この記事では MLOps における Data Validation (データバリデーション: データの検証) について概要を述べます。
Data Validation はこれ単体では新しい概念ではありません。たとえば入力フォームで入力値に制約を設け、その制約を満たすデータのみを入力値として受け入れるようにするのは、サービス開発では一般的なことでしょう。入力欄において空欄を許さない、値は特定のリストからのみ選択できるといった制約を設けている例は、開発者でなくても一般的に目にしたことがあるかと思います。
このように Data Validation は一般的な概念ですが、MLOps においては非常に重要な概念となります。また、そこで述べられる問題について対応が必ずしも容易ではありません。これは一体なぜなのでしょうか。この記事では MLOps における Data Validation の重要性と、問題となる事象について述べていきます。
TL;DR
- Data Validation という既存の概念を機械学習システムにも適用できる
- 一方、適用しようとすると新たな問題が発生するので、それらの問題についても検討が必要
- また、Validation を通らなかった際に、どのような対応を行うのかあらかじめ検討することが必要
MLOps における Data Validation の必要性
まず最初に機械学習システムを運用する上での Validation の必要性について確認しましょう。Validation を行うのは、機械学習を行うシステムの振る舞いはコードではなくデータにも依存するからです。またそれには機械学習特有の事情も深く関わっています。以降ではそれらを確認していきましょう。
機械学習のおさらい
そのまえにまずは用語の確認をかねて、機械学習についてかんたんに振り返りましょう。この記事ではさまざまな役割のデータが出現します。このため、それぞれのデータの役割について改めて確認しておきましょう。
機械学習にはさまざまなタイプの問題設定がありますが、今回は教師あり学習を対象とします。教師あり学習では、データを訓練と推論の2つの用途で用います。訓練には訓練データを、推論には推論用のデータを使います。それぞれについて詳しく見ていきます。
訓練データは、あるデータの特徴を表す特徴量 (Xで表される) と、そのデータについての正解となる値である目的変数 (yで表される) の対からなるデータセットです。たとえば、画像分類タスクにおいては特徴量は画像そのものと、その分類結果 (「犬」や「猫」など) の対からなるデータセットです。この訓練用データをアルゴリズムに読み込ませ、データの傾向を学習したモデル (訓練済みモデル) を作成します。
推論データは訓練済みモデルが目的変数の値を推測する、未知のデータを指します。これは典型的には本番環境で与えられるデータになります。画像分類においては、まだ分類がなされていない画像、たとえば読者の撮影した画像を指します。他にも、画像分類を行う Web サービスを作成した場合、推論データはユーザーの入力する画像になります。
訓練と推論の関係についての平易な入門用の動画にはたとえば次のものがあります。
評価データは訓練データと同様、特徴量と目的変数の対からなるデータセットで、学習済みモデルの性能評価に用います。性能評価では訓練データの特徴量を学習済みモデルに入力し、実際の目的変数の値とモデルが推測した値が一致している度合いを、さまざまな指標で評価します。性能評価は一般に、学習済みモデルを本番環境にデプロイする前のテストとして行われます。また、評価データと訓練データは同一のデータセットを分割して作られることが一般的です。
以降では、訓練データ、推論データ、評価データを単に「データ」とだけ書く場合があります。
ここまでに見てきた、タスクは典型的には次の順で行われるでしょう。
