はじめに☃️
今回は手動で画像を集めるという行為に飽きてきたので、自動で特定のサイトの画像集めをしてくれるプログラムをNode.jsで作っていこうと思います。
特に思い入れも何もないですが、Pinterestというサイトから画像を持ってきます。
ちなみに完成品のリポジトリはこちらです。🔧
SugarShootingStar/scraping-pinterest-images: Need your Pinterest account.
こういうのを作る👊
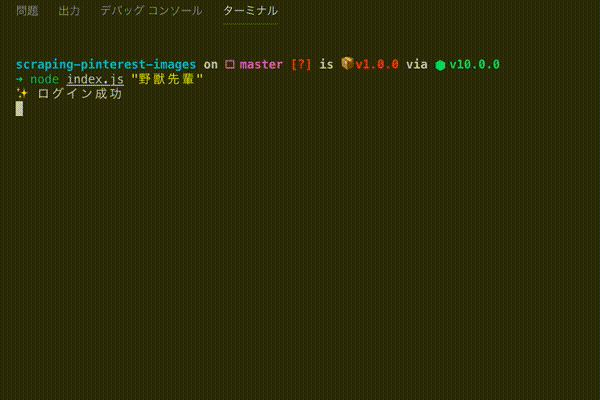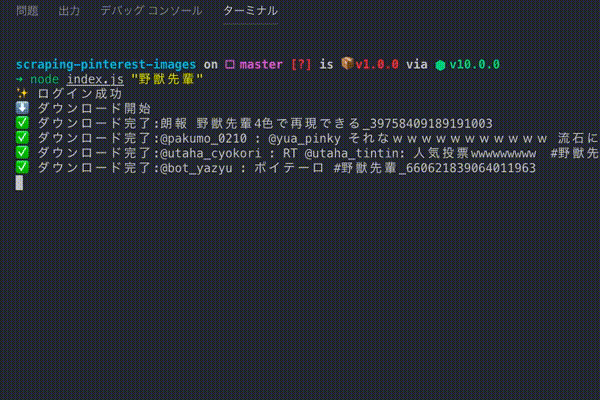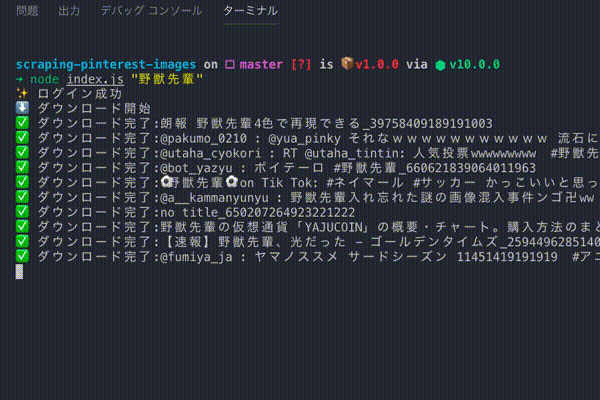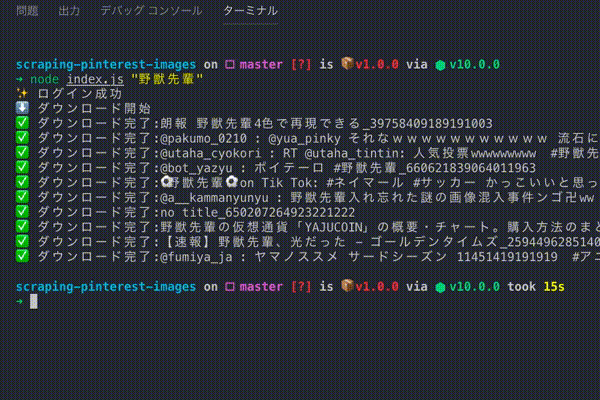
本当はヘッドレスブラウザのログイン処理があるのでもっと遅いです
初期構想時💪
最初はPinterest APIを使えばいいと思ったのですが、検索結果に基づく画像を取得できないことがわかりました😇
なので、実際にアクセスして画像を取得しダウンロードしていきたいと思います🐥
サイトDOM構造を確認する🔍
- 画像情報がまとめられているJSONがあればそれを取得
- なければ、
document.querySelectorAllなどでimgタグが存在する場所をセレクタ指定し抽出
今秋は前者のJSONを取得する方法でいけました。しかし、未ログインの状態だと該当のJSONには中身が入っていないようです…😨
実際にChromeのデベロッパーツールを使いログインして見てみたら中身が入っていることが確認できました👻
なので、コード上で取得する場合はなんとかしてログインする必要があります🤔
検索キーワードを引数から取得し、URLを動的に作成📜
- 引数を文字列で取得
- minimistを使う
node index.js "野獣先輩"
// 野獣先輩
const searchKeyword = require('minimist')(process.argv)._[2];
- 検索キーワードからクエリを生成
- URLSearchParamsを使う(querystringでもいい)
// q=%E9%87%8E%E7%8D%A3%E5%85%88%E8%BC%A9
new URLSearchParams([
['q', searchKeyWord]
]).toString();
これでクエリ文字列を生成し、URLにくっつければ検索用URLが完成する。⚡️
const query = new URLSearchParams([['q', searchKeyword]]).toString();
const URL = 'https://www.pinterest.jp/search/pins/?' + query;
puppeteerを使ってログインしてみる🚪
とりあえずブラウザを操作してログイン後のJSONを持ってきたいので、ヘッドレスブラウザを使います。
今回使うライブラリはpuppeteerといい、Googleがサポートしているヘッドレス状態でChromeを操れるすごいやつです。(画面から見えない状態でブラウザを操作するやつ)
GoogleChrome/puppeteer: Headless Chrome Node API
puppeteerの処理ではasync,awaitを使い非同期処理を記述していきます。
async,awaitについてはこちらが参考になります。
ちなみに、立ち上げるときはこんな感じで書きます
// Headless Chromeの起動
const browser = await puppeteer.launch();
// 新しいタブでページを開き変数に入れる
const page = await browser.newPage();
// 指定したURL先へ遷移する
await page.goto(URL);
あと、忘れがちですが処理が終了したときは
browser.close();
させてあげないとブラウザが閉じてくれないので注意しましょう。意外と忘れがちです。
ログインモーダルを開く🙉
とりあえずクリックイベントだけ起こせば大丈夫なので、いい感じにクリックさせます。
page.click(セレクタ指定)でクリックさせることができるみたいです、
簡単!!
await page.click('.lightGrey');
メルアドとパスワードを入力させる🖐
後述しますが、危ない情報なので環境変数から持ってきます。
テキストボックスに入力させるのは、page.type(セレクタ指定)でできます。
