文字起こしをしたい
色々と環境も変わりまして、書く時間が取れませんでしたorz
今後は自身が試してきた内容などを気軽に投稿できたらと思っておりますー!
さて、文字起こしをしたいきっかけなのですが、妻が学校のPTAで書記をしており、iPhoneで音声を聞きながら何度も聞き直し鉛筆を走らせていた様子を見て、めちゃくちゃ大変だったのを見て(費用をかけずに)楽できないかと。
そこで、Whisperにひっかかりとりあえずやってみました。
使うもの
今回使うものはこちら
- Google Colaboratory
- Whisper
- 議事録のデータ
※音声はサンプル音声で検証しました。
セットアップ
新規ノートブックを作成
Google Colaboratory
Googleアカウントでログインすると使えます。
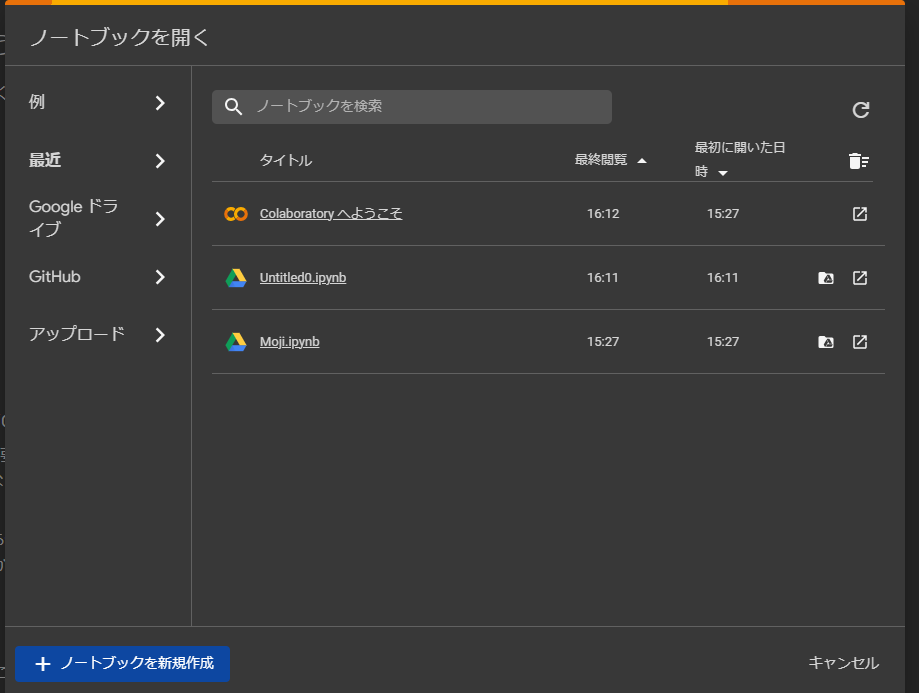
以下のような画面が出たら「ノートブックを新規作成」をクリック
ランタイムを選択
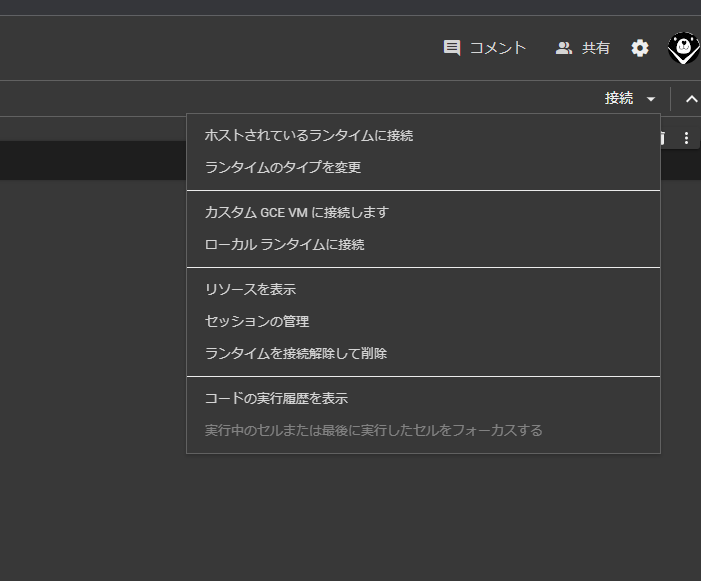
画面の右上側にある「接続」の横にある「▼」をクリックし、「ランタイムのタイプを変更」を選択します。
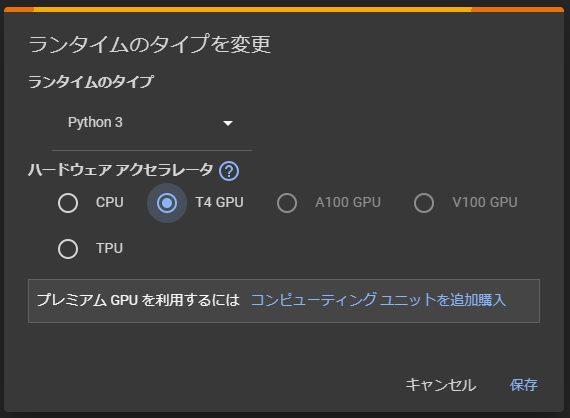
すると、以下の画面がでますので、「T4 GPU」を選択し、保存をクリックします。
起動
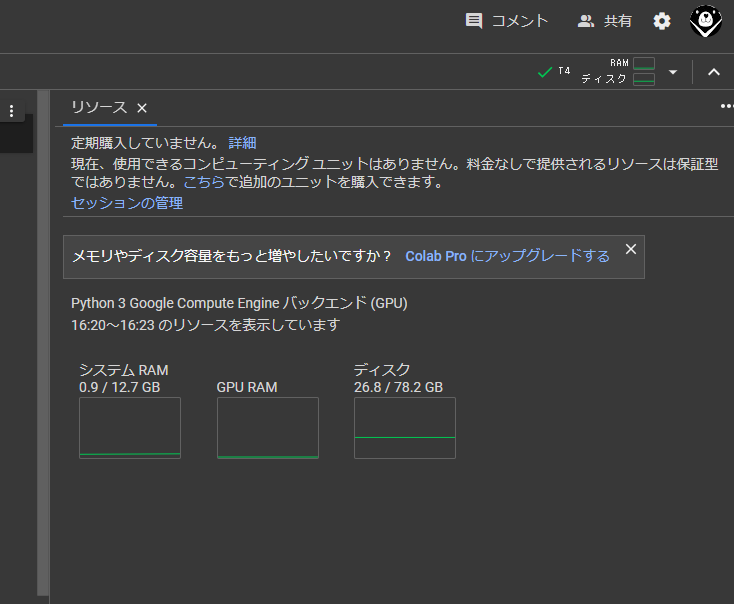
画面の右上側にある「接続」をクリックすると起動します。
裏側ではGCEが動いているようですね。
画面の右上側にある「接続」の横にある「▼」をクリックし、「リソースの表示」を選択するとリソースの状況が表示されます。
WhisperをInstall
画面中央に、コマンド入力する画面がありますので、Whisperをインストールしていきます。
以下のコマンドを入力して、実行ボタン( ▶ のボタン)を押してください。