- 訓練
- 評価
- 学習済みモデルの本番環境へのデプロイ
- 本番環境での推論
この一連の流れを手動で何度も実行のは現実的ではないため、自動化しておくのが望ましいです。機械学習パイプラインは自動化のために機械学習モデルを本番環境で推論できるまでのタスクを一連のワークフローとして実行できるようにしたものを言います。
また、機械学習パイプラインをたとえば日次のバッチ処理として実装するといったように、継続的に学習プロセスを動かし続けている状態を継続的学習 (Continuous Training) と呼びます。
この記事では継続的学習において Data Validation が重要になることを後ほど取り上げます。
機械学習はとにかく複雑
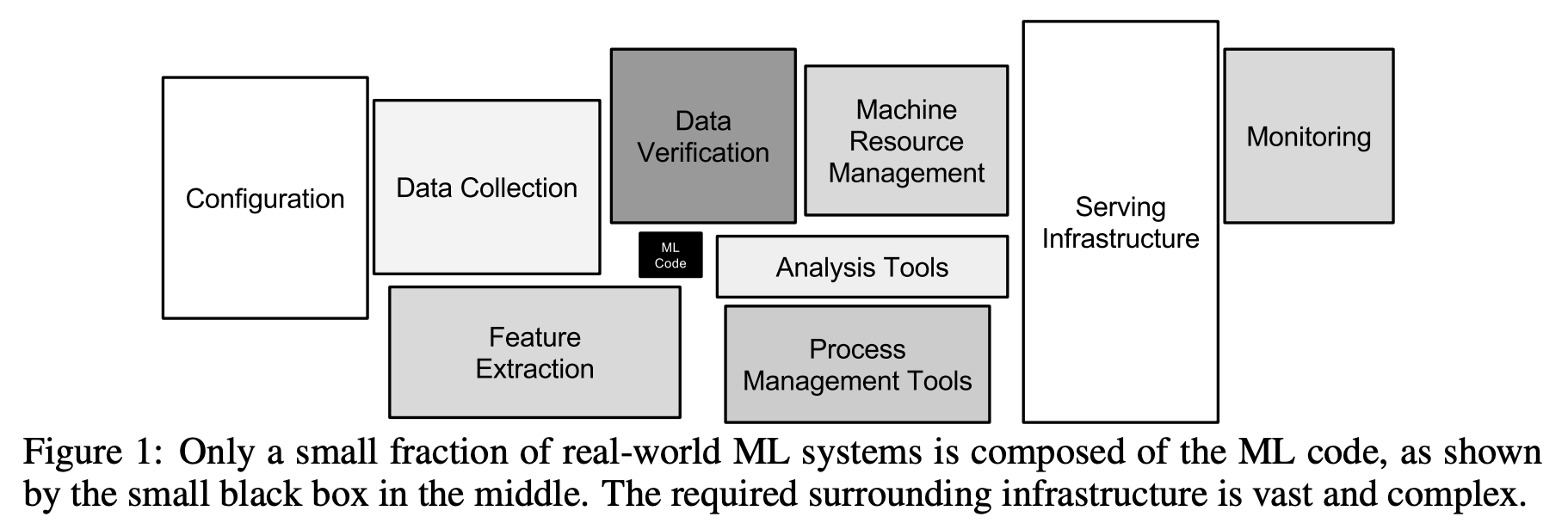
上の図は Hidden Technical Debt in Machine Learning Systems から引用したものです。機械学習に携わる方なら一度は目にしたことがあるかと思います、私も何度も引用しています。
機械学習を用いる際、モデルの定義を行っているコードは比較的短くなります。特に、既存のモデルを用いる転移学習を行うケースでは、モデル自体の定義は行わず、ライブラリのように用いることになるため更にコードが短くなります。
一方、上記の図からわかるように、機械学習を用いる機械学習システムではデータのためにさまざまなコンポーネントが追加で必要になります。データを収集し、前処理を行い、モデルを用いて推論を行うといった一連の処理を行うためのコンポーネントが必要になるとともに、モデルの推論結果の監視や入力データの監視を行うコンポーネントも必要になります。その理由は、システムの振る舞いがコードとデータに依存するためです。
通常のシステムとは異なり、機械学習システムの振る舞いはコードを書き終えた段階では定まりません。また、データが手に入るのは本番環境になりがちなため、本番環境のデータについても監視が必要になります。このことについてより詳細に見ていきましょう。
機械学習システムの複雑さ
通常のシステム開発では振る舞いはコードに依存しますが、機械学習システムでは振る舞いがコードとデータに依存します。このことが通常のシステム開発とは異なる複雑さを機械学習システムにもたらします。
たとえば、振る舞いの正しさを保証するための取り組みとしてテストがあります。通常のシステム開発では構成要素を分解し、それぞれについて単体でテストしたあとに組み合わせていくという手法をとります。一方、機械学習を含むと「単体テスト」がとたんに難しくなります。その理由について詳細に見ていきましょう。
通常のシステム開発におけるコードの動作は決定論的
システム開発を行う上で、多くの場合、それぞれのコンポーネントはコードで記述できます。Web サービスを開発しようとする場合、サーバーのロジックや UI はさまざまな手法でコードで記述できます。また、インフラについてもクラウドサービス上で構築する場合は terraform やそれぞれのクラウド特有の方法を用いてコードとして記述できるでしょう。
これらを動かそうとした場合、基本的にはいつの時点でも同様の動作をします。(厳密にはそのように作ることができるというだけで、そのためには少なくない労力を払わなければいけません) コンポーネントに分割し単体で動作させたときと、デプロイ前にステージング環境にデプロイしたとき、本番環境にデプロイしたときで同じ動作を期待できます。このため、単体テストが細かい単位でできますし、本番環境にデプロイ前にステージング環境で動作確認ができます。
機械学習システムにデータのもたらす複雑さ
一方、機械学習システムにおいては振る舞いがコードだけではなくデータ、特に訓練データにも依存します。このため通常のシステム開発とは異なる問題が発生します。
