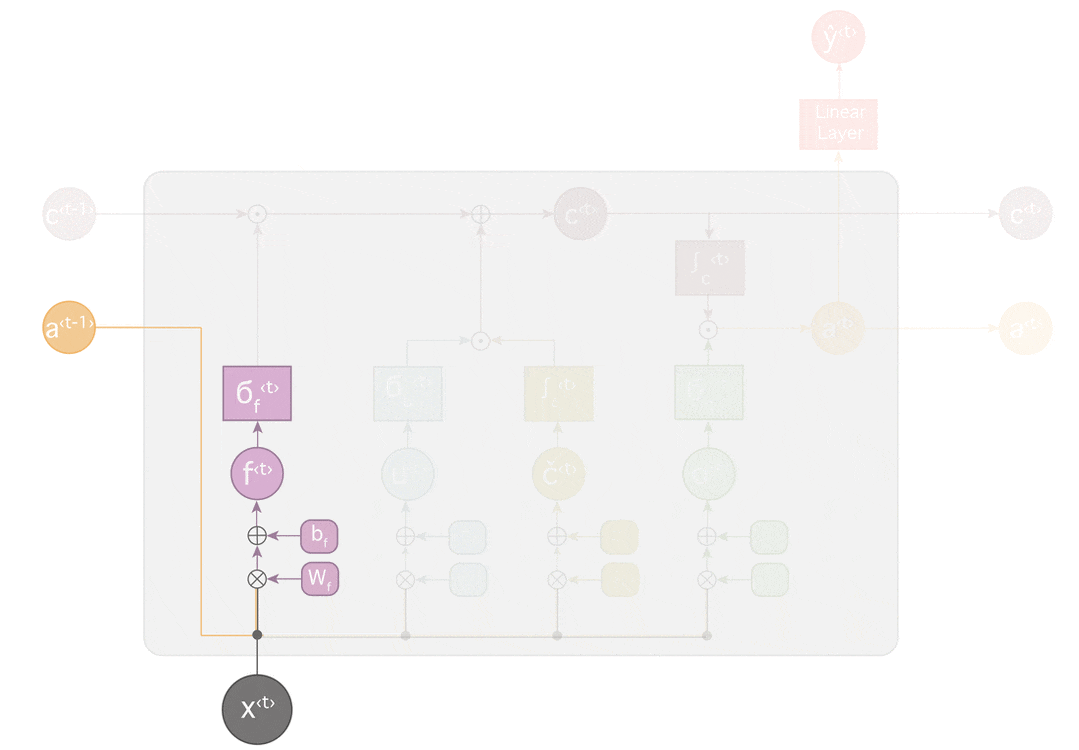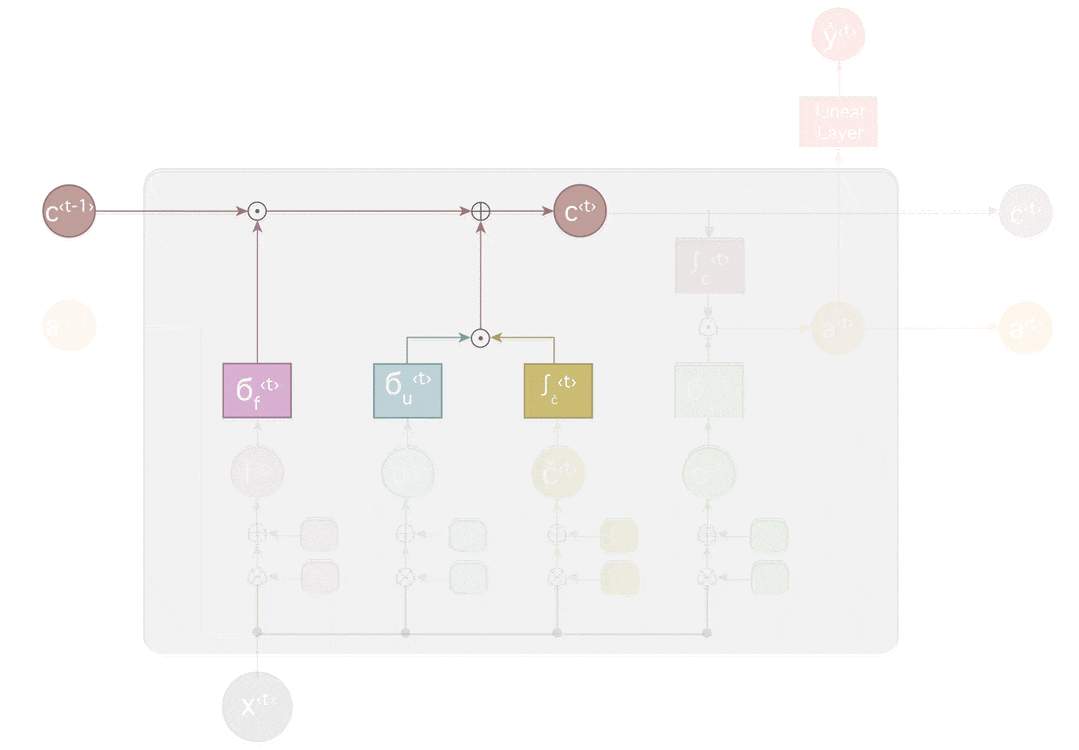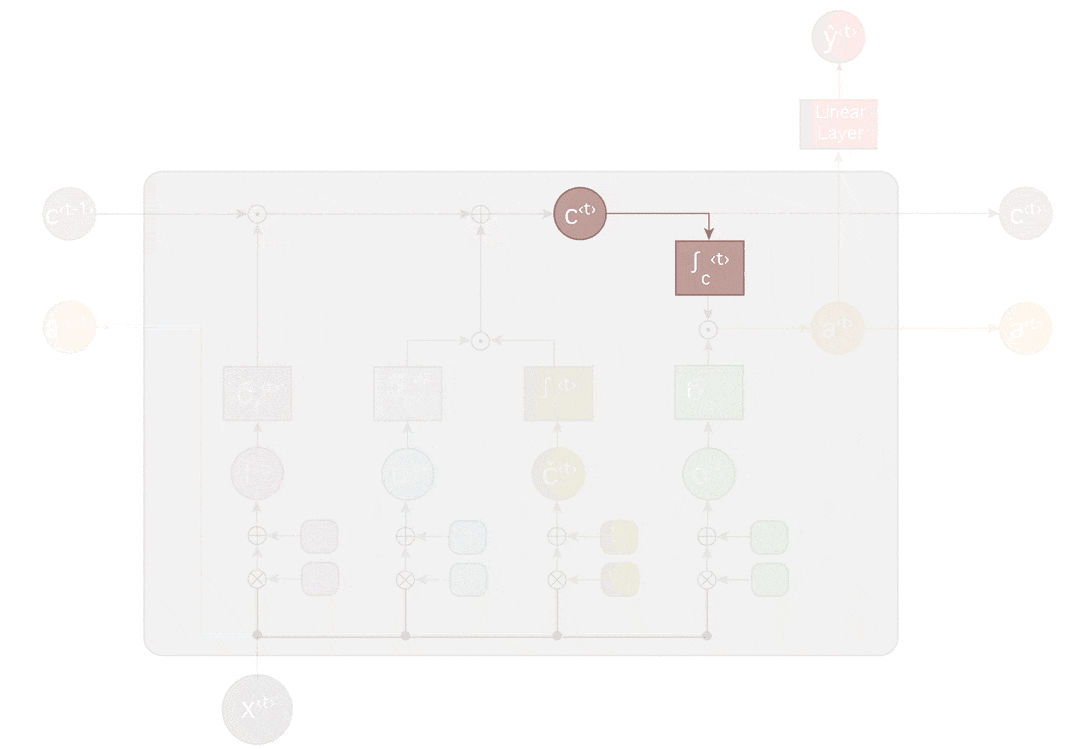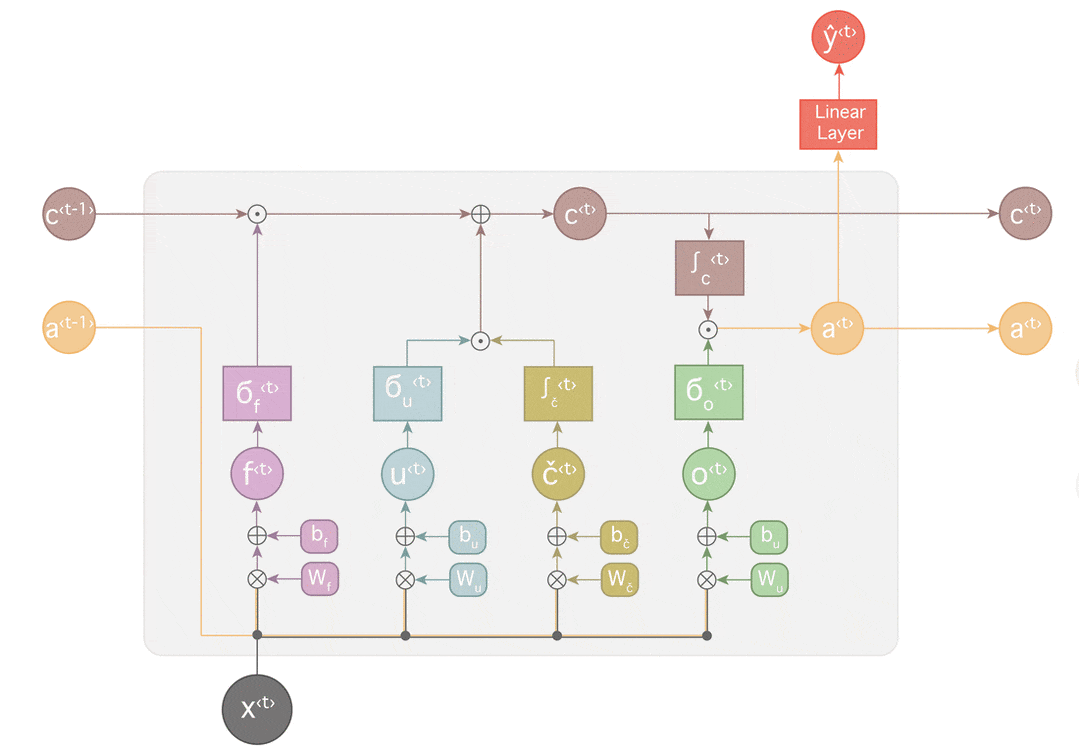
LSTM
LSTMは長期依存を学習できるように、ゲートを導入しています。
LSTMは、セル状態に対し情報を削除したり追加する機能を持っています。この操作はゲートと呼ばれる構造によりしっかり制御されます。
ゲートは選択的に情報を通す方法です。
https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca より
上記では主に、https://medium.com/learn-love-ai/the-curious-case-of-the-vanishing-exploding-gradient-bf58ec6822eb を参考(ほぼ翻訳)にしました。
Overview
以下に全体の流れを示した手書きのイラストを載せました。字が汚いのはごめんなさい!
My handwriting is much better in English but fewer people will read it.. probably.
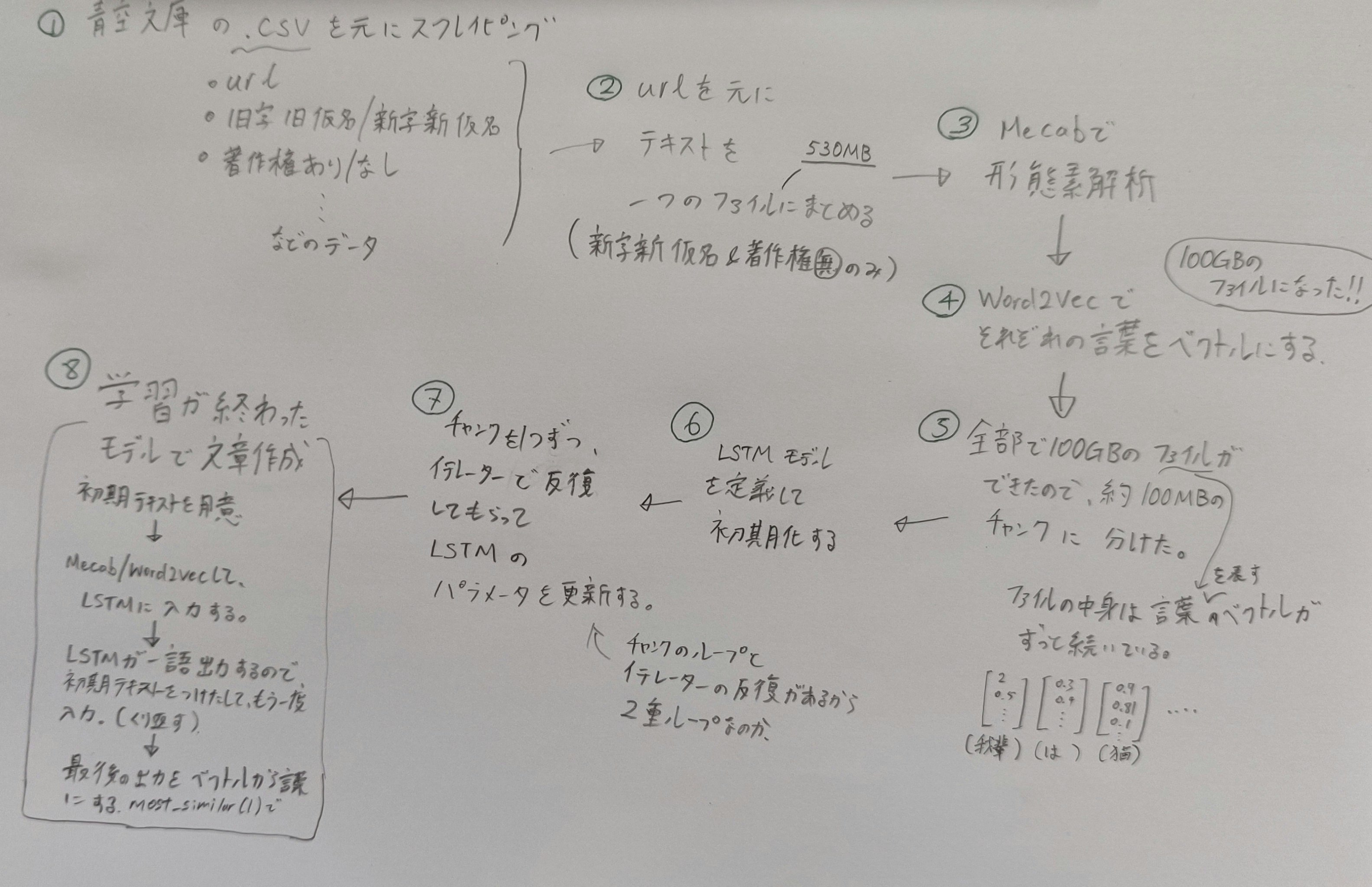
学習データ
青空文庫のHTML文字をスクレイピング
Beautiful Soup を用いて青空文庫にある文章を一つのテキストファイルにまとめます。
まず、一つのhtmlからテキストデータを引っ張ってきます。
以下. 実行例
import requests
from bs4 import BeautifulSoup
def get_text(url):
req = urllib.request.Request(url, headers={'User-Agent': ua})
