Databricks社は、Apache Sparkを開発したUCバークレーの研究組織AMPLabから2013年にスピンアウトして起業した会社です。
単にOSSとしてのApache Sparkを開発している会社ではなくなっています。AWSや、Azure上で、Sparkの実行基盤を幅広く提供しており、『Databricks統合データ分析基盤』を提供をしています。
Apache Sparkのクラウドサービスであれば、既にAmazon EMRや、Azure HDinsightでも稼働済みであるので、特に注目をすることはないのですが、『統合データ分析基盤』となっていることに気が付くことが重要です。
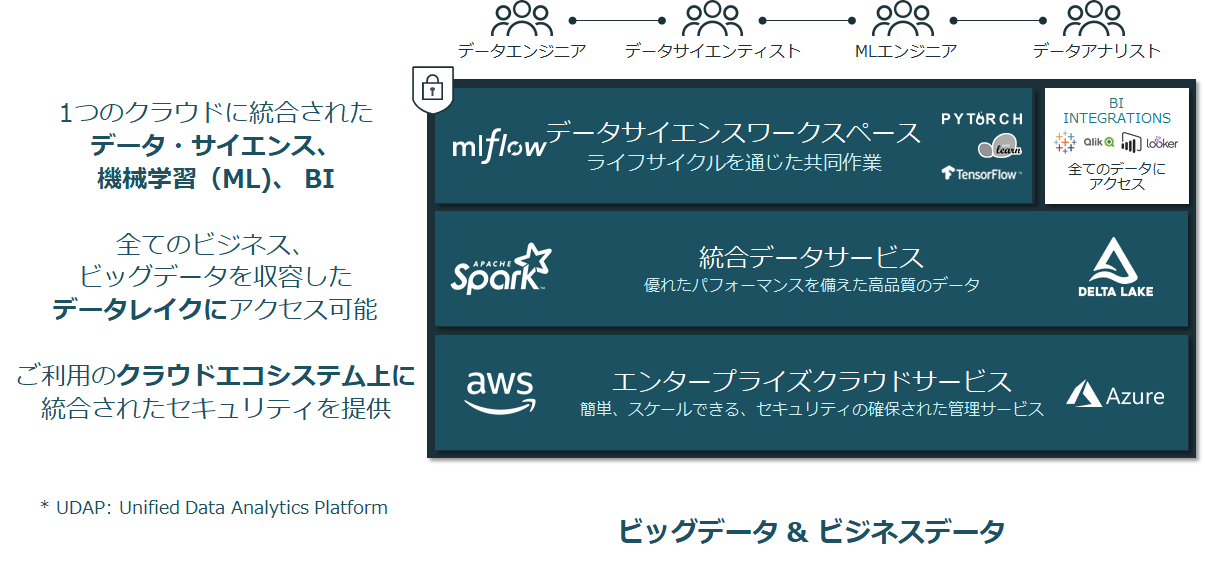
つまり、Sparkだけでなく、『Delta Lake』というSpark専用のストレージ処理によるリアルタイム処理とバッチ処理の融合と『ML Flow』という機械学習のワークフロー、そして『Databricks Notebook』という統合開発環境に、Re:dashというBIダッシュボード製品も含めた、まさに全部入りの『統合データ分析プラットフォーム』になっています。
Databricksがデータ分析基盤構築としてお勧めなポイントを簡単にご紹介します。
DeltaLake
Appleと協同開発をした分散処理用のファイル形式『Parquet』ベースに対応したストレージレイヤーソフトです。
SparkAPIに対応しており、注目は、ストリーミング処理のデータと、バッチ処理のデータを実現するデータパイプラインを構築できることです。今までも、バッチ処理はSparkで、リアルタイム処理はKafka/Kinesysでという処理を実施してアーキテクチャーを実現してきましたが、異なるアーキテクチャーからのデータなので、データの処理設計には注意が必要です。そこをDelataLakeにて統一して処理が可能になっていることが、非常に便利です。
また、データの履歴管理をどうするかですが、データ分析基盤では、S3に単に保存すれば良いと言えるほど単純ではありません。S3バケットをどうするかから始まり、Rawデータのネーミングルール、S3ディレクトリー構成、バックアップ、リカバリー方式等のパイプラインを決定をしておかなければいけないからです。
データは、そのまま使えないので、Rawデータから何度か処理をしてデータマート作成を実施することになるのですが、もう一度処理をしたいと思った場合に、Rawデータからデータマート作成をするのか、データマートを作成してからバックアップを取るのか等、検討しておかなければなりません。
