OpenShift Virtualization は、コンテナ基盤ソフトウェアであるOpenShift上で、仮想マシンを扱えるようにする機能拡張です。この拡張により、仮想マシンもコンテナアプリケーションと同様に作成したり削除したりといった、統一された操作が可能になります。こうした特徴は、「仮想マシンをコンテナと同様に扱える」という言葉でよく紹介されています。
しかし、「同様に扱える」とは、具体的にどういうことでしょうか?
この記事では、OpenShift におけるコンテナと仮想マシンの管理が、どのように同じなのかと言う点について、特に、ユーザーに開放されている操作インターフェースが同じ 「宣言的なYAML」 という作法である点に注目します。
このYAMLを介した操作を比較することで、VMとコンテナの管理における 「共通点」 と 「違い(主にリソース定義の構造)」 を具体的にイメージできるはずです。今回は、まずその第一歩として、 YAMLベースでゲストVMを作成する手順 に焦点を当ててまとめていきます。
仮想マシンを作成するYAMLファイル
早速、仮想マシンを作成する際のYAMLファイルを見てみましょう。以下は、Fedoraのディスクイメージテンプレートを使用して、1CPU / 384MB RAM / 30GB Disk の仮想マシンを作成する最小限の定義です。
apiVersion: kubevirt.io/v1
kind: VirtualMachine
metadata:
name: {{ .hostname }}
labels:
app: {{ .hostname }}
spec:
running: true
dataVolumeTemplates:
- apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: {{ .hostname }}
spec:
sourceRef:
kind: DataSource
name: fedora
namespace: openshift-virtualization-os-images
storage:
resources:
requests:
storage: 30Gi
template:
metadata:
labels:
kubevirt.io/domain: {{ .hostname }}
kubevirt.io/size: small
app: {{ .hostname }}
spec:
architecture: amd64
domain:
cpu:
cores: 1
devices:
disks:
- disk:
bus: virtio
name: rootdisk
- disk:
bus: virtio
name: cloudinitdisk
interfaces:
- masquerade: {}
model: virtio
name: default
rng: {}
features:
acpi: {}
smm:
enabled: true
firmware:
bootloader:
efi: {}
memory:
guest: 384Mi
networks:
- name: default
pod: {}
volumes:
- dataVolume:
name: {{ .hostname }}
name: rootdisk
- cloudInitNoCloud:
userData: |
#cloud-config
hostname: {{ .hostname }}
user: fedora
password: {{ .password }}
chpasswd: { expire: False }
runcmd:
- ["/bin/bash", "-c", "curl -L -o /tmp/setup.sh https://raw.githubusercontent.com/toaraki/rhcharcard2025/main/setup.sh && /bin/bash /tmp/setup.sh"]
name: cloudinitdisk
-
2行目:リソースの種類(Kind)
- kind が “VirtualMachine” となっています。これは、このYAMLファイルをOpenShiftが受け取った際、 「VirtualMachineというリソースに対するDesired State(あるべき状態)の定義である」 と指定しています。Kubernetesの他のリソース(Pod、Deploymentなど)と同様の作法です。
-
9 - 22行目:VMのルートディスクの定義(DataVolume)
- 仮想マシンにアタッチされる DataVolume の定義をしています。これは、VMのOSディスクとなるストレージリソースを宣言的に定義する部分です。
- DataSource を指定しており、環境上に予め用意されている “fedora” という名称のデータソース(ディスクイメージ)を参照しています。
- storageセクション (19 - 22行目) の書き方によって、ディスクサイズとして 30Gi をリクエストしています。
- ポイント: VMのストレージ定義も、Cloud Nativeな PersistentVolumeClaim (PVC) の仕組みに基づいているため、ストレージのプロビジョニングも宣言的に行われます。
-
23行目〜:VMゲストのコア定義 (Template)
- 仮想マシンそのものの定義情報を記述しています。
- domainセクション (31-55行目) で、CPU、メモリの割り当て量、ディスクやNICのデバイスモデルを指定しています。この辺の情報は、従来の仮想基盤であれば、VM作成時のウィザードで定義するデバイスの情報に相当する部分がコード化されています。
-
56 - 58行目:ネットワーク接続の宣言
- 仮想マシンが接続するネットワークの指定をしています。今回は、
name: defaultを指定していますが、この定義の場合、OpenShift Virtualization は、Podネットワーク(コンテナが標準的に使用する内部ネットワーク)に接続します。 - 【興味深い挙動】 ちなみに、ここの定義を外すなどして、Podネットワークに接続しない仮想マシンを作れるか試しましたが、OpenShift Virtualizationが強制的に接続を補完する動作となっているように見えました。この点は興味深い動作ですので、改めて調べてみたいと思います。
- 仮想マシンが接続するネットワークの指定をしています。今回は、
-
59 - 72行目:ディスクアタッチと初期設定 (cloud-init)
- disksセクションでは、VMゲストがマウントするディスク(先述のDataVolume)の定義をしています。
- cloudInitNoCloud セクションでは、VM起動時の初期設定を定義しています。ホスト名の設定や、ユーザーの作成、追加で実行させたいスクリプトの定義(ユーザーデータ)を入れています。これにより、VM作成と同時にゲストOS内の設定まで自動化できます。
実行:宣言された状態の作成
実際にこの定義情報をもとにVMを作成するには、OpenfhitのCLIツールのapply サブコマンド oc apply -f <yamlファイル> を使用して行います。これは、定義した「あるべき状態(Desired State)」をOpenShiftクラスターに宣言する操作です。
1. YAMLの準備と適用
YAMLファイル内の {{ .hostname }} や {{ .password }} といったテンプレート変数は、残念ながら oc process では直接処理されませんでした。
したがって、直接yamlファイルを記入するか、oc apply を実行する前に、以下のような手法で、適切な値に置き換える必要があります。
# 例: sed コマンドでホスト名とパスワードを置き換えて適用
sed -e 's/{{ .hostname }}/my-fedora-vm/' \
-e 's/{{ .password }}/YourSecurePass/' vm-fedora-template.yaml | oc apply -f -
実行例
$ oc apply -f - <<EOF
$(sed "s/{{ .hostname }}/my-fedora01/g" vm-fedora-template.yaml)
EOF
Warning: spec.running is deprecated, please use spec.runStrategy instead.
