Tips
1. While文によるページ遷移の繰り返し処理(うまくいく)
selenium_success.py
# 1ページ目の次のページ(2ページ目)のURLを取得
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
# 2ページ目から最終ページまでをループ処理する
while len(next_page_url) > 0:
driver.get(next_page_url)
#要素がロードされるまでの待ち時間を10秒に設定
driver.implicitly_wait(10)
next_page_html = driver.page_source.encode('utf-8')
# 任意の処理の実装コードをここに書く
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
else:
print("\n\n最後のページの処理が終わりました。\n\n")
2.for文によるページ遷移の繰り返し処理(途中で止まる)
selenium_failure.py
# 1ページ目の次のページ(2ページ目)のURLを取得
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
# 2ページ目から最終ページまでをループ処理する
if len(next_page_url) != 0:
driver.get(next_page_url)
#要素がロードされるまでの待ち時間を10秒に設定
driver.implicitly_wait(10)
next_page_html = driver.page_source.encode('utf-8')
# 任意の処理の実装コードをここに書く
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
else:
print("\n\n記事検索結果の最後のページの処理が終わりました。\n\n")
実際に作成したコード
selenium_python_multi_pages_while.py
# coding: utf-8
import time, argparse, datetime
from selenium import webdriver
from bs4 import BeautifulSoup
from pprint import pprint
import pandas as pd
import numpy as np
import time
### 定数 ###
url = "http://qiita.com"
### 変数の初期化宣言 ###
pagenum = 0
# コマンドライン引数を受け取る
parser = argparse.ArgumentParser()
# コマンドライン引数を1つだけ受け取る
parser.add_argument('-word', '--search_word', default='Python', help='Qiitaの記事検索ページに入力する検索単語を指定してください。')
parser.add_argument('-max', '--max_page_num', default='50', help='該当するページが複数ある場合、データ取得するページ数に上限を設定する場合は、上限ページ数を指定してください。')
args = parser.parse_args()
search_word = args.search_word
num_of_search_pages = int(args.max_page_num)
print("\n\n入力された検索文字列: ", args.search_word, "\n")
print("記事一覧ページが複数ページに及ぶ場合、{}ページまでで処理を打ち切ります。".format(num_of_search_pages))
# outputファイル名
output_file_name = str(datetime.datetime.now()) + "_Search: " + search_word
### メソッド定義 ###
def proceed_each_page(page_num, this_page_html, driver):
from bs4 import BeautifulSoup
this_soup = BeautifulSoup(this_page_html, 'lxml')
print("""
================================
{}ページ目を処理中...
===============================
""".format(page_num))
results = this_soup.find_all("h1", class_="searchResult_itemTitle")
# 結果を記事タイトルリストに格納
this_page_title_list = []
for result in results:
title_texts = result.findAll("a")
title_texts = str(title_texts[0]).replace("<em>", "").replace("</em>", "").split(">")[1:]
title_texts = title_texts[0]
pos = title_texts.find('</a')
title_text = title_texts[:pos]
this_page_title_list.append(title_text)
