Source
Introduction
Main Challenges:
- Sparse rewards - Hard to explore.
- Partially observable environments - Forces the use of memory, reduce generality of information by a single demonstration trajectory.
- Highly variable initial conditions - Generalizing between different initial conditions is difficult.
Hard-Eight Task Suite
- Baseball

- Drawbridge

- Navigate Cubes

- Push Blocks

- Remember Sensor

- Throw Across

- Wall Sensor

- Wall Sensor Stack

Recurrent Replay Distributed DQN from Demonstrations (R2D3)
- Outperforms behavioral cloning and expert demonstrations.
- Uses expert demonstrations to guide agent exploration.
Implementation
The overall system design of R2D3 can be seen in Figure 1. There exists multiple actors, each with a copy of the behavior policy, that stream its experience to a shared and globally prioritized agent replay buffer. The actors update their network weights periodically from the learner (This is akin to R2D2). The learner is a n-step Dueling Double DQN, which also updates the priorities in the replay buffer.
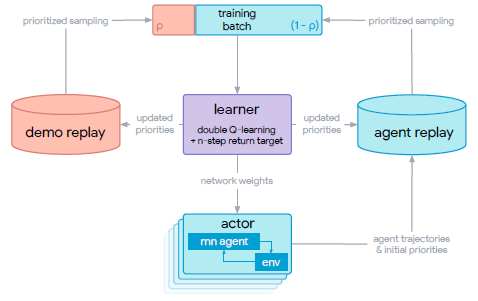
Figure 1. R2D3 architecture.
For each entry in the replay memory, instead of the usual (s, a, r, s'), we store a fixed length (m=80) sequences of (s, a, r), with adjacent sequences overlapping each other by 40 time steps, and never crossing episode boundaries.
The input consists of 4 frame stacks, and instead of reward clipping, the algorithm opts for the adaptation of an invertible value function  (with $h(x)^{-1} = sign(x)((x+sign(x))^2 - 1)$).
(with $h(x)^{-1} = sign(x)((x+sign(x))^2 - 1)$).
This leads to the n-step targets for the Q-value function: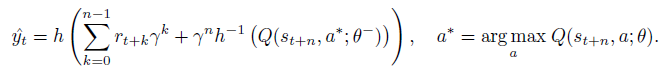
where $\theta^-$ is the target network parameters that are copied from the online network parameters $\theta$ every 2500 learner steps.
The replay prioritization uses the max and mean absolute n-step TD-errors $\delta_i$ over the sequence  with $\eta$ being the priority exponent.
with $\eta$ being the priority exponent.
There is a second demo replay buffer, which contains prioritized records of expert demonstrations. The learner can then sample batch replays from the 2 replay buffers simultaneously.
The hyperparameter $p$ is the demo-ratio, which denotes the proportion of data sampled from each replay buffer. The sampling is done at a batch level, meaning samples in one batch can be from different sources.


Experiment
Input feature
The input feature representation is computed using the architecture shown in Figure 2.

Figure 2. Architecture for input feature representation
The input frame of size 96x72 is fed into a ResNet, and its output is concatenated with previous action $a_{t-1}$, previous reward $r_{t-1}$ and other proprioceptive feature $f_t$, such as accelerations, whether the avatar hand is holding an object, and the hand's relative distance to the avatar.
Baselines
- Behavior Cloning (BC) - Supervised imitation learning on expert trajectories.
- Recurrent Replay Distributed DQN (R2D2) - R2D3 without demonstration. Off-policy SOTA.
- Deep Q-learning from Demonstration (DQfD) - Replace recurrent value function of R2D3 with feed-forward reactive network (Figure 3). LfD SOTA.
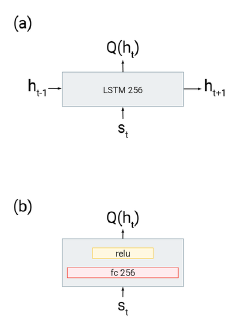
Figure 3. (a) is the recurrent head used by R2D3, whereas (b) is the feedforward head used by DQfD.
Setup
100 expert demonstrations per task.
R2D3, R2D2 and DQfD
- Adam optimizer
- Learning rate 2x10$^{-4}$,
- Distributed training with 256 parallel actors, at least 10 billion actor steps for all tasks.
BC - Adam optimizer
- Learning rate {10$^{-5}$, 10$^{-4}$, 10$^{-3}$}
- Trained for 500k learner steps.
An agent is considered successful if it solves at least 75% of its final 25 episodes. Note that a successful agent may still fail depending on the environment randomization.
Result
From Figure 4, it can be gathered that:
- None of the baseline algorithms succeed in any of the eight environments.
- R2D3 learns six out of the eight tasks, exceeding human performance in four of them.
- All algorithms fail to solve two of the tasks: Remember Sensor and Throw Across, which are the most demanding in terms of memory requirement for the agent.
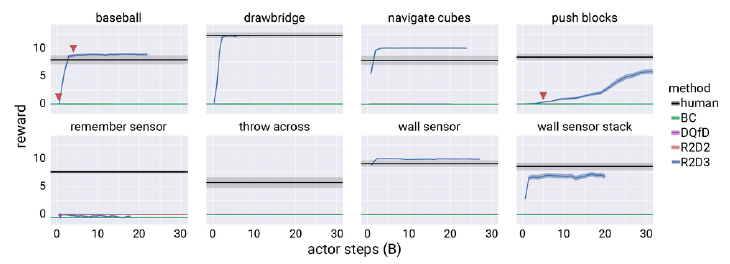
Figure 4. Reward vs actor steps curves for R2D3 and baselines on the Hard-Eight task suite.
From Figure 5, it can be deduced that lower demo ratios outperform the higher demo ratios.
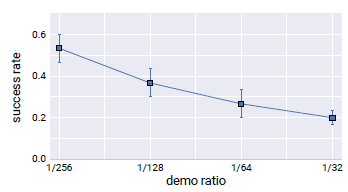
Figure 5. R2D3 success rate vs demo ratio
At 5 billion steps (well before R2D3 solves the task), it can be seen that R2D3 is sufficiently guided by expert demonstrations to perform actions which lead to successful outcome (Figure 6).
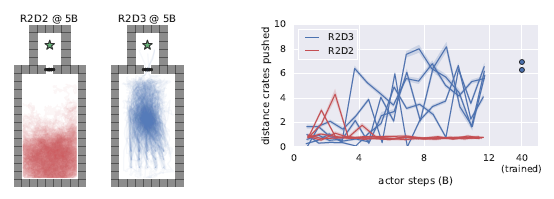
Figure 6. Guided exploration behavior in the Push Blocks task.
R2D3 significantly outpaces R2D2 at tackling the Baseball task (Figure 7), eventually beating human average.
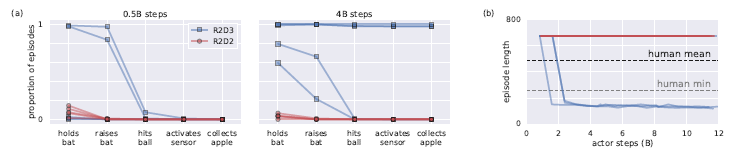
Figure 7. Guided exploration behavior in the Baseball task.


R2D3 was able to exploit a bug in the Wall Sensor Stack task. This exploitation was not present in any of the demonstrations, although the authors fail to mention whether other baselines were able to find and exploit this bug.

Conclusion
Combining agent self-exploration with expert demonstration achieves good result in partially observable environments with sparse rewards and highly variable initial conditions, despite the ratio of learning from demonstrations is generally minute.