await page.type('#email', process.env.email);
await page.type('#password', process.env.password);
メルアドとパスワードをgit管理外にする🔒
ログインできるとはいえ、マジモンのアカウントのメルアドとパスがバレたら生きていけないのでそこら辺は環境変数に退避させます☝️
dotenvを使います。
とりあえずyarn add dotenvしてプロジェクトのルートフォルダに.envファイルを作成します。
そして上のほうに呪文を記述し
require('dotenv').config();
.envファイルに環境変数を記述することで
mail = xxxx@gmail.com
password = passwordtest
Node.jsにおける環境変数process.env内に危ない変数が用意されアクセスすることが可能となります。
今回の例でいくと、それぞれprocess.env.mail、process.env.passwordと指定することでアクセスできます。
また、dotenvを使う時には必ず.gitignoreに.envと書かれているか確認しておきましょう。
これだけやっておいてgitにメルアドとパスワードが公開されたら意味がないので…😇
ログインボタンをクリックさせる👆
こちらもモーダルを開いたときと同じでクリックさせてあげればちゃんと動きます。
ログインボタンがdivで囲まれていて名前も何もなかったのでセレクタが大変なことになっています😨
const loginSelector = 'body > div:nth-child(1) > div > div > div > div > div:nth-child(6) > div > div > div > div > div:nth-child(1) > div:nth-child(4) > div:nth-child(1) > form > div:nth-child(3) > button > div';
await page.click(loginSelector);
JSONを取得する✌️
今回はページ内の<script><タグにIDが入っていたので、そちらを指定して取得してみます。
ただ、ID指定だとIDの名前が変わった瞬間に動かなくなってしまうので、できれば正規表現で取得したほうがいいです
JSONを抜くのはやったことがなかったですが、普通にquerySelectorしてinnerHTMLで中の値を取得後にJSON.parseすれば大丈夫でした。
また、説明が送れましたがpuppeteerにおけるDOM取得にはpage.evaluateのコールバック関数を使います。
要素の取得方法に関しては他にも色々メソッドが用意されているみたいです👀
こちらの記事が参考になります。
const imagesJson = await page.evaluate(() => {
const json = document.querySelector('#initial-state').innerHTML;
return JSON.parse(json);
});
取得したJSONから必要な画像のみ抽出する📦
ここは正直元のJSONに依存するので、深く解説はしません。
とりあえず、必要なのは画像パスとユニークな名前くらいなので、他の情報は捨てていい感じに抽出します。
取得したJSONで画像が入ってるところを回していきます。
とりあえず配列を作って必要な情報をまとめたObjectをpushしていけば大丈夫だと思います。
ObjectをforEachで回したいときにこんな書き方になっちゃうのちょっとしんどみを感じます🐙
function extractionImagesInfo(json) {
var imagesInfo = [];
Object.keys(json.pins).forEach((key) => {
const imageObj = json.pins[key];
imagesInfo.push({
id: imageObj.id,
description: imageObj.description ? imageObj.description.split('/').join('_') : '',
image_url: imageObj.images.orig.url,
source_url: imageObj.link
});
});
return imagesInfo;
}
画像をダウンロードしていく⬇️
実際に画像を持ってこないとプログラムを書く意味がないので、画像を持ってきます。🐣
画像を取得してくるのにはaxiosというHTTP Clientを使います!!