virtualmachine.kubevirt.io/my-fedora01 created
$
作成される様子の確認
vm リソースは仮想マシンの定義情報を扱うリソース、vmi はvmリソースを元に起動状態のvmインスタンスとなります。以下のコマンドでは、-w で、vmi が作成〜起動までの状態をポーリングさせた出力となっています。
[lab-user@bastion vm-templates]$ oc get vm
NAME AGE STATUS READY
my-fedora01 9s Provisioning False
[lab-user@bastion vm-templates]$ oc get vmi -w
NAME AGE PHASE IP NODENAME READY
my-fedora01 15s Scheduling False
my-fedora01 29s Scheduling False
my-fedora01 30s Scheduling False
my-fedora01 40s Scheduled worker-cluster-zkkmk-1 False
my-fedora01 42s Scheduled worker-cluster-zkkmk-1 False
my-fedora01 42s Running 10.134.0.57 worker-cluster-zkkmk-1 False
my-fedora01 42s Running 10.134.0.57 worker-cluster-zkkmk-1 True
my-fedora01 42s Running 10.134.0.57 worker-cluster-zkkmk-1 True
my-fedora01 70s Running 10.134.0.57 worker-cluster-zkkmk-1 True
my-fedora01 70s Running worker-cluster-zkkmk-1 True
参考までに、OpenShift のWeb Console からの確認した場合は、以下の様になります。
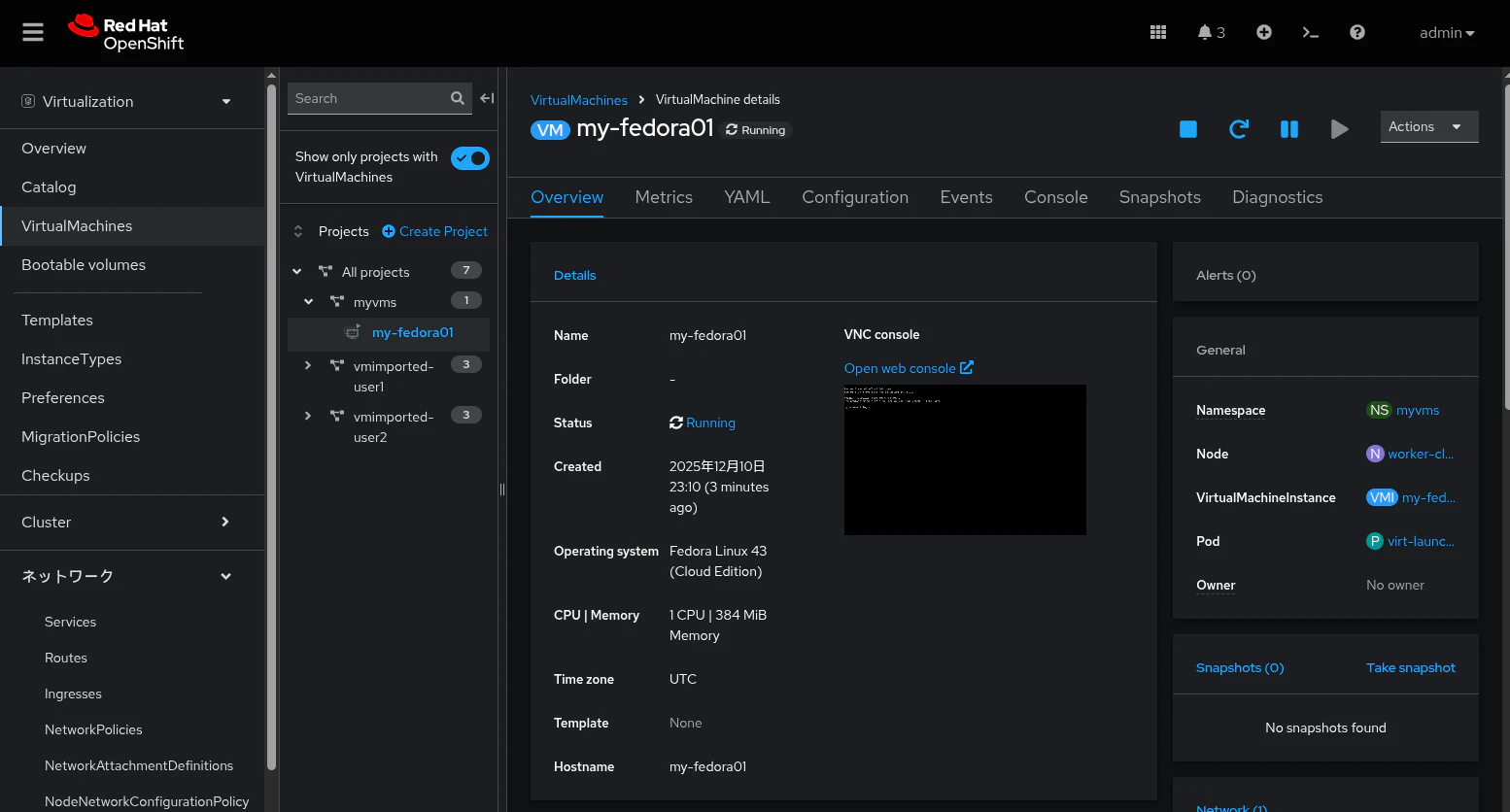
ざっと、OpenShift上で、コンテナと同様に仮想マシンを扱える様子を見てきました。
この一連の操作で重要なのは、 「宣言的な管理」 というKubernetesのコアコンセプトが、VM管理にも適用されている点です。ユーザーは、このYAMLファイルで「どのようなリソース(VM、ディスク、ネットワーク)が、どのような状態(1CPU、384MB、Podネットワーク接続)で存在するべきか」を宣言するだけで済みます。
そして、 「実際にどのように作成し、動かすのか?」 という複雑な実装の詳細、すなわちVMのプロビジョニング、ストレージやネットワークの接続設定、そしてその状態の維持までを、すべてOpenShiftのコントロールプレーンに任せる形になるわけです。
