もくじ
- fast.aiとは
- fast.aiのミッション
- style-transferをやってみる。
- どんな画像が生成されたか
- 反省会など
1. fast.aiとは?
理論や数学から入るBottom-upアプローチではなく、まずはコードを動かしてタスクを解くTop-downタイプのMOOCです。タスク例としては、猫と犬の分類、映画レビューのgood/bad分類、スーパーの売上予測などがあります。
現在は、Deep Learningのコースが2つ(Part1, 2)、Machine Learningコースが1つあり、今年DLコースのPart3がリリース予定とされています。
▼他ではあまりみない特徴として、
・受講自体が無料(※)
・タスクベース
・最新の手法をアクティブに取り入れ、実装レベルで説明している(2,3年前の世界最高記録をお気軽に)
・Excelを用いた説明があり、中身がブラックボックスといわれがちなDLがどのように処理を行っているのかが理解しやすい。
※環境設定、GPU等がボトルネックになりがちですが、Google Colabなどの台頭により、完全フリーでできるみたいです。
▼参考URL
・DL4US落ちたので、google翻訳でfast.aiをやるしかない①
・fast.ai の Practical Deep Learning for Coders, Part1 を受けた
・Lesson別の概要 (各講義の内容、動画の再生時間、参考リンクなど)
・ディープラーニングに入門するためのリソース集と学習法(2018年版)
・無料オンライン講座(fast.ai)の学生、機械学習でグーグルの研究者に勝利
・全レクチャーのすばらしきスクリプト(Hiromi Suenagaさん)
・fast.aiのQiita記事
2. fast.aiの理念
"Making neural nets uncool again"
"fast.ai’s mission is to make the power of state of the art deep learning available to anyone. In order to make that happen, we do three things:
- Research how to apply state of the art deep learning to practical problems quickly and reliably
- Build software to make state of the art deep learning as easy to use as possible, whilst remaining easy to customize for researchers wanting to explore hypotheses
- Teach courses so that as many people as possible can use the research results and software"
Deep Learningの民主化がミッションで、
Top-downアプローチ、SOTA (state-of-the-art: 最先端)の追求、シンプルなライブラリなどの源流はここにあるようです。
ここ最近の流れとしては、大幅に改良されたライブラリ(fast.ai v1)が昨年10月にリリースされ、
それに伴いPart1, 2で扱ったタスクのNotebookが一新されました(URL)。
そのため、Part3からはじめてみる、、というのも可能かもしれません。
3. style-transferをやってみる。
比較的面白気のありそうなタスクをやってみます。
style-transferは、写真をほかのスタイルに変えるというもので、今回のゴールは、人の写真をゴッホ風にすることです。
使用ライブラリはPyTorchと旧fastai、データセットはImageNet
Notebook自体はPart2 Lesson13のもの
# はじめのおまじない
%matplotlib inline #新たなWindowにグラフやイメージが描画されないようにする
%reload_ext autoreload #importしているpyファイルを修正した際、
%autoreload 2 #Kernelの再起動せず、自動読み込みする。
続いて、import
from fastai.conv_learner import *
from pathlib import Path
from scipy import ndimage
torch.cuda.set_device(0) # デフォルトで使用するGPUを設定。今回は0番目のGPU使用
torch.backends.cudnn.benchmark=True #cuDNNのベンチモードをオン。これで、高速化するらしい。
ファイルパスの定義
# wget http://files.fast.ai/data/imagenet-sample-train.tar.gz
# 今回使用するデータ(Imagenet)は上記から取得できる。
PATH = Path('C:/Users/user/fastai/data/imagenet')
PATH_TRN = PATH/'train'
img_fn = PATH_TRN/'n01440764'/'n01440764_26631.JPEG'
