はじめに
本記事は「AWS EC2 × Zabbix監視基盤構築シリーズ」の第3回です。
以下の続きとなります。
- 第1回:『【構築ログ①】AWS EC2 × Zabbix監視基盤|IAMユーザーでEC2構築~SSH接続まで』
https://qiita.com/AWS_show/items/827c25c17d1b99da08e0 - 第2回:【構築ログ②】AWS EC2 × Zabbix監視基盤|Zabbix 6.0 をEC2に構築|ハマりポイントまとめ
https://qiita.com/AWS_show/items/1d57f767a9a66835b398
第3回では、Zabbix に監視設定を行い、
意図的に障害を発生させて、検知から復旧までを確認します。
構成の再確認
本シリーズでは、単一のEC2インスタンス上に
Zabbix Server / Agent を構築し、
監視データを CloudWatch Logs 経由で S3 に集約する構成を採用しています。

本記事では、単なる設定手順だけでなく、
実運用を想定したアラート挙動や障害検知の流れも確認します。
検証環境
本記事の検証は、以下の環境で実施しています。
| 項目 | 内容 |
|---|---|
| クラウド | AWS |
| サービス | EC2 |
| OS | Ubuntu Server 22.04 LTS |
| Zabbix | 6.0 LTS |
| Webサーバ | Apache |
| DB | MariaDB |
| PHP | Ubuntu標準(Apache連携) |
| リージョン | ap-northeast-1(東京) |
Zabbix Agentの設定
まずZabbixのエージェントが動いているか確認します。
systemctl status zabbix-agent --no-pager
activeを確認しました。

設定ファイルの変更
以下のコマンドで設定ファイルを確認します。
sudo vi /etc/zabbix/zabbix_agentd.conf
以下の項目を変更しました。
※Server,ServerActive,Hostnameはデフォルトの値です。
Server=127.0.0.1
ServerActive=127.0.0.1
Hostname=Zabbix server
設定ファイルに反映します。
sudo systemctl restart zabbix-agent
ポート10050が待受しているか確認
sudo ss -lntp | grep 10050
待受できていることが確認できました。

Zabbix UIでホスト登録
自身を監視する設定を行おうとしましたが、
初期状態ですでに「Zabbix server」ホストが登録されており、
テンプレートが適用された状態で監視が開始されていました。

