このチュートリアルの内容
このチュートリアルでは、Pepperによる音声認識・音声出力について、その仕様やどのようなことができるのかを、サンプルを通じて説明します。
- 音声関係の仕様
- ボックスの使い方:音声認識と音声出力
- それぞれをボックスで実現
- QiChat scriptの活用
- ボックスの使い方:好きな音を鳴らす
- ボックスの使い方:音のした方向の追跡
各種センサー・出力仕様
Pepperの音にかかわる仕様としては、以下のようなものがあります。
- 出力
-
頭部スピーカー×2 (右**[A], 左[B]**)

-
タブレットスピーカー ... ステレオ
-
- 入力
-
頭部マイク ... 頭頂部、前後それぞれ左右の4つ (左後部**[A], 右後部[B], 左前部[C], 右前部[D]**)

-
ボックスの使い方:音声認識と音声出力
ボックスを使った音声認識 + 音声出力
音声認識、音声出力それぞれの機能を担うボックスが提供されています。
ここでは、 言うことを聞き取り、「いちご」ならば「あかい」と言い、「ばなな」ならば「きいろい」と言う ことをやってみます。なお、このアプリケーションは、 「おしまい」と言われたら「ばいばい」と言って停止する ことにします。
つくってみる
-
利用するボックスの準備
- Audio > Voice > Set Language ... 言語設定を変更する
- Audio > Voice > Speech Reco. ... 音声認識をおこない、パラメータで与えられた単語候補のいずれかを判別する
- Flow Control > Switch Case ... 入力された値に対して、条件に応じて異なる出力をおこなう
- Audio > Voice > Say ... こんにちはと言う (3回ドラッグ&ドロップ)
-
ボックスをつなぐ
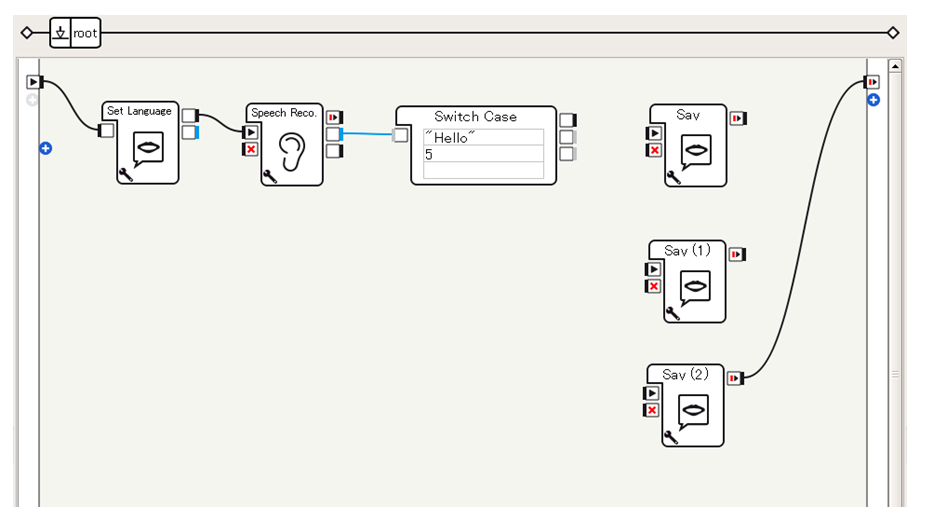
- Set Languageボックスで言語設定をしたのち、Speech Reco.ボックスへと接続します
- Speech Reco.ボックスは音声認識処理を実装するボックスで、話しかけられると候補の単語から最も候補としてふさわしいものを選択し、文字列として出力します
- この出力を、条件分岐機能を提供するSwitch Caseボックスで分岐させ、「あかい」と言うSayボックス、「きいろい」と言うSayボックス、「ばいばい」と言うSayボックスへと接続することで、話者への応答を実現します。これらのボックスの設定、接続はこの先の手順でおこないます
