【2026年2月最新】Claude Codeと最新モデル(Opus 4.6・Sonnet 4.6)をゼロからわかりやすく解説します。
この記事では、AIエージェントの基礎概念からClaude Codeの実力、
そして2026年2月に立て続けにリリースされたClaude Opus 4.6・Sonnet 4.6の最新情報まで、一気に解説します。
はじめに
この記事はこんな人向けです:
- 「AIエージェント」って最近よく聞くけど、結局何なの?という方
- Claude CodeやChatGPTなどのAIツールに興味はあるけど、まだ使っていない方
- 最新モデル(Opus 4.6・Sonnet 4.6)で何が変わったのか知りたい方
前提知識は不要です。専門用語は都度かんたんに説明していきます。
この記事を読むとわかること:
- AIエージェントとチャットAIの違い
- Claude Codeがなぜ注目されているのか
- 最新モデル(Opus 4.6・Sonnet 4.6)で何が変わったのか
- どのプランを選べばいいのか
📖 読了時間の目安:約10〜15分
お知らせ(採用情報)
AppTime では一緒に働くメンバーを募集しております。
詳しくは採用情報ページをご確認ください。
みなさまからのご応募をお待ちしております。
そもそもAIエージェントとは?
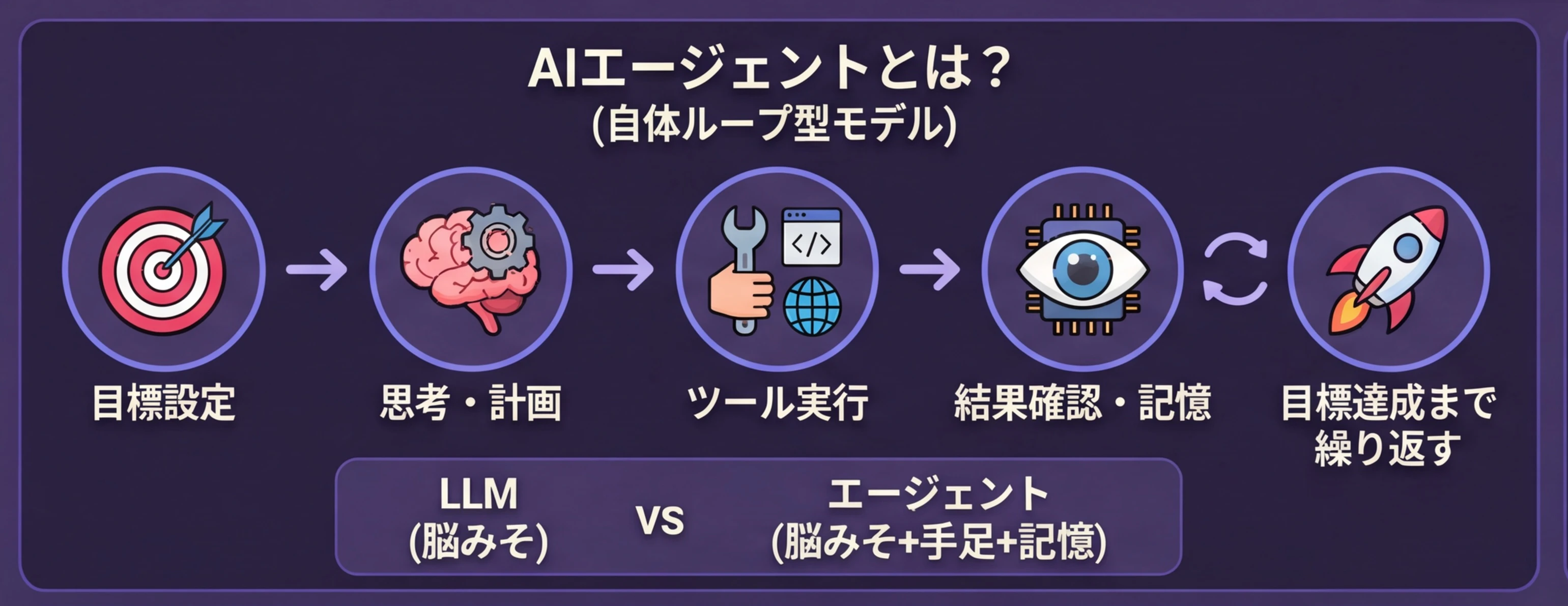
「AIエージェント」って最近よく聞くようになりましたよね。
AIの「エージェント度」には段階があります。システム会社への依頼にたとえると分かりやすいです。
「ヘルプデスクに聞く」→「常駐エンジニアに作業を頼む」→「SEに設計から任せる」→「PMに丸投げする」——と、どこまで自分で判断して動いてくれるかに段階がありますよね。AIも同じです。
ざっくり両端を分けるとこうなります。
| 分類 | イメージ | 例 |
|---|---|---|
| チャットAI(基本形) | とても賢い相談役 | ChatGPT, Gemini, Claude, Grok |
| AIエージェント(フル装備) | とても賢い主体的プロジェクトマネージャー | Claude Code, Codex, Antigravity, Manus |
チャットAIは「聞けば答えてくれる」存在。Web検索やコード実行もできますが、毎回こちらから話しかける必要があります。一方AIエージェントは「ゴールを渡せば自分で動く」存在。何が必要かを自分で判断して、完了するまで手を止めません。
Claude Codeの開発元であるAnthropicは、AIエージェントをこう定義しています。
"Agents are models using tools in a loop"
(エージェントとは、ツールをループで使うモデルである)
つまり、
目標を受け取る → 情報を集める → 行動する → 結果を確認する → 足りなければもう一回 → ... → 完了!