console_message = "検索結果画面の{}ページ目の記事件数: ".format(pagenum) + str(len(this_page_title_list)) + "\n\n"
pprint(this_page_title_list)
# 結果をURLリストに格納
this_page_url_list = []
for result in results:
href = result.findAll("a")[0].get("href")
this_page_url_list.append(str(url + href))
# 投稿者を投稿者リストに格納
# <div class="searchResult_header"><a href="/niiku-y">niiku-y</a>が2019/08/07に投稿</div>
this_page_author_list = []
results = this_soup.findAll(class_="searchResult_header")
for result in results:
author = result.findAll("a")[0].get("href")
author = author.replace("/", "")
this_page_author_list.append(author)
# nページ目から取得した記事であることをデータ保存
this_page_num_list = [page_num]*len(this_page_title_list)
## 検索結果画面のnページ目の画面スクリーンキャプチャを取得
# 画面の縦横サイズのデータを取得
w = driver.execute_script("return document.body.scrollWidth;")
h = driver.execute_script("return document.body.scrollHeight;")
driver.set_window_size(w,h)
# 画面スクリーンキャプチャファイル(画像ファイル)の保存場所とファイル名を指定
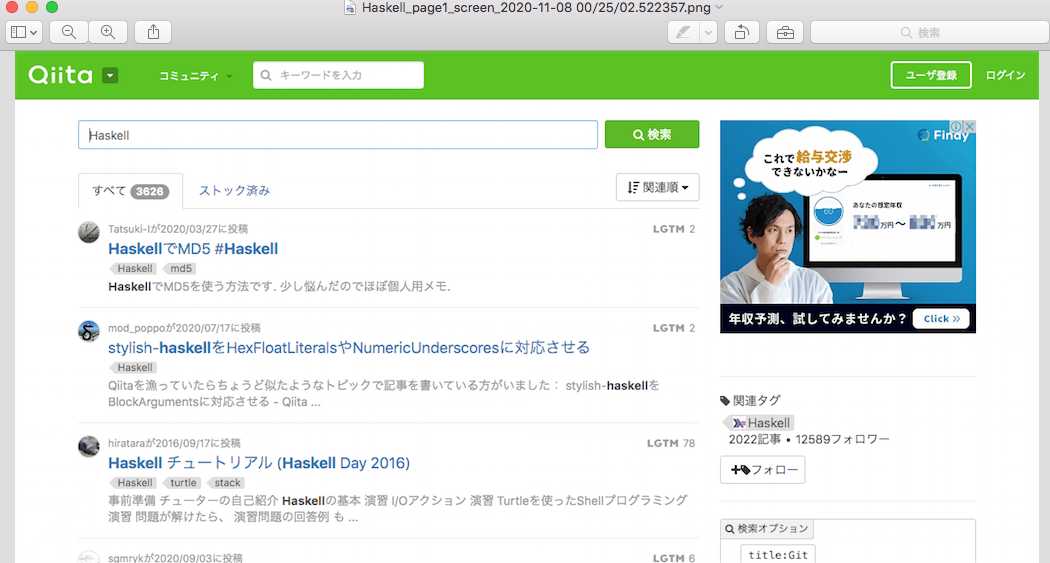
FILENAME = "./{search_word}_page{number}_screen_{datetime}.png".format(search_word=search_word, number=page_num, datetime=str(datetime.datetime.now()))
# 画像を保存
driver.save_screenshot(FILENAME)
#処理したWebページの情報を格納した各listを返す
return [this_page_num_list, this_page_author_list, this_page_title_list, this_page_url_list, driver]
### メソッド定義おわり
### main処理
driver = webdriver.Chrome()
# Qiitaのトップページにアクセス
driver.get(url)
# 記事の検索ボックス欄に、キーワードを入力
search = driver.find_element_by_class_name("st-Header_searchInput")
search.send_keys(search_word)
search.submit()
time.sleep(5)
# 検索結果の記事一覧ページの1ページ目のHTMLを取得
first_page_html = driver.page_source.encode('utf-8')
# 1ページ目を処理
page_num = 1
all_page_num_list = []
all_page_author_list = []
all_page_title_list = []
all_page_url_list = []
this_page_num_list, this_page_author_list, this_page_title_list, this_page_url_list, driver = proceed_each_page(page_num, first_page_html, driver)
all_page_num_list = all_page_num_list + this_page_num_list
all_page_author_list = all_page_author_list + this_page_author_list
all_page_title_list = all_page_title_list + this_page_title_list
all_page_url_list = all_page_url_list + this_page_url_list
# 受け取ったdriverの指示対象のWebページに、次のページがある場合は、次のページに移動する
# next_page_urlの返り値はlist型。次のページが記載された上記のタグが存在しない場合は、空のlistが返る
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
print("=======")
print(type(next_page_url))
print("=======")
# 2ページ目から(最終ページ目 もしくは、{num_of_search_pages}ページ目までのいずれか小さいページ番号目)までをループ処理する
# (num_of_search_pages)ページ目を最終ページにするためには、{num_of_search_pages -1)回、次のページをめくる
while len(next_page_url) > 0 and page_num <= (num_of_search_pages - 1):
