1.はじめに
株式会社日立製作所 研究開発グループ サービスコンピューティング研究部の田中です。
前回の記事では、機械学習のモデル作成・学習・検証、ワークフロー構築、モデルサービングといった MLOps に関するワークロードを統合して実行することを特長とするプラットフォームである Kubeflow のバージョン1.4を一般的な Kubernetes クラスタ上へデプロイする手順を紹介しました。
今回は、Kubeflow の機能の活用例として、Kubeflow 内部のオブジェクトストレージである MinIO サーバを使用することで、クラウド/オンプレミスを問わずに Kubeflow Pipelines 上で実行した機械学習パイプラインの実行結果を TensorBoard で可視化する手順を紹介します。
2.前提環境
前回の記事の手順などを利用して Kubeflow バージョン1.4をデプロイした Kubernetes クラスタ環境を前提とします。このため、今回の手順を動作確認した環境情報は以下の通りで前回と同様です。
(a) 動作確認環境(1)
- OS
- Masterノード(1台):Ubuntu 18.04 LTS
- Workerノード(2台):Ubuntu 18.04 LTS
- Kubernetes バージョン1.21.4(kubeadmでクラスタを作成)
- Kubeflow バージョン1.4.0
- Dynamic Volume Provisioner:nfs-subdir-external-provisioner v4.0.2
(b) 動作確認環境(2)
- OS
- Masterノード(1台)+Workerノード(1台):Ubuntu 18.04 LTS
- Kubernetes バージョン1.21.1(Kindでクラスタを作成)
- Kubeflow バージョン1.4.0
- Dynamic Volume Provisioner:local-path-provisioner v0.0.14
3.Kubeflow Pipelines と TensorBoard の連携の設定手順
3.1. Kubeflow Pipelines のコンポーネント実行結果可視化機能
Kubeflow Pipelines は、Kubeflow を構成する機能の一つで、機械学習の一連の処理をコンテナ化した「コンポーネント」を連結したワークフローを機械学習パイプラインとして管理・実行するための OSS です。Kubeflow Pipelines には、パイプラインの実行後の各コンポーネントのログや成果物(Artifacts)といった実行結果を可視化するための Visualization という機能があります。Visualization では、コンポーネントの実行結果の可視化方法の一つとして、 TensorBoard が用意されています。また、他の可視化方法としては、Confusion Matrix、ROC Curve、Scalar Metrics、Markdown、Web App(HTML)、Tableなどが用意されています。
| TensorBoard |
|---|
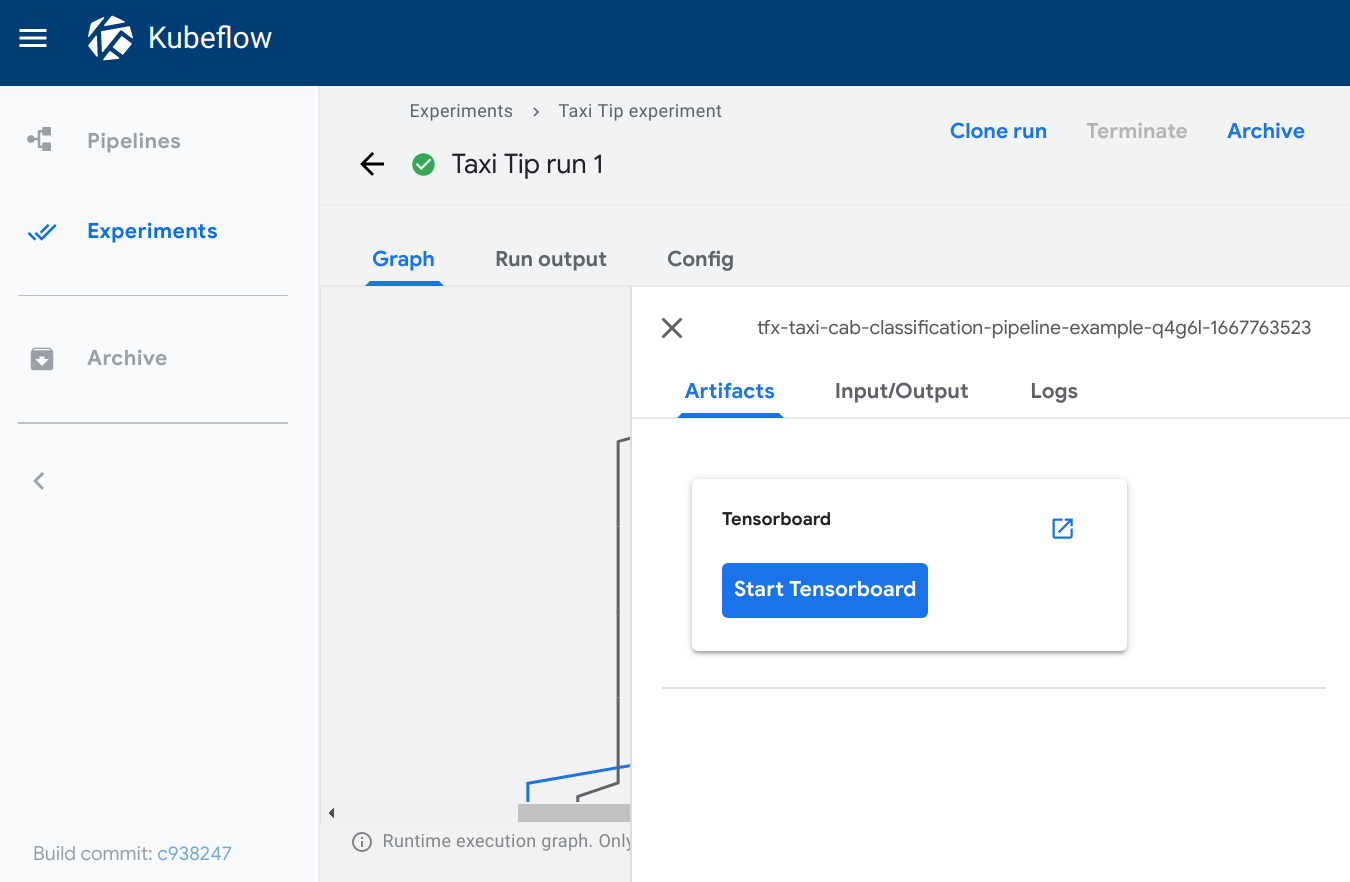 |
| Confusion Matrix | ROC Curve |
|---|---|
!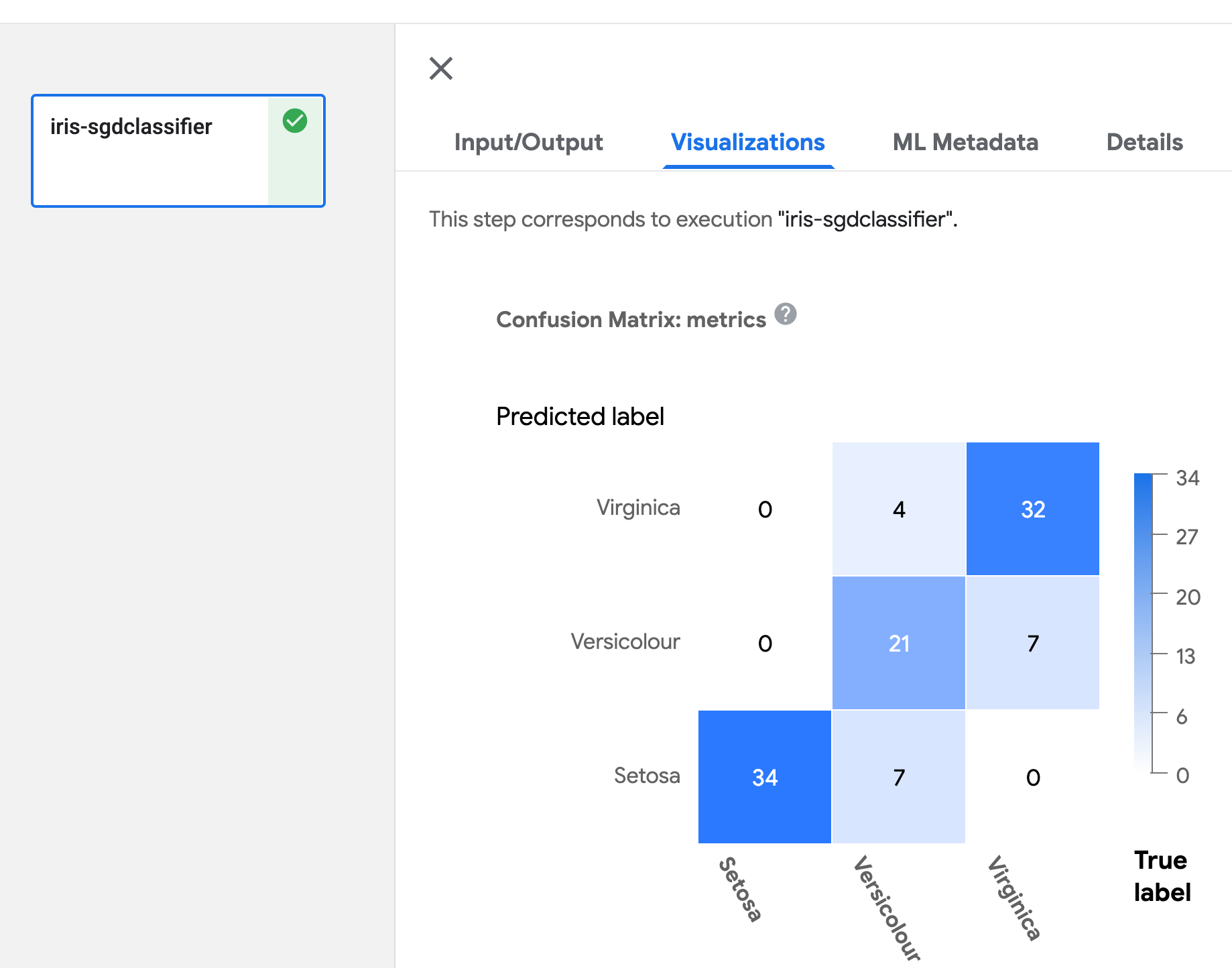
|
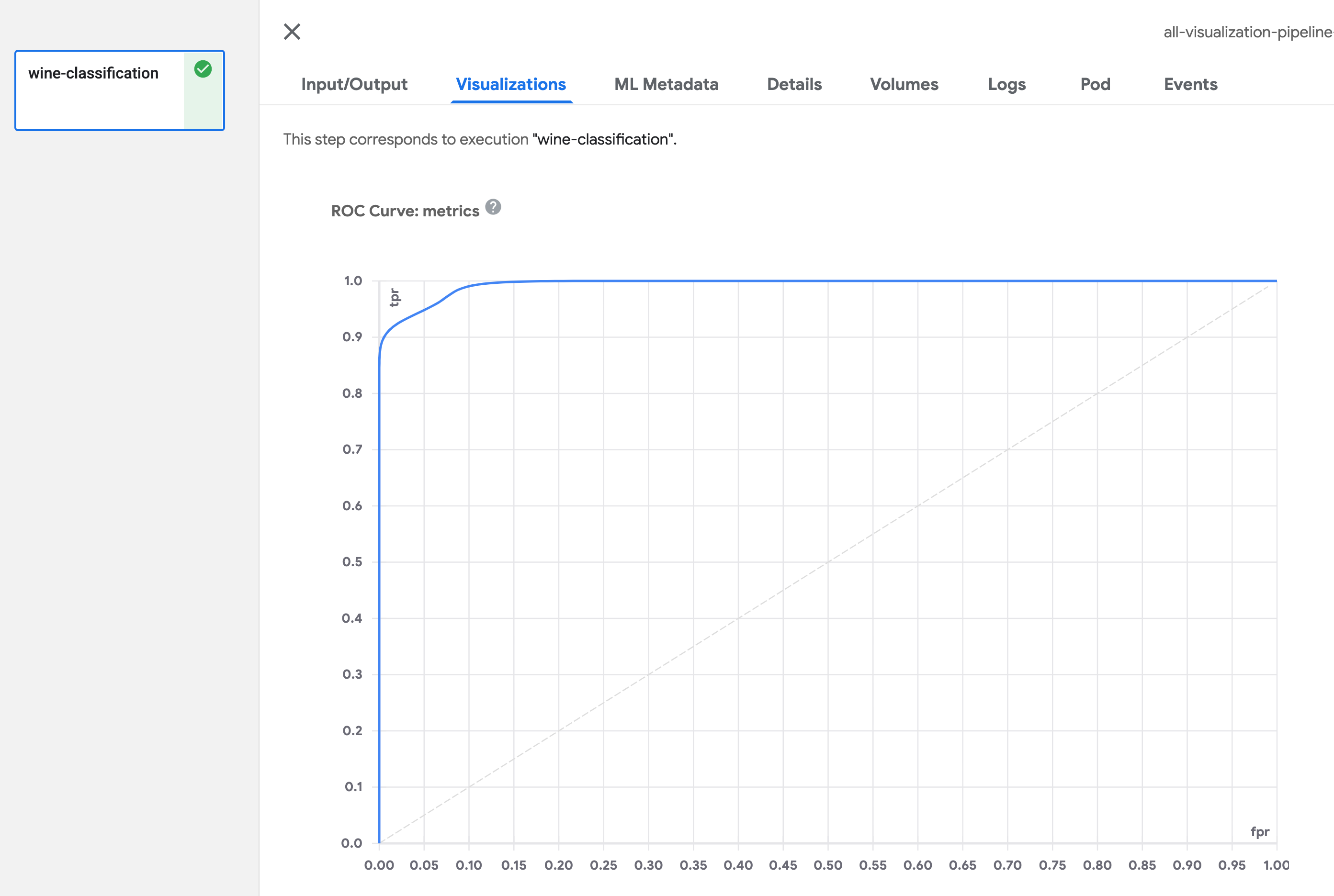 |
| Scalar Metrics | Markdown |
|---|---|
