1.はじめに
どうも、ARIの名古屋支社に勤務している愛知県民です♪
(/・ω・)/
2022/8/22に、与えられた英文から画像を生成する「Stable Diffusion」なるものが
オープンソースとして公開されました。
Stable Diffuisionをローカルに入れようとすると、
そこそこPCのスペックが必要なためどうしようか悩んだのですが、
LINEやクラウドを利用して、簡単に使うことができる様でした!
そこで今回は様々な方法でStable Diffusionを動かす方法についてまとめたいと思います♪
Stable Diffusionについて勉強中の方や画像生成AIに興味のある方の参考になれば幸いです。
(*^^)v
例として、「カレーライス」をStable Diffusionに描いてもらうと以下の様になります。
毎回出力される結果が異なるので、世界に1枚だけの画像です。
(・・・AIが描いたのが分からないくらいリアルで、とてもとても感動しました♪)
 |
|---|
2.用語の説明
2.1.Stable Diffusionとは
Stable Diffusionは、2022年8月22日(現地時間)に英Stability AI社によって
全世界に公開された高性能画像生成AIであり、
任意のテキストを入力するだけで、その内容に沿ったオリジナル画像を
自動で生成することができるという特徴を有しています。
2.2.Google Colaboratoryとは
Google Colaboratory(グーグル・コラボレイトリーもしくはコラボラトリー)とは、
Googleが機械学習の教育及び研究用に提供しているインストール不要かつ、
すぐにPythonや機械学習・深層学習の環境を整えることが出来る無料のサービスです。
3.デモ用サイトを使う
まずは、デモ用サイトを使う方法です。
3.1.以下のサイトにアクセスします。
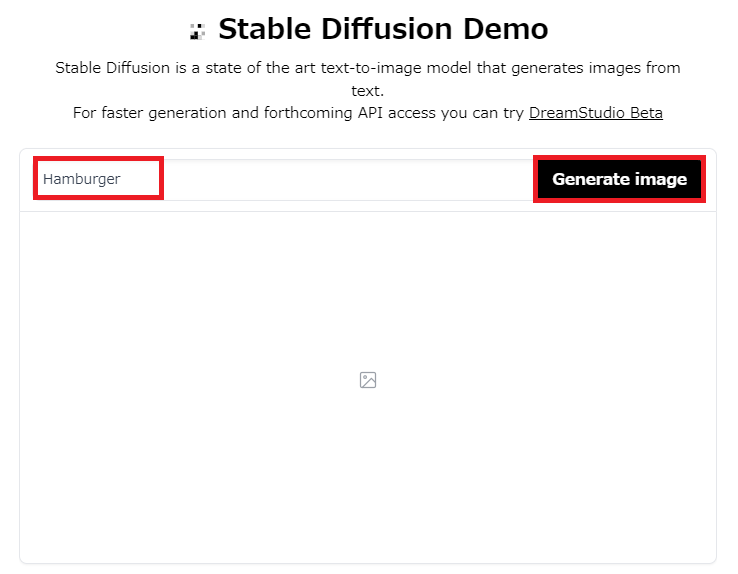
3.2.描いて欲しい絵の内容を英語で入力し、「Generate image」を選択します。
以下では例として、「ハンバーガー」の画像を出力しようとしています。
 |
|---|
3.3.約5分ほど待つと、Stable Diffusionが生成した4枚の画像が出力されるので、必要に応じて保存します。
 |
|---|
4.LINEを使う
続きまして、LINEを使う方法です。
「お絵描きばりぐっどくん」というアカウントが裏でStable Diffusionを使用して画像生成してくれます。
前提条件は以下となります。
- LINEをインストールしていること。
4.1.LINEのホームタブを選択し、友達追加のアイコンを選択します。
 |
|---|
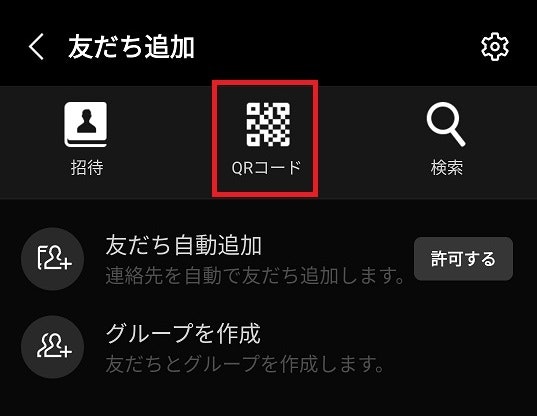
4.2.「QRコード」を選択します。
 |
|---|
4.3.以下のQRコードを読み込みます。
 |
|---|
4.4.「お絵描きばりぐっどくん」を友達追加します。
