はじめに
こんばんは、miyaharaです。最近、OCRを利用した業務アプリケーションを作ったりしています。
有名所のOCRライブラリを幾つか試してみたのと、クラウドベースの画像処理APIが使いやすくて、正直ビビりましたので、備忘録も兼ねて記して置きたいと思います。
使ってみたOCRライブラリ・API
- tesseract-ocr
- Microsoft Azure Computer Vision API
- Google Cloud Vision API
OpenCV3系から、利用しやすくなった「tesseract-ocr」からはじめ、その後AzureとGCPのAPIを試しました。
今回作成するアプリケーションの制約が、「C#を使うこと」と「WindowsPCで動作するアプリケーションにすること」の2つでしたので、これらに落ち着きました。
(ですので、基本的にNuGetを利用してライブラリが導入できるものを選択しています)
有償のOCRライブラリ等は、試せなかったのですが、どの程度の精度でOCR出来るのかが気になりました。お試して試せる方法等、ご存知の方は教えて頂けたら幸いです。
それぞれのOCRライブラリの精度(雑感)
tesseract-ocr
バイナリー(.exe)形式で導入できるのもとしては、Ver.3.5.1とVer.4.0.0があります。
前者は安定番で、後者がα板のようです。欧米諸国の言語に対しては、α板を使うことで飛躍的に良くなるということはありませんでしたが、日中韓の3カ国の言語は、α板のほうが断然精度が高いです。
Ver.3.5.1には、Ver.3.5.1用の言語の学習データを、Ver.4.0.0には、Ver.4.0.0用の学習データをそれぞれダウンロードする必要があるため、単純に認識精度を高めたい場合は、Ver.4.0.0を使うことをオススメします。
しかし、バイナリーファイルはサードパーティ製になるので、この点のみご注意ください。
GitHubからソースコードをダウンロードし、ビルドする分には、問題ないかと思います。
(ビルドは結構たいへんでした)
Microsoft Azure Computer Vision API
Microsoft Azureにて提供されている「Microsoft Cognitive Services」から利用できる“Vision API”。
Microsoft社謹製ということも有り、C#での開発にはドキュメント類も整備されており、悩むことなく試すことが出来るかと思います。テキスト認識では、与えた画像中の文字の特徴から、言語を判定してもっとも有力な言語の候補を返してくれます。
また、日本語、中国語、韓国語に関しても高い精度でOCR出来ていました。
Google Cloud Vision API
Cloud Vision APIは、公式リファレンスにて解説されている言語の種類が、最も多いです。
Go言語はもとより、Python、RubyにC#などなど、Webアプリケーションを作り慣れた方でも、Windowsアプリケーションを作り慣れてた方でも利用しやすい、印象を受けました。
OCRの精度については、利用した3つうち最も良い結果を出しました。Azureの方は、なんとかして文字で表現しようと試みている感じがしましたが、Googleの方は信頼度が高い文字のみ結果に反映させているような印象でした。
3つのライブラリに言えることなのですが、0とOを完全にOCR出来たものはありませんでした。非常によく似ている文字ですし、フォントによってはほとんど差のない文字でもあります。これに関しては、使い手側で間違えることを前提にアプリケーションを作成したほうが良いでしょう。
インストール
NuGetを使って、ライブラリをインストールします。
Visual Studioはこのあたりが、非常に便利なので助かります。
PM> Install-Package Google.Apis.Vision.v1 -Version 1.32.2.1159
実装
認証処理
Vision APIを用いて画像の解析を行う前に、すでに取得済みの認証情報を使用して、サービスを認証する必要があります。認証情報に幾つか種類がありますが、今回はサービスアカウントキーを利用します。GCPのコンソールツールから、サービスアカウントキーを発行し、このキーを使用するPCの環境変数へ設定します。
ここで、アプリケーションのデフォルト認証情報(ADC)を使用します。デフォルトでは、先程の環境変数を「GOOGLE_APPLICATION_CREDENTIALS」の名前で登録してあります。
認証情報が正しく有効化されれば、Vision APIの機能を使うことができるようになります。しかし、これは認証情報が有効なのは、特定のスコープの中に限られます。
private VisionService CreateAuthorizedClient()
{
GoogleCredential credential =
GoogleCredential.GetApplicationDefaultAsync().Result;
// Inject the Cloud Vision scopes
if (credential.IsCreateScopedRequired)
{
credential = credential.CreateScoped(new[]
{
VisionService.Scope.CloudPlatform
});
}
return new VisionService(new BaseClientService.Initializer
{
HttpClientInitializer = credential,
GZipEnabled = false
});
}
リクエストを構築
さて、Vision APIを利用する準備が整いましたので、サービスへリクエストを行います。Cloud Vision APIに対するリクエストは、JSONオブジェクトとして作成し、送信する必要があります。
今回は、まず読み込んだ画像をByte型へ変換して関数へ渡します。
次に。画像に対してBase64エンコードを行います。
OCRを行うため、「TEXT_DETECTION」をペイロードします。
JSONをimage:annotate URLへのPOSTリクエストとして送信します。