driver.get(next_page_url)
#要素がロードされるまでの待ち時間を10秒に設定
driver.implicitly_wait(10)
#time.sleep(5)
next_page_html = driver.page_source.encode('utf-8')
page_num += 1
this_page_num_list, this_page_author_list, this_page_title_list, this_page_url_list, driver = proceed_each_page(page_num, next_page_html, driver)
all_page_num_list = all_page_num_list + this_page_num_list
all_page_author_list = all_page_author_list + this_page_author_list
all_page_title_list = all_page_title_list + this_page_title_list
all_page_url_list = all_page_url_list + this_page_url_list
next_page_url = driver.find_element_by_class_name("js-next-page-link").get_attribute("href")
print("=======")
print(next_page_url)
print(len(next_page_url))
print("=======")
else:
print("\n\n記事検索結果の最後のページの処理が終わりました。\n\n")
# Excelファイル出力
print("\n\n取得した検索結果のデータをExcelファイルに出力します。\n\m")
data = np.array([all_page_num_list, all_page_author_list, all_page_title_list, all_page_url_list]).T
index_list = list(range(len(all_page_num_list)))
column_list = ['検索結果画面内の掲載ページ番号', '投稿者', '記事のタイトル', '記事のURL']
output_df = pd.DataFrame(data, columns=column_list, index=index_list)
pprint(output_df)
# 結果をExcelファイルに出力
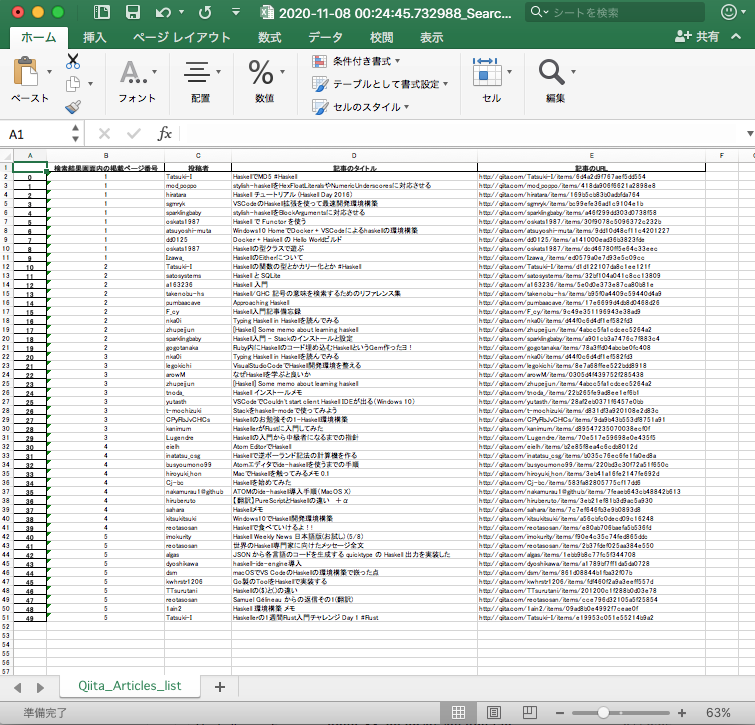
output_df.to_excel('./'+output_file_name + '.xlsx', sheet_name='Qiita_Articles_list')
# Webページに自動アクセスするために生成したdriverインスタンスを閉じて消去(メモリ開放)する
time.sleep(5)
driver.close()
driver.quit()
( 使い方 )
Console
$ python selenium_python_multi_pages_while.py --help
usage: selenium_python_multi_pages_while.py [-h] [-word SEARCH_WORD]
[-max MAX_PAGE_NUM]
optional arguments:
-h, --help show this help message and exit
-word SEARCH_WORD, --search_word SEARCH_WORD
Qiitaの記事検索ページに入力する検索単語を指定してください。
-max MAX_PAGE_NUM, --max_page_num MAX_PAGE_NUM
該当するページが複数ある場合、データ取得するページ数に上限を設定する場合は、上限ページ数を指定してください。
$
( 実行例とその結果 )
Console
$ python selenium_python_multi_pages_while.py -word Haskell -max 5
入力された検索文字列: Haskell
記事一覧ページが複数ページに及ぶ場合、5ページまでで処理を打ち切ります。
================================
1ページ目を処理中...
===============================
['HaskellでMD5 #Haskell',
'stylish-haskellをHexFloatLiteralsやNumericUnderscoresに対応させる',
'Haskell チュートリアル (Haskell Day 2016)',
'VSCodeのHaskell拡張を使って最速開発環境構築',
'stylish-haskellをBlockArgumentsに対応させる',
'Haskell で Functor を使う',
'Windows10 HomeでDocker + VSCodeによるhaskellの環境構築',
'Docker + Haskell の Hello Worldビルド',
'Haskellの型クラスで遊ぶ',
'HaskellのEitherについて']
=======
<class 'str'>
=======
================================
2ページ目を処理中...
