
こんにちは! AI開発スタートアップでエンジニアをしている明生 です。
2025年11月、Metaから突如としてリリースされた 「SAM 3 (Segment Anything Model 3)」。皆さんはもう試されましたか?
「SAM 2が出たばかりじゃなかったっけ?」 「今度は何ができるようになったの?」
そんな疑問をお持ちの方も多いはずです。実は今回のSAM 3、単なる精度の向上やマイナーチェンジではありません。これまでの「クリックして切り抜く」体験を過去にする、真の「マルチモーダル・セグメンテーション」 への進化を遂げています。
今回は、公式GitHubやHugging Faceの情報を元に、SAM 3の凄さをどこよりも分かりやすく解説します。さらに、記事の後半では 当社がいち早く成功させた「Ryzen AI 395+ Max」を用いたローカル実装 についても、開発画面をチラ見せしながらご紹介します。
そもそも「SAM」とは?(おさらい)
これまでのSAM(Segment Anything Model)の歴史を少し振り返りましょう。
-
SAM 1 (2023年): 画像内のあらゆる物体を「クリック」や「ボックス」で切り抜けるゼロショットモデルとして登場。セグメンテーションタスクの常識を覆しました。
-
SAM 2 (2024年): 画像だけでなく「動画」に対応。フレームを跨いで物体を追跡(トラッキング)できるようになり、映像編集や解析の幅が広がりました。
そして、今回の SAM 3 です。
SAM 3 のここが革命的! 3つの進化ポイント
公式リポジトリ(facebookresearch/sam3)やデモを確認すると、その進化の方向性は明確です。
1. 「言葉」で指示すれば、すべて切り抜ける (Open Vocabulary)
これが最大のアップデートであり、エンジニアとして最も興奮するポイントです。 これまでのSAMは、基本的に「ここ」と場所を指定(クリックやボックス指定)する必要がありました。しかし、SAM 3は テキストプロンプト をネイティブに理解します。
