C言語における、
- OpenMPを用いて並列計算を行う方法
- 並列計算時の処理時間を計測する方法
についてまとめます。
0. OpenMPとは
OpenMP(Open Multi-Processing)とは、共有メモリ型マシンで並列プログラミングを可能にするAPIです。FORTRAN、C/C++から利用できます。
ディレクティブを挿入するだけで並列化してくれるので、数ある並列化手法の中でも敷居は低い方といえます。
1. 計算する式
並列処理によって、以下の計算を高速化させることを考えます。
total=\sum_{i=0}^{L-1}\sum_{j=0}^{L-1} (i-j) \\
因みに上記の計算、Lが如何なる値であってもtotalの値は0になるので、正しく計算されているかどうかの確認が容易です。そのため、数値計算速度のベンチマークテストを行う上で有効だと(個人的には)思っています。
2. コード
# include <stdio.h>
# include <stdlib.h> /* for atoi */
# include <omp.h> /* for parallel processing */
# include <time.h> /* for clock_gettime */
int main(int argc, char const * argv[]){
int i, j, L, total, n;
struct timespec startTime, endTime;
if (argc == 1 || argc >= 3){ /* 引数なし or 引数2つ以上 */
printf("引数に整数を1ついれてください。\n");
return 1;
}
else{
L = atoi(*++argv);
/* スレッド数を取得 */
n = omp_get_max_threads();
printf("max threads (set): %d\n", n);
total = 0;
/* 時間計測 開始 */
clock_gettime(CLOCK_REALTIME, &startTime);
/* 計算 */
#pragma omp parallel for private(j) reduction(+:total) num_threads(n)
for (i = 0; i < L; i++){
for (j = 0; j < L; j++){
total += i - j;
}
}
/* 時間計測 終了 */
clock_gettime(CLOCK_REALTIME, &endTime);
/* 計算にかかった時間を表示 */
printf("elapsed time = ");
if (endTime.tv_nsec < startTime.tv_nsec) {
printf("%5ld.%09ld", endTime.tv_sec - startTime.tv_sec - 1,
endTime.tv_nsec + (long int)1.0e+9 - startTime.tv_nsec);
} else {
printf("%5ld.%09ld", endTime.tv_sec - startTime.tv_sec,
endTime.tv_nsec - startTime.tv_nsec);
}
printf("(sec)\n");
printf("result : %d\n", total);
return 0;
}
}
コンパイル・実行は、
$ gcc -fopenmp -O3 parallel.c -o para.out
$ ./para.out 2000 # Lの値を指定してやる。
実行結果の例:
max threads (set): 4
elapsed time = 0.070201000(sec)
result : 0
3. 解説(並列処理)
並列処理は、iに関するfor loopにおいて行っています。
#pragma omp parallel for private(j) reduction(+:total) num_threads(n)
for (i = 0; i < L; i++){
for (j = 0; j < L; j++){
total += i - j;
}
}
3.1. pragma omp parallel for
for loopの並列化を行います。
3.2. private(j)
変数jがスレッド毎に用意されることを示します。
3.3. reduction(+:total)
これは**「reduction指示節」**というものであり、以下のような用いられ方をします。
reduction({演算子}:val)
これが指定された場合、valで示される変数のprivateコピーがスレッド毎に作成され、初期化されます。
また、ブロックの最後では、それぞれのスレッドの
- privateコピー
- 共有された変数
が、演算子が示す方法により集計されて、共有された変数に格納されます。
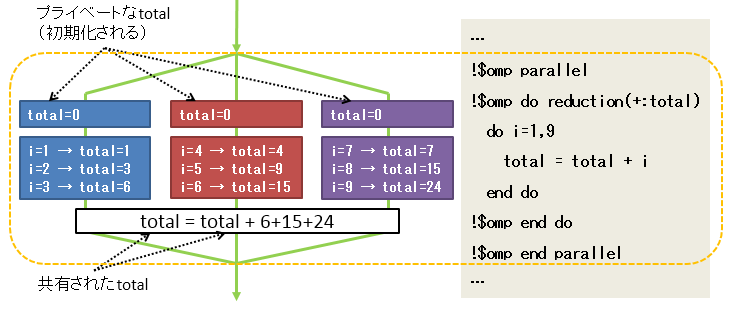
(画像:OpenMP入門: reduction指示節より)
このreduction節がないと正しい結果は得られません。なぜなら、並列領域のtotalが更新される処理
total += i - j;
において、totalが競合する可能性があるからです。
3.4. num_threads(n)
並列処理に用いるスレッド数を指定します。
4. 解説(時間計測)
C言語で時間を計測する関数といえばtime()やclock()などですが、time()はミリ秒単位の細かい時間計測を行うことが出来ないし、clock()は実時間ではなくCPU時間を計測しているので、並列計算時には「全スレッドのCPU時間の総和」が返ってきてしまいます。
そこで、clock_gettime()関数を用います。
# include <time.h>
struct timespec {
time_t tv_sec; /* Seconds. */
long tv_nsec; /* Nanoseconds. */
};
int clock_gettime(clockid_t clk_id, struct timespec *tp);
clk_idでクロックの時間情報のタイプを指定。
*tpに、秒数とナノ秒数の情報が格納されます。
(詳細は、時間情報の取得 clock_gettime() - 時間の扱い - 碧色工房)