ChatGPTやAzure OpenAI Service等のLLMのプロンプトで扱えるデータは一般的には文字列のみで、通常はExcelで作成したようなテーブルデータをそのまま読み取ることはできません。
しかし、テーブルデータをMarkdownやHTML形式の文字に変換することによりLLMが内容を理解することができます。
今回は、上記2つの形式を扱ったテーブルデータの読み取りについてご紹介します。
※本記事で利用したモデルはAzure OpenAI Serviceのgpt-35-turboとなります
Markdown形式
まずはMarkdownを活用したテーブルデータの読み取りについてご紹介します。
Markdownとは簡単な記号でリスト・リンク・テーブル等を表現する記法で、QiitaなどのブログやVisual Studio Codeなどのエディタ等でサポートされています。
Markdown形式の場合、後述のHTMLと比べて文字数が少ないためトークン数が節約できます。
試しに、以下のテーブルを読み取らせてみます。
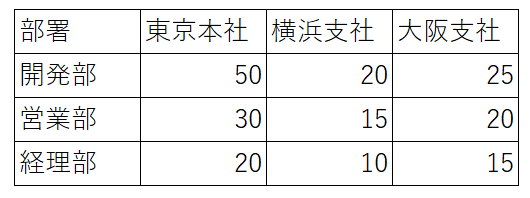
テーブルデータ
-
テーブルイメージ
-
Markdown
| 部署 | 東京本社 | 横浜支社 | 大阪支社 | | - | - | - | - | | 開発部 | 50 | 20 | 25 | | 営業部 | 30 | 15 | 20 | | 経理部 | 20 | 10 | 15 |
回答結果
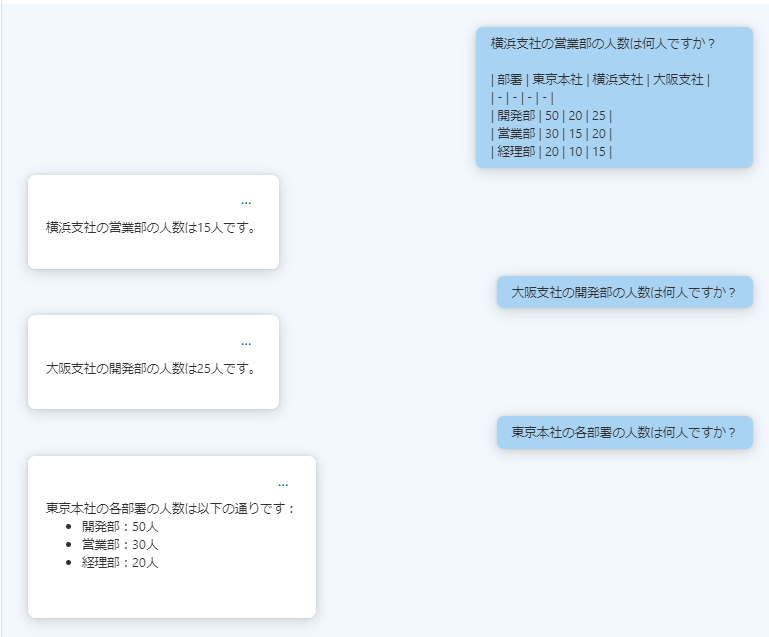
どちらの質問も適切に回答できているため、Markdown形式で記述した文字をテーブルとして理解できていますね。
HTML形式
次に、HTMLのTableタグを活用したテーブルデータの読み取りについてご紹介します。
HTMLを読み取る強みとしては、複数セルを統合しているようなデータ(colspanやrowspan)に関しても読み取ることもできます。
試しに、以下のテーブルを読み取らせてみます。
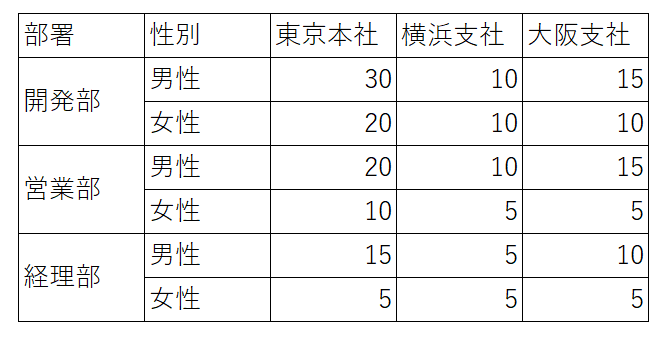
テーブルデータ
-
テーブルイメージ
-
HTML
<table border="1"> <tr> <th>部署</th> <th>性別</th> <th>東京本社</th> <th>横浜支社</th> <th>大阪支社</th> </tr> <tr> <td rowspan="2">開発部</td> <td>男性</td> <td>30</td> <td>10</td> <td>15</td> </tr> <tr> <td>女性</td> <td>20</td> <td>10</td> <td>10</td> </tr> <tr> <td rowspan="2">営業部</td> <td>男性</td> <td>20</td> <td>10</td> <td>15</td> </tr> <tr> <td>女性</td> <td>10</td> <td>5</td> <td>5</td> </tr> <tr> <td rowspan="2">経理部</td> <td>男性</td> <td>15</td> <td>5</td> <td>10</td> </tr> <tr> <td>女性</td> <td>5</td> <td>5</td> <td>5</td> </tr> </table>
回答結果

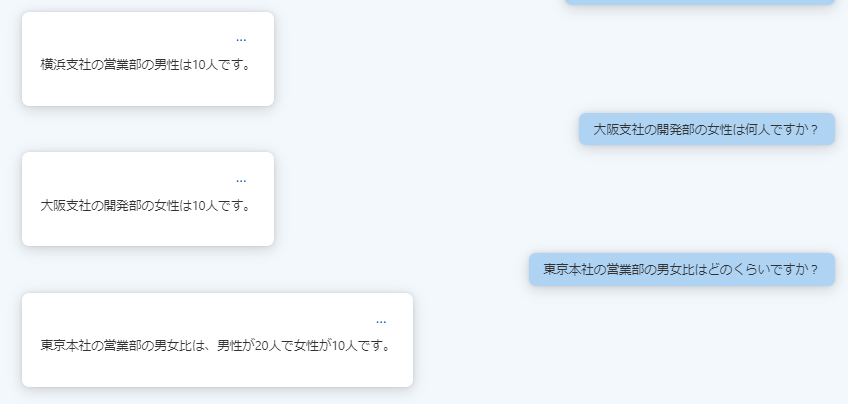
Markdown形式での結果同様に、HTMLで記載された文字をのテーブルとして理解できています。
さらに、複数セルを統合した情報(今回の例では部署情報)も読み取れています。
まとめ
LLMでは、MarkdownやHTML形式に変換することでテーブルデータを読み取ることができます。
今回扱ったテーブルデータ程度であればどちらでも精度は大きく変わりませんが、トークン数を節約したいのであればMarkdown、複数セルを統合したテーブルを扱いたい場合はHTMLが適していると思います。