例えば、街中の映像に対して:
-
「赤い車 (red car)」 と入力するだけで、画面内の全ての赤い車を検出し、マスクを生成します。
-
「黄色いスクールバス (yellow school bus)」 と言えば、それを即座に特定・追跡します。
これは、検出(Detection)、セグメンテーション(Segmentation)、追跡(Tracking)が完全に統合されたことを意味します。もはや「どこにあるか」を人間が教える必要はありません。AIが言葉の意味を理解し、視覚情報と結びつけるのです。
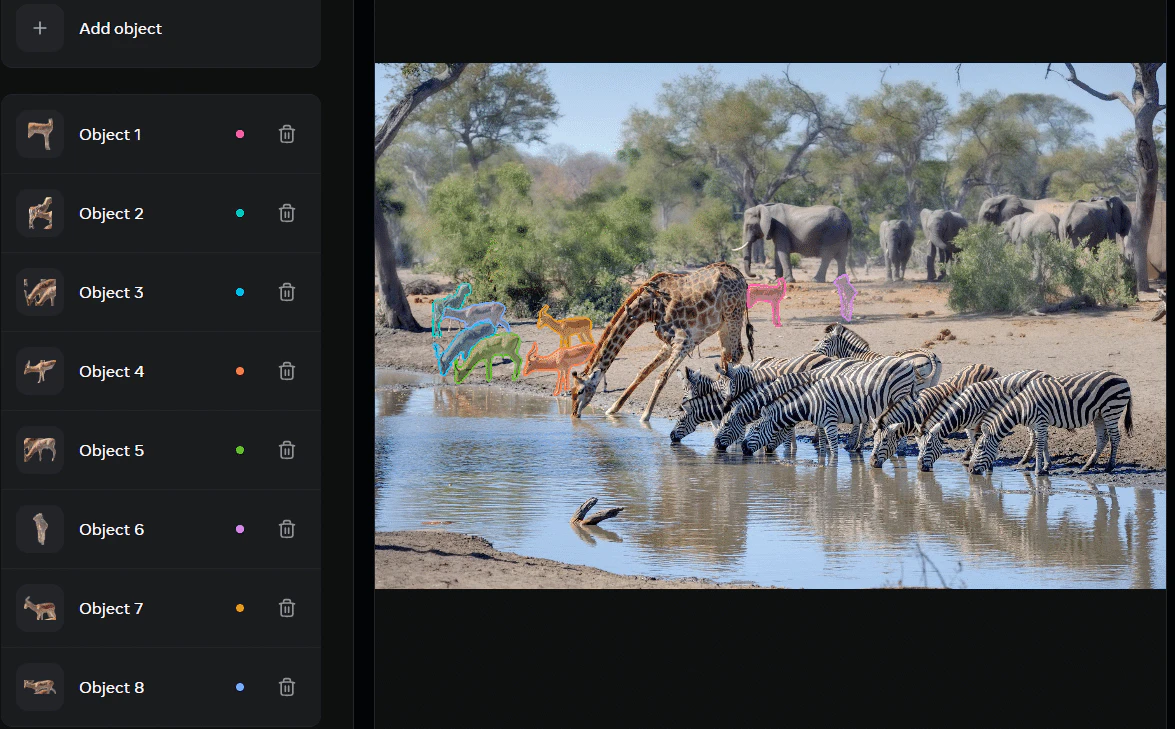
「インパラ」とテキスト入力すれば、インパラだけ抜き出す
2. 画像・動画・3Dを横断する「汎用ビジョン基盤」
SAM 3は、静止画と動画の壁を完全に取り払いました。 共通のビジョンバックボーン(Vision Backbone)を使用することで、動画の各フレームでの物体検出と、時間軸に沿った追跡を一貫して行います。
さらに注目すべきは 3D再構成(3D Reconstruction) への対応です。 「SAM 3D」とも呼ばれる機能により、2Dの画像や動画から対象物を切り抜くだけでなく、その立体的な形状を推定するタスクにも応用が可能になりました。これにより、XR(AR/VR)開発やロボティクスの分野での活用が一気に現実的になります。
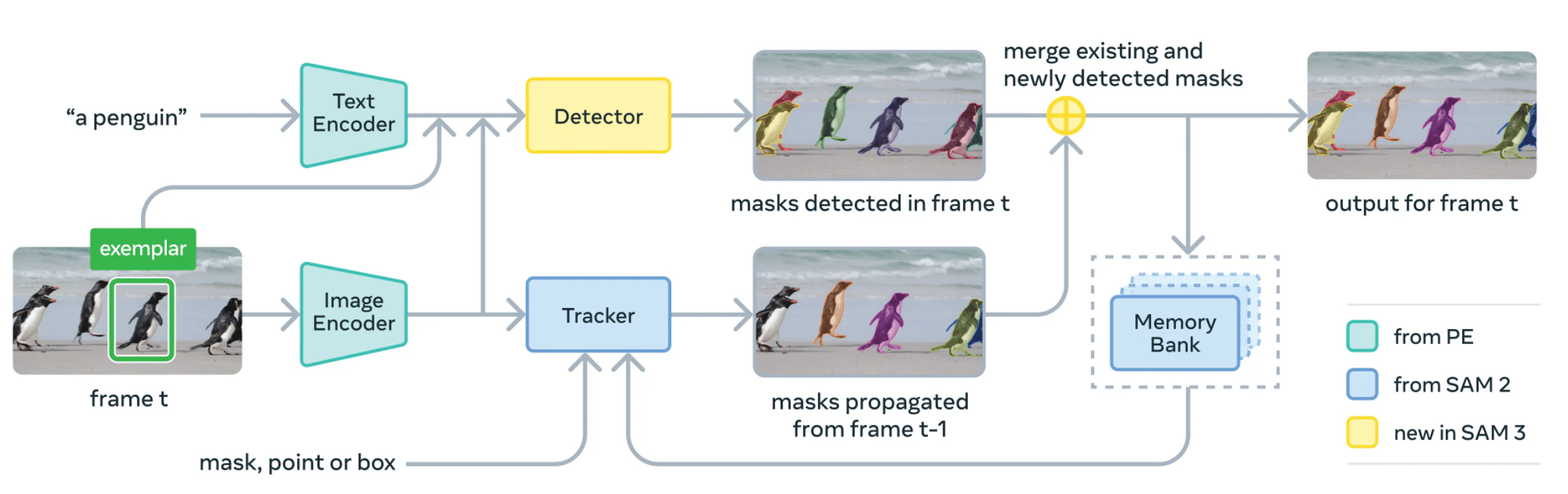
画像、動画、そしてプロンプト入力を統合処理するSAM 3のアーキテクチャ
(Source: Meta AI GitHub)
3. 驚異的な処理効率と軽量化
高機能化すると重くなるのがAIの常ですが、SAM 3は推論効率も最適化されています。 Metaが公開したベンチマーク「SA-Co Dataset」においても、従来モデルを凌駕する精度を出しつつ、エッジデバイスでの動作も視野に入れた設計がなされています。
