1. はじめに
ATLシステムズの田中です~。
本記事では、Azure Cosmos DBにdtui.exeというツールを使ってJSONのインジェストをする方法を紹介します。
経緯として、Azure Cosmos DB SQL/Core APIで、GROUP BYや、ORDER BYといったステートメントがどのように書けば動作するのかを検証するにしても、Azure Cosmos DBにコンテナーをどのように作り、どのようにJSONデータを入れられるのか、を知る必要があったため、本記事にまとめた次第です。
※免責事項(必ず、ご一読ください)
本記事の情報により生じた、いかなる損害や損失についても、当社は一切の責任を負いかねます。
また、誤情報が入り込んだり、情報が古くなったりすることもありますので、必ずしも正確性を保証するものではありませんのでご了承ください。
2. 概要図

3. 結果
完成したGROUP BYと、ORDER BYを合わせた集計クエリは下記のようになりました。
SELECT * FROM (SELECT v.名前,count(v.名前) FROM Votes as v GROUP BY v.名前) as view ORDER BY view.名前
※本記事のデータは**疑似個人情報生成サービス**から生成したものです。

どうも、副問い合わせの形式にしないと、ORDER BYがうまく解釈されないようで、下記のようになります。

4. データの用意
・今回は、前回の**大量テストデータの生成(SQL Server)で取り込んだデータをFOR JSONクエリを用いて、1つのJSONにして、dtui.exeを使い、Azure Cosmos DBに取り込みます。シチュエーションは、手元に大量のJSON形式のレコードをもつファイルがある場合を想定しています。
※データ元はこちらの疑似個人情報生成のWebサービスから生成したものです。(疑似個人情報生成サービス**)
・SQLの実行結果を右クリックし「結果に名前を付けて保存(V)」をして、test.jsonなど任意の名前を付け、.json形式で保存します。

5.Dtuiのインストール
・こちらからダウンロードできます。
Azure DocumentDB Data Migration Tool
・zipが手に入るので、dt-1.7を使いたい任意の場所で展開してください。

・dtui.exeを選択して起動します。Nextを押します。

6. データクレンジング
データにはいろいろとごみが混ざっていることがありますので、dtui.exeでjsonファイルを取り込む前に、まずはデータクレンジングをします。
FOR JSONで変換すると、下記をする必要があります。
・余分な行頭の削除(必須)
jsonファイルとして正しい形式にするために、行頭1行を削除します。

・半角空白、改行記号の削除
列が文字列型(nvarchar(24)等)の場合、半角埋めでバイト数分(この場合24byte分)きっちり埋めて出力してしまうため、空文字を除去する必要があります。そこで、高機能エディタの置換機能で、不要な文字を空文字に置換して削除します。
例:サクラエディタの置換の場合(正規表現オン)

※あまりにファイルサイズが大きい場合、エディタで開けないことあるので、エディタのGrep置換機能や、linuxOSの置換クエリsedなどを使用することをお勧めします。
7. データベースとコンテナーの作成
以下の内容で作成します。

データベース**"Tohyo"名前をパーティションキーとする、空のコンテナー"Votes"**が出来上がりました。
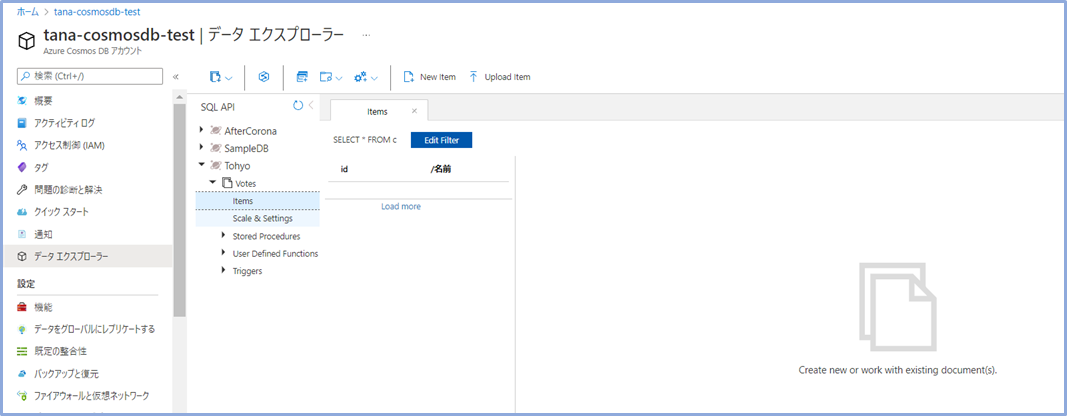
8. Dtui.exeからのインジェスト
・jsonファイルの指定
先ほど開いたdtui.exeで、先ほどデータクレンジングしたtest.jsonを指定します。