- 3つめのSayボックス(「ばいばい」と言うSayボックスに変更する予定)が停止したらアプリケーションが停止するように、SayボックスのonStopped出力をビヘイビアのonStopped出力に接続します
-
パラメータを設定する
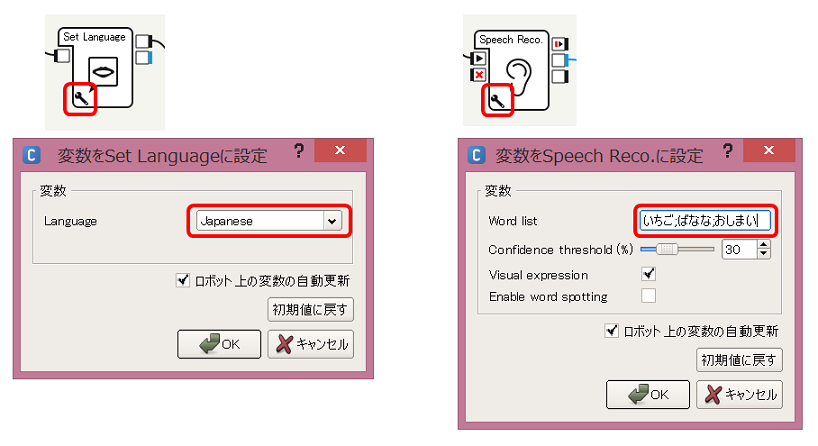
- Set Languageボックスにはいつも通りJapaneseを、Speech Reco.ボックスには いちご;ばなな;おしまい (セミコロンで区切る)を設定します。これにより、Speech Reco.ボックスは、話しかけられた内容に対して「いちご」か「ばなな」か「おしまい」かのいずれかを判断するように設定されます
-
条件を設定する
Switch Caseに "いちご", "ばなな", "おしまい" (ダブルクォーテーションで囲む)を設定します。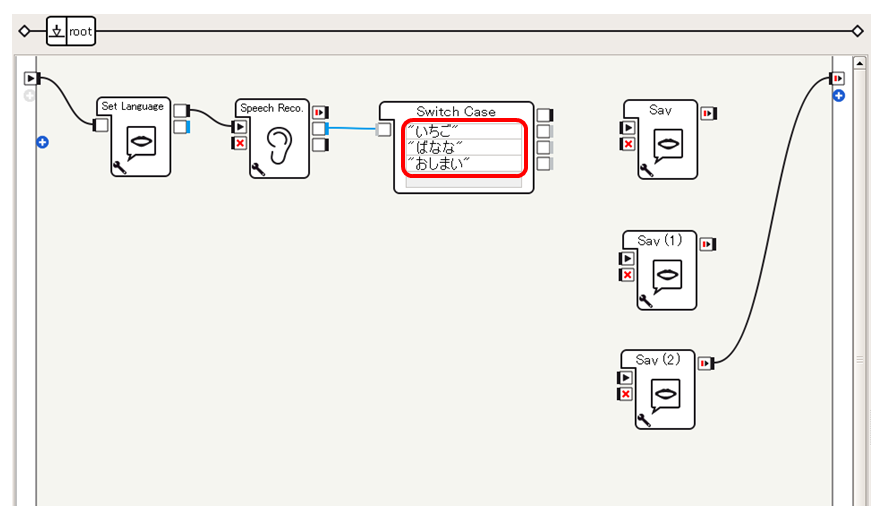
すると、Switch Caseボックスのグレー(Dynamic)出力が2つから3つに増えます。Speech Reco.から渡された文字列が「いちご」であれば output_1 出力に、「ばなな」であれば output_2 出力に、「おしまい」であれば output_3 出力にシグナルを送るようにSwitch Caseボックスが設定された状態になります。
-
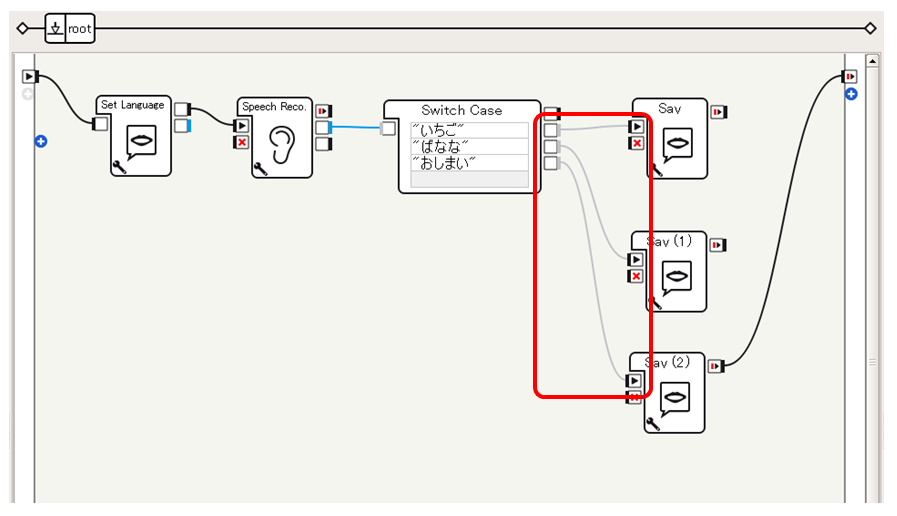
Switch Caseボックスの3つの出力をそれぞれ以下のように3つのSayボックスへと接続します
-
Sayの内容を変更する
- Switch Caseの output_1 につないだSayは、Localized TextにJapaneseを設定したうえで あかい とし、output_2 に接続されたSayは きいろい とし、output_3 に接続されたSayは ばいばい とします
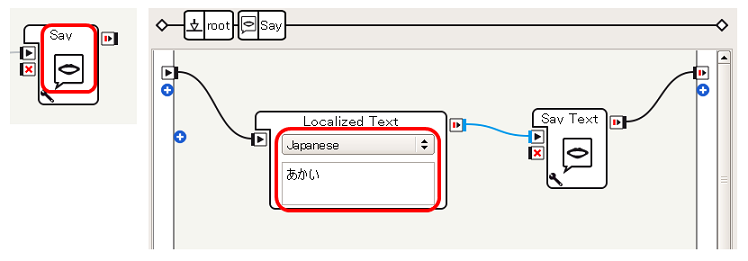
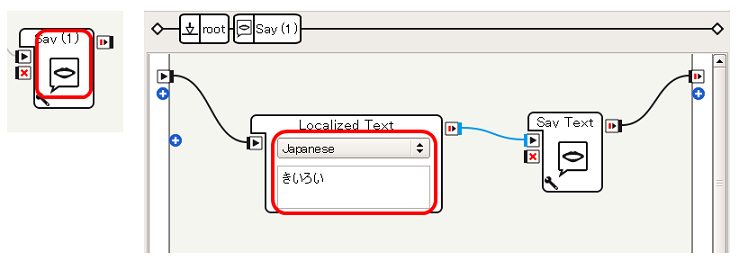
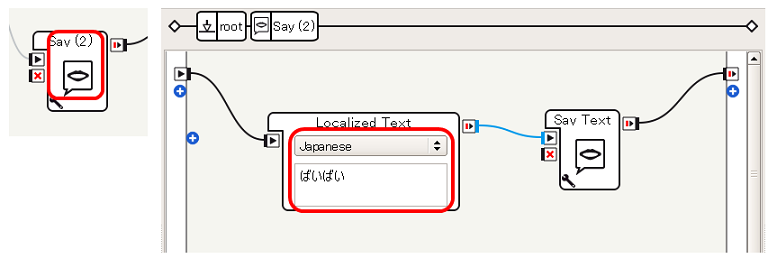
これで、単純な 音声の認識→条件分岐→音声による応答 を実現することができます。
動作確認
Pepperの場合は、接続、再生後、実際に話しかけることで動作確認をすることができます。
また、バーチャルロボットではダイアログパネルによって文字列ベースで対話することができます。
バーチャルロボットで再生を実行したのち、ダイアログパネルに単語を入力する [1] と、フローダイアグラムにしたがった応答が確認できます。 [2]

