こんにちは、クラウドワークスの新規事業のエンジニアとして仕事をしている高梨です!
最近、「実践ドメイン駆動設計」という本を読みました!
500ページ近くもある技術書で、なかなか量は多かったのですが、DDDがどんなものなのか一通り大枠を掴めた気がします。
ただ読み終わった後にこんな疑念や不安をいだきました。
「たしかにかなり面白そうだけど、実際にやるとどれだけ工数かかるんだろう...?」
「設計の話は全然出てこなかったけど、DDDで作るとなるといったい何から始めればいいんだ?」
「戦術についての知識はついたけど、実際に書こうとしたらできなそうだな...」
そこで、そういった疑念や不安を解決するために、実際にDDDでサンプルプロダクトを作ってみようと思ったわけです。
実際に作ってみるのが、結局一番理解が進みますしね。
今回は、そのプロダクトがリリースされるまでの過程や感想を、作成した設計書やソースコードを公開しつつ、お話ししていければと思います。
この記事の対象者
「DDDについてなんとなく理解したけど、実際に作れるかはちょっとわからない。」
「実践ドメイン駆動設計は全部読んだ!実際にDDDで何か作ってみたいと思っている。」
「チームでDDDを取り入れるか迷っている。DDDに関する記事はいくつか読んでみた。」
本記事では、主に上記のような方を対象にして話を進めていければと思います。
今回は、DDDで出てくる基本的な用語の説明はあまりせずに、それらをある程度理解した上で、実際にDDDを採用してみたいと考えている方に参考にしていただけるような話をしていこうと思っています。
なので、まだDDDについてあまり理解できていないという方は、先に下の参考記事から読んでいただいた方が頭に入りやすいかもしれません。
DDDの理解が進む参考記事
1. そもそもドメイン駆動設計(DDD)とは何か
ドメイン駆動設計入門
https://www.slideshare.net/TakuyaKitamura1/ddd-29003356
ドメイン駆動設計の基礎知識
https://logmi.jp/tech/articles/310424
2. コード(実装)側からDDDを理解してみる(ボトムアップ)
ボトムアップドメイン駆動設計
https://nrslib.com/bottomup-ddd/
ボトムアップドメイン駆動設計2
https://nrslib.com/bottomup-ddd-2/
ここからの話の流れ
ここからは以下の順番で話を進めさせていただければと思います。
- 今回作ったプロダクトの内容説明
- DDD勉強開始〜プロダクトリリースまでの流れ
- 今回登場するユビキタス言語
- 設計過程
- 実装過程
- やってみた感想
今回作ったプロダクトの内容説明
今回は適当なテーマを1つ決めてから、プロダクトを作りました。
そのテーマは「名言」です。
テーマを「名言」に決めたのに大きな理由はなく、単にTwitterを見ていた時に名言Botというアカウントを見て、そこそこフォロワー数が多かったので、これでいいやと思ったという軽い理由です。
(あくまで勉強目的だったので、特別需要があるようなものでないことは承知しています。)
注意点として、今回作成したプロダクトはあくまで業務時間外に作成した個人のサンプルプロダクトであるため、特に社内でレビューを通したりはしていません。
サービスの特徴としては、以下のような感じになります。
- 経営者, エンジニア, ドラマ, 学問, スポーツ, アニメ, ビジネスなど様々なジャンルの名言が見れる。
- 名言に対して、いいね, お気に入り登録, コメントなどのアクションを取れる。
- 名言の登録, 修正, 削除を申請することができる。
- 名言の登録, 修正, 削除の申請の承認・非承認は他ユーザーの多数決(かそれに似通ったルール)で判断される。
- 名言の生まれたドラマやアニメなどの詳細(イメージ画像や紹介文, HuluやAmazon Prime対応かなど)が見れる。
- アプリである。
上のサービスの特徴もまた、今回設計過程で決めていったことなので、ここではその過程を説明していければと思います。
(あくまで設計開始時点では「名言」というテーマだけが決まっている状態で、サービスを作りました。)
技術的には、Spring Boot(Kotlin)を採用して、アプリはReact Nativeで作成しました。
IOSとAndroidの両方で公開中ですので、下のURLからアクセスするまたはアプリの名前が「Phrase Art」になっていますので、App StoreまたはGoogle Playで検索しても出てくるかと思います。
| IOS | Android |
|---|---|
| App Store | Google Play |
 |
 |
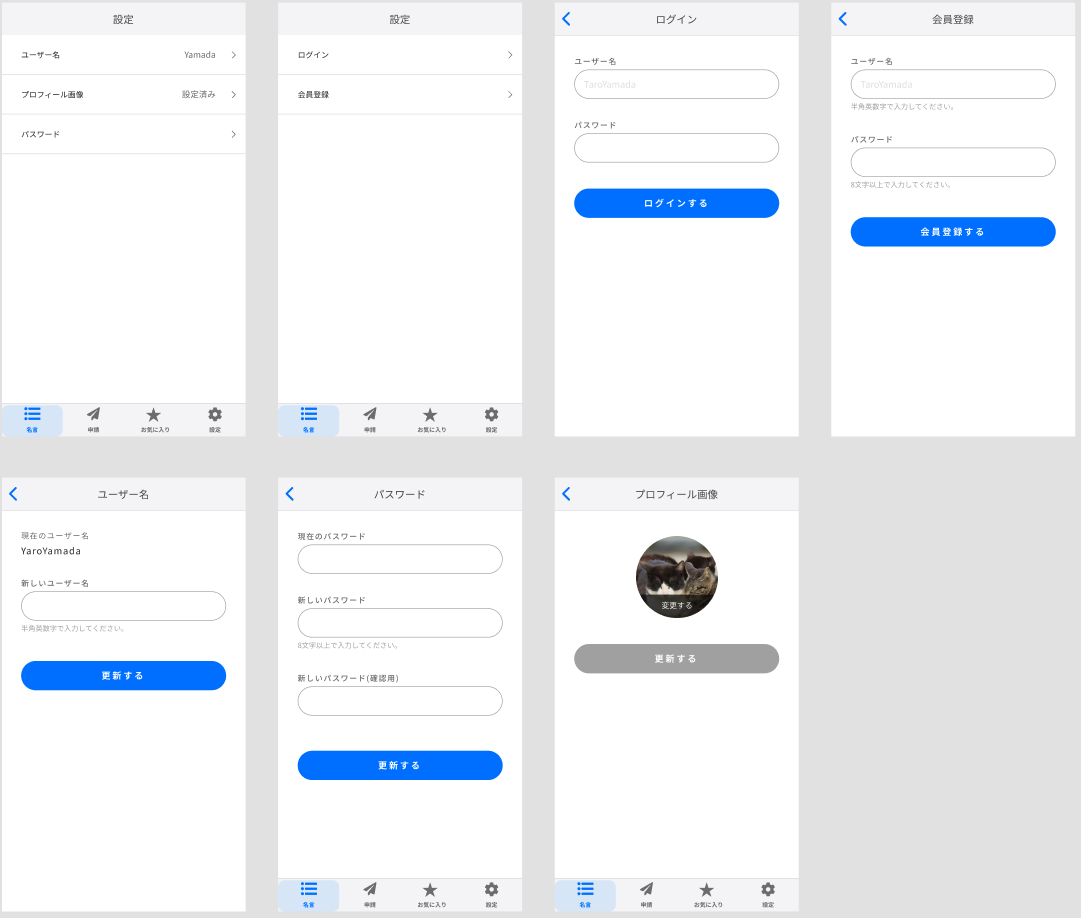
一応、アプリのイメージとしてはこのようなものになりますね。
| 名言一覧 | 名言詳細 | サブカテゴリー詳細 | 申請一覧 | 申請詳細 | 設定 | 会員登録 |
|---|---|---|---|---|---|---|
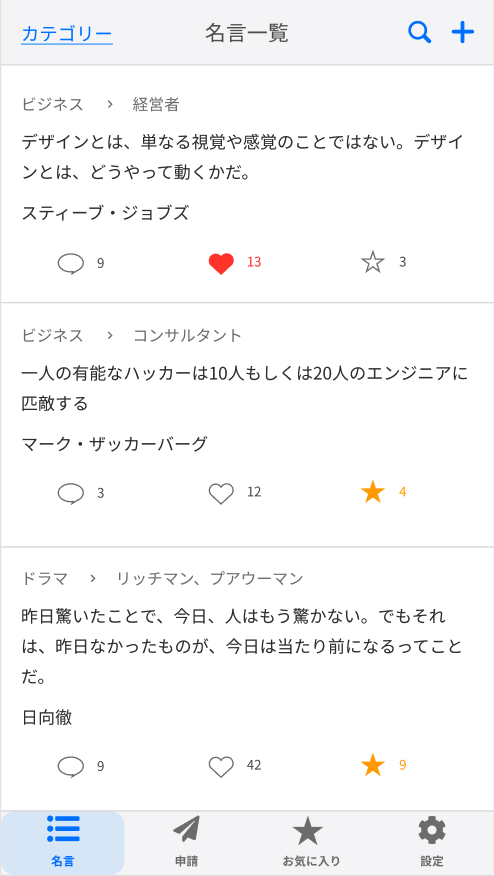 |
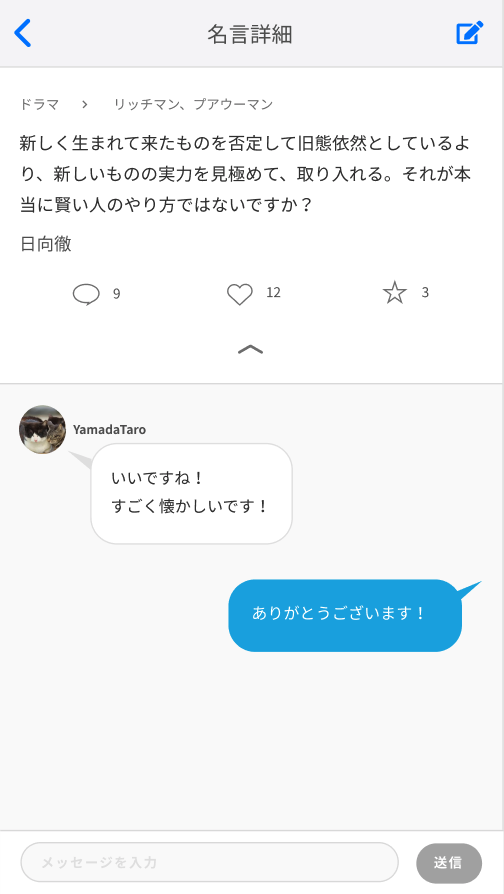 |
 |
 |
 |
 |
 |
DDD勉強開始〜プロダクトリリースまでの流れ
前提
もともとチーム内では、DDDを利用して(新規事業の)プロダクトを作り直すという話がでていました。
そのため、先月(2018年11月)の1日あたりから、チーム内でもDDDの読書会が開始され、そこから1週間に1, 2回の頻度で1回1時間のDDD読書会を開いている状況です。
そんな中、参考資料として、本「実践ドメイン駆動設計」がいいという話を聞き、実際に読んでみると作りたくなったというのが今回プロダクトを作ろうと思った理由でした。
チーム内読書会で読んだこと(2018年12月17日 現在)
第1, 2回
本「わかる!ドメイン駆動設計 ~もちこちゃんの大冒険~」
第2, 3, 4回目
記事「ボトムアップドメイン駆動設計」
https://nrslib.com/bottomup-ddd/
https://nrslib.com/bottomup-ddd-2/
第5, 6, 7, 8回目
本「実践ドメイン駆動設計(1, 2, 3, 4章)」
時系列 (2018年)
11月01日 : チーム内でDDD勉強会開始
11月04日 : 本「実践ドメイン駆動設計」をGET & 読書開始
11月10日 : 本「実践ドメイン駆動設計」を読破
11月11日 : Spring Bootの勉強開始
11月12日 : 本「モデルベース要件定義テクニック」読書開始
11月16日 : 本「モデルベース要件定義テクニック」読破
11月17日 : 「名言」というテーマが決定 & 設計開始
11月24日 : 設計完了 & 実装開始
12月17日 : 本記事公開 (実装途中 8割完)
12月26日 : 実装完成 (最終盤 IOSリリース)
12月28日 : Androidリリース
今回登場するユビキタス言語
設計の話に入る前に今回登場するユビキタス言語の説明を少しさせていただければと思います。
登場するユビキタス言語を軽く知っておいた方が、より設計書自体も理解しやすいかなと思い、設計の話の前にお話しすることにしました。
主に登場するユビキタス言語とその説明は以下の通りです。
