◆InfluxDBとは
少し前に流行ってた?時系列データベースの1つでv1.7.4が最新です。
今は普通に使われているのでしょうか?
動向はよく知りませんが、先日少し触る機会がありましたのでコンポーネントを作ってみたいと思います。
◆テスト環境
まずは環境ですが、AWSにcentosインスタンスを立ち上げてに1.7.4を入れました。
デフォルトではユーザー認証とか設定されていないので、そのままアクセスできます。
8086が社内からアクセスできるようにしました。
データベースは「asteria」という名前で作っておきます。
保持ポリシーも「1日」とか何個か作っておきます。

具体的にコンポーネントの使用案は無いのですが、専用コネクションをつくってデータを入れるコンポーネントを作成したいと思います。
◆ライブラリ
influxdb-javaを使用します。
https://github.com/influxdata/influxdb-java#influxdb-java
◆InfluxDBコネクション
専用コネクションがあると、それっぽく見えますのでコネクションを作りましょう。
プロパティは、URL、ユーザー名、パスワードくらいでしょうか。
今回はURLしか使いません。
コネクションのテストでは、SHOW DATABASESコマンドを実行できるどうかを確認します。
何か取れたらOK!
@Override
public TestResult test() {
InfluxDB influxDB = null;
InfluxDBConnectionEntry entry = (InfluxDBConnectionEntry)getEntry();
influxDB = createInfluxDB(entry.getUrl(), entry.getUserName(), entry.getPassword());
try {
Query query = new Query("SHOW DATABASES");
QueryResult result = influxDB.query(query);
List<Result> results = result.getResults();
for (Result res : results) {
List<Series> series = res.getSeries();
for (Series se : series) {
List<List<Object>> values = se.getValues();
for (List<Object> value : values) {
for (Object obj : value) {
return new TestResult(true);
}
}
}
}
} finally {
influxDB.close();
}
return new TestResult(false);
}
◆コンポーネント
まずデータを入れたいのでInfluxDBPutコンポーネントを作成します。
やりたいことは、
1、レコードストリームで受けたレコードをInfluxDBへ入れる!
2、データベースとMeasurementと保持ポリシーを指定して入れる!
3、バッチで入れる!
4、timeというフィールドがなかったらtimeを設定してあげる!
5、timeはMilliSecondsとNanoSecondsを指定できて、必ず入るように調節する!
6、タグをカテゴリープロパティで指定できるようにする!
くらいです。
◆プロパティ
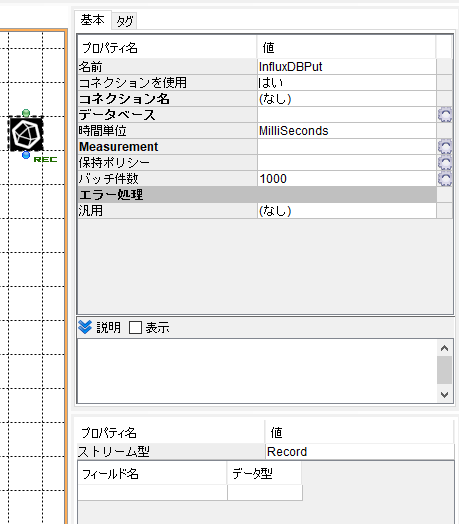
| プロパティ名 | 動作 |
|---|---|
| コネクションを使用 | コネクションを使用しない場合は、隠れているURLとユーザー名とパスワードのプロパティで指定します。 |
| コネクション名 | 専用コネクションを指定します。 |
| データベース | 今回は作成済の「asteria」を指定します。 |
| 時間単位 | MilliSecondsとNanoSecondsを選択できるようにします。 |
| Measurement | Measurementの名前を指定します。 |
| 保持ポリシー | 保持ポリシーを指定します。 |
| バッチ件数 | 1回のバッチで処理するレコード数を指定します。 |
タグ:入力ストリームのフィールドで、タグと指定使用したいものを指定します。
◆入力ストリーム
入力ストリームのフィールドをそのままInfluxDBのフィールドとして設定します。
もしtimeというフィールドが入力ストリームにあったら、その値をtimeに設定し、
timeが入力ストリームに無い場合は、実行時の時間を使います。
※timeが重なるとデータが無くなってしまうので、必ず異なる値が入るように若干調整してあげます。
System.currentTimeMillis()とSystem.nanoTime()でごにょごにょします。
private long getFirstTime(TimeUnit timeUnit) {
long time = System.currentTimeMillis();
if (timeUnit.equals(TimeUnit.NANOSECONDS)) {
return time * 1000000;//nano秒に設定してやらないといけない
} else {
return time;
}
}
private long getTime(long time, TimeUnit timeUnit) {
long thisTime;
if (timeUnit.equals(TimeUnit.NANOSECONDS)) {
long nowNano = System.nanoTime();
thisTime = time + (nowNano - _startNano);
} else {
thisTime = System.currentTimeMillis();
}
while (_timeList.contains(thisTime)) {
thisTime = thisTime + 1;//必ず入れる!