!pip install git+https://github.com/openai/whisper.git
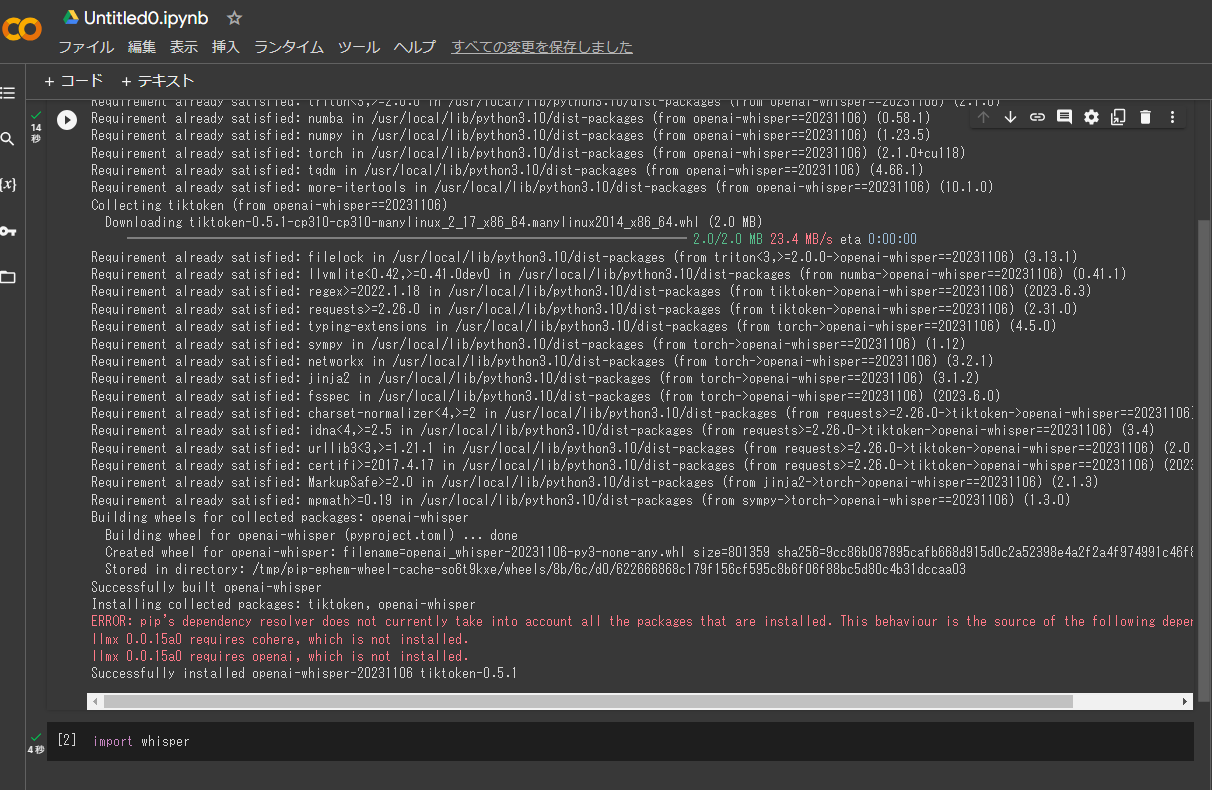
依存関係のエラーが出ましたが、一旦そのまま進めます。
次に、「+ コード」を押し、以下のコマンドを実行します。
import whisper
音声データのアップロード
画面左側のフォルダマークをクリックすると「Content」フォルダの下に「Sample_data」というフォルダが表示されております。
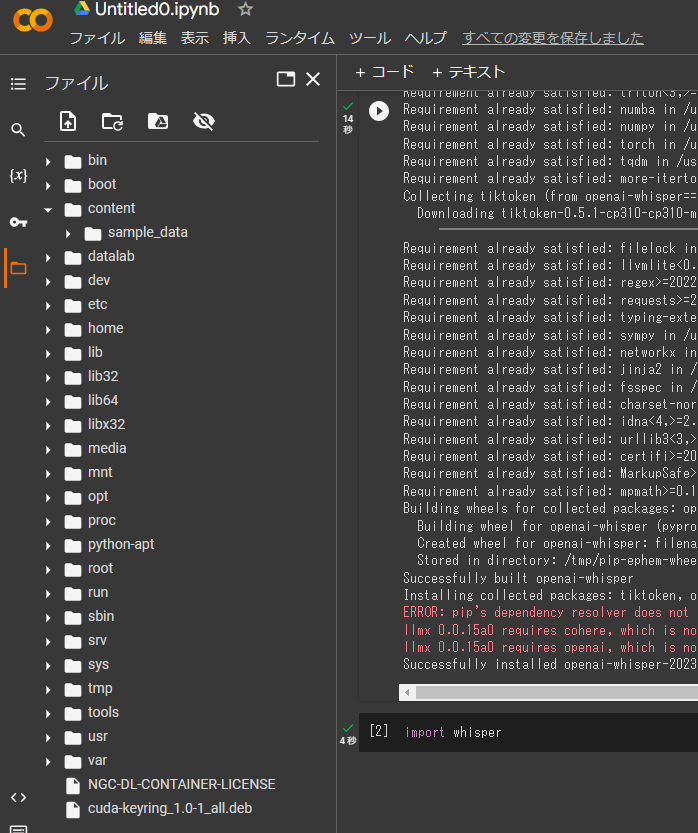
以下の図のように、音声データを「Content」フォルダの直下にアップロードします。
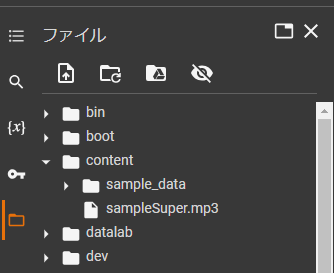
音声データをアップロードすると、最上位にアップロードされるようですので、ドラックアンドドロップで移動させればOKです。
Let's 文字起こし
音声データのアップロードまで完了しましたら、また「+ コード」を押し、以下のコマンドを実行します。
model = whisper.load_model("small")
result = model.transcribe("sampleSuper.mp3", verbose=True)
print(result["text"])
※verbose=True を追加すると、読み上げられた時間が表示されるようになりますので議事録的によさそうです。
modelの「base」はWhisperに書いていますが、5つのモデルが用意されておりlargeになるほど精度が良いようです。
しばらく待つと、以下のように文字起こしされております。
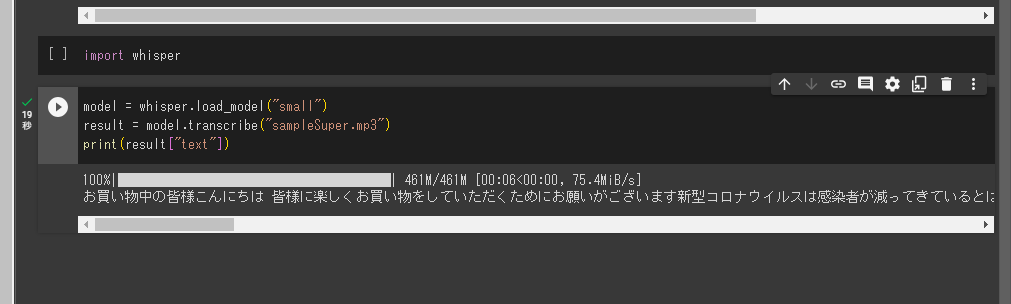
実際の出力結果
Detecting language using up to the first 30 seconds. Use
--languageto specify the language