この「行動する → 結果を見る → また行動する…」の繰り返しこそが、AIエージェントの核心です。
通常のチャットAIが「超優秀だけど、聞かれたことに1回答えて終わりのコンサルタント」だとしたら、AIエージェントは「プロジェクトに常駐して、自分で判断しながら動き続けるプロジェクト・マネージャー」に近い存在です。
ポイント
AIエージェントの核心は「自分で考えて、道具を使って、目標達成まで繰り返し作業する」こと。
1回の質問 → 回答で終わるのではなく、目標を達成するまで自律的にループし続けるのが最大の特徴です。
LLMとAIエージェントの違い
用語解説
LLM(Large Language Model / 大規模言語モデル) とは、大量のテキストデータを学習して人間のように文章を理解・生成できるAIの「頭脳」部分のこと。GPT-5.2やClaudeなどがこれにあたります。
ここが一番混乱しやすいポイントです。LLMとAIエージェントは別物です。でも、対立するものでもありません。
- LLM = 脳みそ。超賢いけど、ただ考えるだけ
- AIエージェント = 脳みそ(LLM)+ 手足(ツール連携)+ 記憶(メモリ)+ 作業計画(プランニング)+ 繰り返し実行(ループ)
LLMはAIエージェントの「中に入っている部品」であり、対立概念ではありません。「LLMとAIエージェント、どっちがすごい?」みたいな比較はそもそも成り立たなくて、AIエージェントの中でLLMが動いているというのが正しい関係性です。
| 項目 | チャットAI / LLM単体 | AIエージェント (例: Claude Code) |
|---|---|---|
| 動作の仕組み | 質問→回答が基本 | 目標→計画→実行→確認→繰り返し |
| ツールの使用 | Web検索、コード実行等は可能 | ファイル操作、コマンド実行等を自律的に組み合わせ |
| 自律性 | ユーザー主導 | 目標主導(自分で判断して動く) |
| 作業の範囲 | 基本的に1セッション内で完結 | 複数ステップを長時間にわたり自動で連続実行 |
| 例え | 超優秀なコンサルタント | 超優秀な常駐プロジェクトマネージャー |
IBMはこう言っています:
「ツールを呼び出せるだけではエージェントにはならない。LLMにどのツールをいつ使うか自分で判断する自由を与えた時、初めてエージェントになる」
「でもGPT-5.2もツール使えるし再帰的に動くよね?」
これはとても良い指摘です。GPT-5.2のツール呼び出し精度は98.7%というとんでもないレベルに到達しています。ファイル編集、シェル実行、カスタムツール呼び出しなど、様々なツールをネイティブにサポート。さらにOpenAIのResponses APIではWeb検索、コード実行、MCP連携などのビルトインツールがサーバーサイドで提供されています。
実例として、Notion社は従来の複雑なマルチエージェントシステムを解体し、GPT-5.2単体の「メガエージェント」(20以上のツールを持つ単一エージェント)に統合しています。モデル自体がここまで賢いと「もうエージェントフレームワークいらないのでは?」と思うのも自然です。
じゃあ何が違うのか?
