概要
タイトルの通りですが、勾配降下法を用いた深層学習による自然言語処理の流れをまとめました。
自分がPytorch×BERTを用いてモデル構築をしているので、各フェイズの説明ではそれらを例に出して説明します。
流れ
大まかに以下のような流れになります。
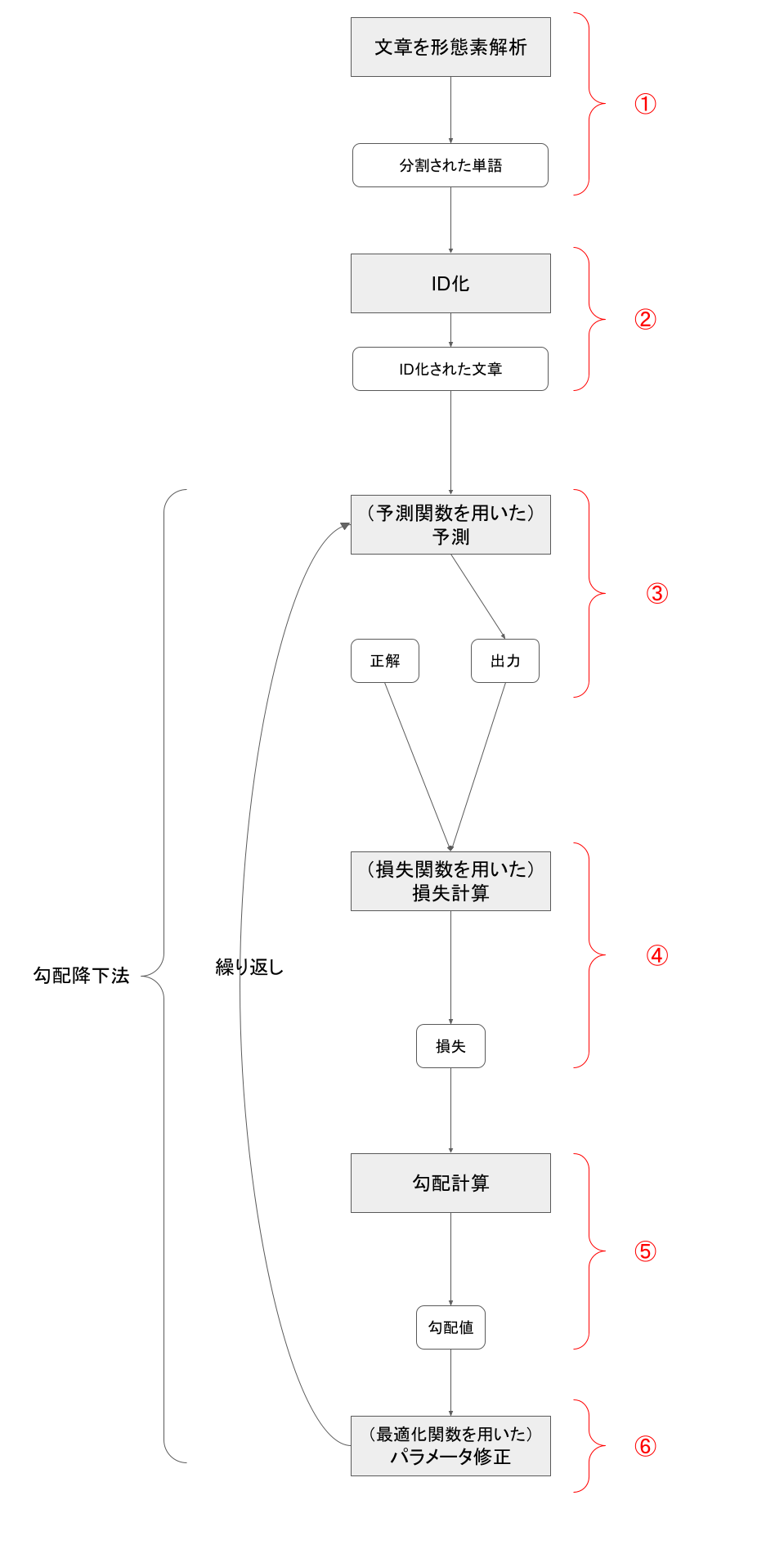
①形態素解析
まず文章を形態素解析します。
形態素解析とは、文章を形態素(=意味を持つ最小単位)に分け、それらが品詞としてどれに当たるのか分類することです。日本語は英語など他の原語と比べると、単語間に空白がないため、単語の切り出しが難しく、形態素解析用のライブラリが必要になります。
有名なライブラリだとMecabがあります。
$ mecab
こんにちは今日はいい天気ですね。
こんにちは 感動詞,*,*,*,*,*,こんにちは,コンニチハ,コンニチワ
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ
天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
。 記号,句点,*,*,*,*,。,。,。
②ID化
次に文章をID化します。
①で形態素解析された文章(単語群)は入力する際、数値に置き換える(ID化する)必要があります。形態素解析されて切り出された単語をそれぞれ数値化することをID化と呼んでいます。
BERTを使うと①と②はencode()を使うだけでいっきにやってくれます。
tokenizer.encode("こんにちは今日はいい天気ですね。")
[2, 10350, 25746, 28450, 3246, 9, 2575, 11385, 2992, 1852, 8, 3]
③予測
次に予測を行います。
入力値と、重み、バイアスを用いて予測値を計算し出力します。いわゆるニューラルネットワークの部分になります。
Pytorchでは関数が用意されているのでそれを利用して予測部分を構築します。予測関数は例えばnn.Sequential()などが用意されています。
BERTなどの自然言語処理のライブラリを用いる場合、この部分は各ライブラリの機能を利用します。
④損失計算
次に損失計算です。
③で出力された値と、その正解ラベルを用いて、予測値がどの程度正解とずれていたか?を計算し、損失を出力します。損失は予測関数と損失関数の合成関数であり、損失計算とはこの合成関数を計算することになります。
Pytorchではこの計算に関数が用意されていて、nn.MSELoss()やnn.CrossEntropyLoss()がそれに当たります。文書分類を行いたい場合はnn.CrossEntropyLoss()(=つまり交差エントロピー)を使います。
⑤勾配計算
次に勾配計算です。
この勾配計算で算出された勾配値によって、損失を減らす方向を決めることができます。
勾配値は損失をパラメータ(weightやbias)で偏微分した値になります。
Pytorchではbackward()が用意されており、簡単に勾配値を計算することができます。
⑥最適化関数によるパラメータ修正
最後にパラメータの修正を行います。
⑤で出力された勾配値に学習率をかけ、その値だけweightとbiasを減らします。
Pytorchではoptimizer.step()が用意されており、これによってパラメータ修正を行います。
繰り返し処理
上記の③〜⑥を繰り返すことで学習が行われます。
このように損失から勾配値を計算してパラメータ修正を繰り返す方法を勾配降下法といいます。