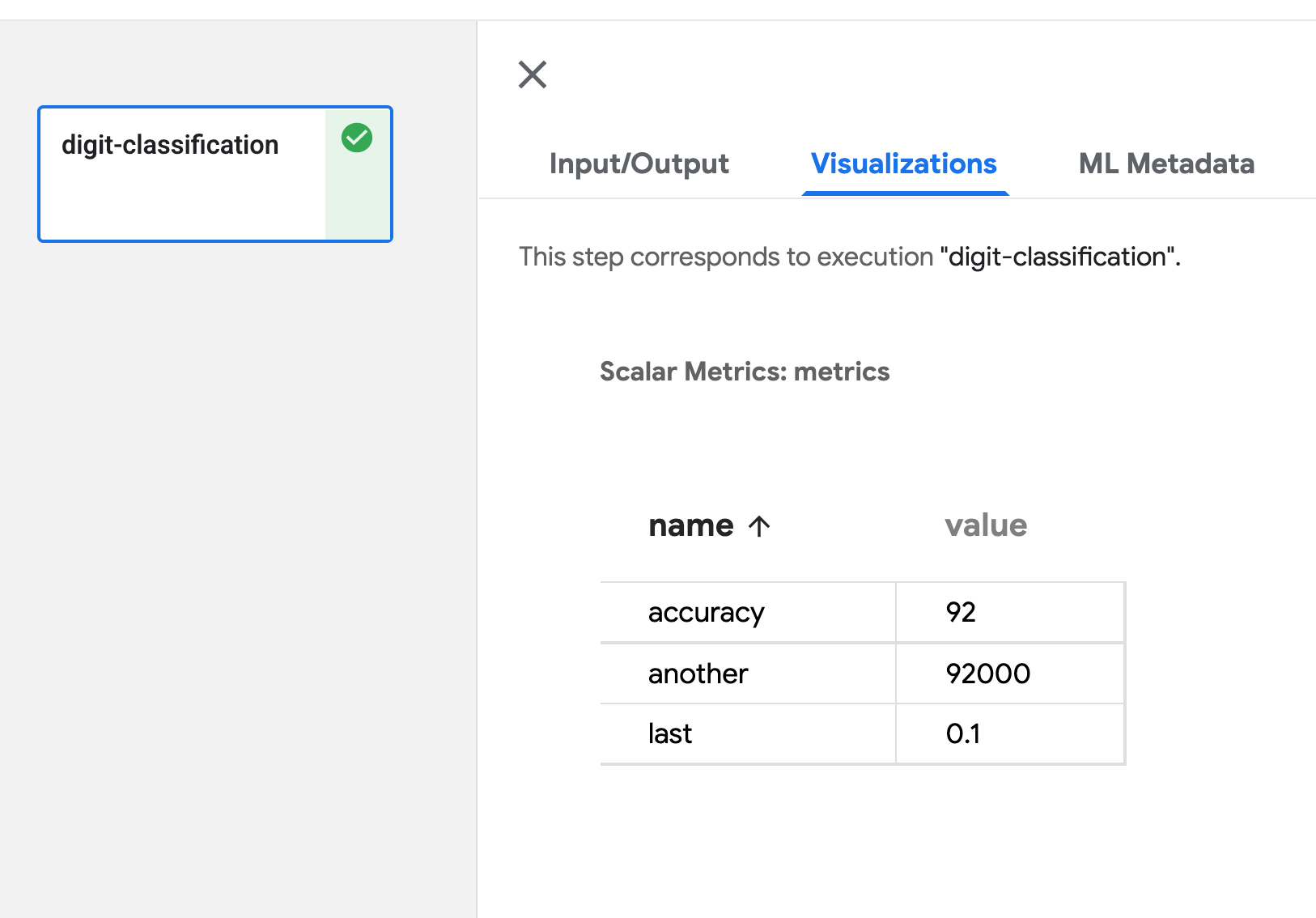 |
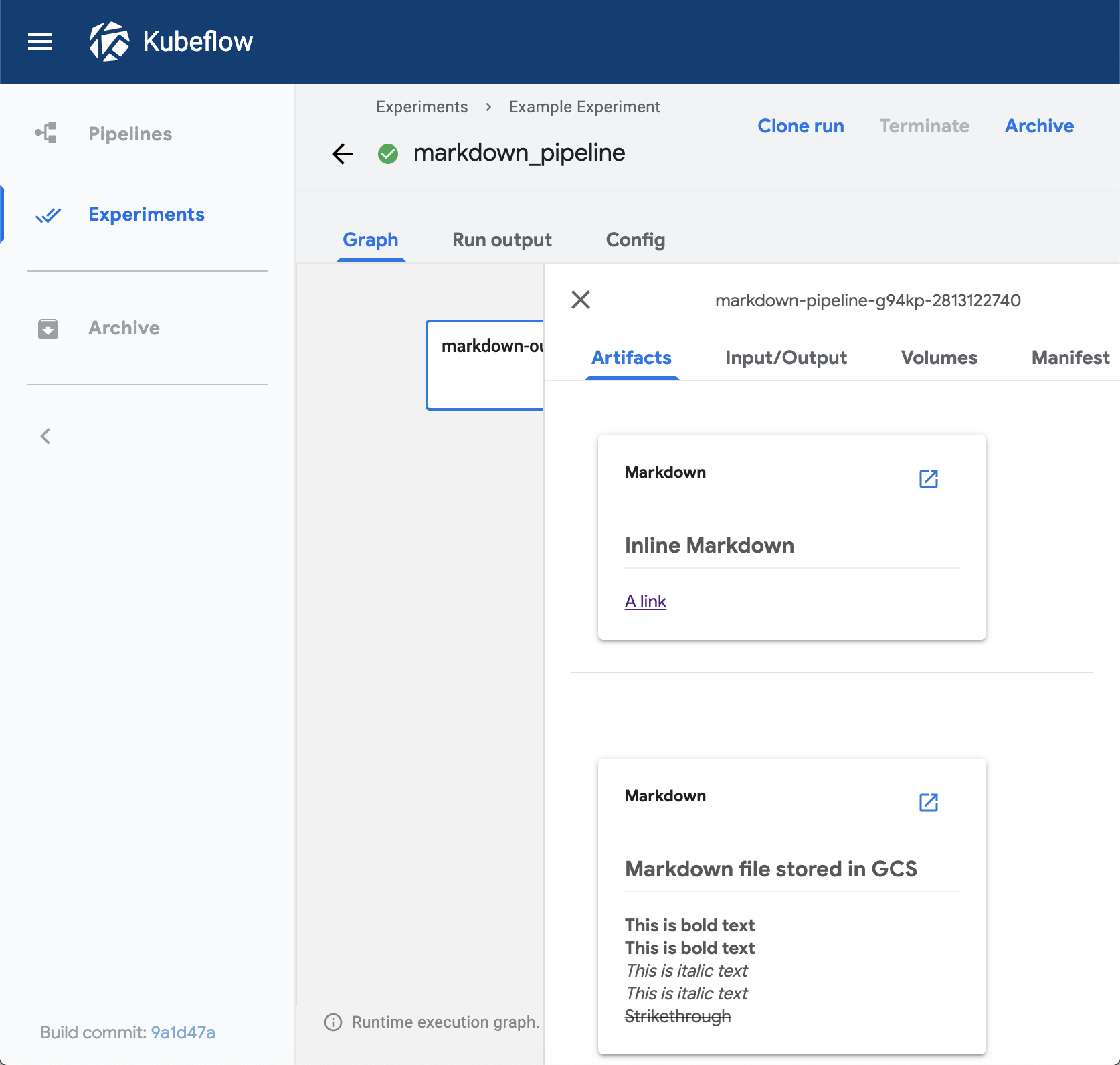 |
| Web App(HTML) | Table |
|---|---|
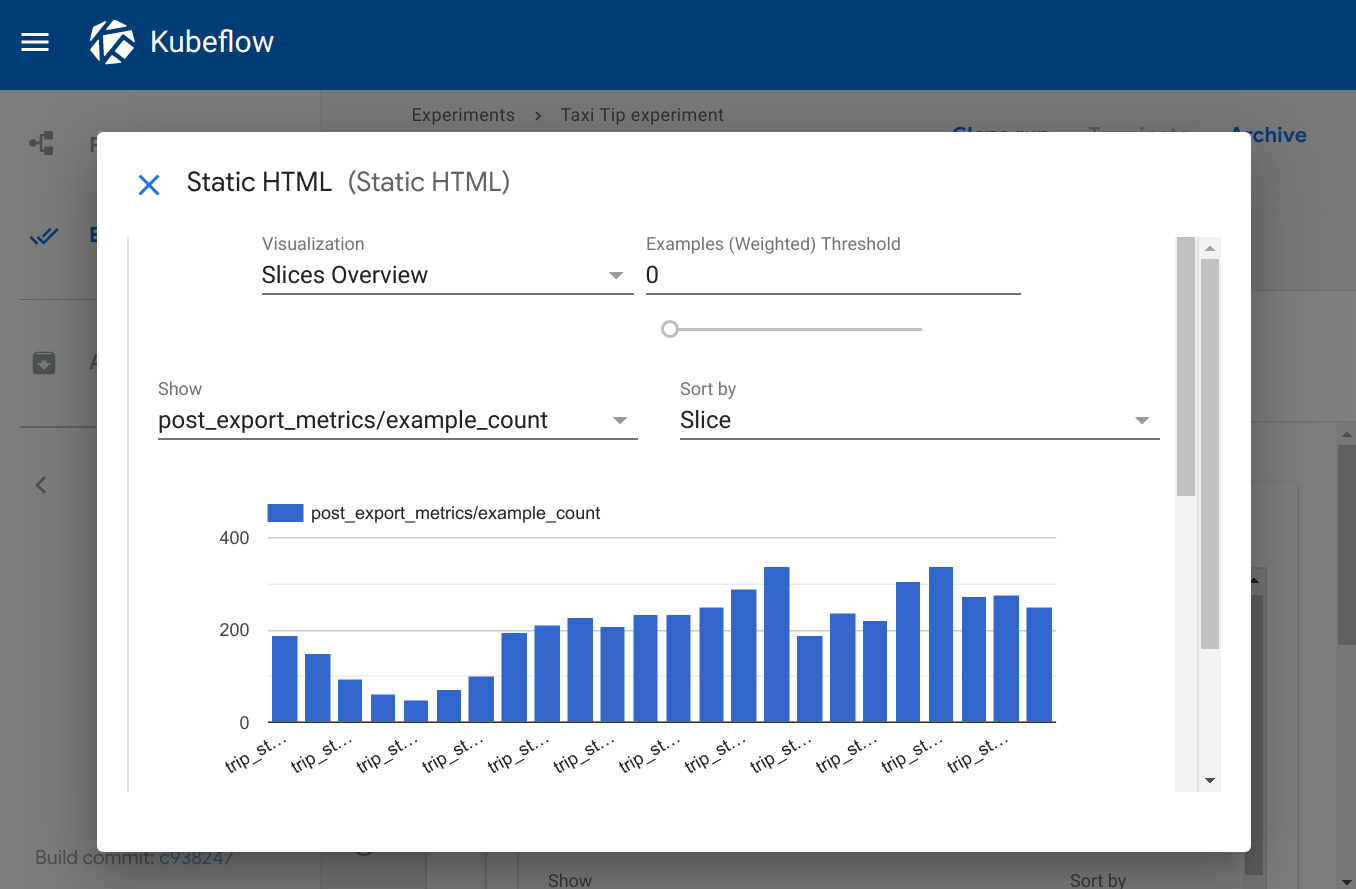 |
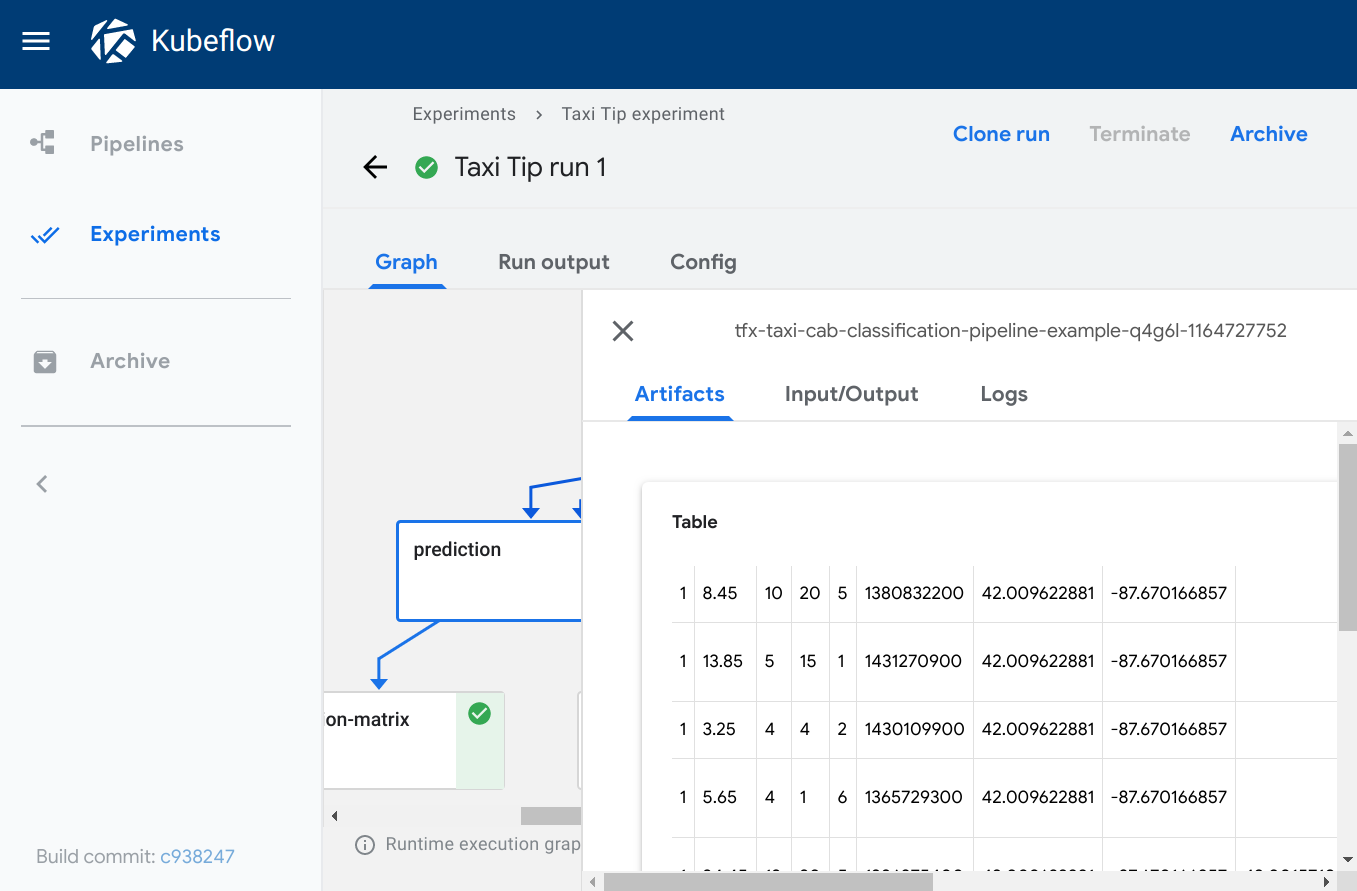 |
出典:https://www.kubeflow.org/docs/components/pipelines/sdk/output-viewer/
3.2. Kubeflow Pipelines と TensorBoard の連携
Kubeflow Pipelines のコンポーネント実行結果の可視化のために TensorBoard を使う場合、可視化するデータソースとしてオブジェクトストレージを指定する必要があります。通常は Kubeflow 外部のクラウドサービスである Google Cloud Storage (GCS) や Amazon Simple Storage Service (S3) をオブジェクトストレージとして使用します。
このように、Kubeflow Pipelines と TensorBoard を連携する場合にはクラウドサービスなどの Kubeflow 外部のオブジェクトストレージを用意する必要があります。一方、Kubeflow 内部では、コンポーネントのログや成果物の格納に利用されている Amazon S3 と API 互換性を持つオブジェクトストレージ・サーバである MinIO サーバが稼働しています。この MinIO サーバを流用することで、外部のオブジェクトストレージを用意することなく、Kubeflow 内部で簡易的に Kubeflow Pipelines のコンポ―ネット実行結果のTensorBoardによる可視化ができます。
そこで今回の記事では、Kubeflow 内部の MinIO サーバを利用することで、Kubeflow Pipelines 上で実行したパイプラインの実行結果を TensorBoard で可視化する(Kubeflow Pipelines と TensorBoard を連携させる)ための設定とサンプルを紹介します。
3.3. Kubeflow Pipelines と TensorBoard の連携の設定
Kubeflow Pipelines から TensorBoard を起動する時に、Kubeflow 内部の MinIO サーバのアクセス情報(S3互換パラメタ)を環境変数として設定することで、内部 MinIO サーバを使用した Kubeflow Pipelines と TensorBoard の連携(Kubeflow Pipelines のコンポーネント実行結果の TensorBoard による可視化)を実現します。
まず、Kubeflow 内部の MinIO サーバのアクセス情報を設定・保持する Kubernetes ConfigMap を作成します。作成する ConfigMap では、Kubeflow 内部の MinIO サーバに対するS3互換アクセスで必要となるパラメタのアクセスキーとシークレットアクセスキーを定義します。アクセスキーとシークレットアクセスキーは Kubeflow のデプロイ時に作成された MinIO アクセス情報を保持する Kubernetes Secret から読み出す形式にしています。
# Masterノードで操作:
# ConfigMapの作成
cat <<EOF | kubectl apply -n kubeflow -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: ml-pipeline-ui-viewer-template