・Import from
入力元のリソースを指定します。
今回は、**JSON file(s)**を指定します。
※実はSQLを指定して、SQL Serverから移行することができますが、シチュエーションから外れるため、今回はSQLは指定しません。
Add Filesからjsonファイルを選択したらNextを押します。
・接続の設定
・Export to
今回は、デフォルトのDocumentDB - Sequential record import (partitioned collection)を選択します。

・Connection String
Azure Cosmos DBの接続文字列と、データベース名を設定します。
Connection Stringの欄は、以下を読むと、

とあるので、それを満たす形式の接続文字列を取得するため、一旦Azure Portalを開き、Azure Cosmos DBのリソースのキーを開きます。

プライマリー接続文字列が当たるので、コピーして欄に張り付けます。
次にデータエクスプローラーからコンテナーの名前を確認します。
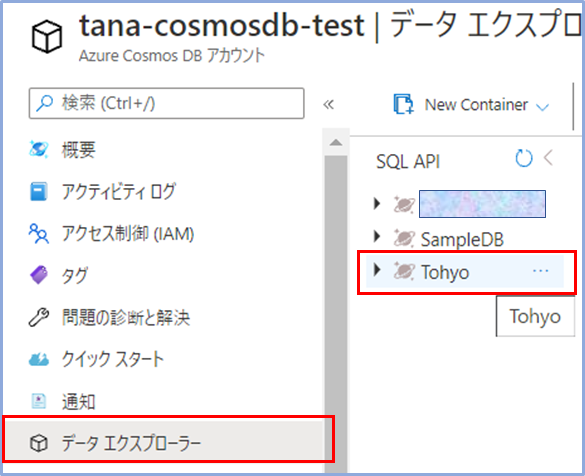
今回、Tohyoコンテナーに入れたいため、ConnectionStringには、プライマリ接続文字列+Database="Tohyo"として以下のようにセットします。
AccountEndpoint=エンドポイント;AccountKey=アカウントキー;Database="Tohyo"
左のVerirfyボタンを押して、以下のダイアログが出れば、Azure Cosmos DBとの接続が成功です!