学習済みモデルの振る舞いは訓練データに依存するため、機械学習システムの振る舞いはコードと訓練データに依存します。一方、日時で訓練・推論が行われるようなバッチが組まれて継続的に学習が行われるケースでは、データが開発時に必ずしも手に入りません。そのデータが手に入るのは、本番環境にデプロイしたあとです。システムの振る舞いを決めるものをすべて管理するためには、コードだけではなく本番環境のデータも監視・管理しなければいけません。
もし、本番環境で与えられる訓練データが厳密に開発時に用いた訓練データと同じであることを示せれば、機械学習を用いるコンポーネントについて単体テストが可能になり、事前に振る舞いを決められるかもしれません。ですが、本番環境で与えられる訓練データが開発時に用いられた訓練データと同じ制約を満たすことを、事前に示すのは非常に困難です。
まず、訓練データの従うべき制約を明示的に書き下すことは非常に困難です。表形式データならともかく、画像や自然言語に対してはそのような制約を記述することは困難でしょう。
また、テストを行うため、入力データに対する想定する振る舞いを明示的に書くことは容易ではありません。もし、容易ならば機械学習を用いる必要はありません。振る舞いを明示的に記述できない問題に対して用いる機械学習について、振る舞いを明示的に記述するというのは矛盾しています。
このように、機械学習システムは本番環境のデータに依存するため、通常のシステム開発とは異なる複雑さが発生します。
データのもたらす複雑さへの対応は困難
コードとは異なり、データのもたらす複雑さに対して自動的にできることはあまりにも少ないと言えるでしょう。
コードの複雑さについて、自動的にできることは数多くあります。次のものを利用するのは一般的です。
- Linter & Formatter
- 単体テスト
- CI/CD
また、ログの取得やエラー時のトレーシングなど、本番環境にデプロイしたあともシステムを監視し、問題を素早く見つけるための取り組みがなされてきています。これらについて、さまざまなプラクティスも、それを実現するためのインフラも、かなり確立されてきました。
一方、データの複雑さについて事前にできることはあまりにも少ないです。まず、先程のように継続的学習を行うため学習プロセス全体を自動化している場合、システムの振る舞いを決めるデータが開発時には必ずしも手に入らないことが挙げられます。
「ゴールデンマスター」としてみなせる静的なデータセットが手に入れば話は別ですが、そのようなデータセットが手に入るケースはまれです。また、大抵の場合、データは時間とともに変化し続けます。たとえば、広告に対する反応は社会の変化とともに人の行動が変わるため時間とともに変化しますし、単純接触効果に代表される心理学的な影響も受けて反応が変化します。人間の意図で環境を制御しやすい工場においても、データは一定ではありません。製造ラインの組み換えがよく発生するため、その変化とともにデータは変わり続けます。
別の問題として、機械学習モデルで用いるデータを扱うコンポーネントについて、「単体テスト」はできないということが挙げられます。
これまでに述べたように、システムを細分し、それぞれについて単体テストを行うことは通常のシステム開発においては一般的です。一方、機械学習モデルについて「単体テスト」は非現実的です。システムの振る舞いを決める訓練データを手に入れるためには、本番環境でパイプラインを動かす必要があるため「単体」の定義を満たしません。あらかじめ振る舞いを定められるのは、入出力の型と自明なデータについてのみになるでしょう。
このように、データドリフト (Data Drift) と呼ばれるデータの変化が発生し続けることが機械学習システムに複雑さをもたらします。
データが壊れると何もかも壊れる