確認のために、
設定 → ホスト とクリックしていきます。
現在、Zabbix serverのみを監視している状態です。

テンプレートとトリガー
Zabbix では、監視設定をテンプレートとしてまとめて管理することが一般的です。
テンプレートには、監視項目(アイテム)だけでなく、
トリガーやグラフなどの設定も含まれています。
本記事では、主にトリガー設定に着目し、
障害検知の挙動を検証していきます。
テンプレートについては補足として、
記事の最後にまとめています。
ディスクのトリガー設定
ディスクのアラート設定
対象:/(ルートファイルシステム)のディスク使用率
条件:使用率が 80% を超えた場合にアラートを発生
ディスク容量の枯渇はログ書き込み失敗や
サービス停止に直結するため、
優先度の高い監視項目として設定します。
トリガー作成画面を開く
設定 → ホスト
対象ホスト(Zabbix server)の「トリガー」をクリック
右上の [トリガーの作成] をクリック
名前: Disk usage on / is over 80% (custom)
深刻度: 警告
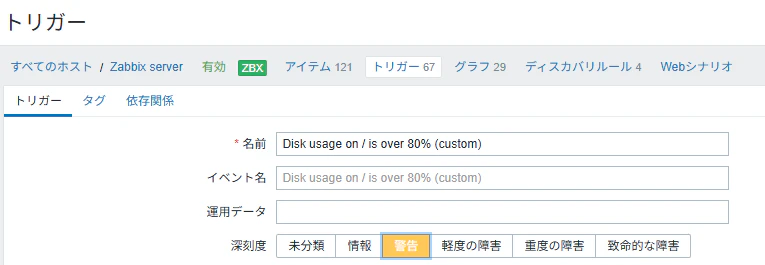
条件式の設定
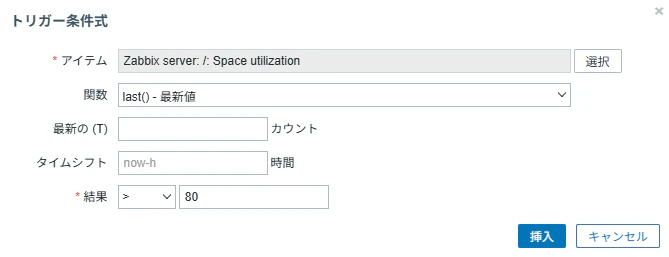
条件式 → 追加 → アイテムから選択
以下を選択します。
Zabbix server: /: Space utilization
結果の欄に以下を入力します。
> 80
「挿入」をクリック
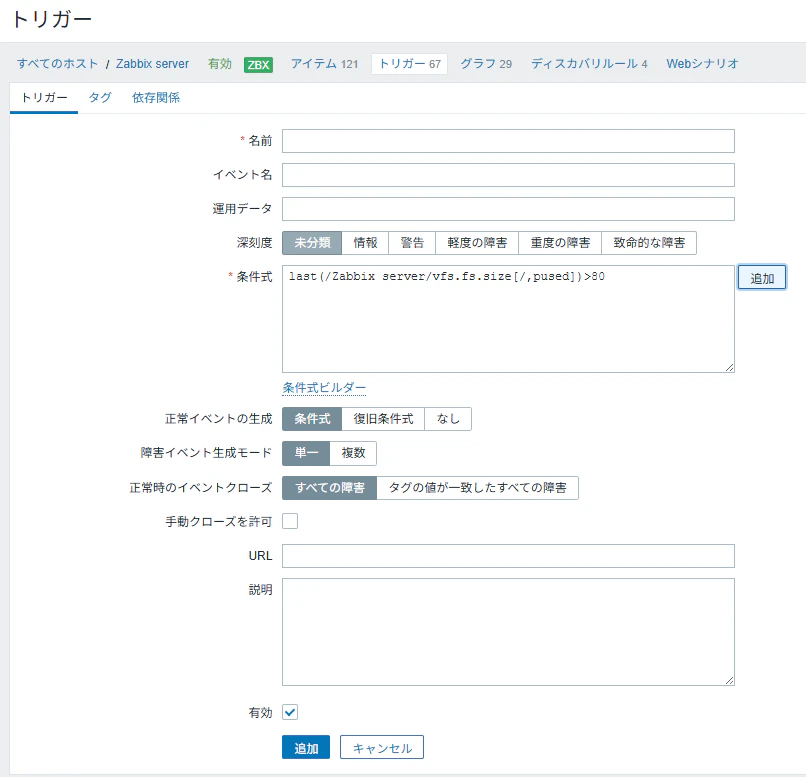
条件式の意味
この条件式は、Zabbix server ホストにおいて、
ルートファイルシステム(/)のディスク使用率の最新値が
80% を超えた場合に障害として検知する設定です。
追加をクリックして、トリガーを追加します。
トリガー発火テスト
目的
「80%超えたら検知」が本当に動くことを確認します。
やること
- ダミーファイルを作ってディスクを圧迫
- Zabbixで Warning が出るのを見る
- ファイル削除
- 自動で復旧(OKになる)ことを見る
今のディスク使用率を確認
df -h /
現在の使用率は42%。

テスト用ディレクトリの作成
後で、まとめて削除できるようにディレクトリを作成します
sudo mkdir -p /zabbix-test
sudo chown ubuntu:ubuntu /zabbix-test
ディスクを一時的に圧迫
fallocate -l 3G /zabbix-test/dummy.img
# 3GB のダミーファイルを作る
ディスク使用率を確認
df -h /
使用率は82%。
80%を超えました。

Zabbix UIで障害の検知が出ました。

ディスク復旧の確認
ダミーファイルを削除
sudo rm -f /zabbix-test/dummy*.img
ディスク使用率を確認
df -h /
42%になっています。

80%を下回ったため、Zabbix UIでは障害の検知が消えました。

復旧を確認済みにする
[監視データ] → [障害] → [問題の履歴]
先ほど発生した障害を選択します。

障害確認のチェックボックスにチェックを入れ、更新をクリック。

先ほどの障害が消えました。

CPUのトリガー設定
CPUトリガーの作成を行っていきます。
CPU使用率は一時的なスパイクが発生しやすいため、平均値(avg)を用いた検知とします。
先ほどと同様の手順でトリガー作成の画面まで進みます。
名前: CPU utilization is over 80% (custom)
深刻度: 警告
条件式の追加をクリック。
アイテムの選択をクリック。
その中から、
Zabbix server: Linux: CPU utilization を選択。
関数: avg()
最新の(T): 5m
結果の欄は、『>』『80』を入力
挿入 をクリック


CPU使用率トリガーの説明
CPUリソースの逼迫を早期に検知するため、
CPU使用率が高い状態が一定時間継続した場合に
警告を出すトリガーを設定しました。
本トリガーでは、
CPU utilization の 直近5分間の平均値 が
80% を超えた場合 に Warning として検知します。
一時的なスパイクによる誤検知を防ぐため、
最新値(last)ではなく平均値(avg)を用いており、
「CPU高負荷が継続している状態」を検知することを目的としています。
CPUトリガー発火テスト
先ほど設定したトリガーが有効になっていることを確認します。