| ユビキタス言語 | 英名 | 説明 |
|---|---|---|
| 名言 | Phrase | そのままの意味。 英名の候補が色々あり、決めるのが難しかったが、結果的にサービス名にもあり、わかりやすいという理由でPhraseにした。 |
| 作者 | Author | 名言の作者を示す。 |
| ユーザー | User | ユーザーのこと。 アクターであるユーザーのことを示す。 |
| プロフィール | Profile | ユーザーの保有する認証関係の情報以外のこと。 |
| カテゴリー | Category | 名言を分類するもの。 管理者のみが変更を行えるもので、ビジネス, 学問, ドラマ, スポーツ, アニメ, その他などがここに属する。 |
| サブカテゴリー | Subcategory | カテゴリーをさらに分類したもの。 ユーザーも内容を修正することができる。 例えば、ビジネスのサブカテゴリーとして経営者, エンジニア, 営業などが属している。 (ドラマなどでは、そのドラマのタイトルが入ることになる。) |
| コメント | Comment | 名言または申請に対してユーザーがつけることのできるコメント。 |
| いいね | Like | 名言に対してできるアクション。 Twitterなどと同様。 |
| お気に入り | Favorite | 名言に対してユーザーができるアクションの1つ。 お気に入りとして登録した名言を別の一覧で閲覧することができる。 |
| 動画配信サービス | Video On Demand | ドラマまたはアニメのサブカテゴリーにのみ属するもの。 HuluやAmazon Prime Videoが入ってくる。 |
| 更新申請 | Update Request | 名言登録申請, 名言修正申請, 名言削除申請, サブカテゴリー修正申請の総称。 |
| 名言登録申請 | Phrase Registration Request | ユーザーが名言の登録を申請する際に提出(submit)するもの。 |
| 名言修正申請 | Phrase Modification Request | ユーザーが名言の修正を申請する際に提出(submit)するもの。 |
| 名言削除申請 | Phrase Deletion Request | ユーザーが名言の削除を申請する際に提出(submit)するもの。 |
| サブカテゴリー 修正申請 |
Subcategory Modification Request | ユーザーがサブカテゴリーの内容を修正を申請する際に提出(submit)するもの。 |
| 判定 | Decision | 他ユーザーの更新申請に対してユーザーが行うもの。 承認(approve)または否認(reject)がある。 |
| 最終判定結果 | Final Decision | 更新申請に対してユーザー(複数)が行った判定を元に出された更新申請を認めるかどうかの最終的な判定結果。 承認(approve)または否認(reject)がある。 |
| (更新申請の)有効期限 | Expires Datetime | 提出された更新申請をユーザーが判定できる期限。 期限を過ぎるとユーザーは判定を行うことができなくなる。 有効期限を過ぎてから一定時間経過すると最終判定結果が出される。 (よく考えると有効期限ではなく判定期限とした方が適切な気がする。) |
上記は簡単にユビキタス言語とその英訳、説明を表にしたものですが、チームでやるときは実際にそのユビキタス言語を利用した時の文の例ぐらいまではまとめておくと、より言葉が揃いやすくなると思います。
例えば、名言登録申請であれば、
「ユーザーが名言登録申請を提出(submit)する。」
「提出された名言登録申請の最終判定結果がでた。」
のような文になるでしょうか。
特にチームでやるときなどは、このユビキタス言語とその使い方を統一しておかないと、実装時に人によってメソッド名の動詞が変わったりしてしまったりするので、早い段階でチーム全員が見れるところに記録しておいて、違和感や足りない言葉があれば都度チームメンバーに合意を取った上で更新していくのがよさそうです。
設計過程
どのように設計内容を決めたのか?
本「実践ドメイン駆動設計」には、戦略の大切さや戦術面の具体的な話などは出てくるのですが、具体的な設計についてはほとんど出てきませんでした。
そこで、本を読み終わった後に色々と調べてみると、どうやらDDDをやる際の設計については、別の本を参考にするのが良いという意見が多く見つかります。
DDDの設計内容を考える際に、参考になる良書として、よく以下の2冊があげられています。


実際に、本「モデルベース要件定義」の方は自分でも 本「実践ドメイン駆動設計」を読んだ後に読みました。
DDDの設計内容を考える上では、この2つを基軸に、自分たちで必要な設計を取捨選択して決めるのが良さそうです。
本の中でも言われていますが、必ずしも紹介されている全ての設計をやる必要はありません。
設計それぞれに目的があるので、それらを理解した上で、今回どの設計を自分たちはやるべきか、チームで話し合って決めるというのがいいみたいですね。
今回採用した設計 & 採用しなかった設計
採用した設計
- コンテキストモデル
- 要求モデル
- 要望の洗い出し
- 要求の洗い出し
- 要件の洗い出し
- ドメインモデル
- データモデリング
- ER図のみ
- ユースケースモデリング
- ユースケース図
- ユースケース記述
- 画面設計
- 画面遷移図
- ワイヤーフレーム(WF)
- (簡易的な)UI設計
- ロバストネス分析
- クラス図
採用しなかった設計
- 業務フローモデル
- 業務フロー的なものはほとんど存在しない想定だったので、除外しました。
- 利用シーンモデル
- やってもよかったのですが、今回は規模的にユースケース図をいきなり描き始めても問題ないと判断しました。
チームで新しいプロダクトを作るときなんかは、まずはプロダクトのイメージを揃えていくために採用してみるのがいいかもしれません。
- 画面・帳票モデル
- 今回はワイヤーフレームも自分で作成することになっていたので、ワイヤーをいきなり書くことで画面・帳票モデルの役割をカバーしました。
- イベントモデル
- イベント駆動設計にするつもりはなかったのと、そもそもそれほどイベントが多いわけではなかったので除外しました。
- 機能モデル
- 機能がそんなに多いわけではなかったので、他のユースケースモデル等で十分と判断しました。
機能が多いプロダクトの場合は、それらを整理する意味で採用した方がいいかもしれません。
- シーケンス図
- 設計開始当初は書く想定だったのですが、Spring Boot自体の理解も浅かったこともあり、シーケンス図を書いても有用なものにならなそうだと判断したため、ロバストネス図、クラス図、データモデルを元に実装をして、シーケンス図は書かないことにしました。(本来は書いた方がいいです。)
採用した設計の取り掛かった順番
- コンテキストモデル
- 要求モデル(要望の洗い出し)
- 要求モデル(要求の洗い出し)
- 要求モデル(要件の洗い出し)
- ドメインモデル
- ユースケースモデリング(ユースケース図)
- 画面設計(画面遷移図)
- 画面設計(ワイヤーフレーム)
- ユースケースモデリング(ユースケース記述)
- ロバストネス分析
- クラス図
- データモデリング(ER図)
- UI設計
- 実装に入る...
