棚画像を分割する方法について(Qiita説明用)
Qiitaでこれを全部説明したところでニーズもないので、掻い摘んでの説明になります!
1.本の文字部分をマウスで選択
2.Enterで本の画像を送信
-ここから非同期-
3.画像を分割
4.OCR処理
5.取得した文字を本検索
-ここまで非同期-
6.画面に結果表示
今回は、「4.OCR処理」です。
そして、お待ちかねの Google Vision API の出番です。
参考サイト
参考にしたのは、完全にこのサイトです。
C#でGoogle Cloud Vision APIを利用して、簡易OCRアプリケーションを作成する
https://qiita.com/nyagato_00/items/4a764260ec76e8504cf4
不足部分は、公式サイトのマニュアルを頼って実装しました。
認証から、サンプルまで。
https://cloud.google.com/docs/authentication/production?hl=ja
プラグイン準備
プラグイン「Google.Apis.Vision.v1」をインストールします。
環境変数の設定
このへんはざっくり説明となりますので、つまずいた人はコメントでも頂ければ別途説明しましょう。
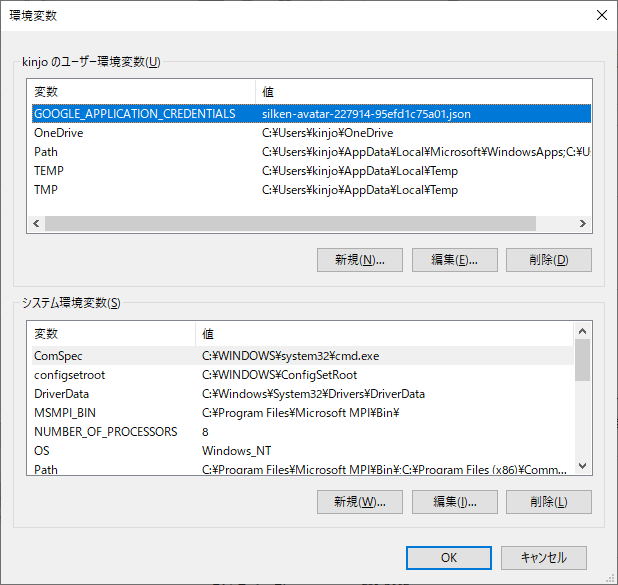
1.公式マニュアル通り、GoogleVisionAPIで取得した認証キーファイル名を環境変数へセットします。
環境変数には、ファイル名を指定します。(多分)
2.認証キーファイルを、プロジェクト直下へ配置する。
3.認証キーファイルの中身
当然、見せれません!が、どんな感じかだけ。。。
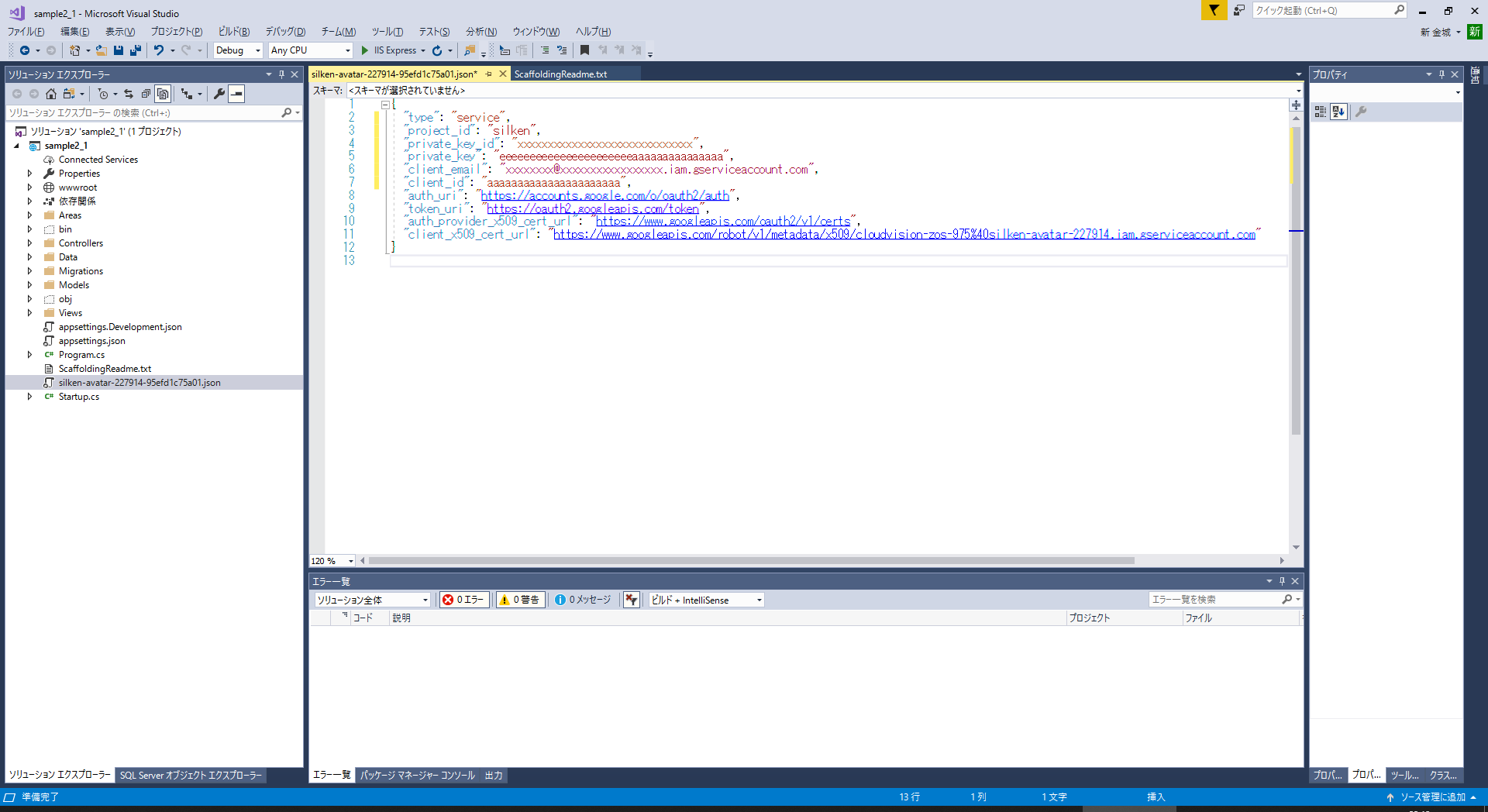
念の為、このあとこのjsonファイルを作り直しました。
Gitから、サンプルを取得
参考サイトのそのままを流用しております。
takashi-miyahara/SimpleOCRApp_for_GoogleCloudVisionAPI:
https://github.com/takashi-miyahara/SimpleOCRApp_for_GoogleCloudVisionAPI/blob/master/SimpleOCRApp_for_GoogleCloudVisionAPI/TextDetector.cs
このクラスを、ちょこっと変えて、Models/GoogleVision フォルダに配置します。
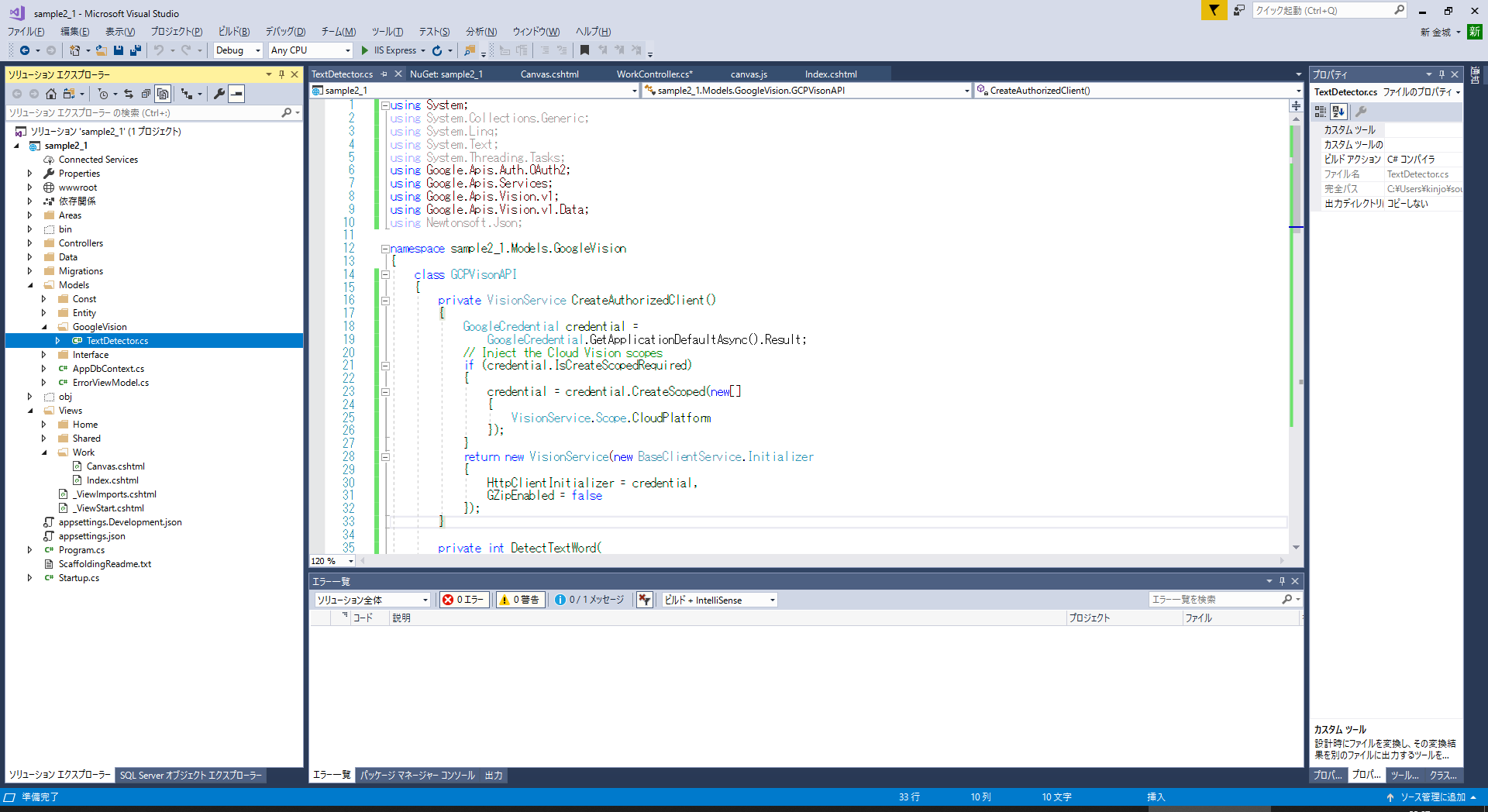
WorkControllerへ実装
あとは簡単なのです。
切り取った部分をOCRへかけてみましょう。
取得できた文字列を、画面上のPopup表示します。(簡単なので。)
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Drawing;
using Amazon;
using Amazon.S3;
using Amazon.S3.Transfer;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using sample2_1.Models;
using sample2_1.Models.Const;
using sample2_1.Models.Interface;
using sample2_1.Models.GoogleVision;
namespace sample2_1.Controllers
{
public class WorkController : Controller
{
// AmazonS3 インターフェイス
private static IAmazonS3 client;
public IActionResult Index()
{
-略- }
}
[HttpPost("UploadFiles")]
public async Task<IActionResult> FileUpload(List<IFormFile> files)
{
-略-
}
// S3 ストレージへアップロード!