素のGPT-5.2と、Codex(フルスペックのエージェントシステム)の中で動くGPT-5.2では、やっぱり性能が違います。
用語解説
ベンチマーク とは、AIの性能を測るためのテストのこと。学校のテストのように、「この問題をどれだけ正確に解けるか」で点数が付きます。以降の記事に登場するベンチマーク名は、それぞれ異なる能力を測るテストだと思ってください。
| テスト内容 | スコア |
|---|---|
| 素のGPT-5.2(ツール・ループなし) | 33.9% |
| GPT-5.2をエージェントシステム(Codex)に組み込んだ版 | 51.3% |
同じ「脳」なのに、エージェントシステムに入れるだけで性能が約1.5倍になっています。
ポイント
モデル自体がどれだけ賢くても、それを「エージェントシステム」に組み込んではじめて本当の実力を発揮できる。Claude Codeも同じで、Claude(LLM)をエージェントシステムに組み込んだものがClaude Code(AIエージェント)。
AIエージェントは高い&作るの大変
AIエージェントを自分でゼロから構築しようとすると、なかなか大変です。
- 開発コスト: 基本的なもので約75万〜300万円、高度なもので約1,500万〜7,500万円以上
- 本番運用の壁: Deloitteの調査では、AIエージェントを本番運用できている組織はたったの11%
- 隠れたコスト: 予算の40〜60%を超過するケースが多い
- 年間維持費: 約750万〜1,500万円(監視、セキュリティ、コンプライアンス対応等)
個人や小さなチームがゼロからAIエージェントを作るのは、正直かなりハードルが高いのが現状です。
だからこそ、完成されたAIエージェントを使うのが正解
そこで登場するのがClaude Codeです。
用語解説
以下のベンチマーク名を簡単に説明します。
- SWE-bench: AIが実際のソフトウェアのバグをどれだけ修正できるかを測るテスト
- Terminal-Bench: ターミナル(黒い画面でコマンドを打つ操作)をどれだけうまく使えるかを測るテスト
- SWE-bench Verified: 80.9% で業界最高クラスのスコア
- Terminal-Bench: 59.3%(vs Codex 47.6%で11.7ポイント差)
- 30時間以上の自律的な集中作業が可能
- Skills、MCP、Subagentsなどの拡張機能で自在にカスタマイズ可能
現時点でAIエージェントとしての完成度はClaude Codeが頭一つ抜けています。自分でエージェントシステムを作る必要はありません。すでに最高レベルのエージェントが使える状態で提供されているので、それを活かすのが一番賢い選択です。
そしてそのエージェントをさらに強くするのが「Skills」という仕組みです。Skillsとは、Claude Codeに「こういう作業はこうやって」と教えるカスタムの指示書のようなもので、Claude Codeの拡張性の要です。Anthropicが言う「AIエージェントは作るな、スキルを作れ!」とはまさにこのことです。
もはやコーディング用途だけにあらず
Claude Codeはもはやコーディング用途にとどまりません。エンジニアでなくても、すべての人が活用できるツールになりつつあります。
Claude Codeを非エンジニア向けに簡素化した「Cowork」というデスクトップアプリは、Claude Codeがほぼ100%自律的に1週間半で作りました。Coworkは、プログラミングの知識がなくてもファイル操作やタスク管理をAIに任せられるツールです。その発表後、「AIエージェントがあれば既存の業務ツールは不要になるのでは」という見方が広がり、複数のSaaS企業の株価に影響が出たことも話題になりました。