ここまではデータを処理するパイプラインがあることを前提に考えてきましたが、このパイプライン自体も非常に壊れやすいです。
組織的なデータの活用において、データの作成者(作成組織)とそれを利用する組織が違うのは通常のことです。この場合、大元となるデータが利用者の予期しないタイミングで変化し、データパイプラインが壊れるという事象が、データパイプラインの運用において散見されます。筆者の例では他部署の管理する Salesforce からのデータの収集をおこなったところ、同じ仕組みは2週間ともちませんでした。壊れた理由は Salesforce で管理しているデータに変更があり、収集していたカラムが消えたためでした。
機械学習についても同様に、機械学習で使うデータを他の組織が作っていることはよくあります。その場合、意図しないタイミングでデータに変更が発生し、データパイプライン・機械学習パイプライン・機械学習モデルがすべて壊れるということが起こりえます。
余談ですが、MLOps.community の提供する podcast のこの回でもここまでに述べたことが触れられていました。英語が大丈夫でしたらぜひお聞きください。
ここまでのまとめ: Data Validation が求められる理由
だいぶ長くなったので一旦まとめます。Data Validation が必要になるのは次のような理由からでした。
- 機械学習システムの振る舞いはコードだけではなくデータにも依存する
- 継続的学習を行う場合、本番環境で使われる訓練データは機械学習システムの開発中に手に入らないため、テストが困難
- 機械学習システムの利用するデータは、機械学習以外の都合で変化し続ける
- このため、本番環境でのデータの検証と監視は非常に重要
以降では本番環境ではデータにどんな変化が発生するのか、いくつかの例をもとに確認していきましょう。
データドリフトの分類
データドリフトは時間の経過とともに発生するデータの変化を指します。ここでは Data Validation for Machine Learning に挙げられている3つのタイプのデータドリフトの例と、それぞれが発生するシナリオを合わせて確認しましょう。
Feature Skew
Feature Skew はデータの特徴量が訓練時と推論時で異なることです。データベースのテーブルに変更が加えられ、あるカラムがなくなってしまうという例が典型的です。
これはデータを収集するパイプラインのコードが訓練時と推論時とで異なってしまうことでも発生します。推論用の API のコードに加えた変更が、訓練時のデータ収集パイプラインには適用されておらず、推論結果が悪化するというのはよくあることのようです。
Distribution Skew
Distribution Skew はデータの分布が訓練時と推論時で異なることです。Distribution Skew を A unifying view on dataset shift in classification で提案された分類に従うと更に3つに細分化できます。それぞれざっくりとした説明を添えて紹介します、正確な定義は本の論文を参照してください。
- Covariate shift: 特徴量の分布の変化
- Prior probability shift: 目的変数の分布の変化
- Concept shift: ある特徴量を与えたときの目的変数の分布の変化
Covariate shift はたとえば画像認識において、訓練データでは撮影条件の良い写真を用意したものの、推論データではそれ以外にも指が写り込んでいたりボケていたりする画像が入力される状況で発生します。
Prior probability shift はたとえば異常検知において、訓練データでは正常・異常のデータを50:50で用意したもの、推論データではほぼ100%が正常である際に発生します。このケースでは大量の偽陽性を生まないよう注意が必要です。