Detected language: Japanese
[00:00.000 --> 00:10.000] お買い物中の皆様こんにちは 皆様に楽しくお買い物をしていただくためにお願いがございます
[00:10.000 --> 00:18.000] 新型コロナウイルスは感染者が減ってきているとはいえまだまだ収束したわけではありません
[00:18.000 --> 00:24.000] 感染が拡大しないようにできるだけマスクの着用をお願いします
[00:24.000 --> 00:31.000] ショッピングに夢中になっているとついつい人との距離感を忘れてしまいます
[00:31.000 --> 00:38.000] 密な状況を作らないようお互いの距離を保ってお買い物してください
[00:38.000 --> 00:44.000] 各店舗の入り口にはアルコール消毒液が設置されています
[00:44.000 --> 00:51.000] お買い物前とお買い物後には手指の消毒にご協力ください
[00:52.000 --> 01:01.000] マスクをつけていても人の多い売り場での席やすれ違い様の席は気持ちのいいものではありません
[01:01.000 --> 01:07.000] 席へつけとを守ってショッピングをお楽しみください
[01:07.000 --> 01:15.000] また新しい生活様式を実践するためスタッフ従業員の健康チェック
[01:15.000 --> 01:21.000] マスク着用こまめな手洗いうがい消毒の冷凍
[01:21.000 --> 01:24.000] 店舗内のこまめな換気
[01:24.000 --> 01:28.000] ずいしょに消毒用アルコールの設置
[01:28.000 --> 01:37.000] 密閉密集密接を避けるなど各店舗でさまざまな対応をしています
[01:37.000 --> 01:46.000] 今まで以上に気を引き締めてご自身やご家族大切な人を守る行動をお願いします