基本的には、本や他の参考記事に載っている通りの順番で進めています。
1箇所だけ、ユースケース図を描いた後、ユースケース記述に進む前に画面遷移図、ワイヤーフレームの設計を行なっているのは、ユースケース記述をしていく際に、画面名やボタン名、入力項目が決まっていないと都合が悪かったので、ユースケース記述の前に画面遷移図とワイヤーフレームの設計を行いました。
あくまで画面名やボタン名、入力項目を定めるのが目的なので、代わりに画面・帳票モデルを入れるのでも問題ない気がします。
(今回はワイヤーフレームも自分で作成する必要があったので、このようにしました。)
設計内容詳細
コンテキストモデル
コンテキストモデルとは?
コンテキストモデルは以下の問いに対する答えを明確にするために作成するものです。
- 要求の元となる関係者にはどのような人や組織がいるか?
- どのような外部システムと連携するのか?
- このシステムのは目的はなんなのか?
実際の設計
| Version 1 |
|---|
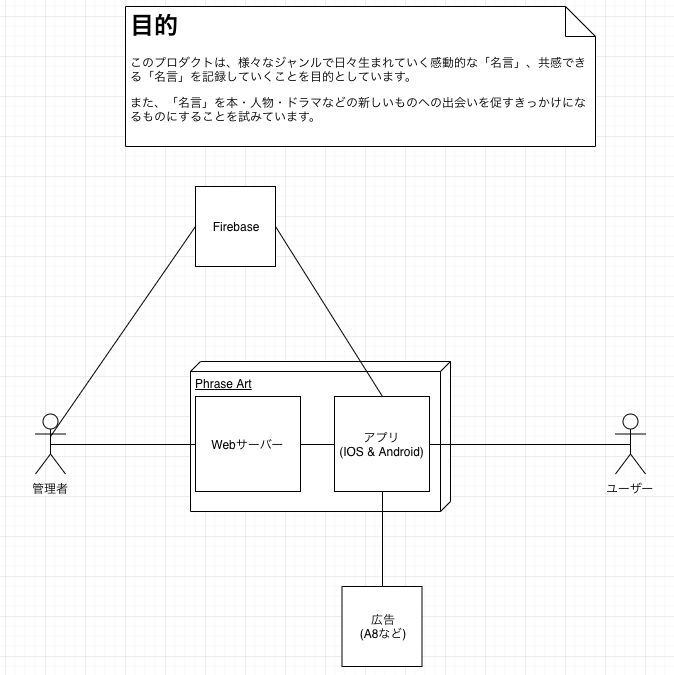 |
(利用ツール : draw.io)
今回は複雑なシステムではないので、コンテキストモデルはかなりシンプルになりました。
他社と連携している場合などは、この図の中にその他社のことが入ってきたり、他のチームと連携している場合はそのチームのことが入ってきたりします。
また、チームメンバーがPO、PM、Designer、Engineerなどに別れている場合は、そこも線で関係性を見える化しておいて、チーム全体でイメージを統一しておくといいかもしれません。
また、今回以下のようなシステム間の関係性を描くコンテキストマップは作成しませんでした。

本来は作成するべきなのですが、今回は最初どのタイミングで作成するべきなのか分かっておらず、結局ドメインモデルのタイミングでコンテキストをどう分けるか一緒に考えてしまいました。
コンテキストマップについても、このタイミングでコンテキストを分けるかやどう分けていくか決めていくべきだと思います。
要求モデル
要求モデルとは?
要求モデルとは、コンテキストモデルで出てきたアクター(役割)にヒアリングを行い、聞き出した要望を元に、要望 → 要求 → 要件 の順に考えていくことで、アクター(役割)が望むものを考慮した要件を定義していけるというものです。
- 要望
- 利用者(アクタ)からヒアリングしたもの。思いつきレベルのもの。
- 要求
- 要望を整理して構造化し、粒度を合わせたもの。機能要求、非機能要求がある。
- 要件
- 最終的に開発で実施すると決めた重要なもの。上位の利害関係者との確認用項目として整理する。
実際の設計
| 要望 | 要求 | 要件 |
|---|---|---|
 |
 |
 |
(利用ツール : esa)
今回は以下のようなルールで要望・要求・要件をそれぞれ洗い出していきました。
- 要望・要求それぞれの語尾はそれぞれ以下の通りにする。
- 要望「〜したい」
- 要求「〜できること」「〜すること」
- 書式はマークダウンで書く。
- 機能要求・非機能要求の差異については考えないでよい。
要望については、本来ペルソナを決めたり、ユーザーに直接ヒアリングするべきなのですが、今回はあくまで勉強用だったので、要望は自分で勝手に考えたものを洗い出しています。
要求モデルは作るものの大枠を決めるものなので、最初は出来るだけ要望・要求を洗い出して、要件でスコープをきるという流れで進めました。
今回は普通のMDを扱えるツールを利用しましたが、チームでやるときはリアルタイムで同じ画面を編集できる方がやりやすいと思うので、その場合はHackMDなんかを使う方がよさそうですね。
別の手段として、実際にホワイトボードに付箋をどんどん出していくというのでもよさそうです。
正解がなく、時間を決めないと無限にできてしまうため、
「1時間で要望全部出し切る」
という具合に時間制限を設けるのがとても大切だと思います。
また、このタイミングで他の類似サービスをリサーチすると、要望や要求を洗い出しやすく、抜け漏れも出にくいので、洗い出しをやりつつリサーチをしっかり行うのが大切だなと思いました。
上の要求・要望・要件については、それぞれリサーチ込みで1時間で作成するようにしました。
最後の感想でも言おうと思っていますが、DDDの設計はとにかく期限を決めて前に進むのがすごく大切だと個人的には思っています。
正直、正解はやってみないとわからないので、使おうと思えばいくらでも時間を使えてしまいます。
それよりも期限内に出来るだけ質高く設計して、形になったら次にいく。
その上で次の設計で違和感に気づいたり、よりより方法を発見したりすると思うので、そのタイミングでまた前の設計を見直す方が圧倒的に効率がいい気がします。
(もちろん、いい加減にやってどんどん進めるという意味ではないので、どれだけ納得感あるものになったら次にいくかはチームのメンバーで決めるべきことになると思います。)
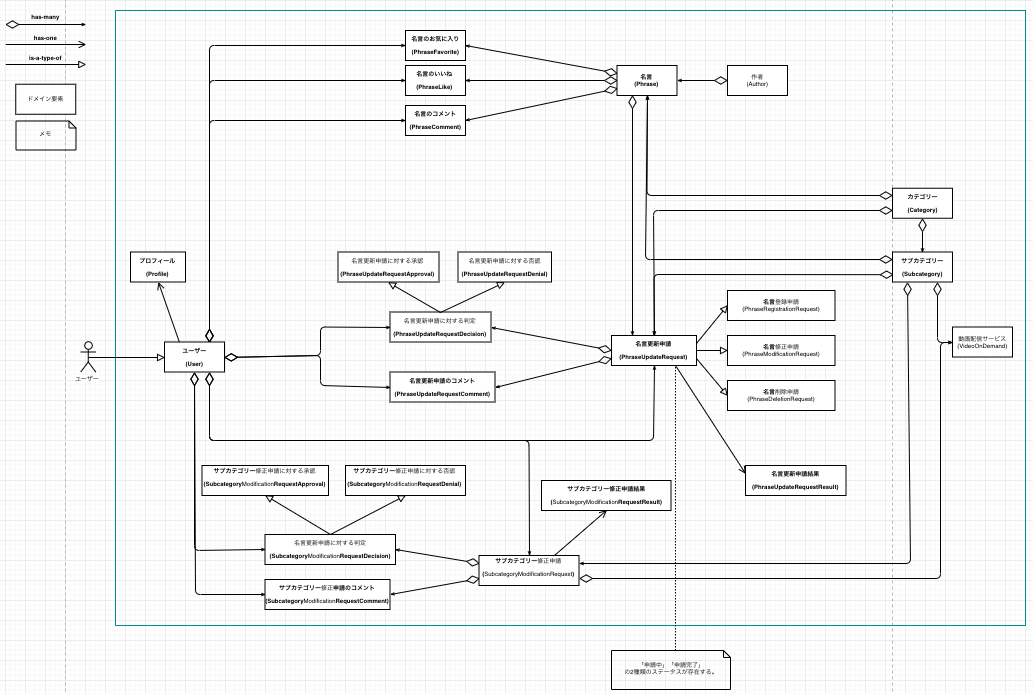
ドメインモデル
ドメインモデルとは?