===============================
['Haskellの関数の型とかカリー化とか #Haskell',
'Haskell と SQLite',
'Haskell 入門',
'Haskell/GHC 記号の意味を検索するためのリファレンス集',
'Approaching Haskell',
'Haskell入門記事備忘録',
'Typing Haskell in Haskellを読んでみる',
'[Haskell] Some memo about learning haskell',
'Haskell入門 - Stackのインストールと設定',
'Ruby内にHaskellのコード埋め込むHaskellというGem作ったヨ!']
=======
https://qiita.com/search?page=3&q=Haskell
41
=======
================================
3ページ目を処理中...
===============================
['Typing Haskell in Haskellを読んでみる',
'VisualStudioCodeでHaskell開発環境を整える',
'なぜHaskellを学ぶと良いか',
'[Haskell] Some memo about learning haskell',
'Haskell インストールメモ',
"VSCodeでCouldn't start client Haskell IDEが出る(Windows 10)",
'Stackをhaskell-modeで使ってみよう',
'Haskellのお勉強その1-Haskell環境構築',
'HaskellerがRustに入門してみた',
'Haskellの入門から中級者になるまでの指針']
=======
https://qiita.com/search?page=4&q=Haskell
41
=======
================================
4ページ目を処理中...
===============================
['Atom EditorでHaskell',
'Haskellで逆ポーランド記法の計算機を作る',
'Atomエディタでide-haskellを使うまでの手順',
'MacでHaskellを触ってみるメモ 0.1',
'Haskellを始めてみた',
'ATOMのide-haskell導入手順(MacOS X)',
'【翻訳】PureScriptとHaskellの違い\u3000+α',
'Haskellメモ',
'Windows10でHaskell開発環境構築',
'Haskellで食べていけるよ!!']
=======
https://qiita.com/search?page=5&q=Haskell
41
=======
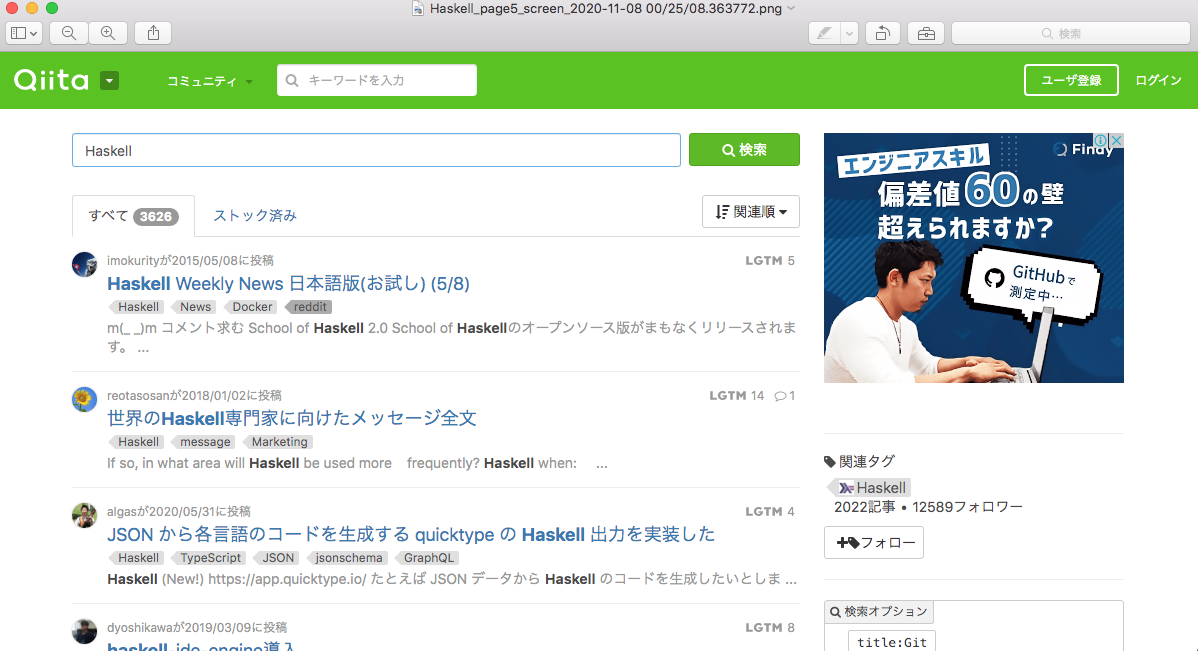
================================
5ページ目を処理中...