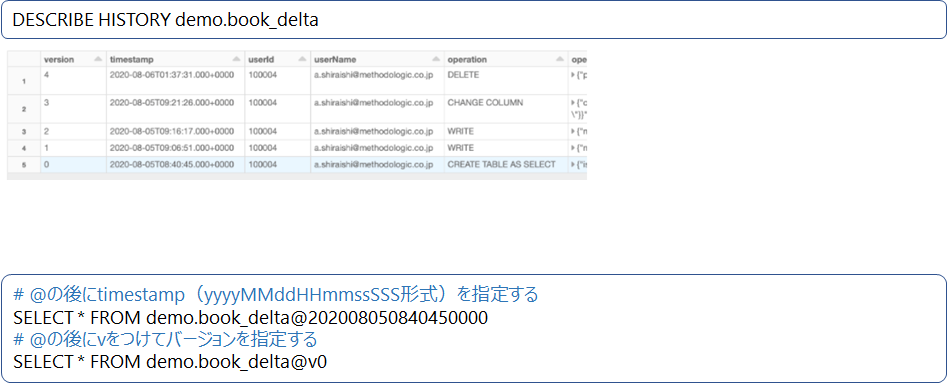
Delta Lakeは、タイムトラベル機能を持っており、分析、レポート、機械学習モデルを任意の過去履歴(スナップショット)から作成したり、オペレーションミスを修正したり、誰が何をしたのか履歴から確認することが可能になっています。
デフォルトでは、履歴を30日間保持します。
履歴からクエリーをする実行例
Databricks Notebook
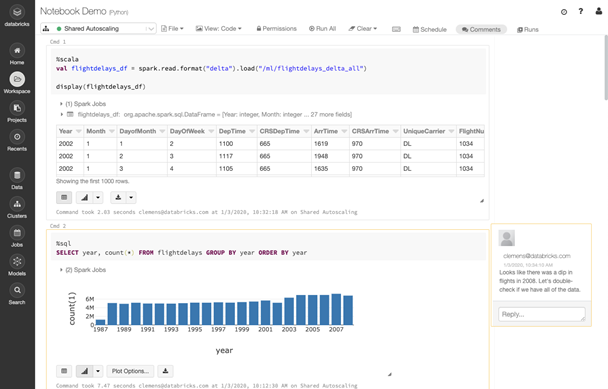
Databricksの中に、JupyterNotebookのようなソフトがあります。SQL、Python、Scala、R言語が1つのNotebookから記述できます。データのトラッキング機能により、コード、パラメータを可視化して管理可能。改定履歴や自動ロギング、Gitバージョン管理等の可視化に必要な機能が搭載されています。EMRにもNotebookというのもありますが、それよりも統合管理されているメリットがあります。
Pyspark、SparkR、Sparklyr、Pandas/Koalas等にて、大量データを並列分散環境で操作可能です。またBokeh、Matplotlib、Plotly、Rplotfunctionなどのサードパーティライブラリーにも対応しています。更に機械学習のライブラリであるTesorFlow、Pytoch、Horovod、scikit-learn、XGBoost等もサポートしており分析者も利用しやすくなっています。
Databricksの、一番のわかりやすい特徴は、この『Databricks Notebook』だと思います。
ML Flow
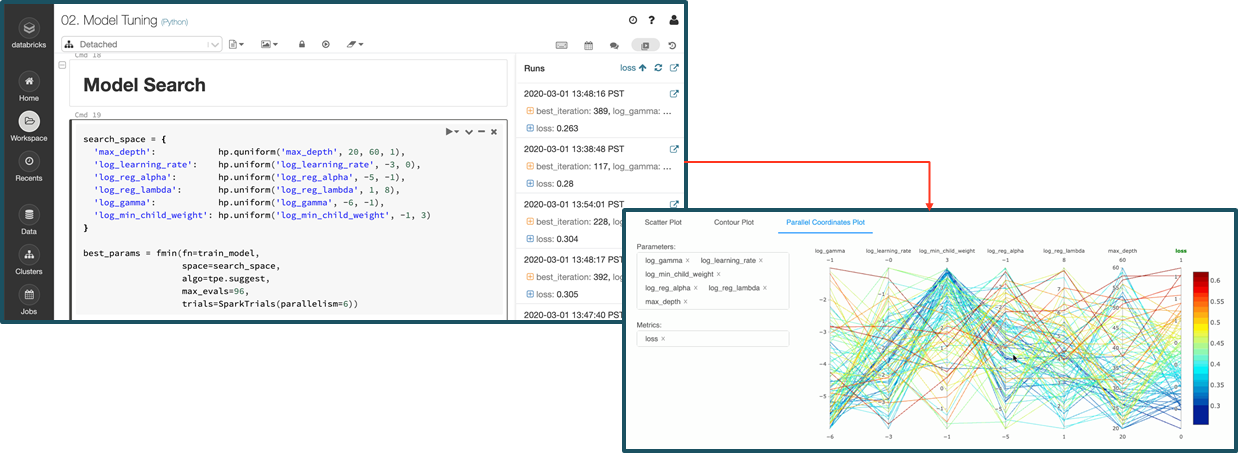
機械学習、AIのプロジェクトを実施するにあたり、1人で実施しているうちは良いのですが、チームで協同作業を実施しようとすると困ることが出てきます。
どのデータに対して、どのアルゴリズムで処理をして、結果はどのデータになっているかの管理が必要になってきます。そこをしっかり管理できるのが、ML Flowとなっており。Databricks Notebookと連携して扱い易くなっております。
機械学習・AIのプロジェクトでは、データ分析をするデータサイエンティストと、データの準備をするデータエンジニアでの協同作業になります。しかし、自分の仕事の範囲は、ここまでとお互いの仕事の領域をキャッチボールしないと進まないことが多く発生します。