スタートアップ視点:なぜ SAM 3 が重要なのか?
私たちのようなAIスタートアップにとって、SAM 3の登場は 「開発スピードの劇的な向上」 を意味します。
従来、特定の物体(例えば工場の特定の部品や、農作物の特定品種)を検知するには、大量の教師データを用意して専用モデル(YOLO等をファインチューニング)を作る必要がありました。
しかし、SAM 3の オープンボキャブラリー能力 を使えば、「傷ついた部品」や「熟したトマト」というプロンプトを与えるだけで、ゼロショット(追加学習なし)で高精度な検出・切り抜きが可能になるのです。
これは、PoC(概念実証)の期間を数ヶ月から 「数日」 に短縮するポテンシャルを秘めています。顧客への提案スピードが命であるスタートアップにとって、これほど強力な武器はありません。
Sneak Peek: 自社でのローカル実装事例
さて、ここからは少しマニアックな話になりますが、当社のラボでは早速 SAM 3 のローカル実装を行いました。 クラウドAPI経由ではなく、オンプレミスで動かすことは、セキュリティやレイテンシ、コストの観点から非常に重要です。
使用したハードウェアは、話題のモンスター級APU 「AMD Ryzen AI Max+ 395」 です。
-
CPU: 16コア Zen 5 (Strix Halo)
-
Memory: 128GB LPDDR5x(8000MT/s)
-
Overall TOPS: 最大126 TOPS
通常、SAM 3のような巨大モデルを快適に動かすには、高価なH100などのGPUサーバーが必要と思われがちです。しかし、ユニファイドメモリという設計による大規模なメモリ量のRyzen AIマシンを使うことで、クラウドにデータを送信することなく、ローカル環境でサクサクとSAM 3を動かすことに成功 しました。
