1. はじめに
ATLシステムズの田中です。
現在弊社では、Azure Synapse Analyticsというデータレイク上のDWH製品を開発で一部使用していますが、近年のHDFS群において、ベンダーロックの問題をネットの記事でよく見かけるようになったため、いくつかのクラウドベンダがサポートしている類似製品であるDatabricksを例に焦点を当てようと思った次第です。
本記事ではCSVファイルをDelta Lake※1というParquet※2をさらに改良した高圧縮の状態で保存する方法(おおよそ1/7程度) を共有したいと思います。
※1 Delta Lake…parquet形式をさらに改良したデータフォーマット。
概要は、 Delta Lake とは何か(ktksq様) をご参照ください。
※2 Parquet…csvより圧縮効率の良いデータフォーマット。
圧縮効率については、Sparkでファイル形式や圧縮形式について実験したの記事をご参照ください。
※免責事項(必ず、ご一読ください)
本記事の情報により生じた、いかなる損害や損失についても、当社は一切の責任を負いかねます。
本記事は、弊社としての見解ではなく、投稿者個人の見解となります。
また、誤情報が入り込んだり、情報が古くなったりすることもあり、必ずしも正確性を保証するものではありませんので、ご了承ください。
2. 紹介範囲
本記事で紹介する範囲のデータフローは下記となります。
今回は下記図のように、ADLS Gen2およびPremium版のDatabricksがデプロイされ、DatabricksのVMクラスターがデプロイされ、稼働している前提で執筆しています。
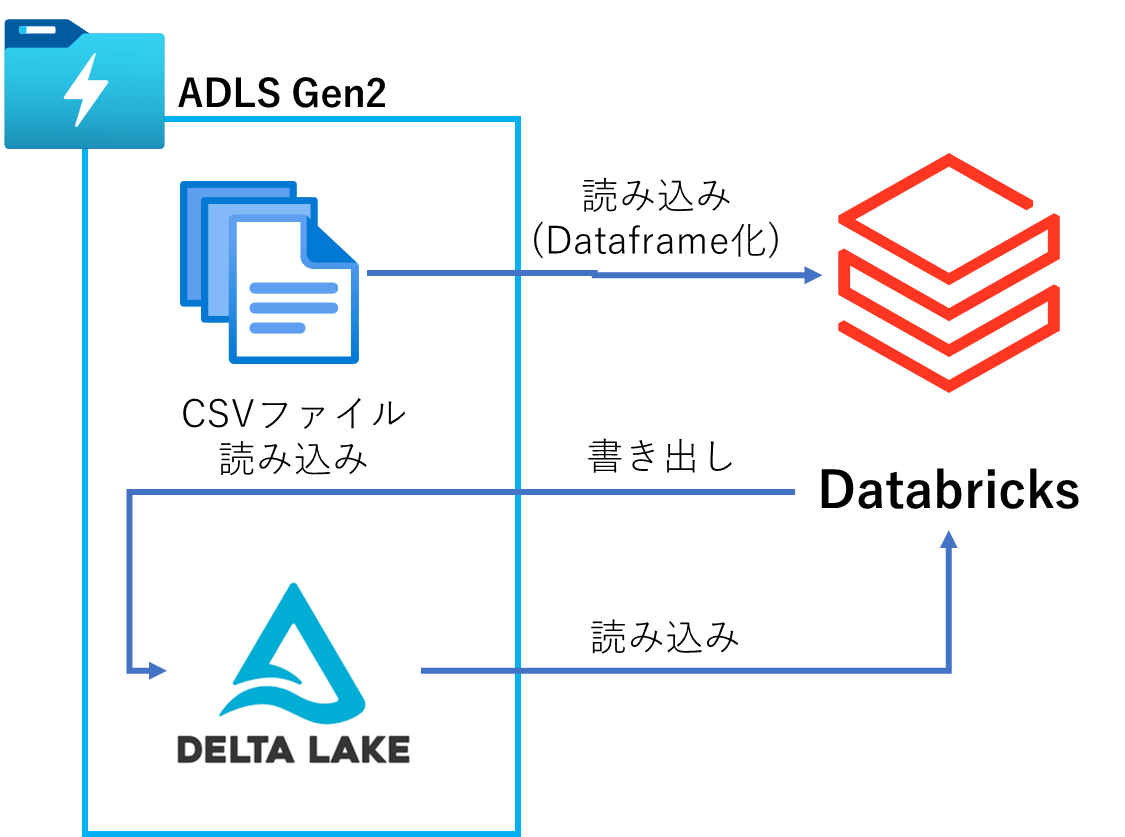
※Databricksでクラスターをデプロイする際、デフォルトの名前が、xxxxx's Clusterような名前でもしセットされている場合、デプロイに確実に失敗しますので、特殊記号 ' を除去した名前としてからデプロイをお勧めします。
NG

OK

3.データソース