世界は「Claude Code(=AIエージェント)さえあれば専用ツールとかいらないのでは?」という共通認識になりつつあります。今のうちに使えるようになっておくと良いかと思います。
2026年2月、怒涛の連続アップデート: Opus 4.6 & Sonnet 4.6
ここからが2026年最大のアップデート情報です。わずか12日間でOpus 4.6とSonnet 4.6が立て続けにリリースされました。
Claude 4.6ファミリーの全容
| モデル | リリース日 | 位置づけ | ひとことで言うと |
|---|---|---|---|
| Claude Opus 4.6 | 2026/2/5 | 最上位・最高知能 | 一番賢いけど高い |
| Claude Sonnet 4.6 | 2026/2/17 | バランス型(速度×性能) | 賢さとコスパの両立 |
| Claude Haiku 4.5 | 2025 | 軽量・高速 | 軽い作業向け |
Sonnet 4.6が衝撃的すぎる件
今回の目玉は間違いなくSonnet 4.6です。何が衝撃かというと、最上位モデル(Opus)クラスの性能を、5分の1の価格で実現してしまったこと。

ざっくり理解するためのベンチマーク比較
下の表の数字が大きいほど優秀です。注目してほしいのは、Sonnet 4.6がほぼOpus 4.6に並んでいるという点です。
| 何を測るテストか | Sonnet 4.5(旧) | Sonnet 4.6(新) | Opus 4.6(最上位) | GPT-5.2(参考) |
|---|---|---|---|---|
| コーディング能力 | 77.2% | 79.6% | 80.8% | 80.0% |
| PC操作能力 | 61.4% | 72.5% | 72.7% | 38.2% |
| 未知の問題を解く力 | 13.6% | 58.3% | 68.8% | - |
| ターミナル操作 | - | 59.1% | 65.4% | - |
| オフィス業務 | 1276 Elo | 1633 Elo | 1606 Elo | - |
| 金融分析 | - | 63.3% | 60.1% | - |
💡 要するにこういうこと: Sonnet 4.6はほぼOpus 4.6と同等の性能に到達しました。しかもオフィス業務や金融分析ではOpusを上回っています。つまり、多くの実務では「安い方が強い」という驚きの結果になっています。
注目すべきポイント:
- コーディング能力でOpusとの差はわずか1.2ポイント(ほぼ同等)
- PC操作能力はOpusと0.2ポイント差(ほぼ同等)
- 未知の問題を解く力は前世代から4.3倍に改善(13.6%→58.3%)
- オフィス業務と金融分析ではOpusを上回る
これは何を意味するか
以前はOpus(最上位モデル)でしかできなかったレベルのタスクが、Sonnet価格(1/5のコスト)で実行可能になりました。多くの場面で、もうOpusに手を伸ばす必要がなくなりつつあります。
ユーザーの実感
Anthropicのテストでは:
- Claude Codeユーザーの70%がSonnet 4.6を旧Sonnet 4.5より好むと回答
- 59%がSonnet 4.6を前世代のフラッグシップOpus 4.5よりも好むと回答