CPU負荷ツールを準備
sudo apt update
sudo apt install -y stress
CPUに負荷をかける
stress --cpu 2
Zabbixで発火を確認
数分待つと、アラートが出ました。
CPUトリガーでは 5 分間平均(avg 5m)を使用しているため、
負荷発生直後にはアラートは表示されず、
一定時間高負荷が継続した後に Warning が発生したためです。
アラートが出たことから、一時的なスパイクではなく
継続的な高負荷状態を検知できる設定であることを確認できます。

stressを止めて、様子を見ます。
同時にtopコマンドを使用して、CPU使用率を確認しました。
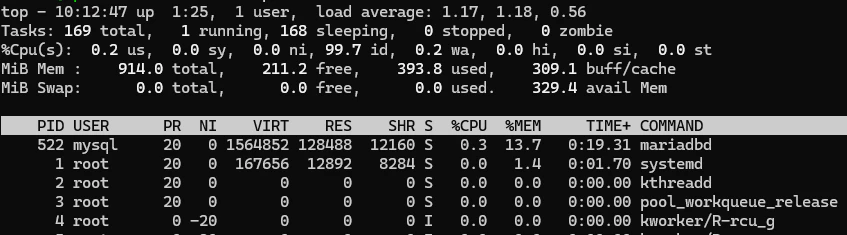
使用率は下がっていたので、いずれアラートは消えます。

CPU復旧の確認
[監視データ] → [障害] → [問題の履歴]
先ほど発生した障害の確認をします。

障害の確認が終わり、項目がなくなりました。

メールの受信確認について
本環境では SMTP(25/tcp) での直接送信がタイムアウトしたため、
送信制約を回避できる AWS SES を通知基盤として採用する方針としました。
AWS SES を用いた通知構成については、
次回の記事で構築および検証を行います。
今回の検証で学んだこと
- Zabbixではテンプレートを利用することで、
主要な監視項目を迅速に設定できる一方、
要件に応じてカスタムトリガーを追加することが重要である。
- トリガーは設定するだけでなく、
実際に発火テストと復旧確認を行うことで、
初めて運用可能な設定となる。
- AWS環境ではメール送信に制約があるため、
監視通知は SES などの外部サービスと
連携する前提で設計する必要がある。
まとめ
Zabbix でディスク使用率のトリガーを設定し、
意図的にディスク圧迫および CPU 負荷を発生させることで、
障害検知から復旧までの一連の動作を確認しました。
本検証により、
監視設定は「設定すること」ではなく、
「検知・通知・復旧までを含めて設計すること」が重要であると理解しました。
次回は、CloudWatch Logs に出力されたログを対象に、
EventBridge を使用して 1 日 1 回 S3 へエクスポートする構成を検証します。
【補足】 Zabbixのテンプレートとは?
監視設定のひな型セット
このサーバでは何を、どうやって、どのくらいの頻度で、
どんな条件でアラート出すか
これらを 全部まとめた設計書+設定集 がテンプレートです。
テンプレートを確認
以下の2つのテンプレートが使用されています。
- Linux by Zabbix agent
- Zabbix server health

つまりLinux by Zabbix agent と Zabbix server health
2つのテンプレートを使用して監視しています。
主要なデータ
いくつかの主要なデータを見てみる。
[監視データ] → [最新データ]
CPU utilization
CPUの使用率(%)を示す指標。
サーバがどの程度CPUリソースを消費しているかを把握できる。
高い状態が継続する場合、アプリケーションの負荷増大や
処理遅延の原因となるため、継続監視が重要となる。

Available memory
OSが即座に利用可能なメモリ量を示す指標。
Linuxではキャッシュやバッファも考慮されるため、
単純な「空きメモリ」よりも実際の余裕を把握しやすい。
この値が極端に少なくなると、スワップ発生や性能低下のリスクが高まる。

Disk utilization
ファイルシステムごとのディスク使用率(%)を示す指標。
ディスク容量の逼迫はアプリケーション停止や
ログ書き込み失敗の原因となるため、注意が必要である。

Load average (1m avg)
直近1分間の平均負荷を表す指標。
CPUコア数に対して値が大きい場合、
プロセスの待ち行列が発生している状態を示す。
CPU使用率と併せて確認することで、
処理詰まりやリソース不足の判断材料となる。

これらのメトリクスを組み合わせて確認することで、
単一指標では判断しづらいサーバの負荷状況を多角的に把握できる。