QiChat scriptの活用
先の例では、音声認識と音声出力をそれぞれ別々のボックスで実現していますが、標準ボックスにはDialogというものがあり、 QiChat Script という対話の定義言語 (参考:SDKドキュメント NAOqi Developer guide > NAOqi Framework > NAOqi API > NAOqi Audio > ALDialog > QiChat) によってPepperとの対話を実現することができます。
つくってみる
-
利用するボックスの準備
- Audio > Voice > Set Language ... 言語設定を変更する

この段階ではとりあえずボックスを置くだけにしてください。 -
ダイアログのトピックを作成する
- 対話の定義のためのファイルを作成します。まず、プロジェクトの内容パネルで 追加(+) をクリックし [ダイアログのトピックを作成中...] をクリックします
- ダイアログの名前として適当な名前を入力 [A] し、英語(enu)のチェックを解除 [B]、日本語(jpj)のチェック **[C]**を設定します

すると、プロジェクトファイルにダイアログの定義ファイルが作成されます。

-
作成されたファイルのうち、日本語に対応するトピック(*_jpj.top)をダブルクリックすると、スクリプトエディタパネルが開きます

このエディタに、以下のようなスクリプトを記述します。
topic: ~aisatsu() language: jpj u:(こんにちは) やあ u:(げんき) まあまあかなこれは、以下のような会話を定義しています。
* ユーザから「こんにちは」と話しかけられたら「やあ」と応答する
* ユーザから「げんき」と問いかけられたら「まあまあかな」と応答する -
プロジェクトファイルのダイアログ(*.dlg)をフローダイアグラムにドラッグ&ドロップすると、ボックスの形にすることができます