 |
|---|
4.5.トークにて、描いて欲しい絵の内容を入力すると、約1分後にStable Diffusionが生成した1枚の画像が出力されるので、必要に応じて保存します。
以下の画像では例として「ピザ」の画像を出力しようとしています。
また、「お絵描きばりぐっどくん」は日本語でも返信してくれます。
「お絵描きばりぐっどくん」の仕様上、1日2画像くらいしか出力できないようです。
 |
|---|
5.Google Colaboratoryを使う
最後にGoogle Colaboratoryを使う方法を記載します。
前提条件は以下となります。
- Googleのアカウントを作成していること
- Hugging Faceのアカウントを作成していること
5.1.Hugging Faceでの作業
5.1.1.以下のサイトにアクセスし、Hugging Faceアカウントでサインインします。
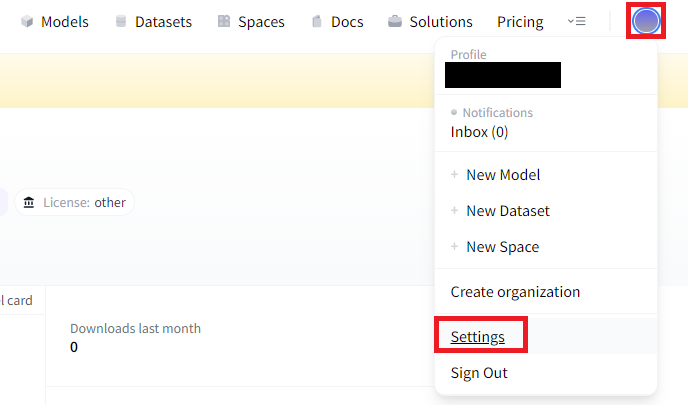
5.1.2.画面右上のアイコンを選択し、「Settings」を選択します。
 |
|---|
5.1.3.「Access Tokens」を選択し、「New token」を選択します。
 |
|---|
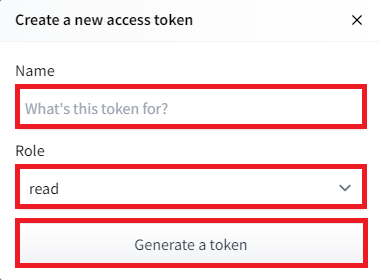
5.1.4.Nameにアクセストークン名を入力し、Roleは「read」とし、「Generate a token」を選択します。
 |
|---|
5.1.5.認証情報が表示されるので、コピーマークを選択し、メモ帳などにコピーします。
 |
|---|
5.1.6.以下のサイトにアクセスします。
5.1.7.チェックボックスにチェックをし、「Access repository」を選択します。
 |
|---|
5.2.Google Colaboratoryでの作業
5.2.1.以下のサイトにアクセスし、Googleアカウントでサインインします。
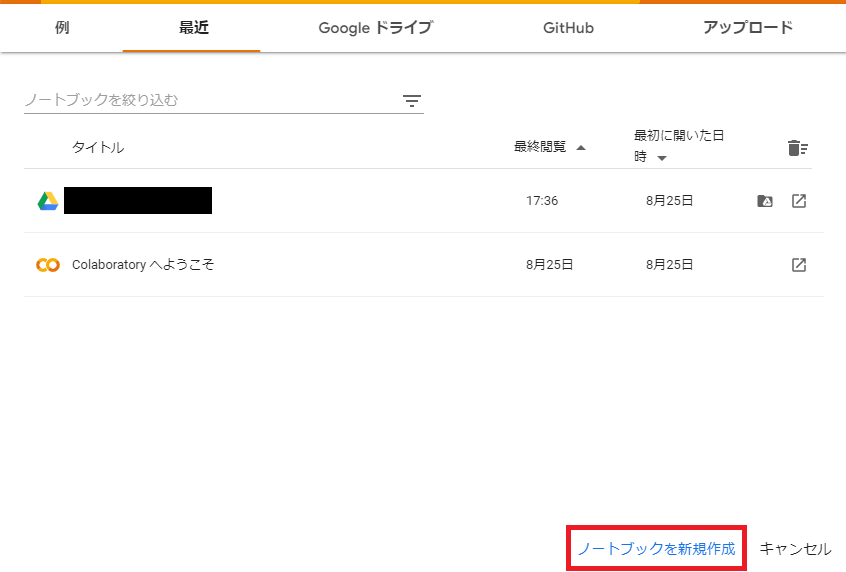
5.2.2.「ノートブックを新規作成」を選択します。
 |
|---|
5.2.3.「編集」を選択し、「ノートブックの設定」を選択します。
 |
|---|
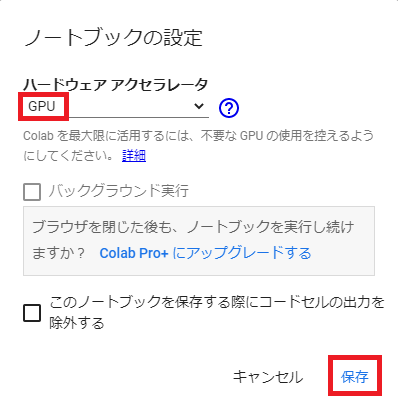
5.2.4.ハードウェアアクセラレータは「GPU」を選択し、「保存」を選択します。
 |
|---|
5.2.5.以下のコマンドを入力し、再生ボタンを選択します。
pip install diffusers==0.8.0 transformers scipy ftfy
2023/1/12時点では「0.8.0」で動作しましたが、別のモデルを使用したい場合は変更してください。
 |
|---|
5.2.6.再生ボタンの左にチェックマークが表示されることを確認します。
 |
|---|
5.2.7.画面左上の「コード」を選択します。
 |
|---|
以下の手順では省略していますが、
