はじめに
この記事ではできるだけ最短ルートでYOLOの物体検知ロジックを自前の画像に適用してみる方法を示したいと思います。
流れは以下のようになります。
- Python環境構築
- YOLOを導入する
- YOLOを実際に使う
VS Code、pipenv、gitが導入済みの方であれば、作業フォルダ内でターミナルを開いて以下の4つのコマンドを打つと動かせます。
git clone https://github.com/ultralytics/yolov5.git
pipenv install -r requirements.txt
pipenv shell
yoloのフォルダ/data/image/に好きな画像を入れて
python detect.py --weights yolov5s.pt --source data/images/画像名
これで、yoloのフォルダ/runs/detect/exp内に結果が出力されます。
では順々に見ていきます。
1. Python 環境構築
自分の書いた記事で恐縮ですがこちらをご覧ください。環境がある方は飛ばしてもらって結構です。ただし、以降の説明ではVS Code上でpipenvを使って動作環境の構築をします。
2. YOLOを導入する
まずVS Codeを開いて、適当な作業フォルダに移動しましょう。
今回はこのyoloを動かしてみることにします。開くと下のような感じになっています。codeをクリックしてzipをダウンロードして解凍します。
もちろん、git cloneできる方はそちらでも大丈夫です。
git clone https://github.com/ultralytics/yolov5.git
出てきたフォルダーの中身を作業フォルダ直下に置いて、本体があるディレクトリ内でterminalを開きましょう。
yolo用の環境を構築します。以下のようにterminalに打ちましょう。
pipenv install -r requirements.txt