data:
# TensorBoard のコンテナ起動時に渡す環境変数を定義します
# "AWS_ACCESS_KEY_ID": 内部MinIOサーバのアクセスキーを Secret から読み出して定義します
# "AWS_SECRET_ACCESS_KEY": 内部MinIOサーバのシークレットを Secret から読み出して定義します
# "AWS_REGION": 内部MinIOサーバのS3リージョンを定義します
# "S3_ENDPOINT": 内部MinIOサーバのS3互換APIのエンドポイントを定義します
# "S3_USE_HTTPS": 内部MinIOサーバのS3互換API通信を非HTTPSに定義します
# "S3_S3_VERIFY_SSL": 内部MinIOサーバのS3互換API通信時のSSL証明書確認なしに定義します
viewer-tensorboard-template.json: |
{
"spec": {
"containers": [
{
"env": [
{
"name": "AWS_ACCESS_KEY_ID",
"valueFrom": {
"secretKeyRef": {
"name": "mlpipeline-minio-artifact",
"key": "accesskey"
}
}
},
{
"name": "AWS_SECRET_ACCESS_KEY",
"valueFrom": {
"secretKeyRef": {
"name": "mlpipeline-minio-artifact",
"key": "secretkey"
}
}
},
{
"name": "AWS_REGION",
"value": "minio"
},
{
"name": "S3_ENDPOINT",
"value": "minio-service.kubeflow.svc.cluster.local:9000"
},
{
"name": "S3_USE_HTTPS",
"value": "0"
},
{
"name": "S3_VERIFY_SSL",
"value": "0"
}
]
}
]
}
}
EOF
続いて、Kubeflow Pipelines が上記の ConfigMap から取得した内部 MinIO アクセス情報を環境変数に設定して TensorBoard を起動するための設定を行うパッチコマンドを実行します。
このパッチコマンドでは、TensorBoard の起動テンプレートとして上記の ConfigMap を適用することを定義しています。結果的に、TensorBoard が内部 MinIO アクセス情報を環境変数として保持して起動するようになります。
# Masterノードで操作:
# ConfigMapに格納した環境変数を持つTensorBoardを起動する設定をパッチ適用する
kubectl patch deployment ml-pipeline-ui -n kubeflow --type strategic --patch '
spec:
template:
spec:
containers:
- env:
# 環境変数 VIEWER_TENSORBOARD_POD_TEMPLATE_SPEC_PATH に
# ConfigMap ml-pipeline-ui-viewer-template で定義される
# viewer-tensorboard-template.json を指定することで、
# 内部MinIOアクセス情報を環境変数に持つ TensorBoard を起動します。
- name: VIEWER_TENSORBOARD_POD_TEMPLATE_SPEC_PATH
