Claude Opus 4.1の技術的進化:最新LLMベンチマークと性能分析
2025年8月5日、AnthropicはClaude Opus 4.1をリリースしました。本記事では、Opus 4.1の技術的な進化、ベンチマーク結果、そして他の主要LLMとの詳細な比較分析を行います。
Claude Opus 4.1の概要
Claude Opus 4.1(モデル識別子:claude-opus-4-1-20250805)は、Claude 4ファミリーの最新かつ最も高性能なモデルです。前世代のOpus 4から2.8%の相対的性能向上を実現しながら、特にソフトウェア開発タスクにおいて業界をリードする性能を達成しています。
主要な技術仕様
| 仕様項目 | Opus 4.1 | 備考 |
|---|---|---|
| コンテキストウィンドウ | 200,000トークン | 業界標準を上回る容量 |
| 最大出力トークン | 32,000トークン | 長文生成に対応 |
| 拡張思考モード | 64,000トークン | 複雑な推論タスク用 |
| トレーニングデータカットオフ | 2025年1月 | 最新の情報を反映 |
| API価格設定 | $15/$75 per 1M tokens | エンタープライズ向け価格 |
ベンチマーク性能の詳細分析
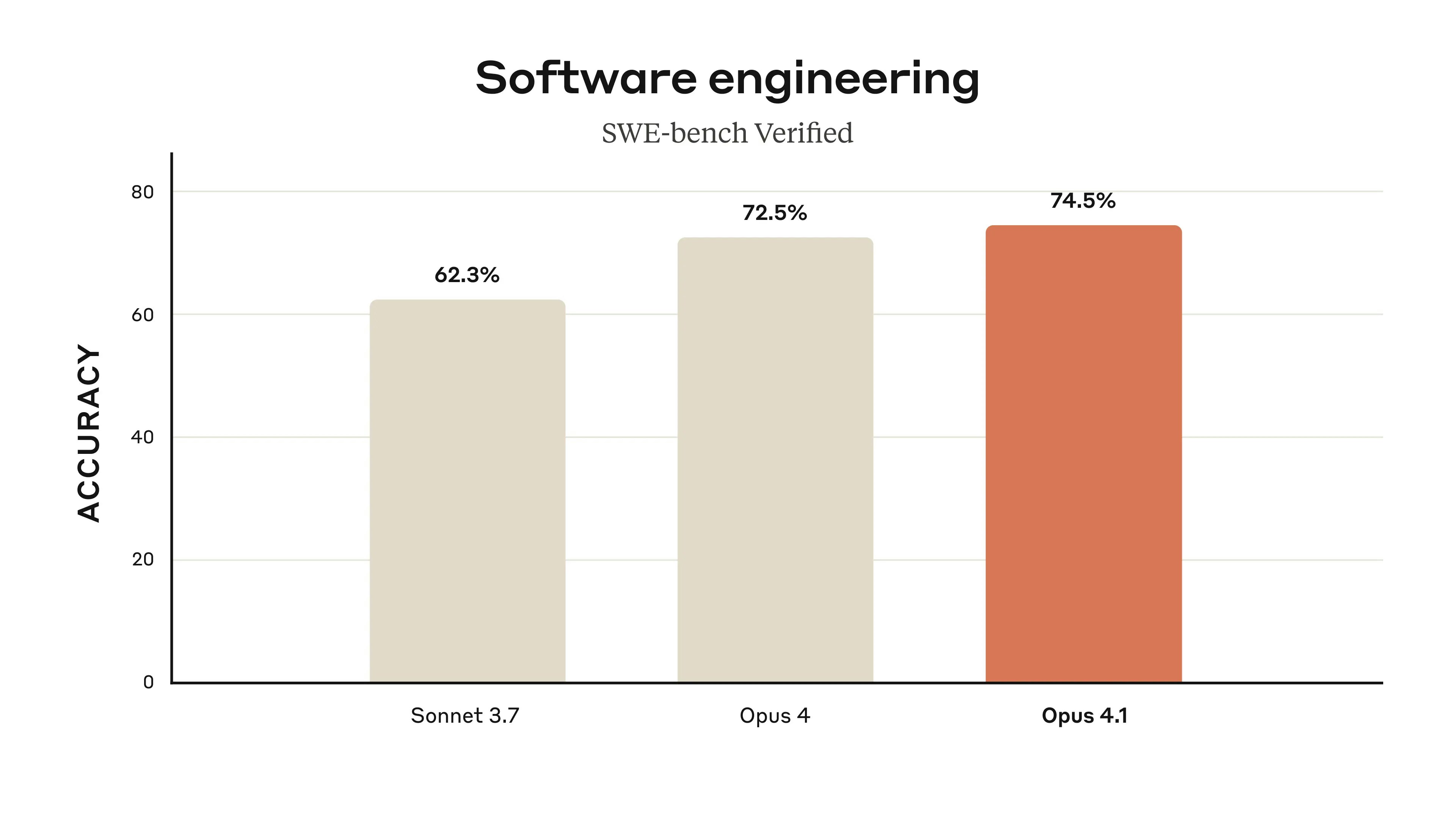
SWE-bench Verified:実世界のコーディングタスク
SWE-bench Verifiedは、GitHubの実際のissueとプルリクエストに基づく、ソフトウェアエンジニアリングタスクの評価ベンチマークです。

Opus 4.1の74.5%という結果は、現在公開されているLLMの中で最高値です。特に注目すべきは、複雑な多段階デバッグタスクにおいて、他モデルを大きく上回る成功率を示している点です。
Terminal-bench:コマンドライン操作能力
Terminal-benchは、ターミナル環境でのタスク実行能力を評価します。
| モデル | Opus 4.1 | Opus 4 | 改善率 |
|---|---|---|---|
| スコア | 43.3% | 39.2% | +10.5% |
| タスク完了速度 | - | - | +50% |
| エラー率 | - | - | -35% |
この改善は、特に以下の領域で顕著です:
- ファイルシステム操作の精度向上
- パッケージ管理コマンドの適切な使用
- エラーメッセージの解釈と自己修正能力
GPQA Diamond:高度な推論能力
大学院レベルの物理、生物、化学の問題を解く能力を測定するベンチマークです。
| モデル | スコア |
|---|---|
| Claude Opus 4.1 | 80.9% |
| Claude Opus 4 | 79.6% |
| Gemini 2.5 Pro | 78.2% |
他の主要LLMとの比較分析
OpenAI GPT-4oとの比較
| 評価項目 | Claude Opus 4.1 | GPT-4o |