Concept shift は判断基準が変わることによって発生します。たとえば漫画アプリなどで作品の閲覧予測を行う場合に、訓練データの収集時には人気がなく閲覧されなかった作品が、その後人気が出て推論データでは閲覧されやすくなっている状況で発生します。
Distribution Skew の分類についてはこれが唯一の正解というわけではなく、他のものも提唱されています。また、同様の内容について触れたブログポストがあるため、それらを紹介します。
Scoring/Serving Skew
Scoring Serving Skew は他の2つに比べるとはっきりと定義しにくいものです。これはシステムからの暗黙的なフィードバックループとして紹介されるものだと思います。ここでは Scoring/Serving Skew が発生するケースを紹介して説明します。
次のようなサービスを考えます。
- ユーザー参加型の動画投稿サイト (Youtube)
- 投稿される動画数が圧倒的に多く、多くの動画はほとんど人の目に触れる機会がない
そこでレコメンドを行うものとします。レコメンドは機械学習モデルを使って行います。機械学習モデルは動画の属性情報とユーザーの属性情報から、ある動画のサムネイルがユーザーに表示されたとき、ユーザーがそれを視聴するかどうかを、ユーザーの過去の視聴履歴から学習します。
このケースにおいて、Scoring/Serving Skew は次のようにして発生します。 - 新着動画 (仮に100件とする) について機械学習モデルが視聴する確率 (スコア) を予測
- 新着動画のうち、モデルの推論したスコアが高い順から 10 件を画面に表示
- 残りの 90 件はユーザーに提示される機会がなく視聴されない
- リコメンドされなかった 90 件はユーザーが視聴しないものとして機械学習モデルが再学習、次の推論でのスコアが下がる
このようにして、リコメンドされなかった 90 件はリコメンドされなかったためにスコアが下がっていくというのが Scoring/Serving Skew です。
データドリフトへの対応
データドリフトへの典型的な対応方法は、スキーマの変化と分布の変化の確認です。
スキーマの変化の確認では、データが従うべきルールをスキーマとして記述し、新たなデータがそのスキーマにしたがっているかを確認します。分布の変化の確認では、分布の間の「距離」を定義し、距離の値がしきい値を超えないか確認します。スキーマの変化と分布の変化の確認方法についてはこのあとより詳細に取り上げます。
一方、Scoring/Serving Skew については検出することが非常に困難です。暗黙的なフィードバックループにより何らかの悪影響が出ていることを、データだけから検出するのは非現実的でしょう。このような現象に気づくためには、さまざまな角度からサービスを計測し、確認し続けることが必要となります。
機械学習における Data Validation
機械学習における Data Validation の典型的な方法と機械学習に特有の課題、注意点について確認しましょう。Data Validation の方法は大きく分けてスキーマに基づくものと分布に基づくものの2種類があります。以降ではそれぞれについて詳細に述べていきます。
スキーマに基づく Validation
スキーマに基づく Validation では、データが従うべきルールをスキーマとして記述し、個々のデータがそのスキーマにしたがっているかを確認します。典型的的には次のような規則で Validation することが考えられます。
| 特徴量の型 | 検証方法 |
|---|---|
| 数値 | それぞれの値が定めた値域に収まっているか |