→設定したらOKをクリック。
・その他項目の設定
下記のように設定します。
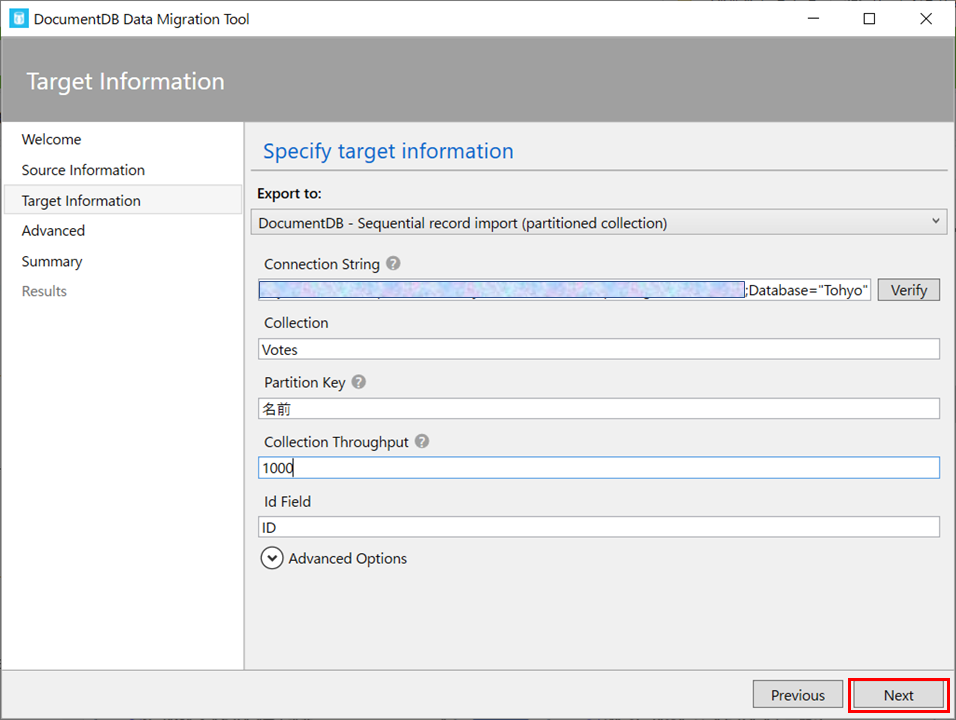
・Collection…インジェスト先のコンテナー(Container)の名前を指定
今回は、"Votes"を指定します。
・Partitiion Key…コンテナー作成時に設定したパーティションキーを指定
今回の入力データでは、場合は投票先の「名前」の列ごとに分割するのが望ましいので、"名前"を指定します。
処理の内部的な並列化をするのに適当な単位(例えばカテゴリ単位や市町村単位など)が望ましいので、そのようなプロパティをセットしてあげます。(詳しくはAzure Cosmos DB でのパーティション分割と水平スケーリングを参照)
・Collection Throughput…インジェストに使うRU/回を指定(詳しくはAzure Cosmos DB の要求ユニットを参照)
・Id Field…今回の入力データの主キーとなる"ID"を指定します。
→設定したらNextをクリック。
・エラーログ出力先の設定
以下のように設定します。

・Error Log File…ログ出力先のファイルパスを指定
・Detailed Error Information…エラーログファイルに出力する、情報のレベルを指定します。
今回は、失敗した場合がわかればよいので、"Critical"を指定します。
・Progress Update Interval…進捗状況の更新頻度を指定します。
今回は、1秒おきに画面更新させるため、デフォルトの"00:00:01"を指定します。
→設定したらNextをクリック。
・実行前確認
実行する内容が表示されます。Importを押すと、Azure Cosmos DBへのインジェストが開始されます。

・実行結果確認
・dtui.exeから
以下のようにImport resultsにFailed:が0と表示されていれば、成功です。

・Azure Portalから
赤枠をクリックしていき、itemsの中のレコードを開いてみます。

無事データが入っていますね。(^^)b
データが入っていることを確認したら、Azure Portal上よりクエリを作成して実行してみます。
9. クエリ動作確認
・クエリの実行窓を開く
New SQL Queryより、クエリの実行窓を開きます。

・クエリの作成
下記のMicrosoftのリファレンスを参考にしながらクエリを組み立てます。
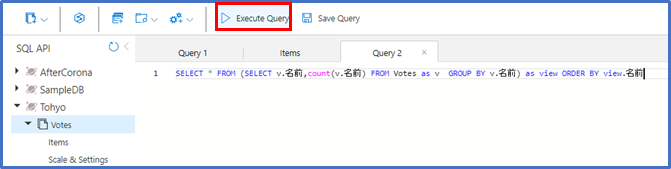
赤枠の、Execute Queryを実行します。(私はよくSSMSを使っているので、F5を押してしまいますが、ウェブブラウザでは更新となってしまうため、くれぐれもF5を押さないように!!
#3 結果のようになるはずです。
以上です!!おつかれさまでした!
10. 参考資料
- FOR JSON を使用してクエリ結果を JSON として書式設定する (SQL Server)
- Azure DocumentDB Data Migration Tool
- Azure Cosmos DB での GROUP BY 句
- Azure Cosmos DB での ORDER BY 句
11. 最後に一言
無事クエリの検証をすることができました。 最後まで読んでいただき、ありがとうございました!
今後もいろいろとAzure周りや、その他の面白そうな技術について投稿していきます。
余談ですが、弊社はfacebookもしております!