システムの鍵となる概念と用語を文書化するために作成されるものです。
ドメインモデルでは、システムの主要な実体とそれらの間の関係性を明らかにして、場合によってはそれらの重要なメソッドと属性も洗い出します。
実際の設計
| Version 1 | Version 2 | Version 3 | Version 4 |
|---|---|---|---|
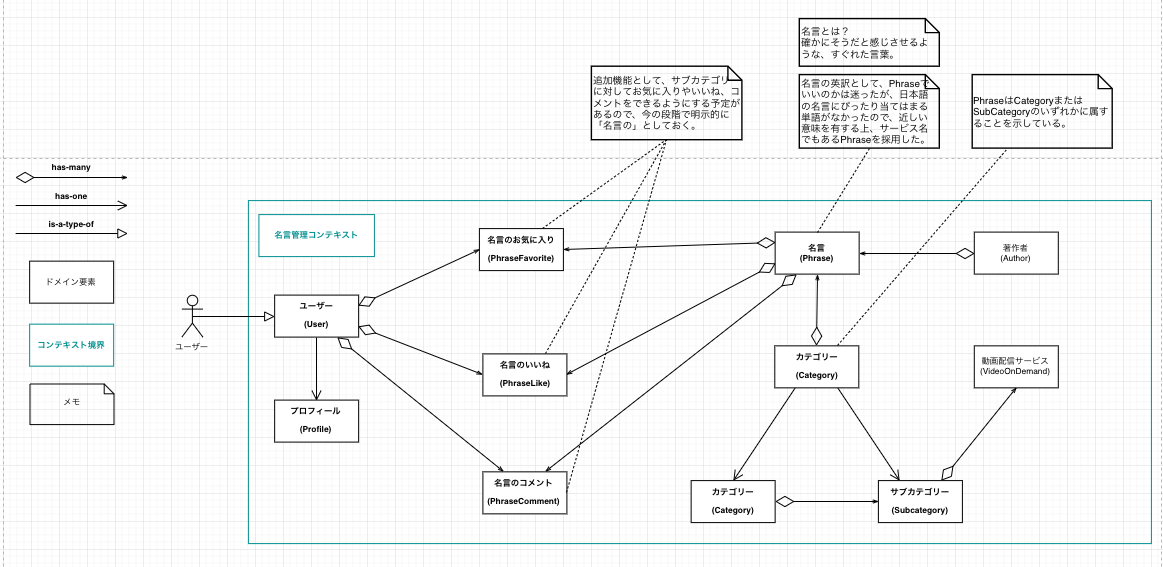 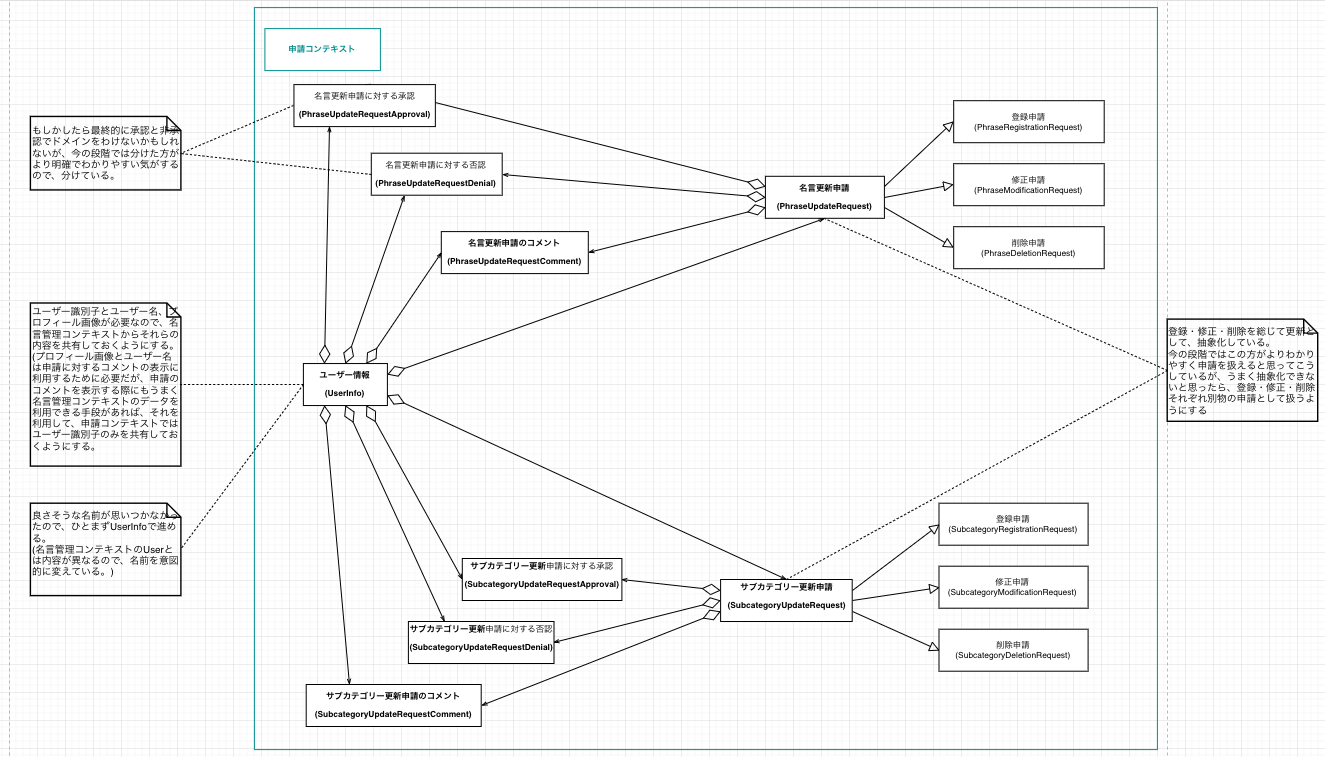
|
 |
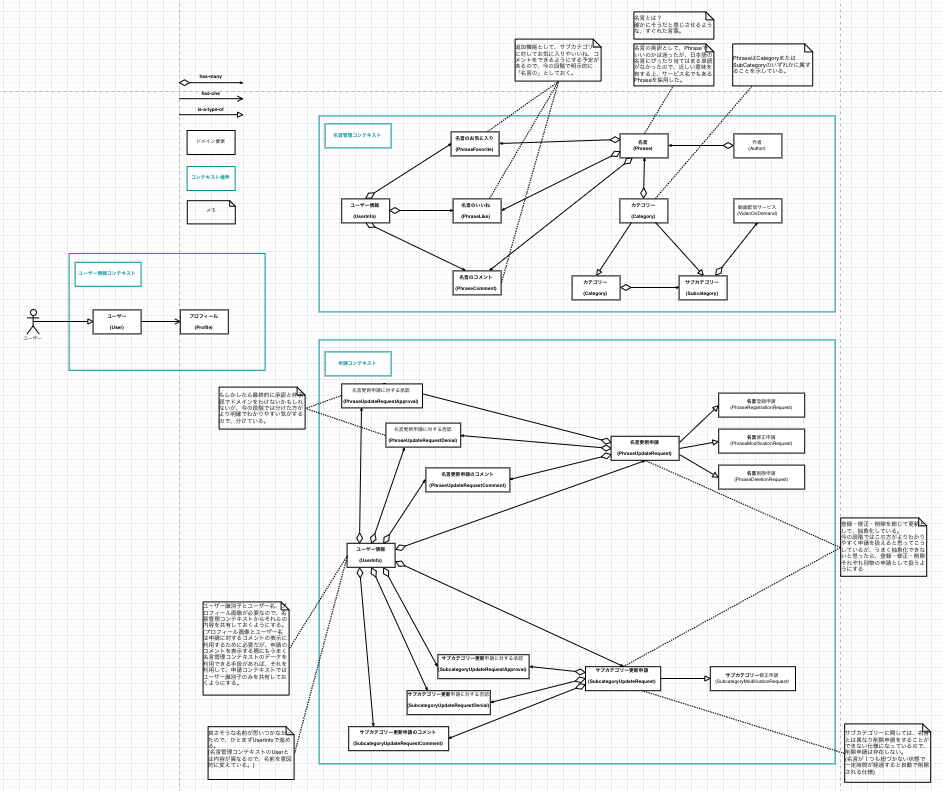 |
 |
(利用ツール : draw.io)
上の実際の設計を見るとわかるように、ドメインモデルは何度も更新した設計書になります。
それぞれ以下のタイミング・理由で更新された設計になります。
| version | タイミング | 理由 |
|---|---|---|
| Version1 | 要求モデル作成後、一番最初に作成。 | - |
| Version2 | ユースケースモデル作成時 | もともと名言管理コンテキストにユーザー関係のドメインを置いていたが、ユースケースを洗い出しているタイミングで、申請コンテキストにはないユーザーのドメインが名言管理コンテキストにだけあるのに違和感があったので、新たにユーザー管理コンテキストを作成して切り出すようにした。 |
| Version3 | ユースケースモデル作成時 | サブカテゴリーの登録申請をなくす仕様に変更したため、そのためのサブカテゴリー登録申請ドメインを削除。 (サブカテゴリーは名言が登録されるタイミングで、未登録のサブカテゴリーが入力されていた場合は、自動的に登録される仕様にした。) また、もともと「名言を書いた人」を著作者(author)としていたが、書物を書いた人という意味が強い著作者は妥当な言葉でないと判断して、日本語名を作者に修正した。(英語の命名は変わらずauthorを採用) |
| Version4 | ロバストネス分析時 | もともと分けていた名言管理コンテキストと申請コンテキストが、かなり互いに作用し合うことがわかったので、コンテキストを分けるメリットが少ないと判断して、全体を1つのコンテキストに統合。 (ユーザーコンテキストも統合したのも、今回の場合ユーザーコンテキストだけ切り出してもメリットが少ないと判断したため。) |
全設計書の中で、もっとも高頻度で更新をしたのが、このドメインモデルになります。
また、今回はドメイン内のプロパティ(プロフィールの画像など)はドメインモデルに書いていませんでしたが、できれば書いていった方がいいかもしれません。
これもユビキタス言語の範疇だと思いますが、プロフィールにある画像を「画像」と呼ぶのか「写真」と呼ぶのかでも人によって違うかもしれませんし、名言の文章を「文章(テキスト)」と呼ぶのか「内容(コンテキスト)」と呼ぶのかも人によるでしょう。