}
_timeList.add(thisTime);//つかった時刻は保持しておく
return thisTime;
}
タグはStringだけですが、フィールドはValueタイプ別にBoolean、Double、Number、Long、Stringで設定してみます。
| WarpのValue型 | InfluxDBの型 |
|---|---|
| Value.TYPE_BOOLEAN | Boolean |
| Value.TYPE_DOUBLE | Double |
| Value.TYPE_DECIMAL | Number |
| Value.TYPE_INTEGER | Long |
| Value.TYPE_STRING | String |
| Value.TYPE_DATETIME | Long |
◆execute
処理としては単純で、レコード情報からPointを作成して、バッチ件数で指定したレコード数へ達したらInfluxDBへ書き込みを行います。
それをレコードが終わるまで行います。
private BatchPoints createBatchPoints(String database, String retentionPolicy, TimeUnit timeunit) {
//BatchPointsを作成します
Builder builder = BatchPoints.database(database).precision(timeunit);
if (!StringUtil.isEmpty(retentionPolicy)) {
builder = builder.retentionPolicy(retentionPolicy);
}
return builder.build();
}
public Point createPoint(String measurement, long time, TimeUnit timeUnit, Map<String, String> tags, Map<String, Value> fields) {
//Pointのビルダーを作成
org.influxdb.dto.Point.Builder builder = Point.measurement(measurement).time(time, timeUnit);
//タグを設定します
for (Entry<String, String> entry : tags.entrySet()) {
builder = builder.tag(entry.getKey(), entry.getValue());
}
//フィールドを型を考えながら設定します
for (Entry<String, Value> field : fields.entrySet()) {
Value value = field.getValue();
if (value.getType() == Value.TYPE_BOOLEAN) {
builder = builder.addField(field.getKey(), value.booleanValue());
} else if (value.getType() == Value.TYPE_DOUBLE) {
builder = builder.addField(field.getKey(), value.doubleValue());
} else if (value.getType() == Value.TYPE_DECIMAL) {
builder = builder.addField(field.getKey(), value.decimalValue());
} else if (value.getType() == Value.TYPE_INTEGER) {
builder = builder.addField(field.getKey(), value.intValue());
} else if (value.getType() == Value.TYPE_STRING) {
builder = builder.addField(field.getKey(), value.strValue());
} else if (value.getType() == Value.TYPE_DATETIME) {
builder = builder.addField(field.getKey(), value.longValue());
}
}
//Pointを作成します
Point point = builder.build();
return point;
}
@Override
public boolean execute(ExecuteContext context) throws FlowException {
_timeList.clear();
TimeUnit timeUnit = getTimeUnit();
BatchPoints batchPoints = createBatchPoints(_database.strValue(),_retentionPolicy.strValue(), timeUnit);
long time = getFirstTime(timeUnit);
long fieldTime = -1;
int batchCount = 0;
int batchMax = _batch.intValue();
//ストリームからレコードを取得してループします
StreamDataObject[] streams = getInputConnector().getStreamArray();
for (int i=0; i < streams.length; i++) {
//まだ複数のストリームはありませんが・・
FieldDefinition fd = streams[i].getFieldDefinition();
Record record = streams[i].getRecord();
int len = fd.getFieldCount();
Map<String, String> tags = new HashMap<>();
Map<String, Value> fields = new HashMap<>();
while (record != null) {
tags.clear();
fields.clear();
fieldTime = -1;
for (int j = 0; j < len; j++) {
//レコードのフィールドの名前
String name = fd.getField(j).getName();
Value fieldValue = record.getValue(name);
//そのフィールドがtime、タグでないか確認
if (FIELD_NAME_TIME.equals(name)) {
fieldTime = fieldValue.longValue();
} else if (isTag(name)) {
tags.put(name, fieldValue.strValue());
} else {
fields.put(name, fieldValue);
}
}
time = fieldTime == -1 ? getTime(time, timeUnit) : fieldTime;
Point point = createPoint(_measurement.strValue(), time, timeUnit, tags, fields);
//Pointをためて
batchPoints.point(point);
batchCount++;
if (batchCount >= batchMax) {
//バッチで書き込みます
_influxDB.write(batchPoints);
batchPoints = createBatchPoints(_database.strValue(),_retentionPolicy.strValue(), timeUnit);
}
record = record.nextRecord();
context.notifyRunning();
}
}
if (batchPoints.getPoints().size() > 0) {
//余りも書き込み
_influxDB.write(batchPoints);
}
passStream();
return true;
}
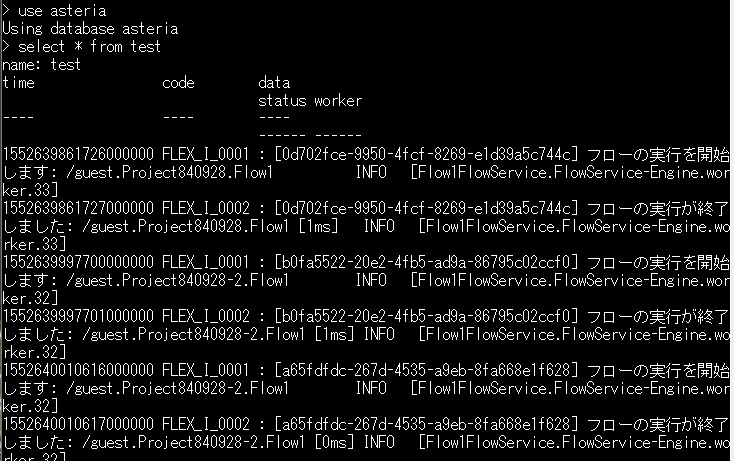
◆実行結果
試しにFlowServiceのログを入れてみて、コマンドから見てみます。
◆まとめ
Exception処理とか入ってませんが・・・InfluxDB面白いですね。
ASTERIA Warpと同じ環境にInfluxDBを入れて、FlowServiceのログを入れるのもありかな?と思いました。
指定期間で勝手に消えていってくれるし、ログがクエリーで検索できると嬉しいかもしれません。