html = urllib.request.urlopen(req)
soup = BeautifulSoup(html, "html.parser")
# エラー処理をサボる
if soup is not None:
text = soup.find(class_='main_text').get_text()
if soup is None:
text = ""
return text
url = 'https://www.aozora.gr.jp/cards/000148/files/789_14547.html'
text_file = open("words.txt", "w")
text_file.write(get_text(url))
text_file.close()

上記を作品分繰り返すには全作品のテキストへのurlが必要で、めんどくさそうだなと思っていましたが、
https://www.aozora.gr.jp/index_pages/person_all.html よりダウンロードできるcsvに全部まとまっていました(ラッキー)。
著作権が切れたもので
- 旧字旧仮名
- 新字新仮名
とで分けてnew.text, old.textを作ります。
データ量を考えずにスクレイピングを始めましたが、文字情報だけにしてはけっこう多かったです笑
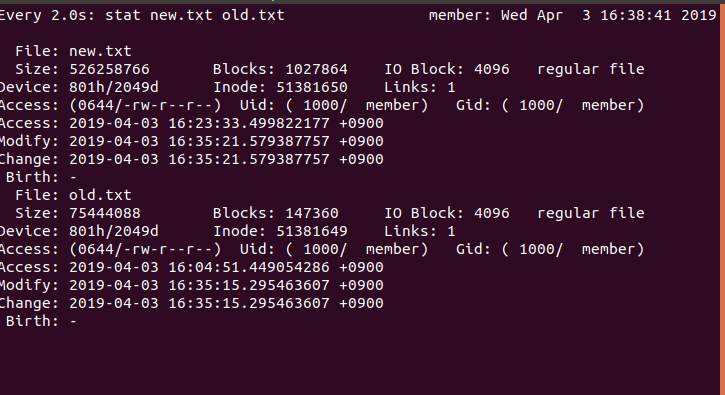
1文字が大体1〜3バイトなので2バイトで計算すると
- new.text - 526.3MB ≒ 2億6000万文字
- old.text - 75.4MB ≒ 3770万文字
これは学習が大変そうだ。
データセット作成
Alex Gravesの論文Generating Sequences With Recurrent Neural Networksを真似して、上記データを形態素解析したものを一つの長いリストに入れて、テストとトレーン分けたデータセットを用意します。モデルにデータを入力するときにWord2Vecします。