static async Task WritingAnObjectAsync(string s_upd_file_nm)
{
-略-
}
//asp.net coreでサービス作ったから宣伝兼ねて技術公開する -2_6.分割画面→Canvasオブジェクト- 追加
public IActionResult Canvas()
{
-略-
}
[HttpPost]
//FormからJsonを受け取り、クラス変換してくれます。
public string Cut([FromBody]CutData cutData)
{
// 1.Imageへ画面に表示している画像ファイルを読み込み
System.Drawing.Image image = null;
try
{
image = System.Drawing.Image.FromFile(@"C:\work\work.jpg");
}
catch (Exception e)
{
throw e;
}
// 2.Bitmapに範囲指定したサイズを設定
Bitmap destbmp = new Bitmap((int)cutData.width, (int)cutData.height);
// 3.Graphicsに読み込ませるBitmapを設定
Graphics graphics = Graphics.FromImage(destbmp);
// 4.[1]でロードした画像を描画
graphics.DrawImage(image, (cutData.x * -1) , (cutData.y * -1), image.Size.Width, image.Size.Height);
// 5.保存先の指定
var stream = new FileStream(@"C:\work\cutter.jpg", FileMode.Create);
// 6.保存処理
destbmp.Save(stream, System.Drawing.Imaging.ImageFormat.Jpeg);
// 7.後処理
stream.Close();
// 8.Google Vision API 認証準備
GCPVisonAPI ocr = new GCPVisonAPI();
// 9.戻り値stringの変数作成、画像をByteArrayで開く
string getText = "";
byte[] imageArray = System.IO.File.ReadAllBytes(@"C:\work\cutter.jpg");
// 10.Google Vision APIの実行
ocr.getTextAndRoi(imageArray, ref getText);
// 受けとった文字列を返却