-
ビヘイビアのonStartと、先に作成したSet Languageボックス、作成したaisatsuダイアログボックスをそれぞれつなぎます

-
Set Languageのパラメータを(いつもと同様)Japaneseに設定します

これでダイアログの定義は完了です。今回は単純な単語と単語での受け答えを定義しましたが、QiChat Script では対話に関するさまざまな定義をおこなうことができます。
動作確認
先の例と同様、再生してロボットに話しかけてみたり、ダイアログパネルを介してロボットと対話してみてください。

ボックスの使い方:好きな音を鳴らす
お遊び的に、 人が頭をさわると「ワン」と犬の鳴き声を再生する ようなアプリケーションを作成してみます。
対応している音声ファイルは、.wav形式のほか、バーチャルロボットは.ogg形式、Pepperは.mp3形式に対応しています。
作業の前に適当な音声ファイルを準備しておいてください。
つくってみる
-
利用するボックスの準備
- Sensing > Tactile Head ... 頭がさわられたことの検出
- Audio > Sound > Play Sound ... 音声ファイルの再生
-
ボックスをつなぐ

- Tactile Headボックスの上から2番目の出力(frontTouched)をPlay Soundボックスにつなぎます。今回は頭の前のほうに反応するかたちになります。
####
 [参考]Pepperの頭部タッチセンサー
[参考]Pepperの頭部タッチセンサー
Pepperの頭部タッチセンサーは、前部 [A]、中央 [B]、後部 **[C]**の3種類があります。

これに対応して、Tactile Headボックスの出力も3つあります。

これらの出力を使って、頭のタッチ位置による挙動を変えることができます。 -
音声ファイルをプロジェクトにインポートする
音声ファイルや映像ファイルのような、ボックスが参照するためのファイルは、プロジェクト内にインポートしておく必要があります。
[プロジェクトの内容]パネルの 追加(+) ボタンを押し、[ファイルのインポート...]を選択します。ファイル選択ダイアログが開くので、そこで音声ファイルを選択すると、プロジェクトに音声ファイルがインポートされます。

-
Play Soundボックスに音声ファイルを設定する
Play Soundボックスのパラメータダイアログを開き、File name変数のファイル参照アイコン をクリックします。

さきほどインポートしたファイルを選択し、[OK]ボタンを押します。

すると、File name変数の値に音声ファイルへのパスが設定されます。

これでフローの作成は完了です。頭の前面がタッチされると、Play SoundボックスのonStartに対してシグナルが送られ、音声ファイルが再生されるようなフローが実現できます。
動作確認
Pepperに接続、再生したのち、Pepperの頭をさわってみてください。「ワン」と音声が再生されるはずです。
たとえばモーションとあわせて音楽を鳴らすなど、いろいろ使いどころがあると思います。
ボックスの使い方:音のした方向の追跡
標準ボックスにはTrackersというカテゴリがあり、Pepperが何かに追従するような動きを簡単に作成することができます。
ここでは例として、Pepperの4つのマイクを活用し、音のした方向を振り向くような振る舞いを作成してみます。
つくってみる
-
利用するボックスの準備
- Trackers > Sound Tracker ... まわりの音に追従する
-
フローの接続

今回はこのボックスだけです -
パラメータの設定

Sound Trackerのパラメータはデフォルトのままです。念のため、Mode変数がHeadになっていることを確認してください。
これでフローの作成は完了です。あとはSound Trackerが適切な処理をおこなってくれます。
動作確認
Pepperに接続し、このフローを再生してみてください。Pepperの近くで手をたたくと、音のした方向をPepperが向くはずです。

(再生時間: 15秒)
ここでは、Sound TrackerのパラメータのうちMode変数をHeadとしたため首を動かすだけですが、WholeBody(全身)、Move(移動をともなう)を選んだり、敏感さなどもパラメータで定義することで、振る舞いをカスタマイズすることができます。
また、targetLost, targetReached出力に別のボックスをつなぐことで、振る舞いをさらにカスタマイズすることもできます。
Pepperと人間のインタフェースにおいて、音声は最もよく使うものになると思います。特にQiChat Scriptは強力な対話の定義言語で、ここで説明したもの以外にもさまざまな機能を提供してくれます。リファレンスなどを活用しつつ、ぜひ色々試してみてください。