MeCab
形態素解析にはnatto-pyのMeCabを用います。これを使えば、簡単に単語毎に文章をわけられます。
from natto import MeCab
words = open("words.txt", "r")
data = []
with MeCab() as nm:
for line in words.readlines():
for word in nm.parse(line, as_nodes=True):
if not word.is_eos():
try:
#データセットからエラーを起こしそうな文字を省く
_ = model[word.surface]
data.append(word.surface)
except:
continue
words.close()
for word in data[:15]:
print(word)

Word2Vec
自然言語処理に関しては、ほとんど知識がないのでこちらのブログを参考にして学習済みのWord2vecモデルを使いたいと思います。
出力結果から分かるとおり、Word2Vecを使うのは全然時間かかりません。
from gensim.models import KeyedVectors
model_dir = './entity_vector/entity_vector.model.bin'
model = KeyedVectors.load_word2vec_format(model_dir, binary=True)
print(sentencelist[1][3], model[sentencelist[1][3]])
%timeit model[sentencelist[1][3]]

学習の流れ
https://docs.chainer.org/en/stable/guides/trainer.html より
ニューラルネットワークを学習させたいときは、パラメータを何度も更新するトレーニングループを実行する必要があります。
典型的なトレーニングループは以下の手順で構成されています。
- 訓練データセットの反復
- 抽出ミニバッチの前処理
- ニューラルネットワークのforward/backward計算
- パラメータの更新
- 検証データセットで現パラメータの評価
- ログ記録と表示
https://qiita.com/AtomJamesScott/items/41c4a3bd85a851f02770
↑でGPUを使ってLSTMを動かしたコードを載せました。このコードを参考にして学習させます。
LSTM
詳しいコードはここでは省略しますが、Mecab→Word2Vecしたデータを役100MBのチャンクに分けて、それぞれのチャンクで40Epoch分の順に学習させていきます。
- GPU1つ
- batchsize = 250
- 初期テキストは500語(もっと短くしたほうが良かったかもしれない)
- epoch数=40
ハイパーパラメータの調整に関しては完全にノータッチなので、もし時間があればPart3かなにかでOptunaなどを使ったチューニングがしたいです。
net = run_LSTM(gpu0=1,batchsize=250,seqlen=500, epoch=40)
学習には3日かかりました笑
たぶん、うまく行ったのですがロスのプロットだけミスっており、それぞれのチャンク毎に新しい画像を作ってしまいました。
結果的に1072個のプロットを作成しました。

結果
うまく学習できてませんでした
最初にこの短編小説の文章をLSTMに入れてから、「The show must go on――たとえ外で何が起こったとしても、芝居の幕は決して下ろしてはならないのだ」の続きを書いてもらおうと思ってましたが、まさかの惨敗です。
結果は以下の通り、「自分」「人間」ぐらいしか覚えてないようですね笑
の自分の人間が、自分の人間の人間が自分の人間のことを信じていることが、自分の人間のように自分自身の人間が自分の人間が自分の人間を戒めているが、自分の人間が自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間のように、自分の人間の人間を自分の人間に戒めている。自分の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の身体が、自分の身体が、自分の身体を常に人間の人間が自分の人間のことを信じていることが、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間のことが、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間のことが、自分の人間の人間が、自分の人間の人間の人間が、自分の人間の人間が、自分の人間の人間がの人間のことである。自分の人間の人間が、自分の人間の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間を自分の人間に戒めていることを信じている。「私は自分の人間だと思うが、自分の人間が自分の人間のことを信じていることができるが、そのことが自分の人間の人間になっているが、その人間が自分の人間の人間が、自分の人間のように、自分の人間の人間が、自分の人間の人間を自分の人間に戒めていることがのが、自分の人間だと思う。自分の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の人間の人間が、自分の身体が、自分の身体が、自分の身体が、自分の身体が、自分の身体を常に、人間の人間がのが、その人間の人間の人間の人間の人間の人間の人間の人間が、自分の身体を常に人間の人間'
もう一度勉強し直して、次回ハイパーパラメータ調整やデータセットの工夫などをして、再挑戦します!