axios/axios: Promise based HTTP client for the browser and node.js
検索ワードに応じたディレクトリを作っちゃう📁
- プロジェクトのルートフォルダに
imgフォルダがなければ作成、あれば何もしない -
imgフォルダ配下に検索ワードのフォルダを作成、あれば何もしない
以上の条件を満たすコードを書きます。
fsというNode標準で入っているモジュールがあるので、それを使ってファイル、ディレクトリ操作をしていきます。
詳しいことは公式に色々書いてあります。
File System | Node.js v11.2.0 Documentation
- process.env.PWD
- プロジェクトフォルダまでのパス
- fs.existsSync(文字列)
- 同名のフォルダが存在するかの判定
- fs.mkdirSync(文字列)
- フォルダの作成
const imgDir = process.env.PWD + '/img';
const dirSearchKeyword = imgDir + '/' + searchKeyword;
// imgフォルダの作成
if (!fs.existsSync(imgDir)) fs.mkdirSync(imgDir);
// 検索キーワードのフォルダ作成
if (!fs.existsSync(dirSearchKeyword)) fs.mkdirSync(dirSearchKeyword);
ダウンロード処理🔥
さっき抽出したいい感じの配列があるので、それを使って回していきます。
また、ダウンロード中コンソールに何も出ないのは寂しいのでいい感じに出力します。
画像ダウンロード処理は以下の方法で実現可能です。
fs.writeFileで非同期に処理をすることもできるらしいですが、正直速度的に全然変わんないので今回は使用しません。
-
axios.get(画像パス, { responseType: 'arraybuffer' })で画像パスに対してアクセス- これを指定することで画像データをバイナリとして取得することが可能となります。おまじないだと思ったほうがいいでしょう。
-
fs.writeFileSync(画像保存パス, new Buffer.from(axiosで取得した画像データ), 'binary')で保存- バイナリで取得してきているので、第2引数にnew Buffer.from、第3引数にバイナリを指定してあげます。 こうすると画像で保存ができるみたいです。
- 画像データをバイナリ文字列にエンコードしてあげて、保存する際にデコードし画像に復元するという流れで動いているんでしょうか…正直ここらへん自信ないです🌚
console.log('⬇️ | ダウンロード開始');
Object.keys(images).forEach(async (key) => {
const res = await axios.get(images[key].image_url, {
responseType: 'arraybuffer'
}).catch((e) => {
console.log('😇 何らかの原因で画像が取得できませんでした。');
console.log('⚠️ エラー内容' + e);
return;
});
const filename = images[key].description + '_' + images[key].id;
const ext = '.jpg';
fs.writeFileSync(dirSearchKeyword + '/' + filename + ext, new Buffer.from(res.data), 'binary');
console.log('✅ ダウンロード完了:' + filename);
});
}
できたや〜ん🐱
課題点
- 1回しかjsonを指定しないせいで画像の取得枚数に限りがあるので何とかしたい(本家Pinterestだとスクロールしたら無限に画像が出る)
- ログイン後、jsonが更新されるまで手動でsleepしている闇のコードがあるのでなくしたい
- 関係ないけどFlickrからも取得したい
まとめ
- puppeteer便利
- これで色々悪巧みできる
- 画像をダウンロードする際は個人的な用途にのみ使用しましょう