この時、ラッパー関数 image().annotate()を利用して、HTTP POSTリクエストを作成します。
その後、Vision APIからのレスポンスが届きます。
これを解析して、欲しい情報を取得します。
OCR結果の全文は、「responses.Responses[0].TextAnnotations[0].Description」に格納されて言います。
また、それぞれの単語は、[1]以降の配列に順に格納されております。
private int DetectTextWord(VisionService vision, byte[] getImage, ref string FullText)
{
int result = 1;
Console.WriteLine("Detecting image to texts...");
// Convert image to Base64 encoded for JSON ASCII text based request
string imageContent = Convert.ToBase64String(getImage);
try
{
// Post text detection request to the Vision API
var responses = vision.Images.Annotate(
new BatchAnnotateImagesRequest()
{
Requests = new[]
{
new AnnotateImageRequest()
{
Features = new []
{ new Feature()
{
Type = "TEXT_DETECTION"
}
},
Image = new Image()
{
Content = imageContent
}
}
}
}).Execute();
if (responses.Responses != null)
{
FullText = responses.Responses[0].TextAnnotations[0].Description;
Console.WriteLine("SUCCESS:Cloud Vision API Access.");
result = 0;
}
else
{
FullText = "";
Console.WriteLine("ERROR : No text found.");
result = -1;
}
}
catch
{
FullText = "";
Console.WriteLine("ERROR : Not Access Cloud Vision API.");
result = -1;
}
return result;
}
結果を返す関数
public int getTextAndRoi(byte[] getImage, ref string FullText)
{
int result = 1;
GCPVisonAPI sample = new GCPVisonAPI();
// Create a new Cloud Vision clieuthorint azed via Application
// Default Credentials
VisionService vision = sample.CreateAuthorizedClient();
// Use the client to get label annotations for the given image
string getFullText = "";
result = sample.DetectTextWord(vision, getImage, ref getFullText);
FullText = getFullText;
return result;
}
アプリケーション
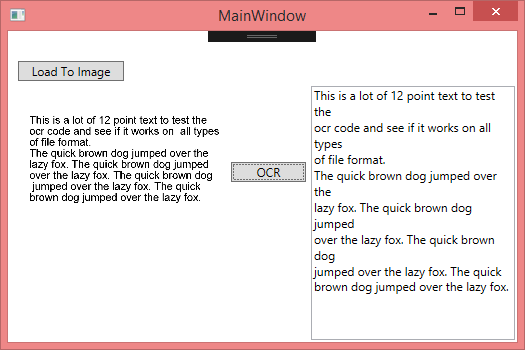
今回作成したデモアプリケーションです。
とってもWindowsなUIになっていますね。Materialデザインを適応出来るそうなので、見た目はもう少し綺麗にしたいと思います。
左上のボタン押下で、画像ファイルを読み込み、直下のイメージビューに表示します。
中央のOCRボタンを押下すると、画像がポストされ結果が帰ってくるまで待ちます。
受信したレスポンスから、OCR結果の全文を取得しテキストビューに設定します。
おわりに
Google Cloud Vision APIを利用して、任意の画像に対するOCRを行うWindowsアプリケーションを作成することが出来ました。私は、画像処理や組み込み畑出身なので、Web界隈の知識はあまりないのですが、公式のドキュメントも非常によく整備されていて躓くことなく実装することが出来ました。
はじめに試した「tesseract-ocr」にて、今回使用するフォントの学習データを作ったり、OpenCVで前処理をしたりと地道な処理をセコセコ書いていました。しかしながら、Microsoft Cognitive ServicesのVision API、Google Cloud PlatformのCloud Vision API双方とも、グレースケール化程度の前処理のみで良好な結果を出してしまいました。
やはり、単なる画像処理の限界を改めて痛感させられました。今回は、Microsoft、Googleと外部の企業のサービスを利用したのですが、自社内で将来的には内製化する必要があるなと感じました。
そして、私人身も機械学習について本格的に学ぶ必要が有るなと思った次第です。機械学習を用いてOCRを行うAPIをこれから作っていこうと思います。
また、今回のコードを私のGitHubに上げました。
とてもツッコミどころ満載のコードだと思いますので、ツッコミいただければと思います。
https://github.com/takashi-miyahara/SimpleOCRApp_for_GoogleCloudVisionAPI
参考
https://cloud.google.com/vision/docs/label-tutorial?hl=ja
https://github.com/msm2020/OCR-google-APIs