img = open_image(img_fn)
style_fn = PATH/'style'/'starry_night.jpg'
style_img = open_image(style_fn)
plt.imshow(img);
plt.imshow(style_fn)

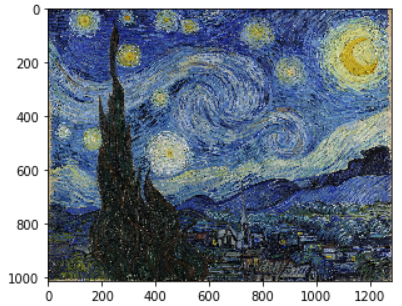
ファイルを読み込んで、描画。
今回ゴッホ風にしたいのは、この青年魚の画像、そしてもとにするStarry Nightの画像
以降、青年魚として呼び、Starry nightをゴッホ風 or 廃り/らせる とします。
sz = 288 #設定したい画像のサイズ(288 by 288)
trn_tfms,val_tfms = tfms_from_model(vgg16, sz)
img_tfm = val_tfms(img)
img_tfm.shape
>>>(3, 288, 288)
今回は2,3枚しか画像を扱わないため、サイズが大きくても問題はないです。
tfms_from_modelにvgg16を入れ、その後、imgを入れていきます。
ニュアンスとして、画像サイズ288×288でtransfroms img from vgg16 という感じになります。
def get_opt():
opt_img = np.random.uniform(0, 1, img.shape).astype(np.float32)
opt_img = scipy.ndimage.filters.median_filter(opt_img, [8,8,1])
opt_img_v = V(val_tfms(opt_img/2)[None], requires_grad=True)
return opt_img_v, optim.LBFGS([opt_img_v])
opt_img_v, optimizer = get_opt()
ここで、青年魚を廃らせるための画像を作ります。
よくわからないと思うので、実際に画像を見てみます。
uni = np.random.uniform(0, 1, img.shape).astype(np.float32)
plt.imshow(uni)
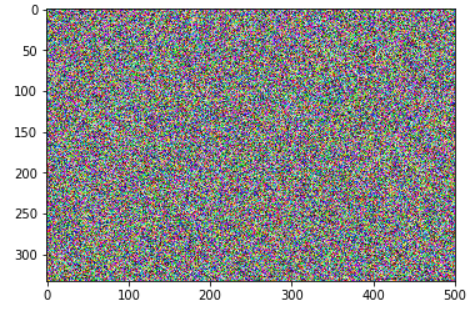
今回はこの砂嵐の画像をゴッホ風の青年魚に仕立てていきます。
以降、砂嵐として呼びます。
blur = scipy.ndimage.filters.median_filter(uni, [8,8,1])
plt.imshow(blur)
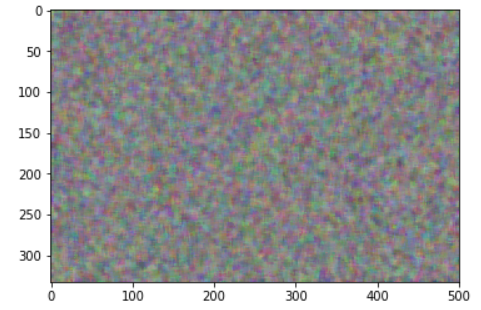
講師のJeremyさん曰く、ぼやかしたほうがよりよく学習されるとのこと。
4行目の"opt_img_v = V(val_tfms(opt_img/2)[None], requires_grad=True)"
では、学習可能な形にopt_imgを変換させています。
m_vgg = to_gpu(vgg16(True)).eval()
set_trainable(m_vgg, False)
VGG16というpre-trained model(すでに学習された強いモデル)をGPUにぶちこみます。
今回はこのモデル自体の学習は行わないため、.eval()とし、set_trainableをFalseにしています。
class SaveFeatures():
features=None
def __init__(self, m): self.hook = m.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output): self.features = output # hook func
def close(self): self.hook.remove()
このSaveFeaturesは、特定のlayerを登録しておけば、学習時にそのlayerのfeature(=output)をself.featuresにしまうことができます。
たった5行のコードですが、今回のタスクにおいてこれがカギとなります。
何故かというと、青年魚をもとに砂嵐の画像を学習させていきますが、その際、両者の特定のlayerのfeatureを利用するためです。
block_ends = [i-1 for i,o in enumerate(children(m_vgg))
if isinstance(o,nn.MaxPool2d)]
block_ends
>>>[5, 12, 22, 32, 42]
先ほどのSaveFeaturesでお話したlayerが上記のblock_endsにあたります。
MaxPoolingの1つ前のLayerをここでは指定しています(ReLU)。
MaxPoolingによって、grid sizeが小さくなってしまい良いfeatureが得られないんだとか
sfs = [SaveFeatures(children(m_vgg)[idx]) for idx in block_ends]
ここで、何番目のlayerをSaveFeaturesに登録するかを伝えています。
すなわち、block_endsの番号に該当するlayerのfeatureです。