[01:46.000 --> 01:53.000] 感染拡大を防ぐためには皆さんお一人お一人の協力が必要です
[01:53.000 --> 01:58.000] マナーを守って楽しいお買い物を
[01:58.000 --> 02:02.000] 皆様のご理解ご協力をお願いいたします
お買い物中の皆様こんにちは 皆様に楽しくお買い物をしていただくためにお願いがございます新型コロナウイルスは感染者が減ってきているとはいえまだまだ収束したわけではありません感染が拡大しないようにできるだけマスクの着用をお願いしますショッピングに夢中になっているとついつい人との距離感を忘れてしまいます密な状況を作らないようお互いの距離を保ってお買い物してください各店舗の入り口にはアルコール消毒液が設置されていますお買い物前とお買い物後には手指の消毒にご協力くださいマスクをつけていても人の多い売り場での席やすれ違い様の席は気持ちのいいものではありません席へつけとを守ってショッピングをお楽しみくださいまた新しい生活様式を実践するためスタッフ従業員の健康チェックマスク着用こまめな手洗いうがい消毒の冷凍店舗内のこまめな換気ずいしょに消毒用アルコールの設置密閉密集密接を避けるなど各店舗でさまざまな対応をしています今まで以上に気を引き締めてご自身やご家族大切な人を守る行動をお願いします感染拡大を防ぐためには皆さんお一人お一人の協力が必要ですマナーを守って楽しいお買い物を皆様のご理解ご協力をお願いいたします
結構いい感じに文字起こしされましたね!
まとめ
まずは、目標であるお金をかけずに文字起こし出来る環境を作りたいは出来たのかなと思います。
自前のMacでWhisper + Docker環境でやったら、セグフォ発生して出来なかったのでお蔵入り
ただ、音声データ自体は2分くらいあるのですが、1:36くらいまでしか文字起こしされておりませんでした。
この辺は、調整が必要なのかもしれませんね。
また、今回初めてGoogle Colaboratoryを使ったのですが、無料で使えるなんてすごいですよね。
今後も色々と使っていきたいと思います:)