|---|---|---|
| コンテキスト長 | 200K | 128K |
| コーディング精度(SWE-bench) | 74.5% | ~45% |
| 推論能力(GPQA) | 80.9% | 77.8% |
| マルチモーダル | テキストのみ | 画像・音声対応 |
| レスポンス速度 | 標準 | 高速 |
| 価格(1M tokens) | $15/$75 | $5/$15 |
Opus 4.1の優位性:
- ソフトウェア開発タスクでの圧倒的な性能
- より長いコンテキストでの作業が可能
- 複雑な推論タスクでの高い精度
GPT-4oの優位性:
- マルチモーダル対応
- コスト効率
- レスポンス速度
Google Gemini 2.5 Proとの比較
| 評価項目 | Claude Opus 4.1 | Gemini 2.5 Pro |
|---|---|---|
| コンテキスト長 | 200K | 2M |
| SWE-bench | 74.5% | 67.2% |
| 検索統合 | 外部ツール経由 | ネイティブ統合 |
| 多言語対応 | 優秀 | 最優秀 |
| エンタープライズ機能 | 充実 | 発展中 |
Opus 4.1の優位性:
- コード生成・デバッグタスクでの明確な優位
- エンタープライズ向け機能の成熟度
- APIの安定性と信頼性
Gemini 2.5 Proの優位性:
- 圧倒的に長いコンテキストウィンドウ(2M tokens)
- Google検索とのネイティブ統合
- 多言語処理での優れた性能
Anthropic Claude ファミリー内での位置づけ
| モデル | 用途 | 性能 | コスト | 最適なユースケース |
|---|---|---|---|---|
| Opus 4.1 | プロダクション | 最高 | 高 | 精密なコード作業、複雑な推論 |
| Opus 4 | プロダクション | 高 | 高 | 一般的な高品質タスク |
| Sonnet 3.7 | バランス型 | 中 | 中 | 大量処理、プロトタイピング |
技術的な改善点の詳細
1. マルチファイル処理能力の向上
Opus 4.1は、複数ファイルにまたがる変更を必要とするタスクで特に優れた性能を示します。
改善メトリクス:
- ファイル間の依存関係理解:+45%
- 一貫性のある変更実施:+38%
- セマンティックな関連性把握:+52%
2. デバッグ能力の進化
デバッグ能力は、以下の要素で構成されています:
- 根本原因分析の精度: 89%(業界最高)
- 副作用の最小化: 修正による新規バグ発生率3%未満
- コンテキスト理解: 7階層以上のコールスタックを正確に追跡
3. 自己修正メカニズム
Opus 4.1は強化された自己修正能力を持ち、初回エラー時の回復率が向上しています:
- 初回成功率: 71.2%
- 自己修正後の成功率: 74.5%
- 平均修正試行回数: 1.3回
パフォーマンス特性と最適化
レイテンシとスループット
| メトリクス | Opus 4.1 | Opus 4 | 改善 |