どのデータが、どういう状態になっているかを可視化して、協同で管理可能になるのはとても便利だと思います。
データエンジニアと、分析者とが、共通プラットフォーム上で、お互いの作業が良く理解できるのが、統合データ基盤と言われる所以だと思います。
Re:dash
OSSダッシュボードツールとして定評あるRe:dashをDatabricksが買収して、統合データ分析基盤が更に強化されることになりました。
Databricks Notebookでも可視化はできるのですが、エンドユーザが利用をするには機能不足気味です。そのために、Tableauとかの有償のBIツールを使わないといけなくなったりします。しかし、Tableauも癖があるので、専任の技術者を育成するのに躊躇をするユーザも多いです。
BIツールは、あくまでも閲覧とSQLでの検索ツールであり、データをしっかり整備し、パフォーマンスを考慮しないと、ユーザには使えなくなるシステムとなる危険性が高くなってしまいます。
Databricksは、統合データ分析基盤として各種BIツールとも連携は可能ですし、Re:dashをDatabricksの基本機能としてどう組み込んでいくのか、今後非常に期待されるところです。

まとめ
Databricks統合プラットフォームは、Hadoop/Sparkにてシステム構築、運用をしている企業は、ぜひ一度ご検討いただければと思います。
Hadoop/Sparkは、オンプレミスでは構築、運用が大変なので、Amazon EMR、Azure HDinsight等のクラウドで利用することが多くなっているかと思います。しかしながら、データ分析基盤を構築をするために、Hadoop/Sparkだけでなく様々なサービス、ソフトとの連携、選定や評価が避けられません。
DWHに対してBI製品の接続で済む程度の分析処理ならそれで良いのですが、パフォーマンス面とか、費用面とかで、結局システム的に見直しをしないといけないことになってませんでしょうか?
クラウドの運用が容易になること、データエンジニアのデータフローの作成が容易になること、機械学習の分析者がデータの扱いが容易になること、それだけでなく、大量データ分析の処理を分散並列に高速処理できるエンジンが、より使い易くなっていることが、『Databricks統合プラットフォーム』の本当の良さだと思います。
株式会社メソドロジック
白石 章 @Akira_Shiraishi