===============================
['Haskell Weekly News 日本語版(お試し) (5/8)',
'世界のHaskell専門家に向けたメッセージ全文',
'JSON から各言語のコードを生成する quicktype の Haskell 出力を実装した',
'haskell-ide-engine導入',
'macOSでVS CodeのHaskellの環境構築で嵌った点',
'Go製のToolをHaskellで実装する',
'Haskellの($)と(.)の違い',
'Samuel Gélineau からの返信その1(翻訳)',
'Haskell 環境構築 メモ',
'Haskellerの1週間Rust入門チャレンジ Day 1 #Rust']
=======
https://qiita.com/search?page=6&q=Haskell
41
=======
記事検索結果の最後のページの処理が終わりました。
取得した検索結果のデータをExcelファイルに出力します。
\m
検索結果画面内の掲載ページ番号 投稿者 \
0 1 Tatsuki-I
1 1 mod_poppo
2 1 hiratara
3 1 sgmryk
4 1 sparklingbaby
5 1 oskats1987
6 1 atsuyoshi-muta
7 1 dd0125
8 1 oskats1987
9 1 Izawa_
10 2 Tatsuki-I
11 2 satosystems
12 2 a163236
13 2 takenobu-hs
14 2 pumbaacave
15 2 F_cy
16 2 nka0i
17 2 zhupeijun
18 2 sparklingbaby
19 2 gogotanaka
20 3 nka0i
21 3 legokichi
22 3 arowM
23 3 zhupeijun
24 3 tnoda_
25 3 yutasth
26 3 t-mochizuki
27 3 CPyRbJvCHlCs
28 3 kanimum
29 3 Lugendre
30 4 eielh
31 4 inatatsu_csg
32 4 busyoumono99
33 4 hiroyuki_hon
34 4 Cj-bc
35 4 nakamurau1@github
36 4 hiruberuto
37 4 sahara
38 4 kitsukitsuki
39 4 reotasosan
40 5 imokurity
41 5 reotasosan
42 5 algas
43 5 dyoshikawa
44 5 dsm
45 5 kwhrstr1206
46 5 TTsurutani
47 5 reotasosan
48 5 1ain2
49 5 Tatsuki-I
記事のタイトル \
0 HaskellでMD5 #Haskell
1 stylish-haskellをHexFloatLiteralsやNumericUnders...
2 Haskell チュートリアル (Haskell Day 2016)
3 VSCodeのHaskell拡張を使って最速開発環境構築
4 stylish-haskellをBlockArgumentsに対応させる
5 Haskell で Functor を使う
6 Windows10 HomeでDocker + VSCodeによるhaskellの環境構築
7 Docker + Haskell の Hello Worldビルド
8 Haskellの型クラスで遊ぶ
9 HaskellのEitherについて
10 Haskellの関数の型とかカリー化とか #Haskell
11 Haskell と SQLite
12 Haskell 入門
13 Haskell/GHC 記号の意味を検索するためのリファレンス集
14 Approaching Haskell
15 Haskell入門記事備忘録
16 Typing Haskell in Haskellを読んでみる
17 [Haskell] Some memo about learning haskell
18 Haskell入門 - Stackのインストールと設定
19 Ruby内にHaskellのコード埋め込むHaskellというGem作ったヨ!
20 Typing Haskell in Haskellを読んでみる
21 VisualStudioCodeでHaskell開発環境を整える
22 なぜHaskellを学ぶと良いか
23 [Haskell] Some memo about learning haskell
24 Haskell インストールメモ
25 VSCodeでCouldn't start client Haskell IDEが出る(Wi...
26 Stackをhaskell-modeで使ってみよう
27 Haskellのお勉強その1-Haskell環境構築
28 HaskellerがRustに入門してみた
29 Haskellの入門から中級者になるまでの指針
30 Atom EditorでHaskell
31 Haskellで逆ポーランド記法の計算機を作る
32 Atomエディタでide-haskellを使うまでの手順
33 MacでHaskellを触ってみるメモ 0.1
34 Haskellを始めてみた
35 ATOMのide-haskell導入手順(MacOS X)
36 【翻訳】PureScriptとHaskellの違い +α
37 Haskellメモ
38 Windows10でHaskell開発環境構築
39 Haskellで食べていけるよ!!
40 Haskell Weekly News 日本語版(お試し) (5/8)
41 世界のHaskell専門家に向けたメッセージ全文
42 JSON から各言語のコードを生成する quicktype の Haskell 出力を実装した
43 haskell-ide-engine導入
44 macOSでVS CodeのHaskellの環境構築で嵌った点
45 Go製のToolをHaskellで実装する
46 Haskellの($)と(.)の違い
47 Samuel Gélineau からの返信その1(翻訳)
48 Haskell 環境構築 メモ
49 Haskellerの1週間Rust入門チャレンジ Day 1 #Rust
記事のURL
0 http://qiita.com/Tatsuki-I/items/6d4a2d9f767ae...