コマンド実行後は都度都度チェックマークを確認した後で、
「コード」を選択して次のコマンド欄を追加してください。
5.2.8.以下のコマンドを入力し、再生ボタンを選択します。
TOKEN="★手順5.1.5でコピーしたTokenの情報★"
5.2.9.以下のコマンドを入力し、再生ボタンを選択します。
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=TOKEN)
5.2.10.以下のコマンドを入力し、再生ボタンを選択します。
pipe.to("cuda")
5.2.11.以下のコマンドを入力し、再生ボタンを選択します。
keyword = "★描いて欲しい絵の内容★"
image = pipe(keyword)["images"][0]
image.save(f"★ファイル名★.png")
例:目玉焼きの絵を1枚出力するコマンド
keyword = "fried egg"
image = pipe(keyword)["images"][0]
image.save(f"目玉焼き.png")
5.2.12.約1分後にStable Diffusionが画像を生成するので、画面左のファイルマークを選択し、必要に応じて画像を保存します。
Google Colaboratoryの仕様で90分経過すると初期化され、
手順5.2.5のコマンドを打つところからやり直しになります。
コマンドは履歴が残っているため再度実行できますが、
Stable Diffusionが生成する画像は毎回異なるため、
保存を忘れると復元できなくなります。
 |
|---|
 |
|---|
| (参考:生成された「目玉焼き.png」の内容) |
5.2.13.複数の絵を出力したいときは以下のコマンドを使用します。
keyword = "★描いて欲しい絵の内容★"
num = ★出力したい枚数★
for i in range(num):
image = pipe(keyword)["sample"][0]
image.save("{}_{}.png".format(keyword,i+1))
例:美しい湖の画像を3枚出力するコマンド
keyword = "beautiful lake"
num = 3
for i in range(num):
image = pipe(keyword)["images"][0]
image.save("{}_{}.png".format(keyword,i+1))
 |
|---|
 |
|---|
 |
|---|
| (参考:実際に生成された3枚の画像) |
6.おわりに
ここまで読んで下さり、ありがとうございます!!!
(^^)
今回はStable Diffusionを使う方法を複数まとめてみました。
描いて欲しい絵の内容を伝えるだけで、AIが無料で絵を描いてくれるとは、
すごい時代になったなぁ・・・としみじみ感じたのと同時に、感動もしました!
また何か気になることがあれば記事にします♪
(:3_ヽ)_