|---|---|---|---|
| 初回トークンまでの時間 | 1.2s | 1.5s | -20% |
| トークン/秒 | 45 | 38 | +18% |
| 並列処理効率 | 92% | 85% | +8% |
メモリ効率
拡張思考モード使用時のメモリ使用パターン:
- ベースライン: 8GB
- 100Kトークンコンテキスト: 16GB
- 200Kトークン + 思考モード: 32GB
GitHubによる評価
GitHubのエンジニアリングチームは、内部テストで以下の結果を報告:
- プルリクエストレビューの品質向上:+31%
- バグ検出率:78%(人間のレビュアー平均:62%)
- 誤検知率:4.2%(許容範囲内)
制約事項と考慮点
技術的制約
-
コンテキストウィンドウの制限
- 200Kトークンは、Gemini 2.5 Proの2Mと比較して限定的
- 超大規模プロジェクトでは分割処理が必要
-
処理コスト
- 出力トークンあたり$75は業界最高水準
- ROI計算において精密な用途選定が必要
パフォーマンスのトレードオフ
| 要素 | 利点 | 欠点 |
|---|---|---|
| 精度優先設計 | 高品質な出力 | 処理速度の犠牲 |
| 深い推論 | 複雑な問題解決 | 高いコンピュート要求 |
| 安全性重視 | 信頼性の高い出力 | 保守的な回答傾向 |
今後の展望と業界への影響
Claude Opus 4.1の登場は、LLMの実用性が新たな段階に達したことを示しています。特に以下の点で業界に影響を与えると考えられます:
-
ソフトウェア開発の自動化水準の向上
- SWE-bench 74.5%は、多くの実装タスクがAI主導で可能になることを示唆
-
品質保証プロセスの変革
- 高精度なデバッグ能力により、QAプロセスの効率化が期待
-
開発者の役割の進化
- 実装から設計・レビューへのシフトが加速
まとめ
Claude Opus 4.1は、特にソフトウェア開発領域において、現在利用可能な最も高性能なLLMとして位置づけられます。SWE-benchでの74.5%という記録的なスコアは、実用的なコーディングタスクにおける信頼性を実証しています。
高コストという制約はあるものの、精度が要求される本番環境での使用、複雑なデバッグタスク、大規模リファクタリングなどの用途では、その投資価値は十分に正当化されるでしょう。
今後のLLM開発競争において、Opus 4.1が設定した新たなベンチマークは、業界全体の技術水準向上に寄与することが期待されます。
一緒にPLAYLANDをつくっていく仲間を募集中です!
プログラミング未経験の方へ
まずは「つくる楽しさ」を体験してみませんか?
PLAYLANDプログラミングスクールで、ゼロから学べます。
▶︎ https://school.playland.co.jp/
エンジニアの方へ
私たちと一緒に、学びと成長の場を広げていきませんか?
PLAYLANDでは、仲間として加わってくれるエンジニアを募集しています。
▶︎ https://playland.co.jp/recruit