return getText;
// 受け取ったheightプロパティを画面に返す。
//return @"正常にCut出来ました!";
}
}
}
デバッグ実行
それでは、試してみましょう!
1回目:
狙いは、「最新 日本の地震地図」
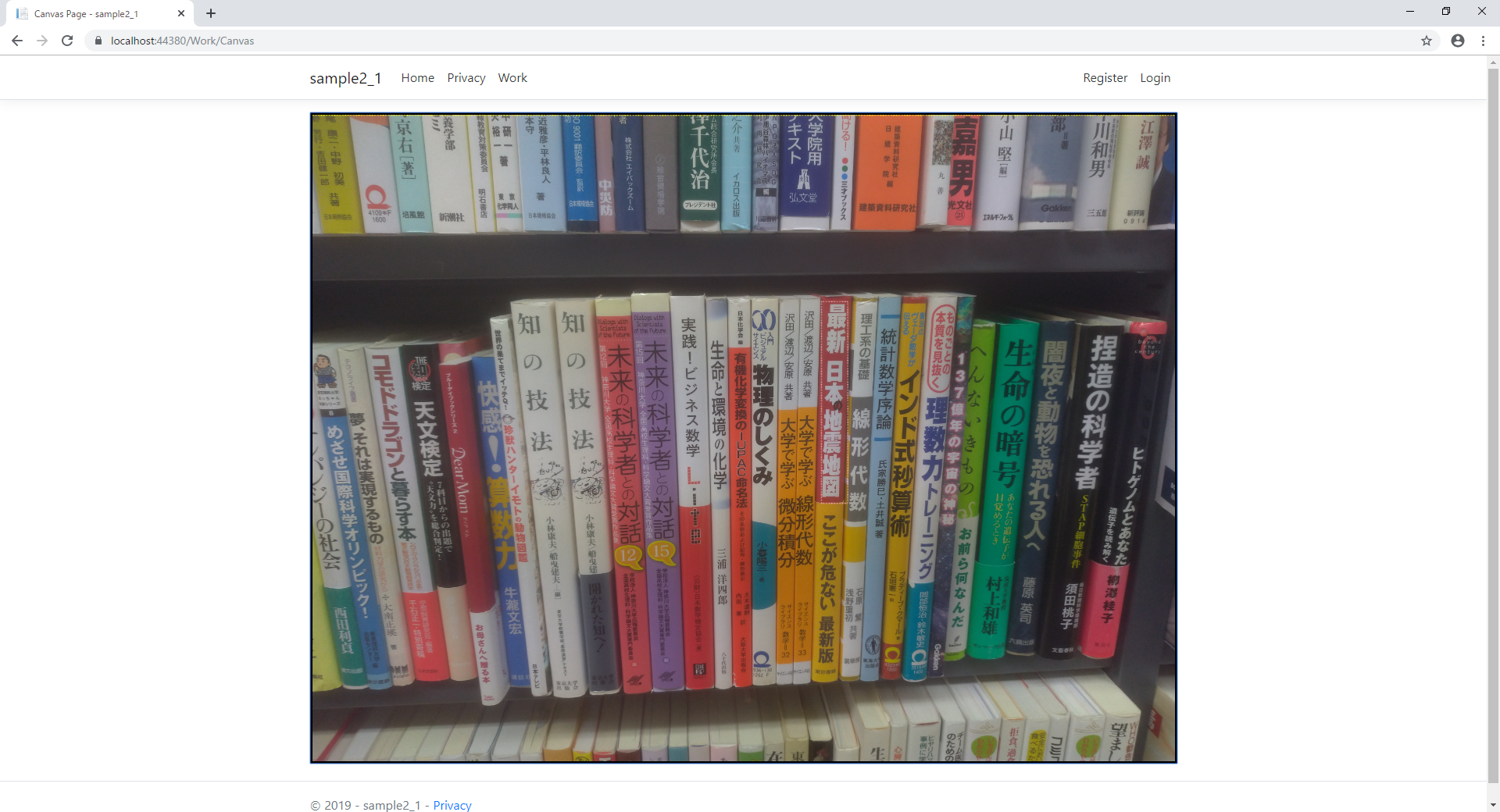
結果
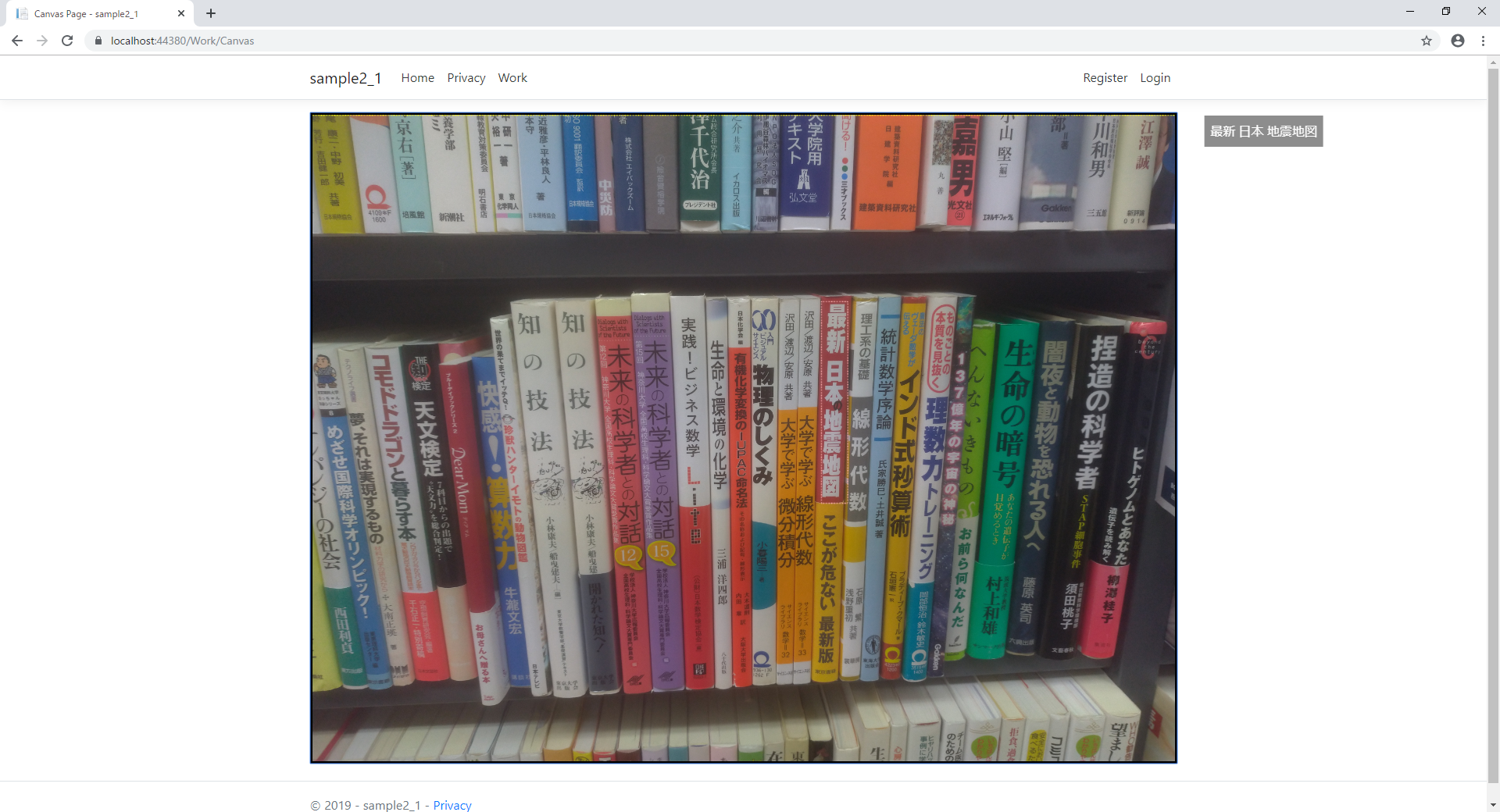
「最新 日本の地震地図」
↓
「最新 日本 地震地図」
いいですね。
小さな「の」は色も違うので認識しておりませんが。。。
2回目:
狙いは、2冊同時「実践!ビジネス数学 Lite」「生命と環境の化学」
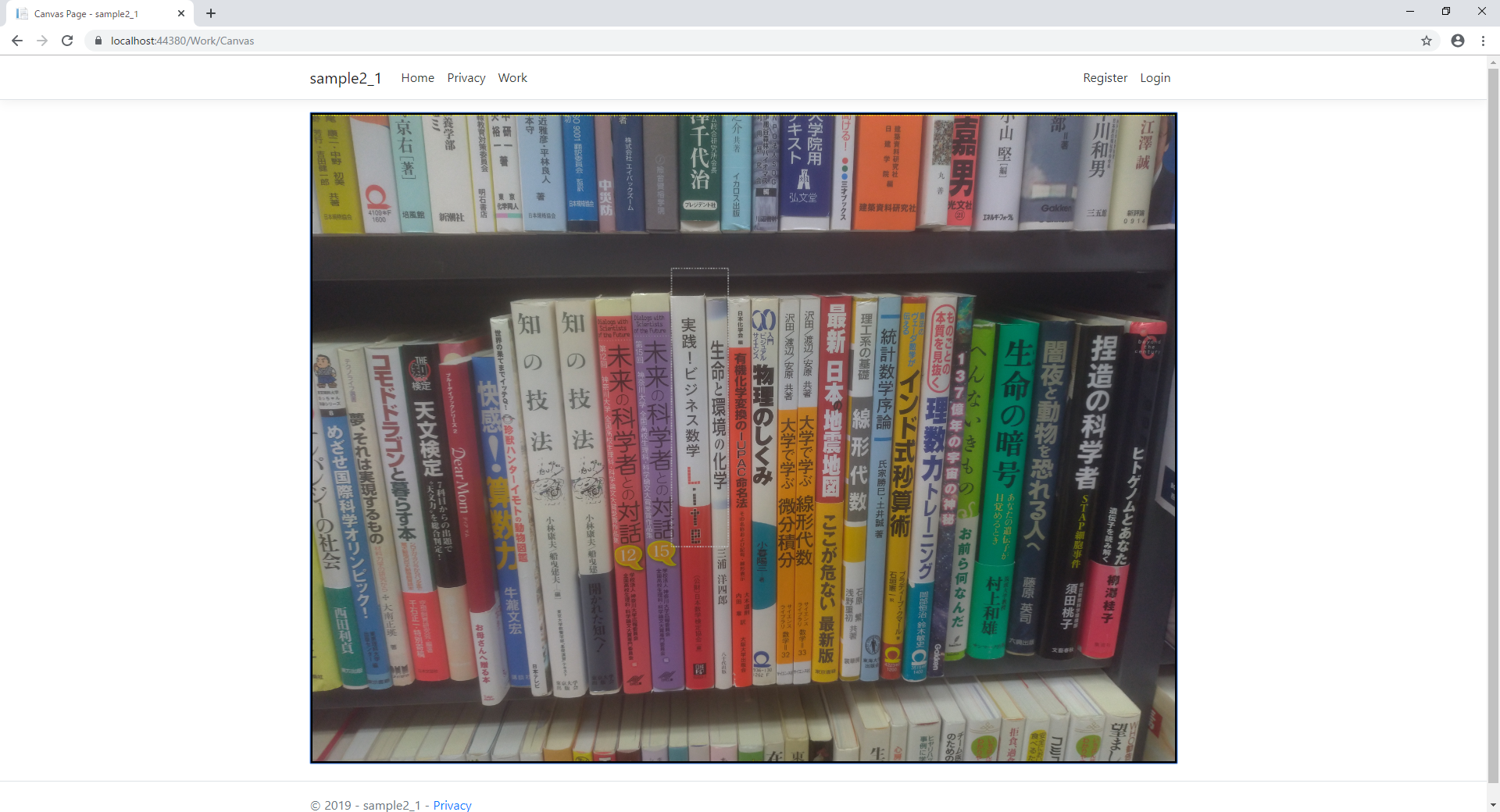
結果
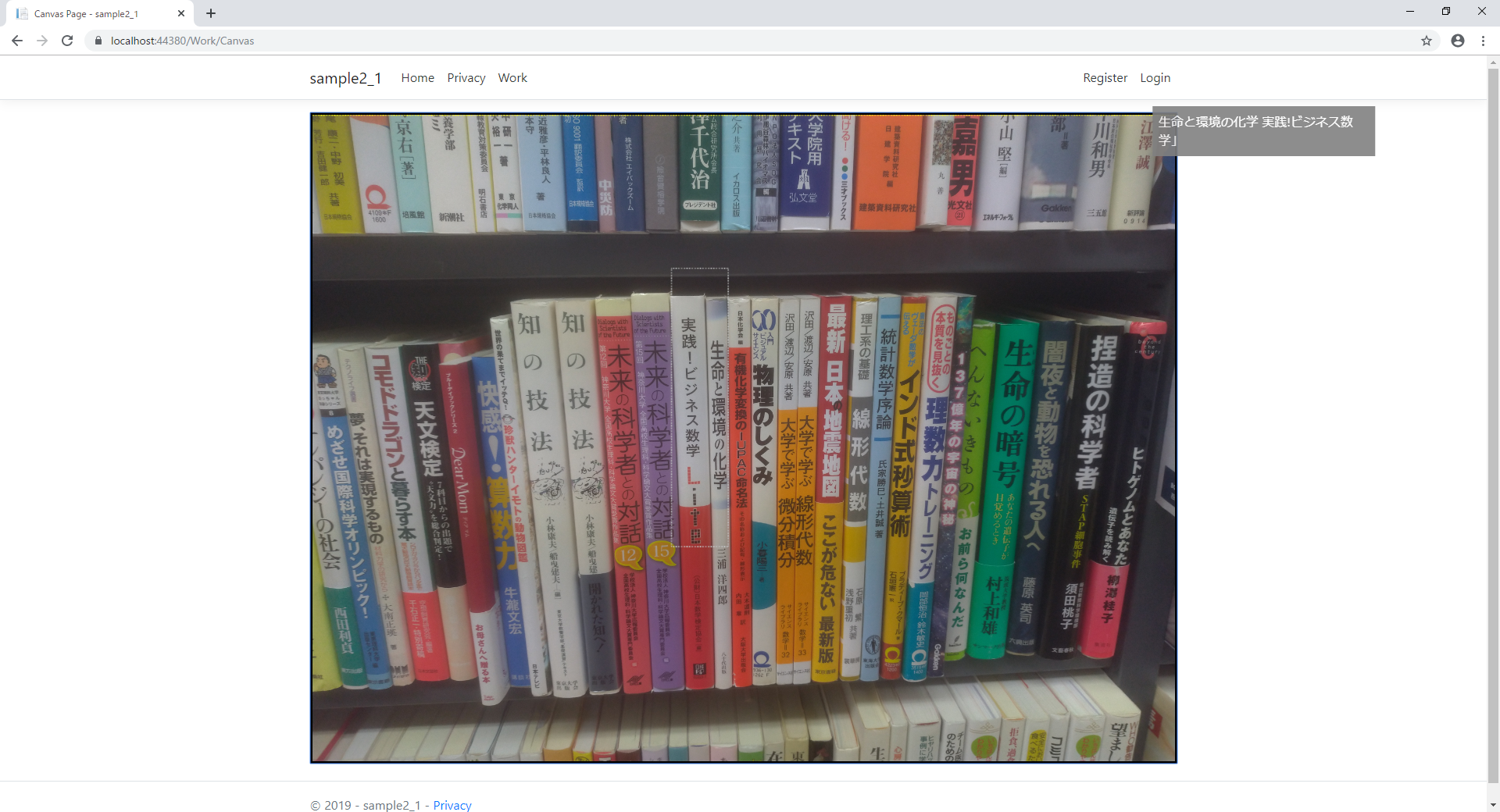