value: /etc/config/viewer-tensorboard-template.json
image: gcr.io/ml-pipeline/frontend:1.7.0
name: ml-pipeline-ui
volumes:
- configMap:
name: ml-pipeline-ui-viewer-template
name: config-volume
'
以上の設定によって、Kubeflow Pipelines のパイプライン実行結果から内部 MinIO サーバを使用して TensorBoard を呼び出す連携動作が可能になります。
3.4. Kubeflow Pipelines と TensorBoard の連携のサンプルコード
Kubeflow Pipelines と TensorBoard の連携例として、MNIST データベース(手書き数値画像データセット)を利用したモデル学習のサンプルコードを用意しました。本サンプルコードは、TensorFlow 上で実行可能なニューラルネットワークライブラリである Keras のサンプルである Simple MNIST convnet に、モデル学習中のログ出力処理と出力ログファイルを Kubeflow 内部の MinIO サーバへコピーする処理を追加して、Kubeflow Pipelines で実行可能なパイプラインとして構成した Python スクリプトです。
3.4.1. Jupyter Notebook の作成・起動
まず、Kubeflow の Notebooks 機能を用いて、Jupyter Notebook(以下、Notebook と記述)を作成・起動し、ブラウザから利用できるようにします。
(1) Kubeflow 画面の「Notebooks」メニューをクリックして、Notebook リスト画面を表示します。

(2) Notebooks リストの上部にあるリンク(+ NEW NOTEBOOK)をクリックして、Notebook 作成画面に移動します。

(3) Notebook 作成画面において、Notebook 作成のパラメタを下表に従い記入し、画面下部の「LAUNCH」ボタンをクリックして、Notebook を作成します。
| # | 項目 | 内容 | パラメタ指定値 |
|---|---|---|---|
| 1 | Name | Notebookサーバ名 | 任意(例:sample-notebook-01) |
| 2 | Image | NotebookサーバのDockerイメージ名 | デフォルト提供のイメージを選択する ・「jupyterlab」ボタンを選択 ・“j1r0q0g6/notebooks/notebook-servers/jupyter-scipy:v1.4”をリストボックスから選択 |
| 3 | CPU/RAM | Notebookサーバ(Dockerコンテナ)の使用CPU数と使用メモリサイズを指定 | 任意(例:CPU数:2, メモリサイズ:4GB) |
| 4 | Workspace Volume | Notebooksのユーザワークスペースとして確保するディスク(ボリューム)の指定 | デフォルト値(10GBを新規作成)を指定 |
| 5 | Data Volumes | データセット用に別途確保するディスク(ボリューム)の追加 | 指定しない(デフォルトのまま) |