| カテゴリカル値 | それぞれの値が値域に収まっているか (例:「県」の値は実際に存在する 47 都道府県のいずれかであるか) |
| 文字列 | 長さは指定された範囲に収まっているか特定の形式にしたがっているか (例: 郵便番号) |
| また、それぞれの特徴量について、欠損を許すかどうかも重要です。このあたりは入力フォームや RDB データベースで取り組まれるものと変わらないかと思います。スキーマに基づく Validation について、機械学習に特有の問題を以降で確認しましょう。 |
スキーマに基づく Validation の機械学習に特有な課題
スキーマに基づく Validation のうち、機械学習に特有の問題をここでは3つ取り上げます。
- 機械学習モデルの特徴量は莫大になることがあり、手動ですべてを書き出すのは現実的でない
- スキーマを満たさないことは、必ずしも悪いことではない
- 機械学習モデルに入力されるのは、構造化データだけではない
機械学習モデルの特徴量は莫大になることがあり、手動ですべてを書き出すのは現実的ではない
通常の Web サービスとは異なり、機械学習ではデータサイエンティストが複雑な SQL を書いて膨大な特徴量を作り出すことがあります。
たとえば、過去の 1 ヶ月の行動履歴から購入予測を行う場合、過去に行った行動 (ログインなど) の回数を日毎に集計し、特徴量とするのは一般的です。具体的には、ユーザーのログイン回数、購入回数を日毎に集計して機械学習モデルの特徴量とします。この場合、取得する行動 (ログイン、購入、etc.) × 30日の特徴量ができあがるため、取得している行動のパターンが 4 つあるとそれだけで特徴量の種類は 100 を超えます。また、2 つの行動をかけ合わせて新たな特徴量を作成することもあるため (ある日にログインしかつ購入した、など) 特徴量の種類は莫大なものになりがちです。
このような例では、人手で値域を把握することは困難です。また、その特徴量に欠損が許されるのかどうかをデータソースや集計クエリから導き出すことも困難になります。このため、データから自動的にスキーマを作成することが行われます。
スキーマを満たさないことは必ずしも悪いことではない
スキーマはデータから自動的に作成することもあるため、それを満たさないデータというのはどうしても発生します。また、事前に手動で作成したスキーマであっても、それを満たさないデータはそれなりに発生します。たとえば、ユーザーの年齢は通常 0 から 120 までの値を取ると思われますが、ユーザーに自由に入力してもらう場合、その範囲を超えるようなユーザーが出現することはままあります。
このように、スキーマを用いた検証において偽陽性というのはどうしても発生します。スキーマを満たさないデータが現れた場合の対応をあらかじめ検討しておくことが必要です。
少し別の話題となりますが、何らかの条件をもってデータの監視を行っている場合に、その条件を満たさないデータが現れた場合の対応を事前に検討しておくことは重要です。
スキーマに基づく Validation 以外にも、入力データに対して訓練用データセットに含まれる最近傍点との距離を計算し、それが大きすぎないか監視しているケースでも対応方法について事前の検討が必要になります。そのようなデータが現れたときに何をするのか (エラーとして扱うのか、何らかのしきい値を持って再学習させるのか、など) 検討しておくと良いでしょう。
機械学習モデルに入力されるのは構造化データだけではない
ここまでは RDB で扱うような表形式データを対象に考えてきましたが、機械学習モデルの扱うデータはそれだけではありません。深層学習モデルに典型的ですが、画像や文章そのものを入力とすることがあります。
画像や文章に対する Validation としては、次のような取り組みが考えられるでしょう。
- 画像