これでYOLOの導入は終了です。
3. YOLOを実際に使う
まずは構築した仮想環境に入りましょう。
pipenv shell
好きな画像をdata内のimagesというところに入れましょう。busという画像とziadaneという画像がデフォルトで入っているはずです。
私は飼っているワンちゃんの画像で検出を行うことにします。
(モデルのトレーニング抜きでは検出できる物体や生き物の種類に限りがあるので、ご注意ください。)
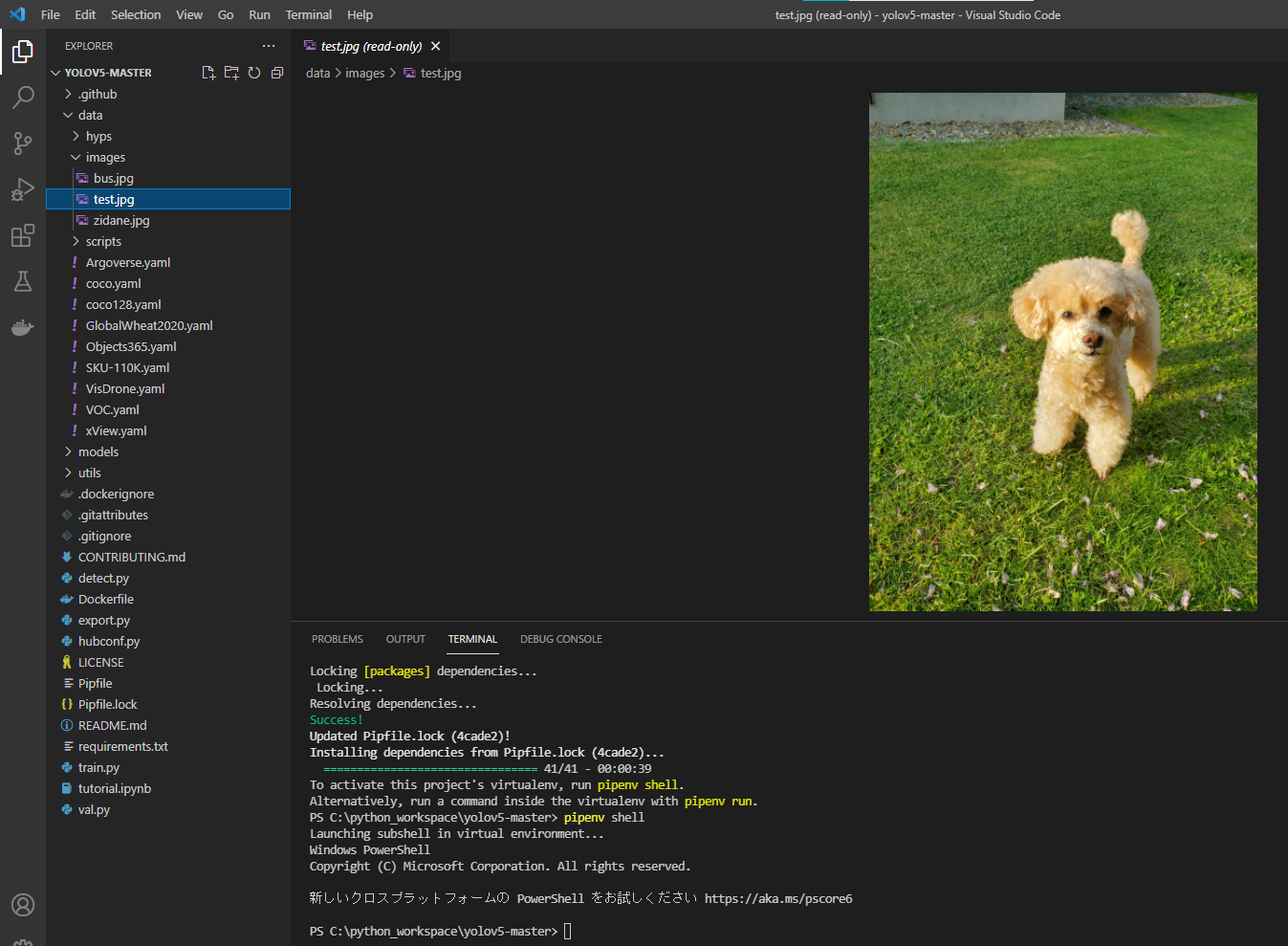
以下のコマンドを打ちましょう。画像名を適宜使用されたものに変えてください。
python detect.py --weights yolov5s.pt --source data/images/test.jpg
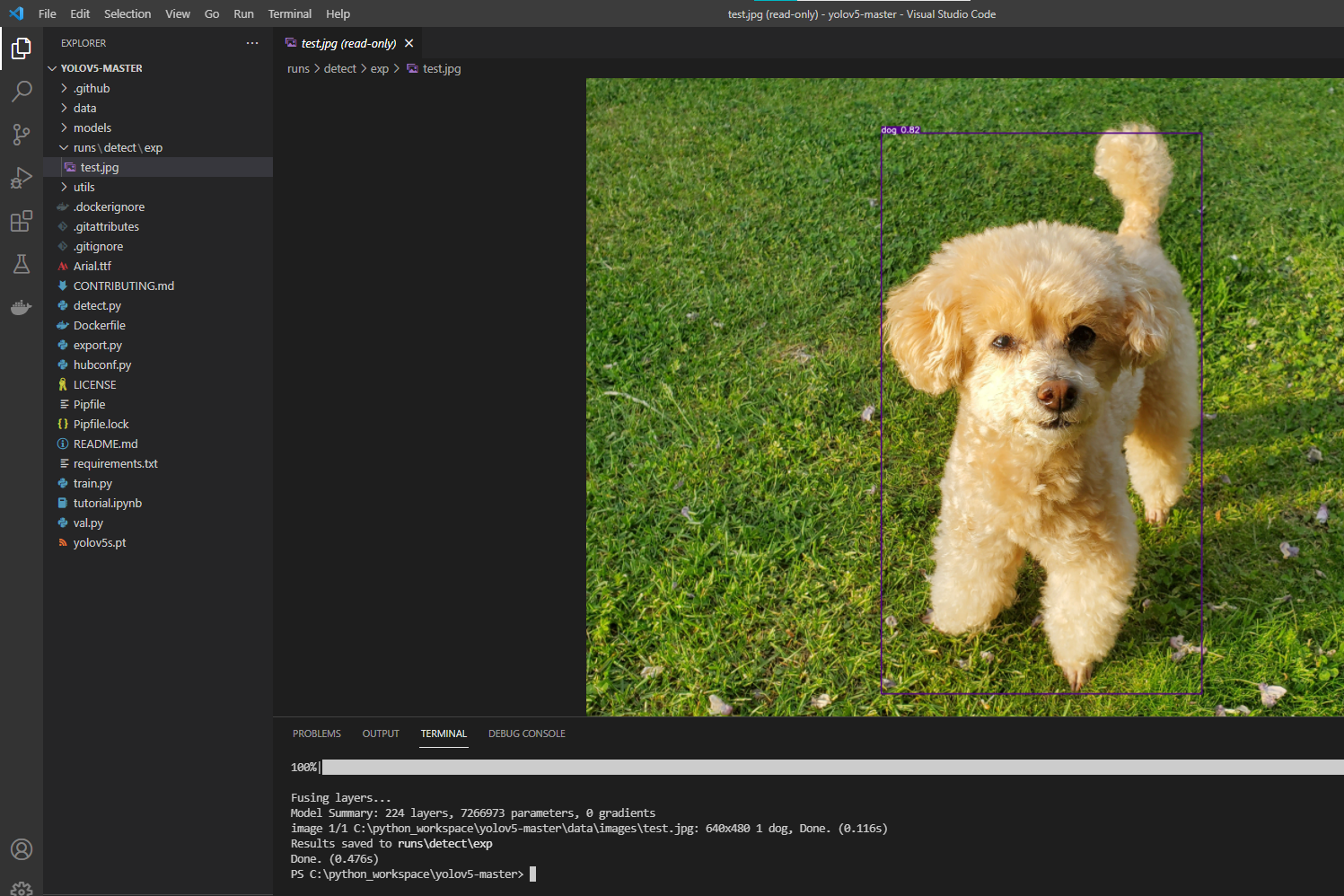
Done.が出たら、検出結果はruns/detect/exp内に保存されます。
無事検出されたようです。
おわりに
まず、唐突に出てきた以下のコマンドについて、少し話しておきます。
python detect.py --weights yolov5s.pt --source data/images/test.jpg
物体検知を行いたいときはdetect.pyを起動します。--weightsの引数は使うyoloのモデルの重みを指定します。今回使用したのはyolov5ですが一口にyolov5といっても多数のモデルがあります。そのうちのyolov5sというモデルを使用したということです。
このコマンドはtutorial.ipynb内に書いてありますので、参考にしてください。
また、gpuをお持ちでcudaをすでに導入されてる方はpytorchのサイトから対応するcuda用のpytorchライブラリをpipで入れなおすと、gpuを使ってモデルを回すことができます。