ただし**「AMD Ryzen AI Max+ 395」**の大きな特徴はユニファイドメモリなので、gpt-oss-120bなど多くのメモリを必要としてローカルで安価に走らせる用途に向いていますが、今回のような軽量メモリ+速度が求められるような用途には、素直にnvidia(コンシューマー向けGPU含む)の方が適していると思います。
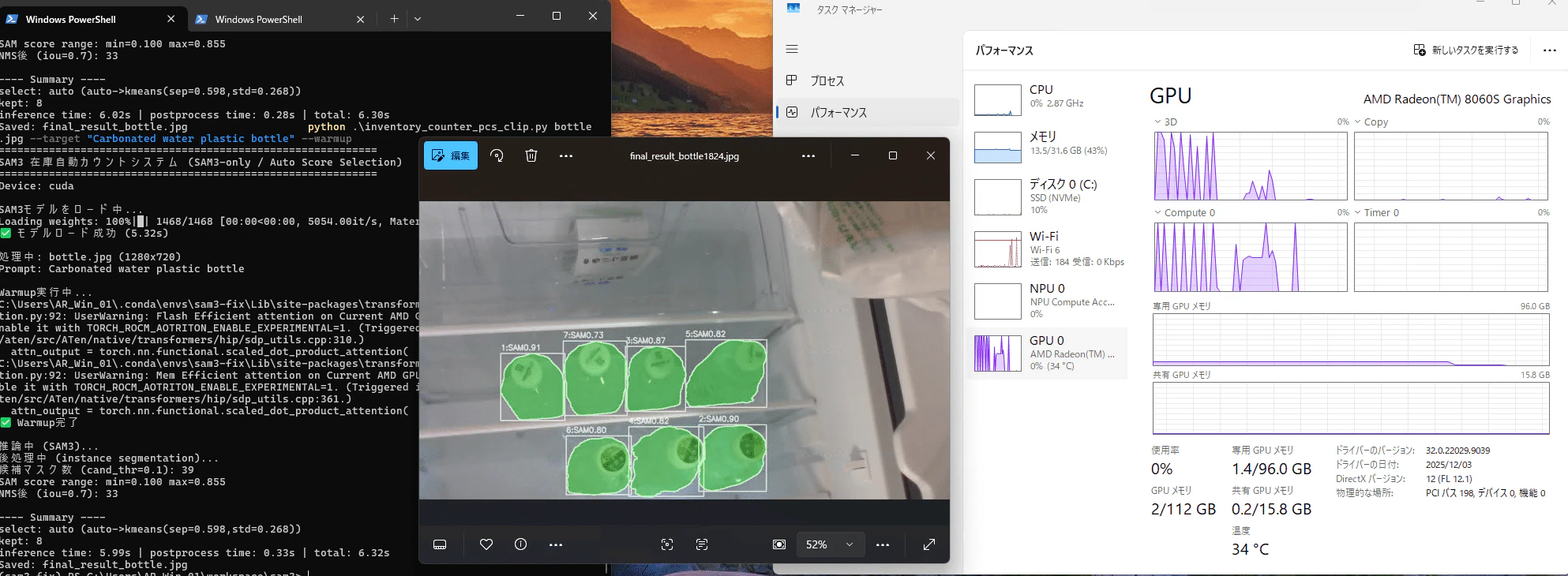
Ryzen AI 395+ MaxにてSAM 3をローカル実行中。推論も非常に高速
現在、このシステムをIoT機器(エッジカメラ)と連携させ、リアルタイムで「言葉で指定して検知する」システムを開発中です。
この 「SAM 3 × Ryzen AI 395+ Max × IoT」 の具体的な実装手順や、推論速度のベンチマーク結果については、次回の記事で詳しくコード付きで解説 する予定です。ぜひフォローしてお待ちください!
まとめ:視覚AIは「理解」のフェーズへ
SAM 3は、単なる切り抜きツールではなく、世界を言葉で理解し、空間として認識するための「目」となるモデルです。
-
GitHub: facebookresearch/sam3
-
Hugging Face: facebook/sam3
-
Demo: Segment Anything Demo
ぜひ、皆さんも公式デモを触ってみてください。そして、その精度の高さに驚いてください。AIの進化は、私たちが想像するよりも遥かに速いスピードで進んでいます。
この記事に関するご意見やご感想、または 「Ryzen AIでの実装について、特にここが知りたい!」 というリクエストがあれば、ぜひコメントでお聞かせください。次回の記事執筆の参考にさせていただきます!
We are hiring! 私たちと一緒に、最先端のAI技術で社会実装に挑戦したいエンジニアを募集中です。興味のある方はプロフィールリンクから!
明生ライジングの実験室より。
https://www.akiorizing.com/