- 画像のサイズは指定した範囲内か
- 画像の形式は指定したものか (ユーザーが画像をアップロードするケースでは、JPEG のフリをした PNG 画像が流れてきたりする)
- 画素のヒストグラムは許容可能か (レシートや図面のように紙に印刷されたものを読み取った場合、全体に対して白地の割合が大きくなるはずなので、黒の割合が多すぎるデータは何かがおかしい)
- 文章
- 文章の長さは許容可能か (最小値以上、最大値未満になっているか)
- 文章に表れる単語 (や形態素) のうち、未知のものの割合が許容可能範囲内か
画像や文章といった非構造化データに対して、スキーマに基づく Validation は一般的に困難です。典型的な Validation の方法は未確立なため、それぞれのユースケースにあった Validation を検討する必要があるでしょう。
分布に基づく Validation
分布に基づく Validation では、モデルの入力となるデータセットの分布が評価用データセットの分布と大きくハズレていないか検証します。
スキーマに基づく Validation ではそれぞれのデータを Validation したのに対して、データセット全体の傾向を Validation する点が異なります。また、スキーマに基づく Validation は入力フォームなどでも用いられるのに対し、分布に基づく Validation は機械学習のようなデータサイエンス特有のものだと思います。
分布に基づく Validation はデータセットの統計量に基づくものと、分布間の距離を計測する方法の2つがあります。
データセットの統計量に基づく Validation
データセットの統計量に基づく Validation では、データセットの統計量を計算し、それが許容可能な範囲内か検証します。例として、次のような取り組みが挙げられます。
- 平均、分散、パーセンタイル値といったデータセットの統計量が許容可能な範囲か
- 特定の値 (典型的には "その他" や "0", "-1") の全体に占める割合が大きすぎないか
後者ではとくに、エラーや欠損があった場合に出力される値の割合が大きくなっていないか検証することが大事です。そのような値の割合が大きくなっていることはデータを収集するパイプラインのどこかが壊れていることを示唆します。
分布間の距離に基づく Validation
分布間の距離に基づく Validation では、評価用データとの分布間の距離を算出し、それが許容可能な範囲内か検証します。
分布の間の距離を図る方法はいくつかあり、それらのうちのどれかを選択することになるでしょう。典型的には KL Divergence, JS Divergence, $L_{\infty}$ 距離を用いますが、KL Divergence, JS Divergence は解釈が困難である点には注意が必要でしょう。
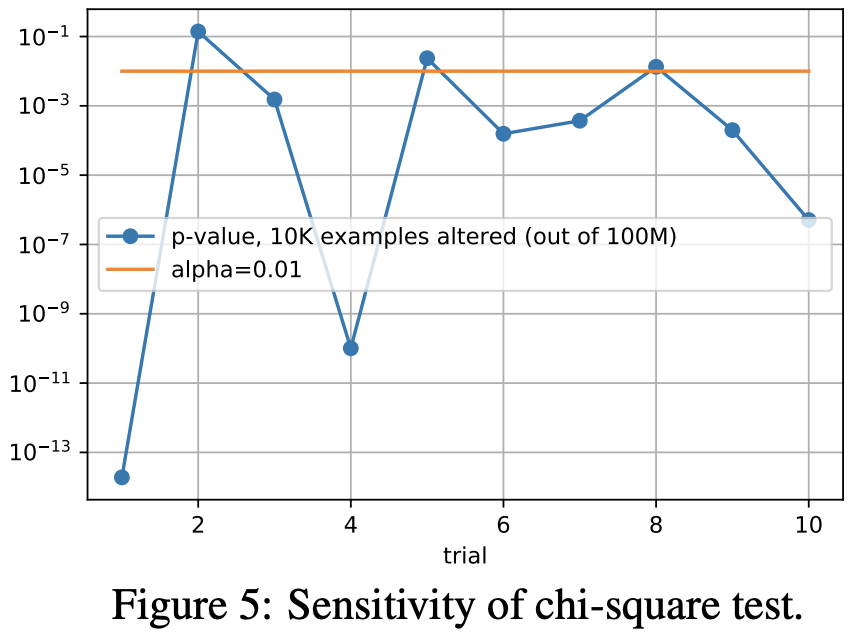
また、一見使えそうでも実際には使えない指標もあるので注意が必要です。たとえば、Data Validation for Machine Learning ではカイ二乗統計量がそのようなものの例としてあげられています。
カイ二乗検定は2つの分布が異なる分布にしたがっていないか検定する方法の1つです。この手法を用いて2つのデータセットが異なる分布にしたがっていないか検定できますが、一般に統計的な検定手法はデータセットが大きくなると機能しない (常に差が有意であるという結果になる) 点には注意が必要です。上記の論文では実際に2つの人間から見て差がない2つのデータセットを用意し、数値実験を行ったところ、10回中8回は差が有意であるという結果になったと報告しています。
Data Validation を行う上での注意事項