雑感
本記事では、仮想マシンを 宣言的な(命令的ではない)方法で、実際に作成してみました。YAMLで「あるべき状態」を記述し、OpenShiftのコントロールプレーンに定義を解釈させ、 「どのように作成し、動かすか」 という複雑な実装の詳細を委ねる形になります。このYAMLをインターフェースとして使用していることから、OpenShift Virtualizationは、IaCネイティブなプラットフォーム上で仮想マシンを扱えるといえるでしょう。
従来の課題とOpenShift Virtualizationの立ち位置
オンプレミス環境のプラットフォームとして、今なお仮想化基盤は中核的な役割を担っています。しかし、その運用管理の手法は、パブリッククラウドでは当たり前とされているモダンなプラクティス(DevOpsやIaC)と比べて、大きなギャップがあるのが実情です。
従来の仮想化環境で高度な自動化を進めようとすると、ユーザー側で後付け的に自動化機能の開発が伴います。これは、単に作る作業が大変なだけでなく、作ったものを保守し続けなければならないという面でも、作り物が多いのはデメリットになりがちです。
課題の根源:APIの抽象度と標準化の欠如
従来の仮想化環境では、VMの作成や設定変更といった操作において、環境構築や運用操作の自動化を進める上で 「やりにくさ」 が生じます。そこには、以下の2点が大きく関わっています。
- RestAPIベースか否か、そしてAPIの抽象度レベルの違い: 公開APIが「低レベルな操作」を提供するに留まり、ユーザー側で「高レベルな自動化ロジック」を別途実装しなければならない。
- 標準化の欠如: 前提とする仮想化基盤やツールの仕様に依存するため、対象とするソフトウェアが大きく仕様変更された場合に、ユーザーが作成したツールの互換性への考慮が限定的となります。
解決策:宣言的な管理モデルへの統合
こうした課題に対し、OpenShift Virtualizationは、「新世代の仮想化基盤」としての特徴を持っています。画期的なのは、VMのライフサイクル管理そのものが、Kubernetesの「宣言的な管理モデル」の上に構築されている点 (この記事でふれてれてみた所!)です。
これにより、VMの設定はYAMLベースでコード化され、プラットフォーム上でのリソース操作のほとんどが最初から自動化の仕組みの中に組み込まれています。
まとめ:IaCと運用の統一性
OpenShift Virtualizationは、従来のVMのメリットを活かしつつ、VMの操作インターフェースをコンテナと同じ Kubernetes API に統一します。これにより、VMもコンテナも同じ IaCの作法 で管理でき、運用負荷の軽減とモダンなワークフローへの統合を可能にします。
(その統一された管理の様子を、この記事で具体的なYAMLを通じて見ていただけたなら幸いです。)
以上