「生命と環境の化学」「実践!ビジネス数学 Lite」
↓
「生命と環境の化学」「実践!ビジネス数学」」
すごい、なかなかの精度です。
Liteが「カッコ閉じる」として認識されてますが、許容範囲。
これだけでちょっとしたサービスになりそうな気がしました。
TanaToruにメニュー追加して、選択画像のOCRサービスを作っても面白いかも。
Google Vision APIの戻り値について
戻り値にはさまざまな情報が込められております。
詳細を見る場合、Gitから取得したサンプルの .Execute() 時にサーバーと通信します。
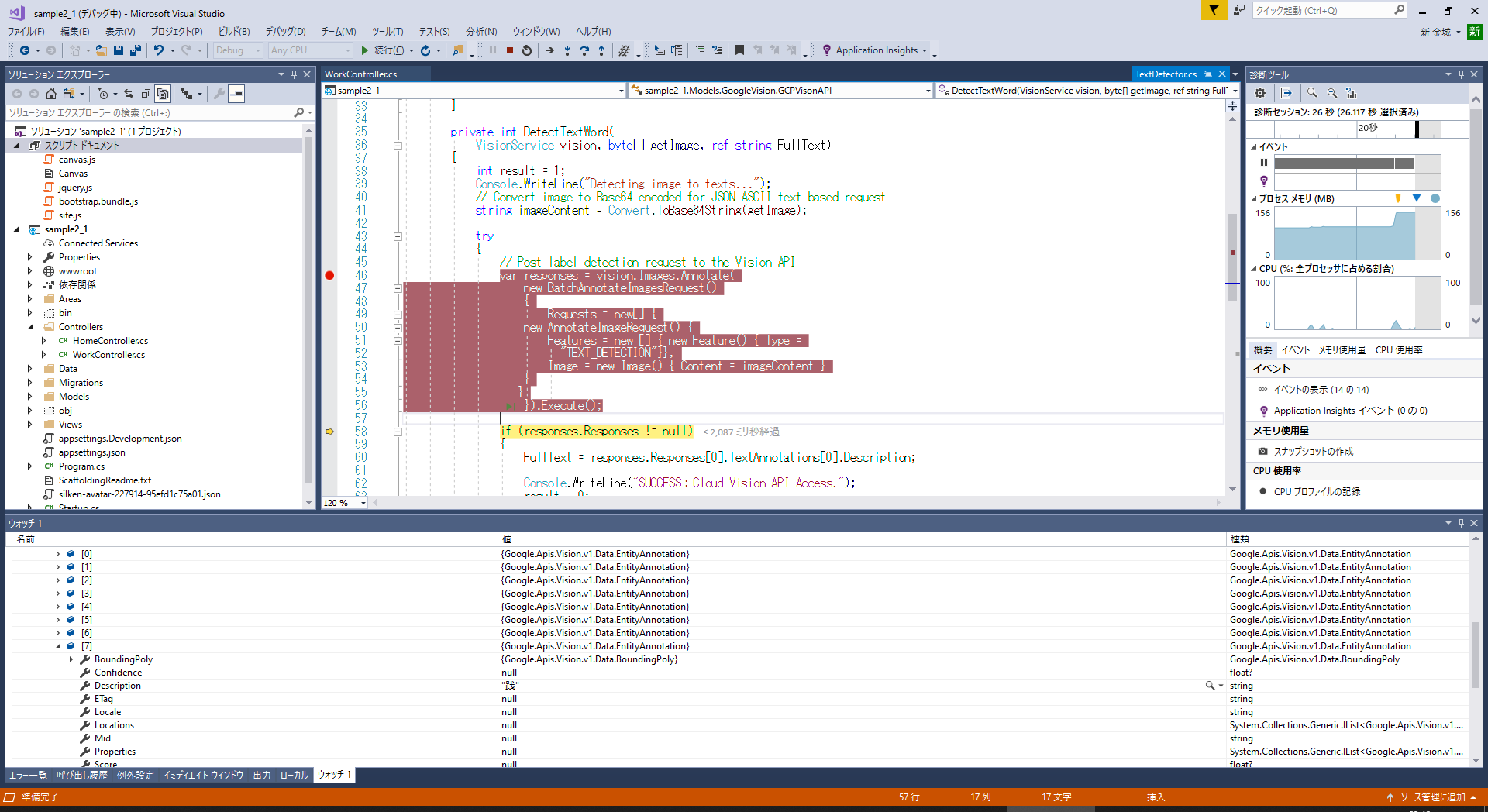
responses.Responses をウォッチで見てみると、色々見れます。
取得できた全てのテキスト:
FullTextAnnotation.Text
取得できた全てのテキストの座標情報:
TextAnnotations[0].BoundingPoly.Vertices[0~3]
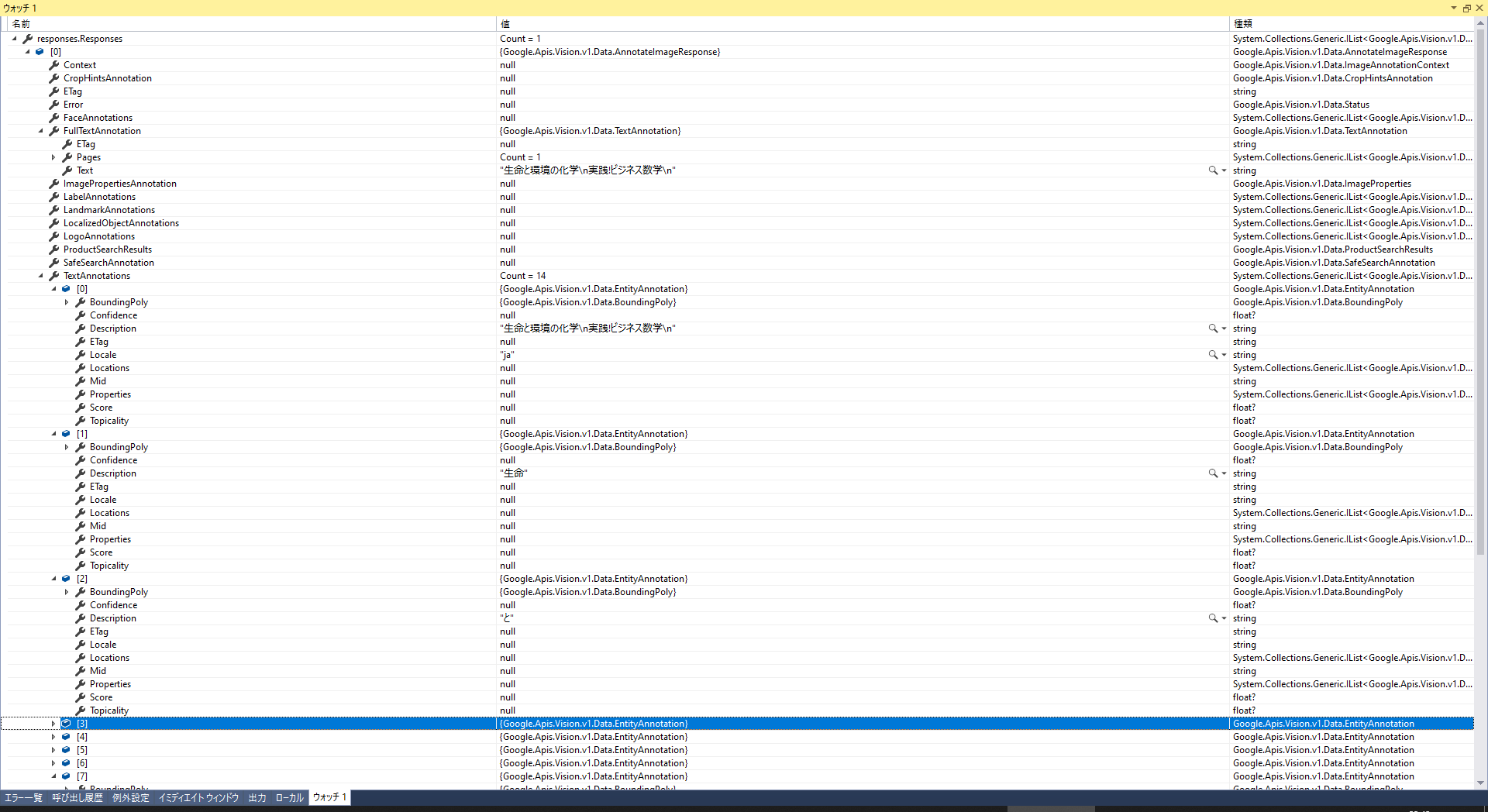
取得できた単語テキスト:
TextAnnotations[1~x].Description
取得できた単語テキストの座標情報:
TextAnnotations[1~x].BoundingPoly.Vertices[0~3]
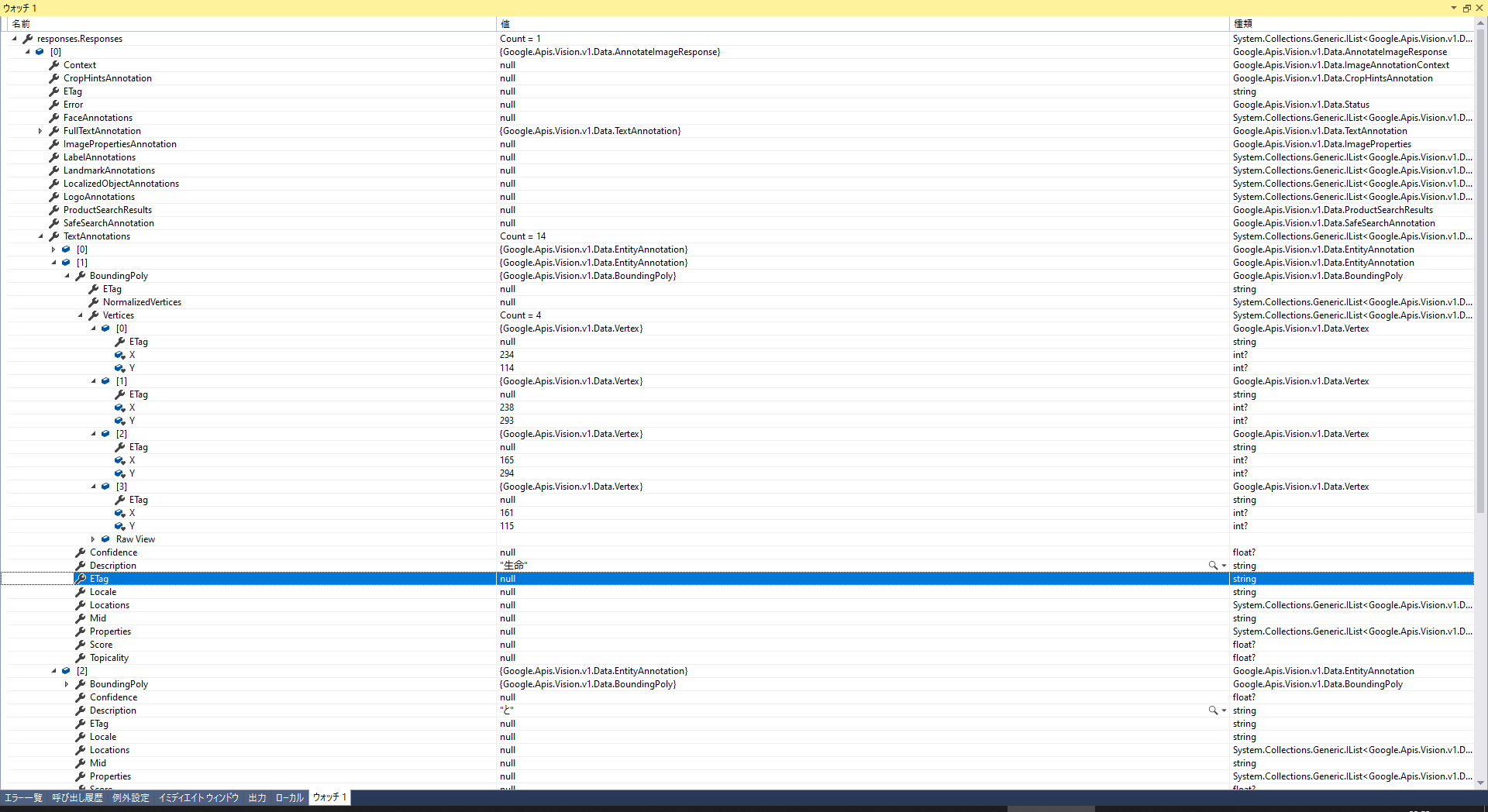
基本的には、文字の取得くらいしかしないだろうけど、文字の座標を使ってなにかしたい場合、使えるかも。
TanaToruでも使う予定です。
【是非お試しください】※完全無料です
TanaToru -本棚管理サービス-
https://app.zero-one-system.co.jp/TanaToru/