1 http://qiita.com/mod_poppo/items/418da906f6621...
2 http://qiita.com/hiratara/items/169b5cb83b0adb...
3 http://qiita.com/sgmryk/items/bc99efe36ad1c910...
4 http://qiita.com/sparklingbaby/items/a46f299dd...
5 http://qiita.com/oskats1987/items/30f9078c5096...
6 http://qiita.com/atsuyoshi-muta/items/9dd10d48...
7 http://qiita.com/dd0125/items/a141000ead36b382...
8 http://qiita.com/oskats1987/items/dcd46780ff5e...
9 http://qiita.com/Izawa_/items/ed0579a0e7d93e5c...
10 http://qiita.com/Tatsuki-I/items/d1d122107da8c...
11 http://qiita.com/satosystems/items/32bf104a041...
12 http://qiita.com/a163236/items/5e0d0e373e87ca8...
13 http://qiita.com/takenobu-hs/items/b95f0a4409c...
14 http://qiita.com/pumbaacave/items/17e6699d4db8...
15 http://qiita.com/F_cy/items/9c49e351196943e38ad9
16 http://qiita.com/nka0i/items/d44f0c6d4df1ef582fd3
17 http://qiita.com/zhupeijun/items/4abcc5fa1cdce...
18 http://qiita.com/sparklingbaby/items/a901cb3a7...
19 http://qiita.com/gogotanaka/items/78a3ffd04abc...
20 http://qiita.com/nka0i/items/d44f0c6d4df1ef582fd3
21 http://qiita.com/legokichi/items/8e7a68ffee522...
22 http://qiita.com/arowM/items/0305d4f439752f285438
23 http://qiita.com/zhupeijun/items/4abcc5fa1cdce...
24 http://qiita.com/tnoda_/items/22b265fe9ad8ee1e...
25 http://qiita.com/yutasth/items/28af2eb0371f645...
26 http://qiita.com/t-mochizuki/items/d831df3a920...
27 http://qiita.com/CPyRbJvCHlCs/items/9da9b43b55...
28 http://qiita.com/kanimum/items/d89547235070038...
29 http://qiita.com/Lugendre/items/70e517e59698e0...
30 http://qiita.com/eielh/items/b2e85f8ea4c6cdb8012d
31 http://qiita.com/inatatsu_csg/items/b035c76ec6...
32 http://qiita.com/busyoumono99/items/220bd3c30f...
33 http://qiita.com/hiroyuki_hon/items/3eb41a16fe...
34 http://qiita.com/Cj-bc/items/583fa82805775cf17dd6
35 http://qiita.com/nakamurau1@github/items/7feae...
36 http://qiita.com/hiruberuto/items/3eb21ef81b3d...
37 http://qiita.com/sahara/items/7c7ef646fb3e9b08...
38 http://qiita.com/kitsukitsuki/items/a56cbfc0de...
39 http://qiita.com/reotasosan/items/e80ab706baef...
40 http://qiita.com/imokurity/items/f90e4c35c74fe...
41 http://qiita.com/reotasosan/items/2b37fdef025a...
42 http://qiita.com/algas/items/1ebb9b8c77fc5f344708
43 http://qiita.com/dyoshikawa/items/a1789bf7ff1d...
44 http://qiita.com/dsm/items/861d08844b1fba32f07b
45 http://qiita.com/kwhrstr1206/items/fdf460f2a9a...
46 http://qiita.com/TTsurutani/items/201200c1f288...
47 http://qiita.com/reotasosan/items/cce796d32105...
48 http://qiita.com/1ain2/items/09ad8b0e4992f7ceae0f
49 http://qiita.com/Tatsuki-I/items/e19953c051e55...
$
( 出力ファイル群 )
( Excelファイル )
( pngファイル )
( 途中ページの画面キャプチャ画像ファイルは、掲載省略)
その他:記事の検索文字列は、漢字カタカナかなもOK
Console}
$ python selenium_python_multi_pages_while.py -word 圏論 -max 20