こちらのページの「一括ダウンロード」をクリックすることにより、各都道府県単位ならびに全国単位の延べ宿泊者数のデータを、1つのCSVへ一括してダウンロードができます。
ADLS上へ、上記のダウンロードしたTimeSeriesResult_~.csvを、ADLS上へAzurePortalより、アップロードします。
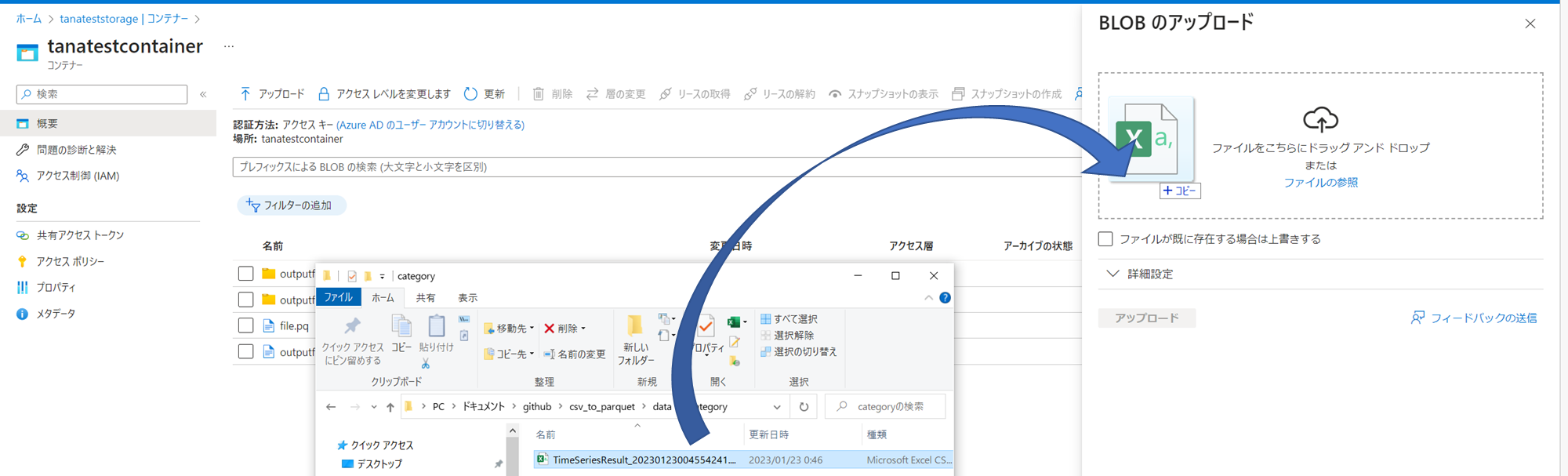
以下、Azure DatabricksのNotebook(python)上のpyspark(ライブラリ)でのADLS上のCSVファイルの読み出しおよびDelta Lakeへの書き込み方法します。
4.ADLSのマウント
まず、Databricks上でADLS上のファイルへアクセスできるように、linuxのようにマウントします。
・ソース
# ADLSのマウントに必要なパラメータのセット
storage_account_name = "tanateststorage"#対象のADLSのストレージアカウント名に置き換えること
container_name = "tanatestcontainer"#対象のADLSのコンテナー名に置き換えること
mount_name = "tanatestmountpoint"#任意のマウント名に置き換えること
storage_account_key = "ストレージアカウントの接続文字列"
# unmount(既にマウントされていた場合、同一名のものアンマウント)
dbutils.fs.unmount(
mount_point = "/mnt/" + mount_name,
)
# mount
dbutils.fs.mount(
source = "wasbs://" + container_name + "@" + storage_account_name + ".blob.core.windows.net",
mount_point = "/mnt/" + mount_name,
extra_configs = {f'fs.azure.account.key.{storage_account_name}.blob.core.windows.net': storage_account_key }