| 6 | Configurations | 追加の構成(リストボックス) | 指定しない(デフォルトのまま) |
| 7 | Affinity/Tolerations | NotebookサーバのKubernetes特定ノードへの配置可否設定 | 指定しない(デフォルトのまま) |
| 8 | Miscellaneous Settings | その他の設定 | Enable Shared Memory をオン (デフォルトのまま) |

(4) Notebook リストに戻るので、作成した Notebook(画面例ではsample-notebook-01)のステータスが「起動中」を示すアイコンであることを確認します。

(5) Notebook(sample-notebook-01)が起動するとステータスが「起動完了」を示すアイコンに変わり、青文字となった「CONNECT」表示をクリックして、起動を完了した Notebook へ接続します。

(6) 「CONNECT」クリック後に Notebook(sample-notebook-01)の接続画面が開き、ブラウザ上で Notebook を使える状態になります。

3.4.2. サンプルコードの入力・実行
Notebook との接続後、Kubeflow Pipelines と TensorBoard の連携に用いるモデル学習のサンプルコードを Notebook 上で入力・実行します。
(1) Notebook の Launcher画面から Notebook (Python 3) を起動します。
以降の作業は、Notebook (Python 3) のコマンドライン上でのサンプルコード入力・実行となります。

(2) Kubeflow Pipelinesのパイプラインを制御するために必要なライブラリをインポートする下記の Python スクリプトを入力・実行します。
# Import Kubeflow Pipelines SDK
import kfp
import kfp.dsl as dsl
import kfp.components as comp
from kfp.onprem import use_k8s_secret
from kfp.components import InputPath, OutputPath
# Import Kubernetes SDK
from kubernetes import client
(3) Kubeflow Pipelines のコンポーネントとして動作させる Simple MNIST convnet のモデル学習処理関数simple_minst_convnet_train を定義する下記の Python スクリプトを入力・実行します。
## Simple MNIST convnet
def simple_minst_convnet_train(minio_endpoint: str, log_bucket: str, log_dir: str, mlpipeline_ui_metadata_path: OutputPath()):
## Setup ##
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import os
from pathlib import Path
import json
from minio import Minio
## Prepar the data ##
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
## Build the model ##
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