また、メソッド(振る舞い)についても同様で、申請1つとっても申請を「送信する(post)」「申請する(request)」「提出する(submit)」... など、色々な言い方ができます。
こういった表記をチーム全体で統一するために、気づいたことがあれば早い段階でチーム全体で納得のいくものに定めて、ドメインモデルに記述していく方が、あとあとになって表記揺れが多発することもなくなると思います。
ちなみに、今回最初にそういったプロパティなどを書かなかったのは、自分自身がまだデータ中心に考える癖が抜けていなかったので、プロパティなどを記述しちゃうとER図に似通ってきて、またデータ中心に考えちゃいそうだったという個人的な理由ですね。
なので、本来はドメイン内のプロパティの名前も決まっているものがあれば書いた方がいいと思います。
(どちらにしろ実装時までには決める必要が出てくるので。)
それと、上の設計書を見るとわかるのですが、途中のVersionまで緑の線でコンテキストを分割しています。
Version1の設計書を見ると緑の線でコンテキストごとに分けられていると思います。
分けたのは、名言を管理するのに必要なドメインと名言を申請する際に必要なドメインで、作用し合うタイミング(依存)は少ないと思い、それぞれ別コンテキストにして独立性を高める方針で進めるようにした方が、余計な依存が発生しにくくなると思ったからですね。
(Version1の時点では、作用し合うのは申請が完了したタイミングで、その申請内容の名言を登録するタイミングぐらいだと考えていました。)
ただ、ロバストネス分析をしたタイミングで、思ったよりも互いに作用し合う必要があることがわかり、コンテキストを分割するメリットが少ないと判断して、最終的には全体を1つのコンテキストとして扱うことにしました。
そもそも本来は、サービスが大規模だったり1つのプロダクトを複数チームで開発するときなんかに、境界づけられたコンテキストを設けることを考えるべきなので、Version1の時点で分けようとしたのが正しい判断ではなかった気もします。
正直、今回最初にコンテキストを分けようと思った一番の理由は、勉強目的で「分けてみたかったから」というのが一番な気もしますしね。
(結果的には分けられませんでしたが、、)
コンテキストを分けて、マイクロサービス化をすると、それはそれでアーキテクチャーが複雑になったり、結果的に管理が大変になるというのはよく聞く話なので、コンテキストを分けるかどうかは慎重に決めるのがよさそうです。
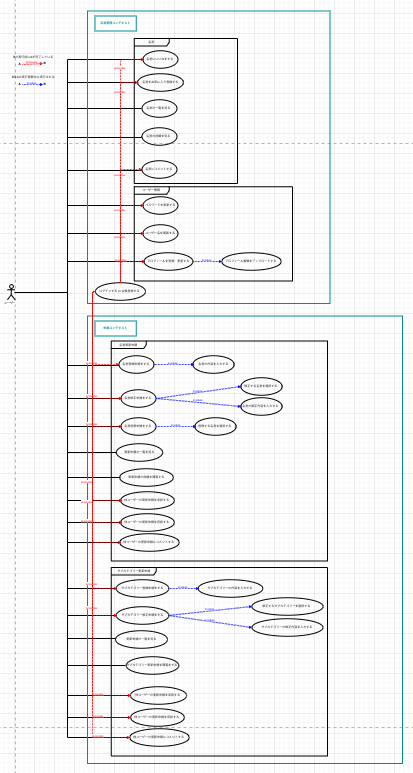
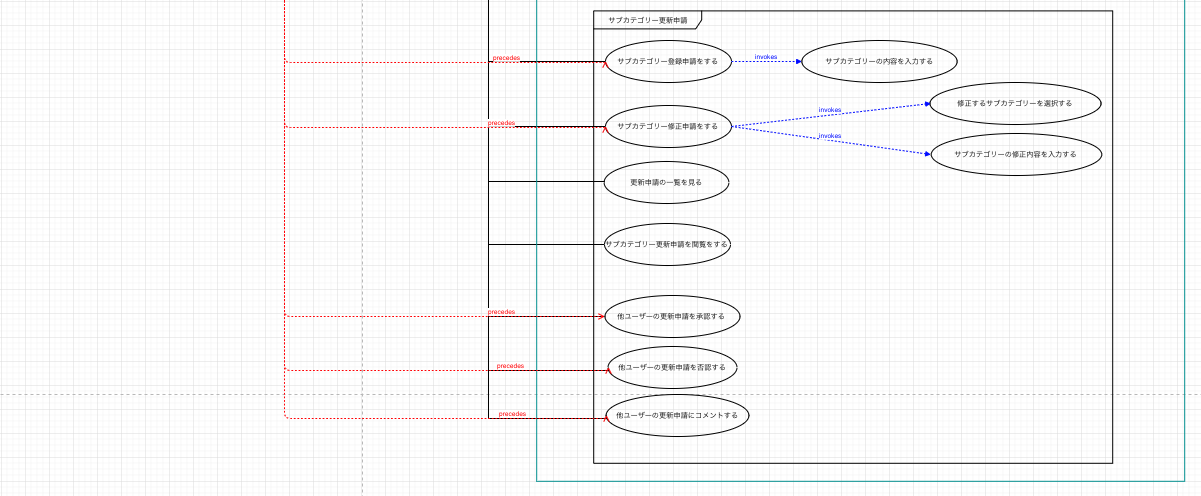
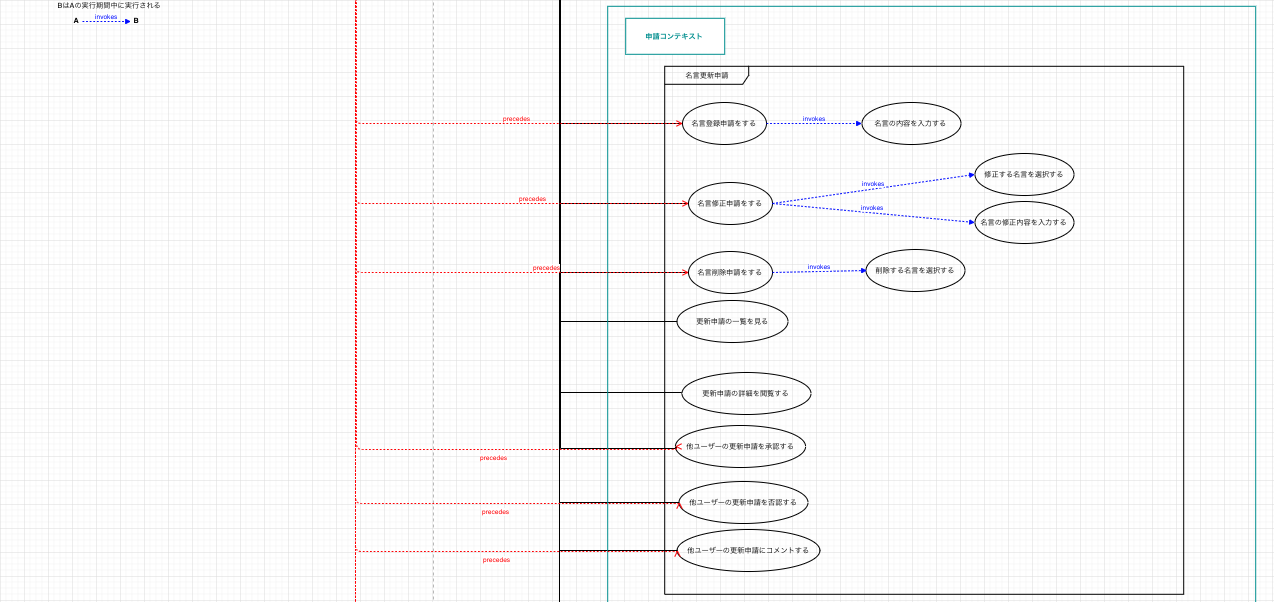
ユースケースモデリング
ユースケースモデリングとは?