これによって、モデル学習時(forward)に勝手にfeaturesがsfsに入っていきます。
m_vgg(VV(img_tfm[None]))
targ_vs = [V(o.features.clone()) for o in sfs]
[o.shape for o in targ_vs]
>>>[torch.Size([1, 64, 288, 288]),
>>> torch.Size([1, 128, 144, 144]),
>>> torch.Size([1, 256, 72, 72]),
>>> torch.Size([1, 512, 36, 36]),
>>> torch.Size([1, 512, 18, 18])]
img_tfmは青年魚の画像なので、学習対象ではありません。
VVの中に入れることで、featureがupdateされずに済みます。(Vはupdate用)
また、1行目にはforwardが記載されていませんが、記載なしでforwardを行ってくれます。
そのため、1行目をキーにSaveFeaturesが作動し、img_tfmにおけるblock_endsのfeaturesがsfsに入ります。
style_tfm = val_tfms(style_img)
m_vgg(VV(style_tfm[None]))
targ_styles = [V(o.features.clone()) for o in sfs]
[o.shape for o in targ_styles]
>>>[torch.Size([1, 64, 288, 288]),
>>> torch.Size([1, 128, 144, 144]),
>>> torch.Size([1, 256, 72, 72]),
>>> torch.Size([1, 512, 36, 36]),
>>> torch.Size([1, 512, 18, 18])]
続いて、style_img ゴッホの絵画です。
青年魚と同様のステップを踏みます。
def gram(input): # gram matrix
b,c,h,w = input.size()
x = input.view(b*c, -1)
return torch.mm(x, x.t())/input.numel()*1e6
def gram_mse_loss(input, target): return F.mse_loss(gram(input), gram(target))
Gram matrixと言われるものを定義しています。
ゴールに立ち戻ると、やりたいことはゴッホ"風"の青年魚であって、ゴッホの青年魚ではありません。
具体的に言うと、絵画に出てくる月や星、churchなど(spacial information)は今回あまり必要ないのです。
だからどこかの段階で、それらの情報を空の彼方へと吹き飛ばす必要があります。
その手段としてGram matrixがあるということになります。
中身を見てみると、3行目でflattenが行われており、sizeが(bc, hw)となっています。
このflattenの段階で、spacial infoを吹き飛ばせるとのこと。
そして4行目で行っていることは、(bc, hw) @ (hw, bc) です。
説明のために簡略すると、例えば下図のように (1,25) @ (25, 1) の場合 (1,1)が残ります。
@ は相関性を示すもので、両者がどれだけ似た者同士かを計算しています。
layerの段階にもよりますが、例えば両者でtexture度合いはどのくらいなのか、どれほどbrightなものなのか、どれほどdarkな性質があるのか、、など。
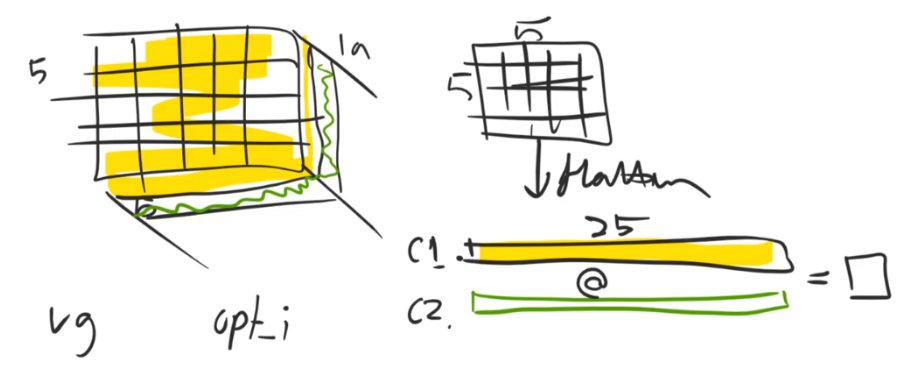
究極的にいえば、どれほどゴッホっぽいのか、廃れさせるのか、、というところなんだと思います。
style-transferがstyleと言われる所以ですね。
1e6に関しては、@の結果、値が大きくなりすぎてしまうことを軽減するために使われているみたいです。
ちなみにinput.numel() == bchwです。
def comb_loss(x):
m_vgg(opt_img_v)
outs = [V(o.features) for o in sfs]
losses = [gram_mse_loss(o, s) for o,s in zip(outs, targ_styles)]
# 砂嵐と廃り同士の比較
cnt_loss = F.mse_loss(outs[3], targ_vs[3])*1000000 # 3の値はテキトウ
style_loss = sum(losses)
return cnt_loss + style_loss # content loss + style loss
前半4行は上のほうで書いた説明と同じです。
▼content loss
MSE_lossとあるように、シンプルに砂嵐と青年魚とのactivationの差異を比較しています。
砂嵐が青年魚に似てきたら、このLoss functionは小さくなります。
▼style loss
content loss同様、gram_mse_lossで砂嵐とゴッホ風とのactivation差異を比較しています。
砂嵐が廃ってきたら、このLoss functionは小さくなります。