## Train the model ##
# log for TensorBoard
log_dir_local = "logs/fit"
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir_local, histogram_freq=1)
# Train the model
batch_size = 128
epochs = 10
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1, callbacks=[tensorboard_callback])
## Evaluate the trained model ##
score = model.evaluate(x_test, y_test, verbose=0)
## Copy the local logs to MinIO Bucket ##
# 内部MinIOサーバのアクセス情報を環境変数から取得します
minio_access_key = os.getenv('MINIO_ACCESS_KEY')
minio_secret_key = os.getenv('MINIO_SECRET_KEY')
if not minio_access_key or not minio_secret_key:
raise Exception('MINIO_ACCESS_KEY or MINIO_SECRET_KEY env is not set')
# 内部MinIOサーバへ学習ログをコピーします
mclient = Minio(
minio_endpoint,
access_key=minio_access_key,
secret_key=minio_secret_key,
secure=False )
for path in Path("logs").rglob("*"):
if not path.is_dir():
object_name = os.path.join( log_dir, os.path.relpath(start=log_dir_local, path=path) )
mclient.fput_object( bucket_name=log_bucket, object_name=object_name, file_path=path )
## Visualize train logs ##
# 可視化(Visualization)としてTensorBoard を指定するためのJSONデータを出力します
metadata = {
'outputs' : [{
'type': 'tensorboard',
'source': 's3://'+log_bucket+'/tensorboard/logs/'
}]
}
with open(mlpipeline_ui_metadata_path, 'w') as metadata_file:
json.dump(metadata, metadata_file)
ここで、入力・実行したモデル学習処理関数simple_minst_convnet_train は、内部 MinIO サーバを使用して Kubeflow Pipelines と TensorBoard を連携させるための下記に示す処理を含みます。
- モデル学習処理の学習ログを Kubeflow 内部の MinIO サーバに格納するコピー処理
- TensorBoard を可視化機能として指示するコンポーネント出力処理