ユーザーがシステムで何をするのか?何をできるのか?何をできないのか?といったことを明確化するためのもの。
ユースケース図
実際の設計
| Version 1 | Version 2 |
|---|---|
 |
|
(利用ツール : draw.io)
それぞれ以下のタイミング・内容で更新された設計になります。
| version | タイミング | 理由 |
|---|---|---|
| Version1 | ドメインモデル作成後、一番最初に作成。 | - |
| Version2 | ユースケース図作成中 | 名言管理コンテキストに本来関係のないユーザー自身の情報に関するユースケースがあるのに違和感があり、別コンテキストとしてユーザー情報コンテキストを作成して、そちらに切り出すようにした。 |
今回は1アクションで済むものが多かったので、かなりシンプルなユースケースになっていると思います。
EC系のサービスであれば、「物を購入する」といったユースケースの中に「商品を探す」「商品をカートに入れる」「住所情報を入れる」など様々な依存があると思うのですが、今回はそういった依存はほぼありませんでした。
ちなみに、ユースケース図はロバストネス分析以降、更新していません。
というのも、ユースケース図はロバストネス分析を行うための準備の役割を果たすところが大きいので、ロバストネス分析で見つかった違和感や修正すべき点などは、ロバストネス分析で全て補完するようにしました。
なので、先ほどドメインモデルでは最終的に1つのコンテキストに統合された設計書になっていたと思うのですが、ユースケース図については、Version2の3つのコンテキストに分割されている状態で止まっていますね。
(コンテキストを1つに統合することに決めたのが、ロバストネス分析のタイミングだったためです。)
ユースケース記述
実際の設計
| Version 1 |
|---|
 |
(利用ツール : esa)
ユースケース記述についてもユースケース図同様、ロバストネス分析の準備の役割を果たすところが大きいので、ロバストネス分析以降に見つかった違和感や修正すべき点などは、ロバストネス分析の方で全て補完して、ユースケース記述の更新はしませんでした。
ちなみに、実際にあったロバストネス分析の段階で気づいた修正すべき点の例を1つ紹介させていただきます。
コメントに関するユースケースで、メインフローに以下のようなフローがあります。
「システムはコメントが入力されたことを確認し、「送信」ボタンをdisabled状態からenable状態にする。」
ページを開いたタイミングではボタンをdisabledにしておいて、入力を確認してからenableに変更するというのが今回の仕様なので、そのことについて記述した文ですね。
ただ、ロバストネス分析で気づいたのは、あくまで上記のフローはフロント(今回でいうとアプリ側)の話で、ドメインには関係のない話でした。
なので、ドメインの関心事や振る舞いを表現するロバストネス分析の準備として書くユースケース記述には、書く必要のないものということになります。
このことについて、今回はロバストネス分析で上記の1文を無視するだけで、ユースケース記述の方は特に直していません。
このように別にユースケース記述に書かなくてもよかったものや書いた方がよかったもの、抜けていた考慮事項はいくつかありましたが、それらは全てロバストネス分析で補完するようにしました。
このタイミングで気づいたのは、DDDの設計をやる上で、前にやった設計書(ドメインモデルなど)の更新は必須になると思いますが、どの設計書を更新するべきかはチームで都度話し合って決める必要があると思いました。