- 「overengineering(過剰設計)」と「laziness(手抜き)」が大幅に減少
- コードを修正する前にコンテキストをしっかり読むようになった
- 共通ロジックを重複させずに統合するようになった
開発者からの評価:
「Claude Sonnet 4.6はOpus 4.6レベルの精度、指示追従性、UIを、はるかに低いコストで実現している」—— Hercules CEO
「以前のSonnetでは不可能に近かったタスクが、今は手の届く範囲にある」
じゃあOpus 4.6はいらないの?
いいえ、そうでもありません。Opusが明確に勝るのは高度な推論と科学的分析です。
💡 要するに: 「じっくり考える必要がある難問」はOpus、「それ以外のほとんどの作業」はSonnetという棲み分けです。
| どんな能力か | Sonnet 4.6 | Opus 4.6 | どっちが上? |
|---|---|---|---|
| 大学院レベルの推論 | 89.9% | 91.3% | Opus |
| 未知の問題を解く力 | 58.3% | 68.8% | Opus |
| 高度なターミナル操作 | 59.1% | 65.4% | Opus |
| 情報を探して分析する力 | 74.7% | 84.0% | Opus |
4.6世代で追加された新機能
Opus 4.6とSonnet 4.6では、モデル性能以外にも重要な機能が追加されています。
| 新機能 | 何ができるようになったか |
|---|---|
| Adaptive Thinking(適応的思考) | モデルが「いつ・どれだけ深く考えるか」を自動で判断。簡単な質問にはサッと、難しい質問にはじっくり答えてくれる |
| Compaction(コンテキスト圧縮) | 長い会話を自動的に要約し、実質的に「無限の会話」を実現 |
| 1Mトークンコンテキストウィンドウ(ベータ) | 非常に長い文書やコードベース全体を1回で読み込み可能に(トークン=AIが処理するテキストの単位) |
| 動的フィルタリング付きWeb検索 | 検索結果を自動でフィルタリングし、関連性の高い情報だけを取得 |
Claude Codeでの使い分け戦略(2026年2月版)
Sonnet 4.6の登場で、使い分けがとてもシンプルになりました。
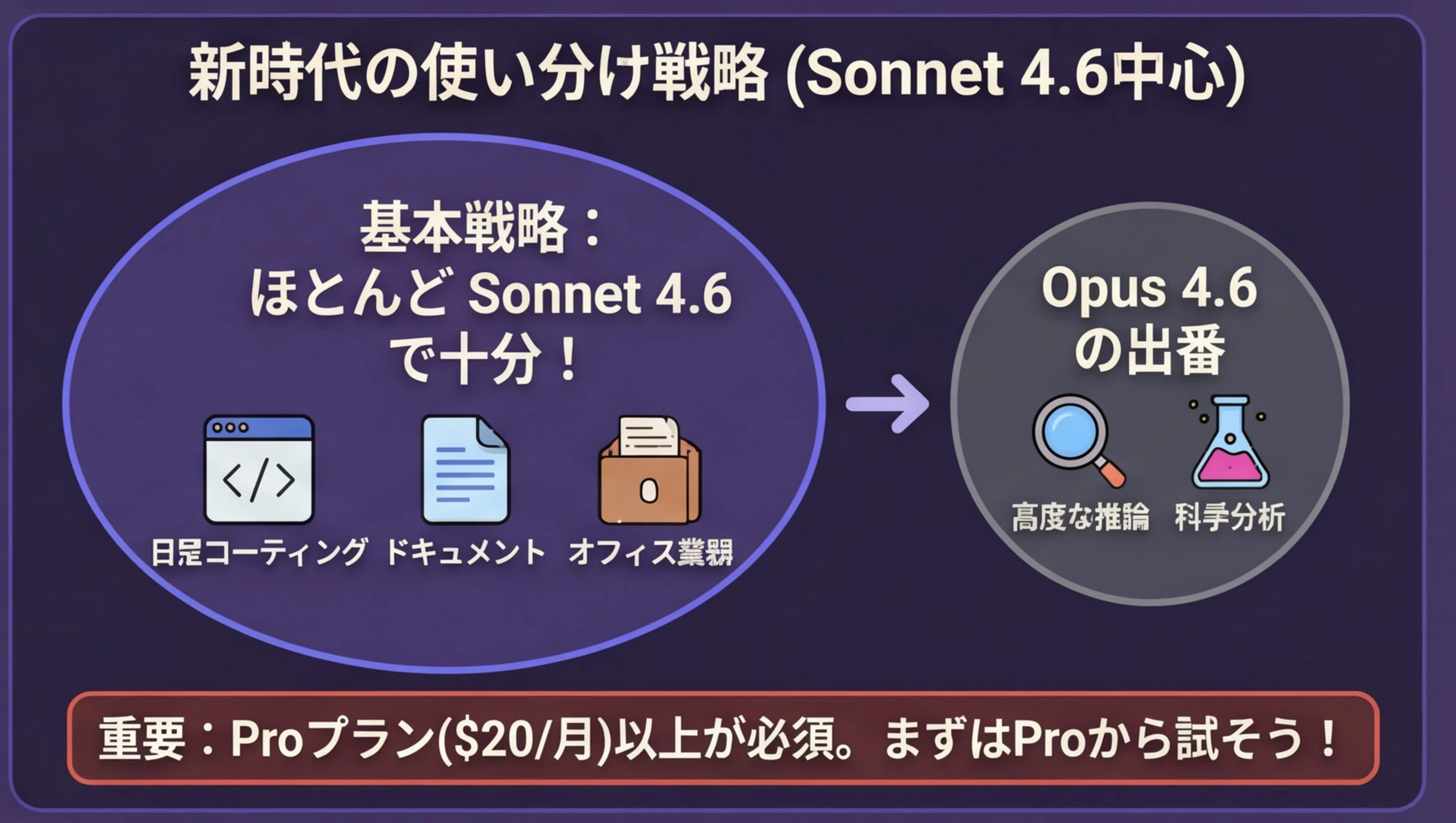
迷ったらこれだけ覚えておけばOK
- 普段の作業はすべてSonnet 4.6 でOK
- 複雑な設計や高度な分析が必要な時だけOpus 4.6 に切り替える
具体的な使い分け:
| シーン | 推奨モデル | 理由 |
|---|---|---|
| 日常のコーディング全般 | Sonnet 4.6 | Opusに迫る性能でコスパ最高 |
| テストコード生成 | Sonnet 4.6 | パターン的作業はSonnetで十分 |
| ドキュメント作成 | Sonnet 4.6 | 文章生成もSonnetで高品質 |
| フロントエンド開発・UI設計 | Sonnet 4.6 | デザインセンスが大幅向上 |
| オフィス業務・金融分析 | Sonnet 4.6 | ベンチマークでOpusを上回る |
| 超複雑なアーキテクチャ設計 | Opus 4.6 | 深い推論力が必要な場面 |
| 科学的・数学的分析 | Opus 4.6 | 高度な推論で明確に優位 |
| 大規模コードベースの根本原因分析 | Opus 4.6 | 多角的な分析力が強い |
Claude Codeを使うためのコスト(2026年2月時点)
まず結論:どのプランを選べばいい?