まず、関数simple_minst_convnet_train のモデル学習処理の学習ログを Kubeflow 内部の MinIO サーバに格納するコピー処理では、後述(5)のパイプライン定義スクリプトによってコンポーネントに設定される環境変数(MINIO_ACCESS_KEY、MINIO_SECRET_KEY)から内部 MinIO サーバのS3互換ファイル操作に必要なアクセスキーとシークレットアクセスキーを読み出し、コンポーネント内のローカルファイルシステム(ディレクトリ logs/fit 以下)に出力した学習ログを内部 MinIO サーバの bucket(mlpipeline)に転送しています。該当部分は次の通りです。
## Copy the local logs to MinIO Bucket ##
# 内部MinIOサーバのアクセス情報を環境変数から取得します
minio_access_key = os.getenv('MINIO_ACCESS_KEY')
minio_secret_key = os.getenv('MINIO_SECRET_KEY')
if not minio_access_key or not minio_secret_key:
raise Exception('MINIO_ACCESS_KEY or MINIO_SECRET_KEY env is not set')
# 内部MinIOサーバへ学習ログをコピーします
mclient = Minio(
minio_endpoint,
access_key=minio_access_key,
secret_key=minio_secret_key,
secure=False )
for path in Path("logs").rglob("*"):
if not path.is_dir():
object_name = os.path.join( log_dir, os.path.relpath(start=log_dir_local, path=path) )
mclient.fput_object( bucket_name=log_bucket, object_name=object_name, file_path=path )
次に、関数simple_minst_convnet_train の TensorBoard を可視化機能として指示するコンポーネント出力処理では、内部 MinIO サーバに格納したモデル学習ログを TensorBoard で可視化するために、コンポーネントの出力フォーマット(JSONフォーマット)に合わせてファイル(変数mlpipeline_ui_metadata_path が保持するファイルパス)に出力しています。該当部分は次の通りです。
## Visualize train logs ##
# 可視化(Visualization)としてTensorBoard を指定するためのJSONデータを出力します
metadata = {
'outputs' : [{
'type': 'tensorboard',
'source': 's3://'+log_bucket+'/tensorboard/logs/'
}]
}
with open(mlpipeline_ui_metadata_path, 'w') as metadata_file:
json.dump(metadata, metadata_file)
(4) 上記(3)で入力したモデル学習処理関数simple_minst_convnet_train を Kubeflow Pipelines 上でパイプライン実行するコンポーネントとして定義する下記の Python スクリプトを入力・実行します。