ここまでで Data Validation について見てきましたが、これを実際に運用する上での注意点について述べます。
運用と一口にいってもさまざまなケースが考えられ、それぞれのケースで注意すべきことが変わると思いますが、ここでは「次にしなければいけないことを明確に」「小さく始める」という 2 点についてのみ述べます。
次にしなければいけないことの明確さ
Validation において注意しなければさまざまにありますが、次にしなければいけないことが明確になることが大事です。
たとえば、Validation の結果の利用方法について、真っ先に思いつくのは Validation を通らなかったらアラートを上げるというような運用が考えられます。この場合に注意しなければいけないのは、次に何をしなければいけないかわからないアラートは無視されるということです。
実際の運用担当者にはさまざまなアラートが飛んできます。そのなかにはユーザーへ固有な環境に起因するものや、ネットワークの瞬断のようなリトライにより解決するものや、本番環境にデプロイされてしまったバグに起因するものなど、優先度の異なるものが含まれています。運用担当者はそのなかから重要なものを見極め、対応する必要があります。このため、システムの運用担当者にとってよくわからないアラートは無視されがちです。
実際に、筆者の体験として、機械学習を用いた異常検知を行う機能のある監視基盤の運用チームが、その機能を切っていたことを目にしたことがあります。理由を聞いてみたところ、「他の監視項目で足りているから」とともに、「次に何をしたらいいかわからないから」というものが挙げられました。
確かに、夜中叩き起こされて、朦朧とするなか必死に対応しようとさまざまな項目を見た結果、何も対応すべき箇所がないということが続くのは運用者にとって高い負荷となるでしょう。そうなってしまうと、そのアラートは無視されてしまいます。
他にも、Data Validation for Machine Learning では Google 社内の Data Validation を行うシステムで異常を検知したものの修正されていない例が報告されています。その理由は「再現不可能」と「対応者が無視した」の 2 つが挙げられていました。ここからも、Validation の結果が次の行動につながることは大事だとわかります。
小さく始める
Validation はさまざまなものが考えられるので、検討しだすといつまでも検討が終わりません。このため、小さく始めることが大事です。考えられるさまざまな事象を書き出し、それらの事象の発生を検知する方法と対応する方法を書き出すと良いでしょう。
また、最初から全自動化を目指す必要もありません。たとえば、自然言語処理を行うモデルにおいて、データセット中の未知語の割合を算出し監視するケースを考えてみます。このケースでは他の精度指標と合わせて計測し、最初は目視で判断して再学習を行うというのも十分有効でしょう。
運用を続けてある程度の感覚が身についてから、しきい値を検討し再学習を自動的に行うようにするというのは良い手段だと思います。一方、最初からしきい値の検討を行い自動化しようとするのはコストが高いので避けたほうが良いです。
まとめ
ここまでをまとめると、次のようになります。
- Data Validation という既存の概念を機械学習システムにも適用できる
- 一方、適用しようとすると新たな問題が発生するので、それらの問題についても検討が必要
- また、Validation を通らなかった際に、どのような対応を行うのかあらかじめ検討することが必要
本文中でも触れましたが、非構造化データに対する Validation のように、機械学習における Data Validation は未解決の問題もまだまだあります。これらについて今後も継続的に取り組みたいと思います。