)
mount_point = "/mnt/" + mount_name
dbutils.fs.ls(mount_point)
・結果

5. CSVからdfへの読み込み
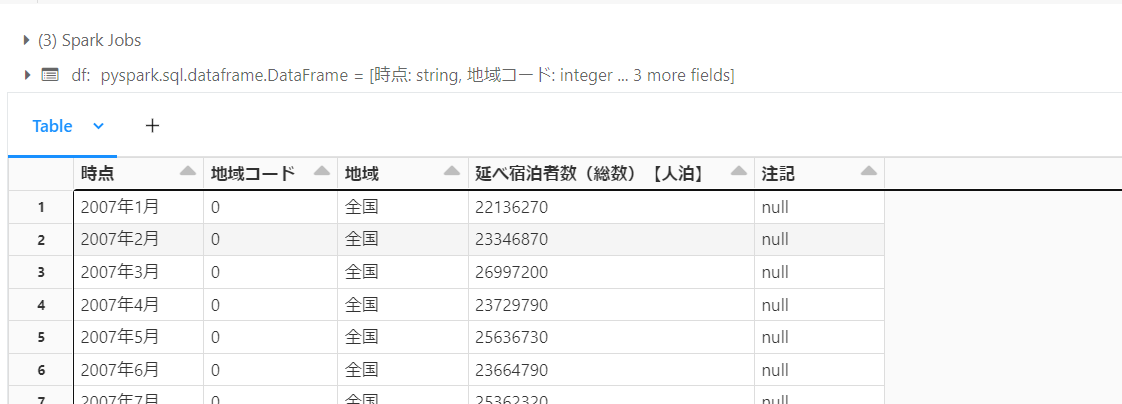
アップロードしたCSV形式のファイルを読み、そのCSVのスキーマにあったdfを生成しデータを読み込みます。
・ソース
# ADLSのcsvからdfへの読み込み
filename = "TimeSeriesResult_20230123004554241.csv"
filelocation = mount_point + "/" + filename
df = spark.read.format("csv").option("header",True).option("inferSchema", "true").load(filelocation)
display(df)
(元ファイルの列定義に従いdfを自動で生成)
結果
6. dfからDelta Lakeへの書き込み
dfからDelta Lake形式のファイルへ書き出します。
・ソース
# dfからADLSのDelta Lakeへの書き込み
from pyspark.sql.functions import col
filename = "outputfile.delta"
file_location = mount_point + "/" + filename
df.write.format('delta').mode('overwrite').save(file_location)
・結果

7. Delta Lakeからのdfへの読み込み
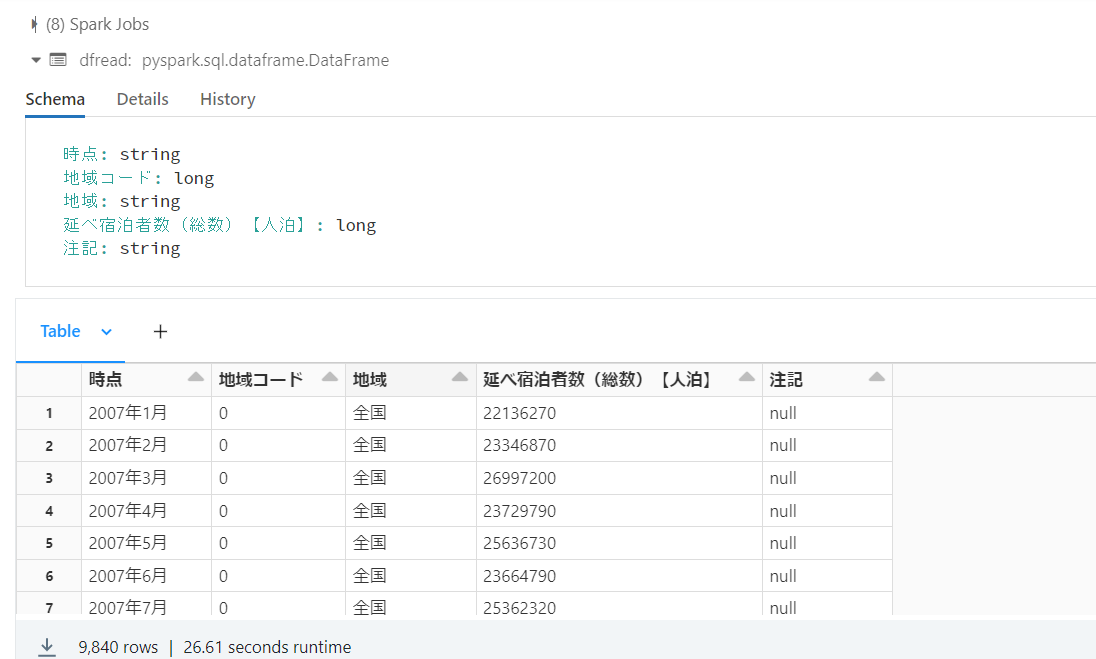
先ほど書き出したDelta Lake形式からdfへ読み込みます。(読めることの確認の意図です。)
・ソース
# ADLSのDelta Lakeからdfへの読み込み
dfread = spark.read.format("delta").option("header",True).option("inferSchema", "true").load(file_location)