例えば、ドメインモデルはシステム全体に存在する概念を表したとても大切な図になりますので、更新するべきだと思いますが、ユースケース記述についてはロバストネス分析ができてしまえば、その後はほぼ不要になると思うので更新する必要はないなど、更新することによるメリットとコストを加味して、どの設計書を都度更新するものにするか決める必要があるみたいです。
また、ユースケース記述のフォーマットについてですが、特別決まったフォーマットがある訳ではないみたいですね。
上のユースケース記述の書き方も他の記事を参考に考えたものです。
最低限、基本コースと代替コース(エラーのパターン)について記述されていて、その流れが順を追って(叙述的な文章で)主語・動詞共に明確に書かれているなどのユースケース記述の基本を押さえていれば、細かいフォーマットは自分たちで見やすいものを考えるのがいいかもしれません。
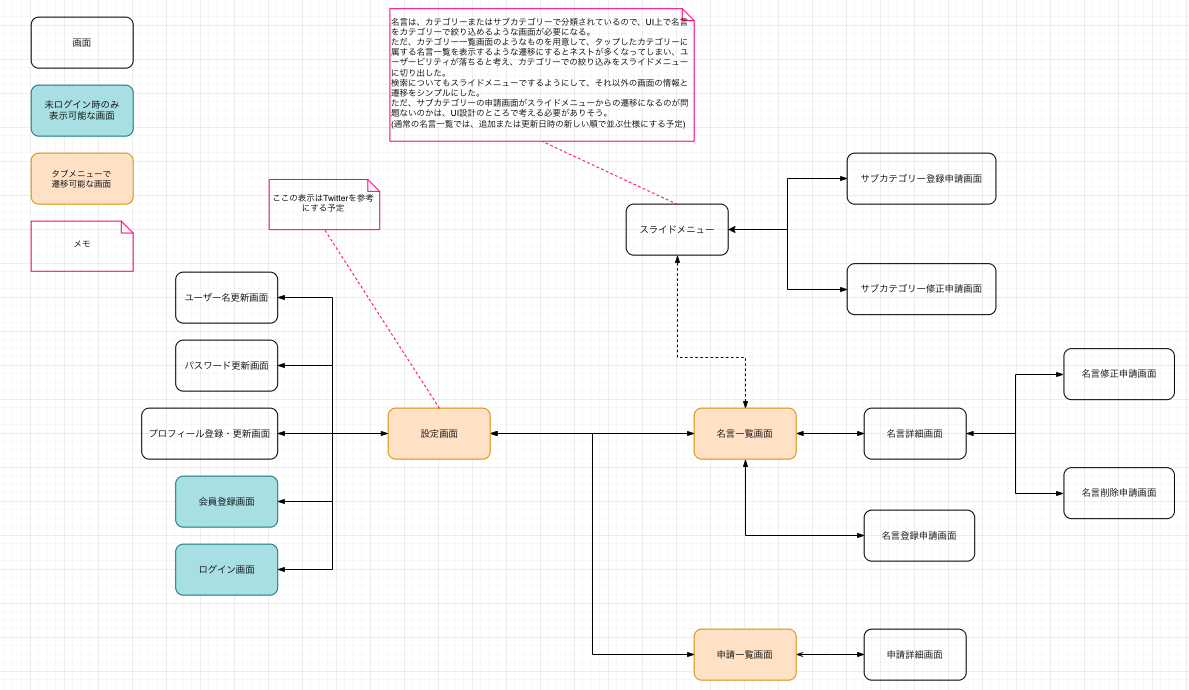
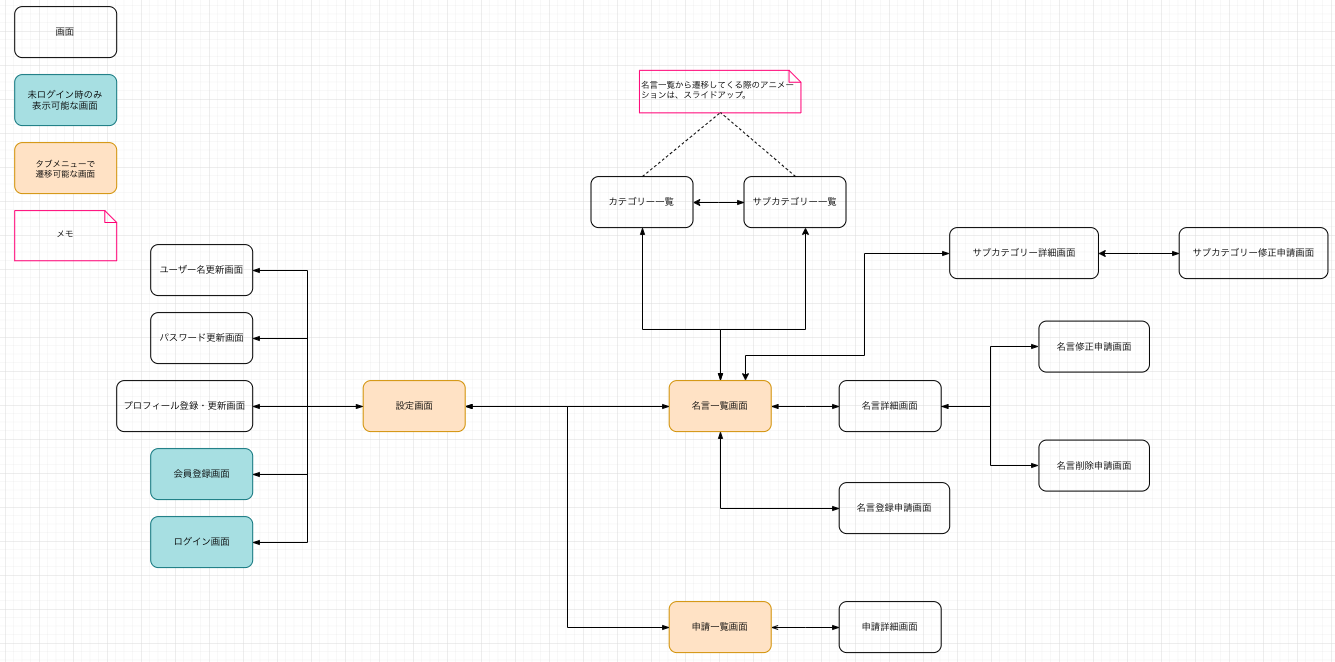
画面設計
画面遷移図
実際の設計
| Version 1 | Version 2 |
|---|---|
 |
 |
(利用ツール : draw.io)
ユースケース記述を書くにあたり画面名が必要になったので、必要な画面を洗い出すために作ったのが、上記の画面遷移図になります。
画面・帳票モデルではないので、あくまで画面名と遷移可能な画面との関係性のみを表しています。
ここまでの設計でユースケースは見えていても、実際に必要な画面やその名前は定まっていないので、後々になって矛盾等が生じないように、ユースケース図が書き終わったタイミングぐらいには、こういった設計で必要な画面を洗い出しておいた方がいい気がしました。
ちなみに、ロバストネス分析のタイミングで数画面追加で必要なことがわかったのですが、それについてはUI設計で補完するようにして、画面遷移図は更新していません。
あくまでユースケース記述を書くために作成した設計書になりますね。
(本来は、UXを考える時などに利用するなら、画面遷移図は更新した方がいいかもしれません。)
ワイヤーフレーム
実際の設計
| 名言関係 | 申請関係 | 設定関係 |
|---|---|---|
 |
 |
 |
(利用ツール : Figma)
画面遷移図のすぐ後に作成したのが、ワイヤーフレームになります。
本来は画面・帳票モデルでもいいのですが、ある程度ページごとの雰囲気を定めておいた方が抜け漏れが発生しにくいと思ったのと、今回ワイヤーも自分で作るということだったので、画面・帳票モデルの代わりにワイヤーを引くことにしました。
(本来はページごとに必要な情報をもう少し吟味して、情報の優先順位などもちゃんと考えた方がいいです。)
ただ実際にワイヤーをこのタイミングで引いて思ったのは、単純に画面ごとに必要な情報をリストアップするような設計に比べるとイメージは断然つきやすいので、新しいプロダクトをチームで作っていくときも間違いなくプロダクトのイメージを統一させるのにかなり役立つと思います。
ここまでは文字や図がベースだったので、実は人によって思っていたものと違ったというのは少なからず避けられないと思いますが、ワイヤーを見ればかなりチーム全体でイメージを統一できるので、より会話もスムーズに進められるのかなと思いました。
なので、チームで話し合いながらデザイナーの方にリアルタイムでワイヤーを引いていってもらうみたいな進め方もできるかもしれませんね。
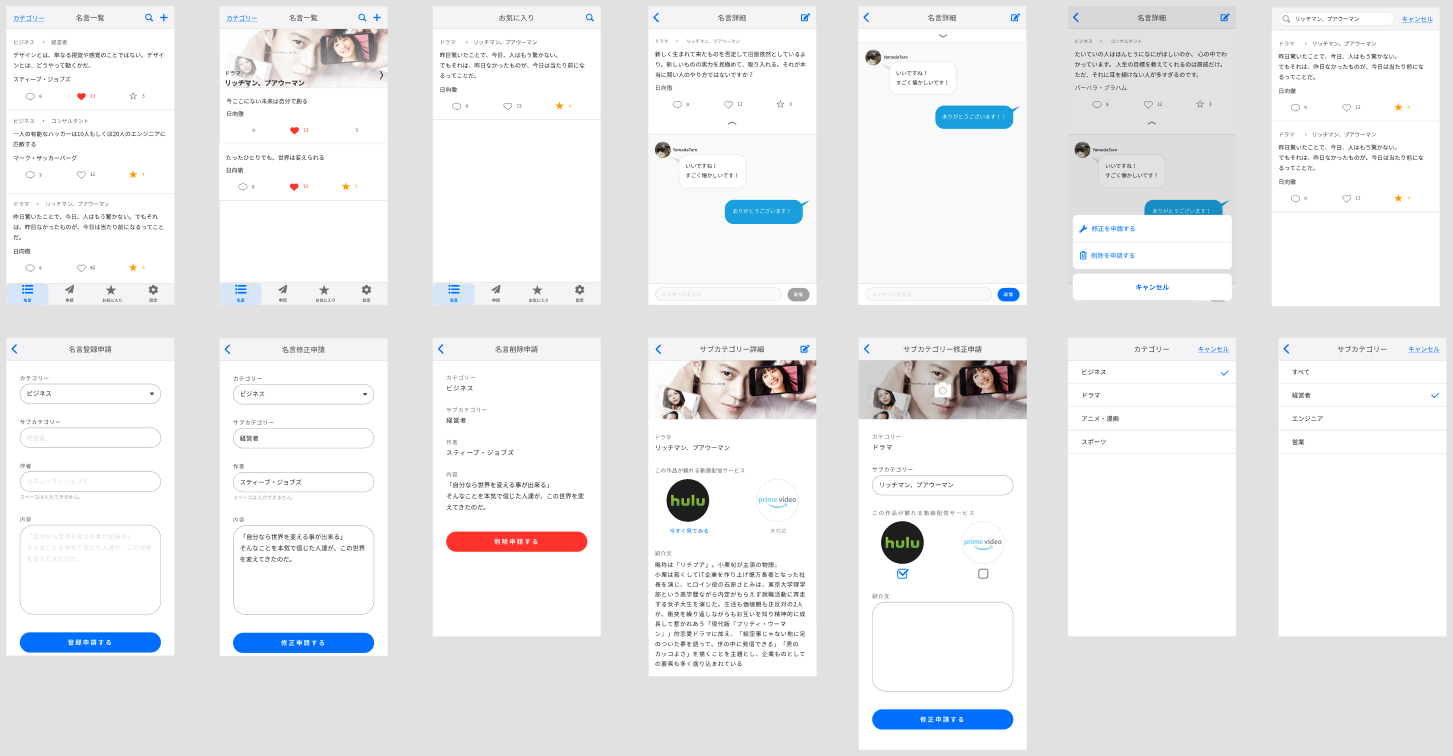
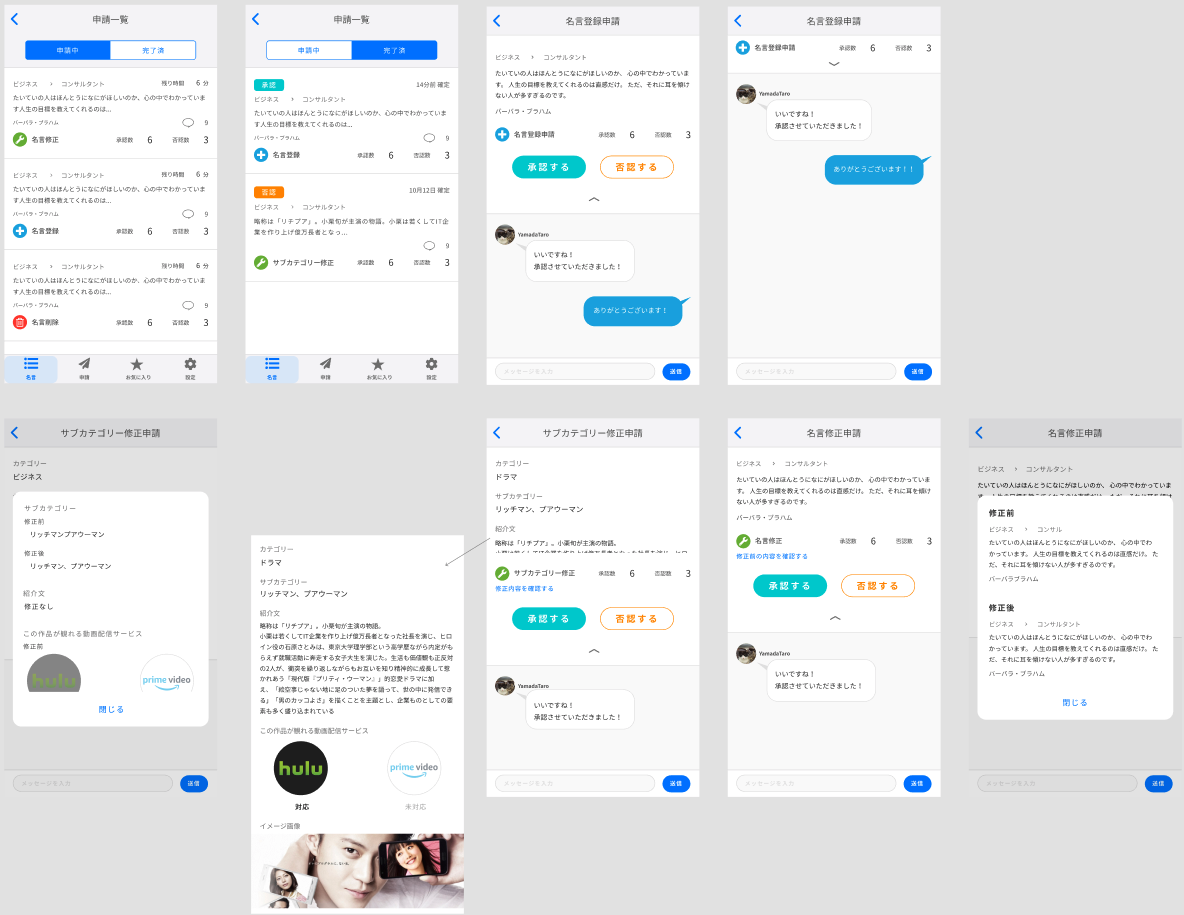
UI設計
実際の設計
| 名言関係 | 申請関係 | 設定関係 |
|---|---|---|
 |
 |
 |
(利用ツール : Figma)
UIの設計については、デザイナーにお願いする仕事になってくるので、ここでは詳細は省きます。
ロバストネス分析
ロバストネス分析とは?