結論を先に言うと
Sonnet 4.6がOpusレベルに到達したことで、Proプラン($20/月 ≒ 約3,000円)で十分すぎるほど使えます。まずはProから始めて、プログラマーや制限に頻繁に当たるようならMax 5xへのアップグレードを検討するのがおすすめです。
| あなたのタイプ | おすすめプラン | 月額 | 理由 |
|---|---|---|---|
| お試し・非エンジニア | Pro | $20 | Sonnet 4.6でClaude Codeを使い始めるのに十分 |
| 軽〜中程度の開発者 | Pro | $20 | Sonnet 4.6がOpusレベルなので困らない |
| 本格的な開発者 | Max 5x | $100 | 制限ストレスなく、必要時Opusも使える |
| ヘビーユーザー | Max 20x | $200 | Opus 4.6も含めて自由に使いたい人向け |
📊 詳しいプラン比較を見る(クリックで展開)
プラン別 基本機能比較
| 項目 | 無料($0) | Pro($20/月) | Max 5x($100/月) | Max 20x($200/月) |
|---|---|---|---|---|
| Claude.ai チャット | ○ | ○ | ○ | ○ |
| Claude Code 使用 | × | ○ | ○ | ○ |
| Opus 4.6 利用 | × | ○ | ○ | ○ |
| Sonnet 4.6 利用 | ○(制限大) | ○ | ○ | ○ |
| デフォルトモデル | Sonnet 4.6 | Sonnet 4.6 | Sonnet 4.6 | Sonnet 4.6 |
重要: 無料プランではClaude Codeは使用できません。最低でもProプラン($20/月)が必要です。
朗報: 無料プランでもSonnet 4.6がデフォルトになり、ファイル作成・スキル・Compactionが利用可能に。チャットAIとしてはかなり使えます。
API料金比較(開発者向け)
| モデル | 入力 (per MTok) | 出力 (per MTok) | コスト比 |
|---|---|---|---|
| Sonnet 4.6 | $3 | $15 | 1x(基準) |
| Opus 4.6 | $15 | $75 | 5x |
| Opus 4.6 Fast | $30 | $150 | 10x |
Opus 4.6 vs Sonnet 4.6 — クォータ消費の違い
| 観点 | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| クォータ消費 | 基準(1倍) | 約5〜10倍 |
| Proプランでの実用性 | 十分使える | 数メッセージで制限到達も |
| Max 5xでの実用性 | 余裕 | 戦略的に使う必要あり |
| Max 20xでの実用性 | 無制限感覚 | 比較的自由に使える |
まとめ
| ポイント | 要約 |
|---|---|
| AIエージェントとは | ツールをループで使うモデル。自律的に目標達成まで動き続ける |
| LLMとの違い | LLMは「脳」、エージェントは「脳+手足+記憶+計画」の統合システム |
| なぜ自作しないのか | 開発コスト・運用コストが高く、本番化できている組織はわずか11% |
| Claude Codeの強み | SWE-bench 80.9%で業界最高クラス。拡張機能で自在にカスタマイズ可能 |
| Opus 4.6 | 最上位モデル。高度な推論・科学分析で真価を発揮 |
| Sonnet 4.6 | 今回の主役。Opus級の性能を1/5の価格で実現。多くの実務タスクでOpusを上回る |
| 推奨戦略 | ほとんどの場面でSonnet 4.6。Opusは高度な推論が必要な時だけ |
| おすすめプラン | まずはPro($20/月)から。Sonnet 4.6がOpusレベルなのでコスパ抜群 |
Anthropicが言う「AIエージェントは作るな、スキルを作れ!」というメッセージの意味がおわかりいただけたでしょうか。
すでに最高レベルのAIエージェントが目の前にあり、しかもSonnet 4.6の登場でそのコストパフォーマンスは劇的に向上しました。
あとはそれを活かす「スキル」を磨くことに集中しましょう。
📝 注記: 本記事のプラン料金やクォータ消費量は執筆時点(2026年2月19日)の情報です。最新の料金体系はClaude公式サイト
をご確認ください。
ベンチマーク詳細はAnthropic公式ブログ
で確認できます。