display(dfread)
・結果
無事、Delta Lake形式からdataframeとして読み込めました。
8. 一連の書き出し後のADLSの様相
下記が、一連の作業が終わった後のADLSの様相です。どうもDelta Lakeは、下記の2つのフォルダ+1つのdeltaの拡張子をもつファイルとして保存されるようです。
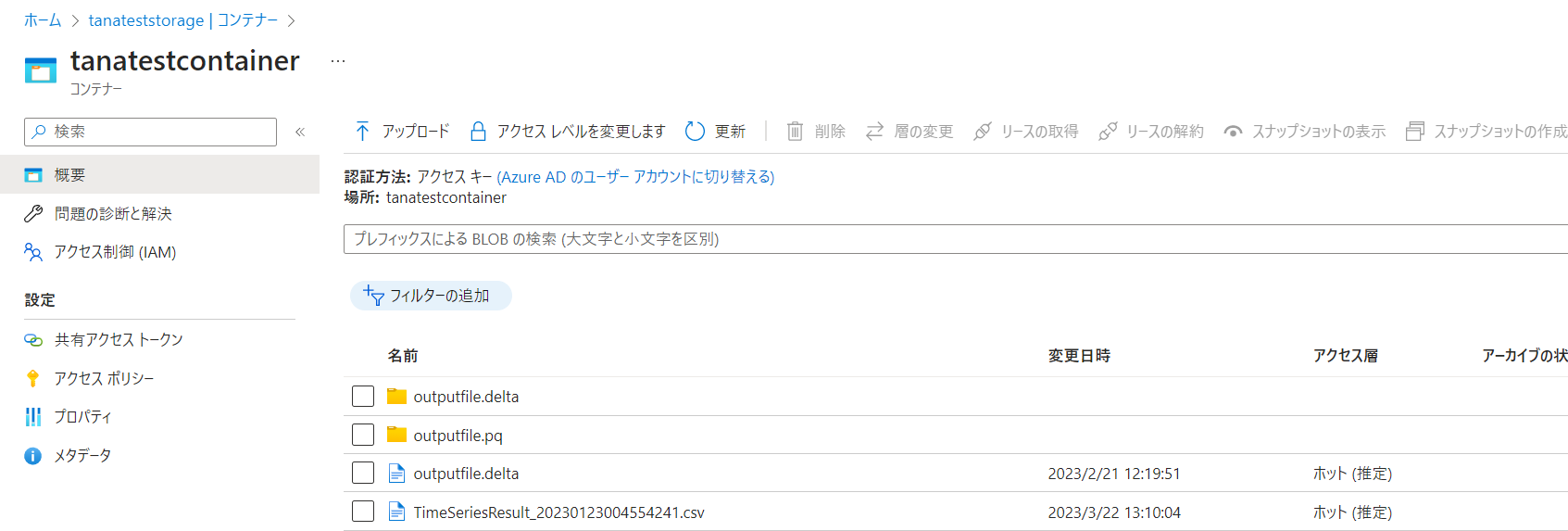
9.おまけ(集計)
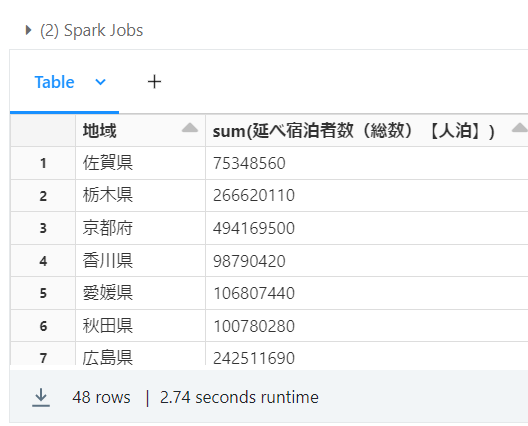
・ソース
# 集計
display(df.groupBy("地域").sum("延べ宿泊者数(総数)【人泊】"))
・結果
10. 最後に
上記の一連の作業により、CSVからDeltaLakeまで高い圧縮状態で保存し、取り出しし、集計できることまで確認できました。
Databricksといったクラウド上のDWHに限定されない、VMなど使ったマルチプラットフォームな環境でpysparkなど互換性でより自由かも....?等々、いろいろ思案することができました。
最後まで読んでいただき、ありがとうございました!
余談ですが、弊社はfacebookもしております!

今回紹介したすべてのコードを1つにまとめたnotebookを下記に記載しておきます。
from pyspark.sql.functions import col
# ADLSのマウントに必要なパラメータのセット
storage_account_name = "tanateststorage"#対象のADLSのストレージアカウント名に置き換えること
container_name = "tanatestcontainer"#対象のADLSのコンテナー名に置き換えること
mount_name = "tanatestmountpoint"#任意のマウント名に置き換えること
storage_account_key = "ストレージアカウントの接続文字列"
# アンマウントt(既にマウントされていることも想定し、同一名のものアンマウント)
dbutils.fs.unmount(
mount_point = "/mnt/" + mount_name,
)
# マウント
dbutils.fs.mount(
source = "wasbs://" + container_name + "@" + storage_account_name + ".blob.core.windows.net",
mount_point = "/mnt/" + mount_name,
extra_configs = {f'fs.azure.account.key.{storage_account_name}.blob.core.windows.net': storage_account_key }
)
# ADLSのcsvからdfへの読み込み
filename = "TimeSeriesResult_20230123004554241.csv"
filelocation = mount_point + "/" + filename
df = spark.read.format("csv").option("header",True).option("inferSchema", "true").load(filelocation)
display(df)
# dfからADLSのDelta Lakeへの書き込み
filename = "outputfile.delta"
file_location = mount_point + "/" + filename
df.write.format('delta').mode('overwrite').save(file_location)
# ADLSのDelta Lakeからdfへの読み込み
dfread = spark.read.format("delta").option("header",True).option("inferSchema", "true").load(file_location)
display(dfread)
#集計
display(df.groupBy("地域").sum("延べ宿泊者数(総数)【人泊】"))