## Create train lightweight components.
train_op = comp.func_to_container_op(simple_minst_convnet_train, base_image='tensorflow/tensorflow:latest-py3', packages_to_install=['minio'])
(5) 上記(4)で定義したコンポーネントで構成される Kubeflow Pipelines のパイプラインを定義する下記の Python スクリプトを入力・実行します。
## Define the pipeline
@dsl.pipeline(
name='MNIST CNN Pipeline',
description='A toy pipeline that performs mnist model training and prediction.'
)
## Define parameters to be fed into pipeline
def mnist_container_pipeline(
minio_endpoint: str = 'minio-service.kubeflow.svc.cluster.local:9000',
log_bucket: str = 'mlpipeline',
log_dir: str = f'tensorboard/logs/{dsl.RUN_ID_PLACEHOLDER}'
):
# Create MNIST training component.
mnist_training_container = train_op( minio_endpoint=minio_endpoint, log_bucket=log_bucket, log_dir=log_dir )
# Get and set access key and secret key to access a storage (backet of MinIO)
# - アクセスキーを環境変数'MINIO_ACCESS_KEY'に設定
mnist_training_container.add_env_variable(client.V1EnvVar(name='MINIO_ACCESS_KEY',value_from=client.V1EnvVarSource(secret_key_ref=client.V1SecretKeySelector(name="mlpipeline-minio-artifact", key="accesskey", optional=False))))
# - シークレットキーを環境変数'MINIO_SECRET_KEY'に設定
mnist_training_container.add_env_variable(client.V1EnvVar(name='MINIO_SECRET_KEY',value_from=client.V1EnvVarSource(secret_key_ref=client.V1SecretKeySelector(name="mlpipeline-minio-artifact", key="secretkey", optional=False))))
ここで、入力・実行したパイプライン定義関数mnist_container_pipeline において、Kubeflow 内部 MinIO サーバの S3 互換ファイル操作に必要なアクセスキーとシークレットアクセスキーを Kubernetes Secret から読み出し、上記(4)で定義したコンポーネント、つまり、モデル学習を実行するパイプラインコンポーネントに対して環境変数(MINIO_ACCESS_KEY、MINIO_SECRET_KEY)として追加設定しています。該当部分は次の通りです。
# Get and set access key and secret key to access a storage (backet of MinIO)
# - アクセスキーを環境変数'MINIO_ACCESS_KEY'に設定
mnist_training_container.add_env_variable(client.V1EnvVar(name='MINIO_ACCESS_KEY',value_from=client.V1EnvVarSource(secret_key_ref=client.V1SecretKeySelector(name="mlpipeline-minio-artifact", key="accesskey", optional=False))))
# - シークレットキーを環境変数'MINIO_SECRET_KEY'に設定
mnist_training_container.add_env_variable(client.V1EnvVar(name='MINIO_SECRET_KEY',value_from=client.V1EnvVarSource(secret_key_ref=client.V1SecretKeySelector(name="mlpipeline-minio-artifact", key="secretkey", optional=False))))
(6) 上記(5)で定義したパイプラインを Kubeflow Pipelines 上で実行する時に渡すパラメタ値を定義する下記の Python スクリプトを入力・実行します。
# arguments of running pipeline directly
pipeline_func = mnist_container_pipeline
experiment_name = 'simple_mnist_covnet_kubeflow'
run_name = pipeline_func.__name__ + ' run'
arguments = {}
namespace = 'kubeflow-user-example-com'
(7) 上記(5)で定義したパイプラインをKubeflow Pipelines 上で実行する下記のPythonスクリプトを入力・実行します。
# Submit pipeline directly from pipeline function
kclient = kfp.Client("http://ml-pipeline.kubeflow.svc.cluster.local:8888")
run_result = kclient.create_run_from_pipeline_func(pipeline_func, experiment_name=experiment_name, run_name=run_name, arguments=arguments, namespace=namespace)
以上の操作により、Kubeflow Pipelines と TensorBoard の連携に用いるモデル学習のサンプルコードを Kubeflow Pipelines 上でパイプラインとして実行することができます。
3.4.3. パイプライン実行結果の参照
前節で実行したサンプルコード( Kubeflow Pipelines のパイプライン)の実行結果から TensorBoard を呼び出して学習ログを可視化します。
(1) Runs メニューから実行中のパイプライン( ”mnist_container_pipeline run” )を選択します。

(2) パイプラインのグラフ表示でモデル学習コンポーネント(”Simple minst convnet train”)のステータスが「完了」になるまで待ち、「完了」となったらクリックします。

(3) Visualizations タブを選択し、「Start TensorBoard」ボタンを押します。
ここで、TensorBoard が起動するまで(「Tensorboard is starting, and you may need to wait for a few minutes.」というメッセージが消えるまで)待ちます。

(4) TensorBoard が起動したら、「Open TensorBoard」ボタンを押して、TensorBoard の画面を開きます。

(5) TensorBoard 画面が立ち上がり、Kubeflow Pipelines のモデル学習コンポーネント(”Simple minst convnet train”)の実行ログ(学習ログ)を可視化することができます。
下の画面例では、モデル学習の反復回数(epoch)を X軸とし、正解率(epoch_accurary)と損失値(epoch_loss)をそれぞれ Y軸としたグラフとして学習ログが可視化されています。なお、各グラフにおいて、赤線は学習時の値、緑線は検証時の値を示しています。

5. おわりに
今回は、Kubeflowの機能の活用例として、Kubeflow内部のMinIOサーバを用いてKubeflow PipelinesとTensorBoardを連携させる手順を紹介しました。今後も、MLOpsを実現するための様々な機能を持つKubeflowの機能の活用例やノウハウを紹介していきたいと考えています。