重要なのは、pixel同士を比較するのではなく、特定のlayerのfeature(=activation)を比較しているという点です。あくまでも"style"であって、完全なrepresentation、同一のモノではないということです。
(そもそも、青年魚とゴッホ風は二律背反とまではいかなくても、完全に同一なものにそもそもなりえないはずですなので当然といえば当然かもしれないです。どの程度、青年魚っぽくて、どこまで廃っているかのグラデーションでしかない。青年魚の大枠を捉えていれば、十分にヒトが認識できる。デフォルメ的何か。同様にゴッホっぽい特徴を抑えていれば、それはゴッホに近いものとして認識されうるはずです、たぶん、知らんけど。)
このloss比較をPerceptual loss(=Content loss)と言うようです。
optimizer = optim.LBFGS([opt_img_v], lr=0.5)
show_iter = 100
def step(loss_fn):
global n_iter
optimizer.zero_grad()
loss = loss_fn(opt_img_v)
loss.backward()
n_iter+=1
if n_iter%show_iter==0: print(f'Iteration: {n_iter}, loss: {loss.data[0]}')
return loss
学習時の流れを定義しています。
optimizationはLBFGSというDLでは基本的に使われないものを利用しています。
一般的なSGDやAdamと異なり、gradientだけではなく、どれだけ速くgradientが変化するかというderivativeも持っているそうです。
この2nd derivativeを持っているがために、メモリーを多く使ってしまい、DLでは利用されないとのこと。
n_iter=0
max_iter = 1000
while n_iter <= max_iter: optimizer.step(partial(step,comb_loss))
>>>Iteration: 100, loss: 1727.613037109375
>>>Iteration: 200, loss: 1137.231689453125
>>>Iteration: 300, loss: 937.7958984375
>>>Iteration: 400, loss: 831.1635131835938
>>>Iteration: 500, loss: 766.7022705078125
>>>Iteration: 600, loss: 725.4498291015625
>>>Iteration: 700, loss: 695.97021484375
>>>Iteration: 800, loss: 674.0704956054688
>>>Iteration: 900, loss: 656.4786987304688
>>>Iteration: 1000, loss: 642.7332153320312
iteration数を1000回に設定しoptimization
x = val_tfms.denorm(np.rollaxis(to_np(opt_img_v.data),1,4))[0]
plt.figure(figsize=(9,9))
plt.imshow(x, interpolation='lanczos')
plt.axis('off');
画像を表示していきます。
opt_img_vは、PyTorchの形式(b, c, h, w)のままとなっていますが、
pltで表示するためには、np形式に戻す必要があります。
(b, c, h, w) → (b, h, w, c)
そのため1行目にあるcを、wと)の間である4つ目に指定します。
続いて、normalizationされた状態からdenormで解除します。
4. どんな画像が生成されたか
何度かやってみたところ、その時々によって作風、作画にブレがありました。
週刊連載だったらアウトですね。



以下、全体像です。
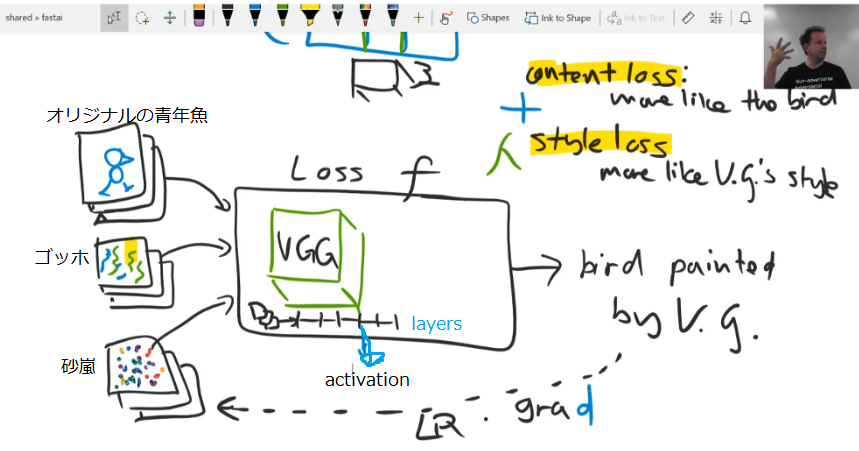
レクチャーの時は、被写体が鳥だったため、bird painted by V.g.と書かれています。
このレクチャー自体はPart2のLecture 13(1:01:28~)で詳しく解説されています。
コード元 style-transfer.ipynb
Hiromi Suenagaさんのスクリプト
5. 反省会など
-
読者レベルを想定せず書いてしまったため、説明の粒度がコード毎であやふや滅茶苦茶で一貫性がなくなってしまった。
そのため、コードの説明も雑であった。自分も困った、みんなこまった。 -
style-transferは3,4日前に学んだばかりで知識不十分なので、どこか誤ってるかもしれないです。
-
AIをさっさとコモディティ化させてuncoolにさせて、次のステージに行きましょう。
それには、practical重視であるfast.aiのdemocratizationがマストな気がしないでもないので、どんどん記事書いてほしいところ。(現状、fast.aiタグのみで見たら、qiita記事は8つのみ)
ちなみに、剛力彩芽とバキでやってみましたが、結果をみて、style-transferの意味をはき違えていることに気が付きました。