システムを「バウンダリ」「エンティティ」「コントロール」の3つに分けて分析し、要件の振る舞いを整理することで、実装すべき点を明確にできるというものです。
参考資料
ロバストネス図を活用したシステム設計
実際の設計
| Version 1 |
|---|
 |
(利用ツール : esa & Visual Studio Code)
ここまでは draw.io を利用して、図を作成してきましたが、ロバストネス図からはUMLを利用して書いています。
というのも、今までの図と違い湾曲した線が多くなったり、線の横に文字を多くおいていたりするため、これらを draw.ioで作成してドラック&ドロップで修正するというのはかなり辛くなると思ったので、コードでUMLを書いていくことにしました。
実際コードを書いていくときは下画像のような雰囲気になりますね。
最近だとqiitaやesaなどのMDでもumlは対応しているみたいです。
最初作るのは少し大変ですが、慣れると簡単に書けますし、更新するのはかなり容易になりますね。
(Visual Studio Codeなどのエディタでは、コードをプレビューを見ながら修正できたりもします。)
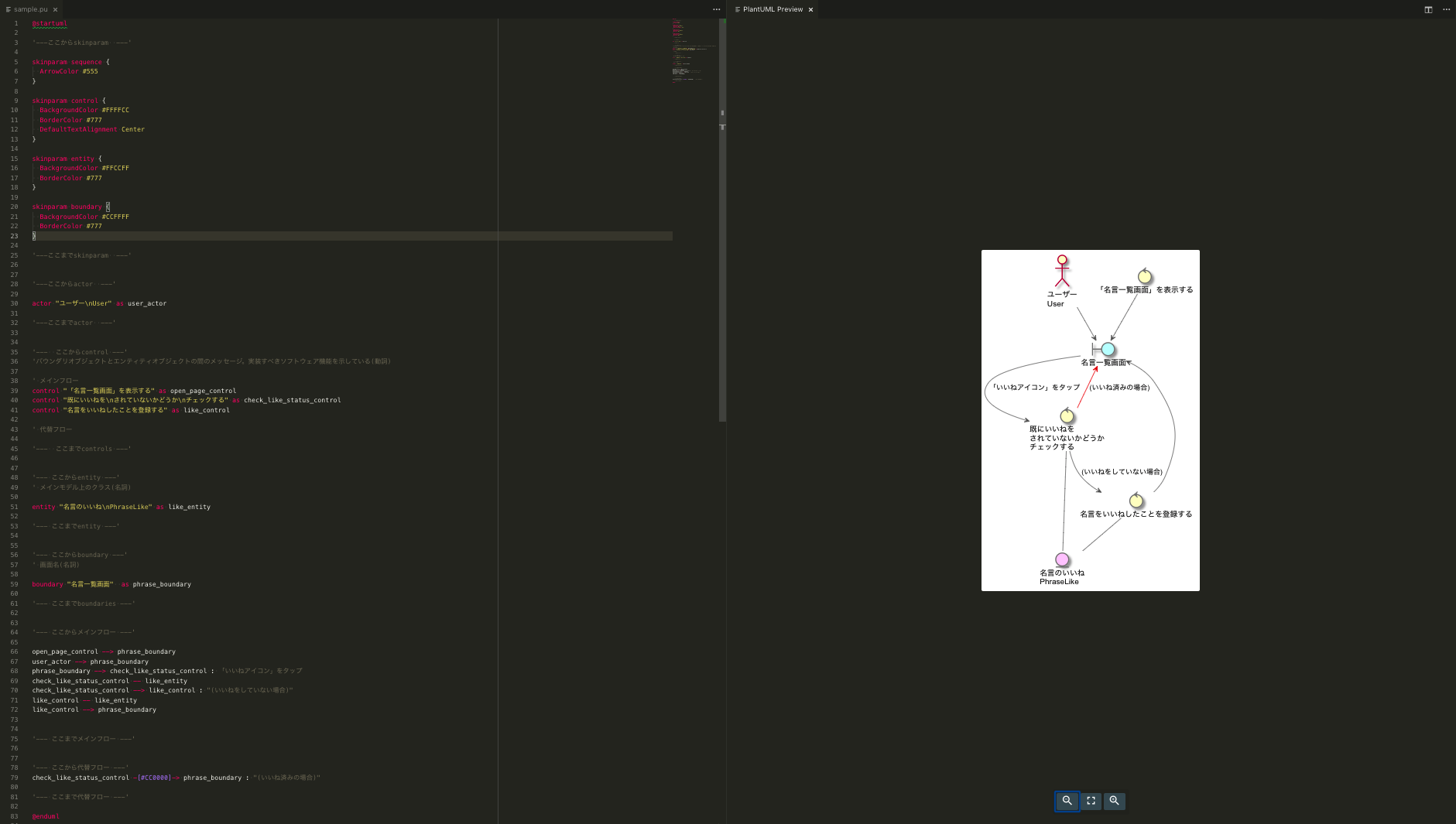
書いていて気づいた点としては、当たり前ですがロバストネス図が複雑なところはコードも複雑になります。
DDDでは特にユースケース、ロバストネス図のような仕様をできる限りそのままコードで表現することを試みるため、ロバストネス図が複雑である場合、ほぼ間違いなくそのあとの実装でコードも複雑になります。
なので、ロバストネス図を書いてみた上で、明らかに複雑になるようなところがあれば、先に進む前に仕様を改善できないか検討してみるのもいいかもしれません。
もし仕様をよりシンプルに改善できるならユーザーにとっても理解しやすいものになりますし、コードも間違いなくシンプルになるので、このタイミングで仕様が複雑だとわかったらシンプルな仕様にできないか検討してみるのが良さそうですね。
また、今回シーケンス図は書いていないのですが、本来はクラス図などを作成した後にロバストネス図とクラス図を利用して、シーケンス図を作成するのが一般的だと思います。
特にチームで開発する時などは、こういったシーケンス図などで細かく認識を合わせておかないと、実装した時に人によってかなりやり方にズレが出てきたりするので、シーケンス図までしっかり書いた方がいいかもしれません。
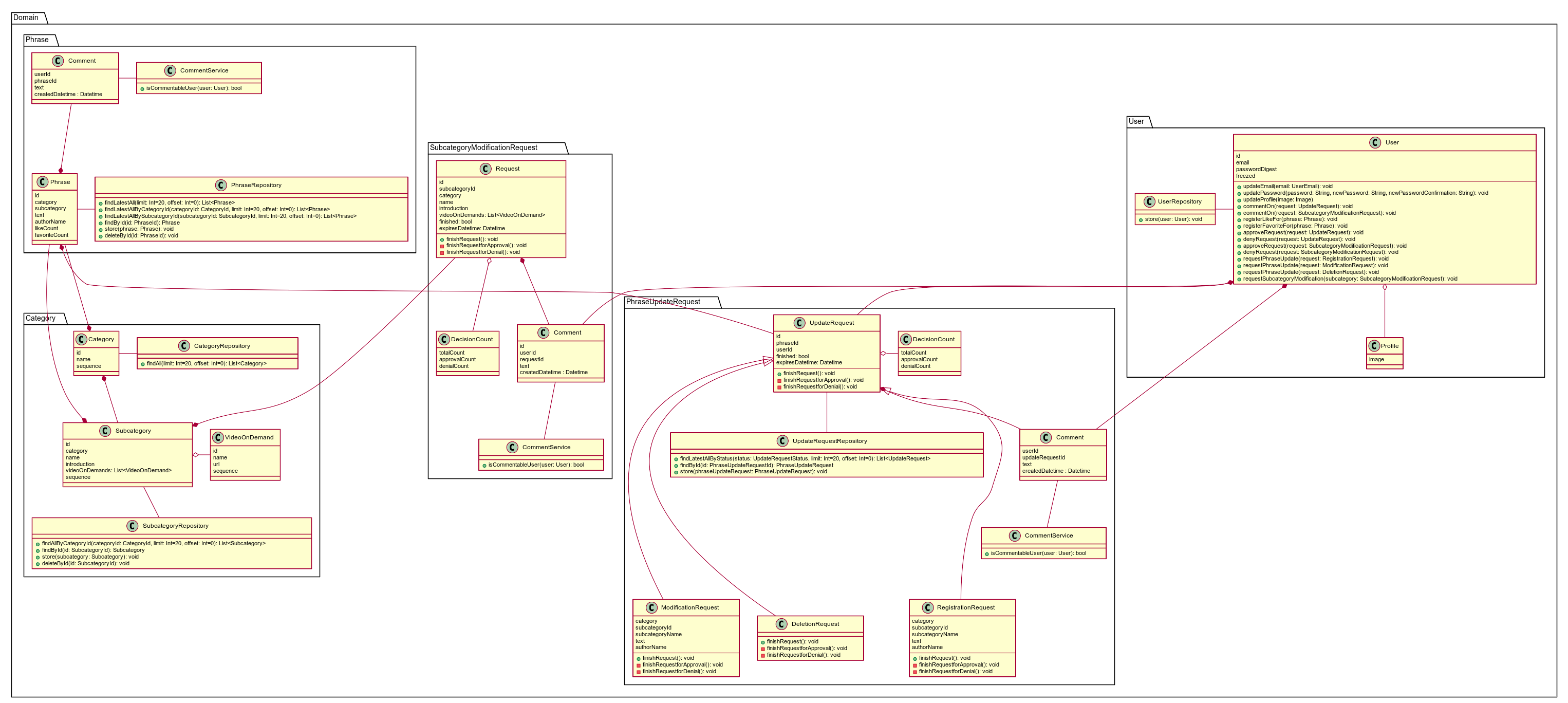
クラス図
実際の設計
| Version 1 | Version2 | Version 3 |
|---|---|---|
 |
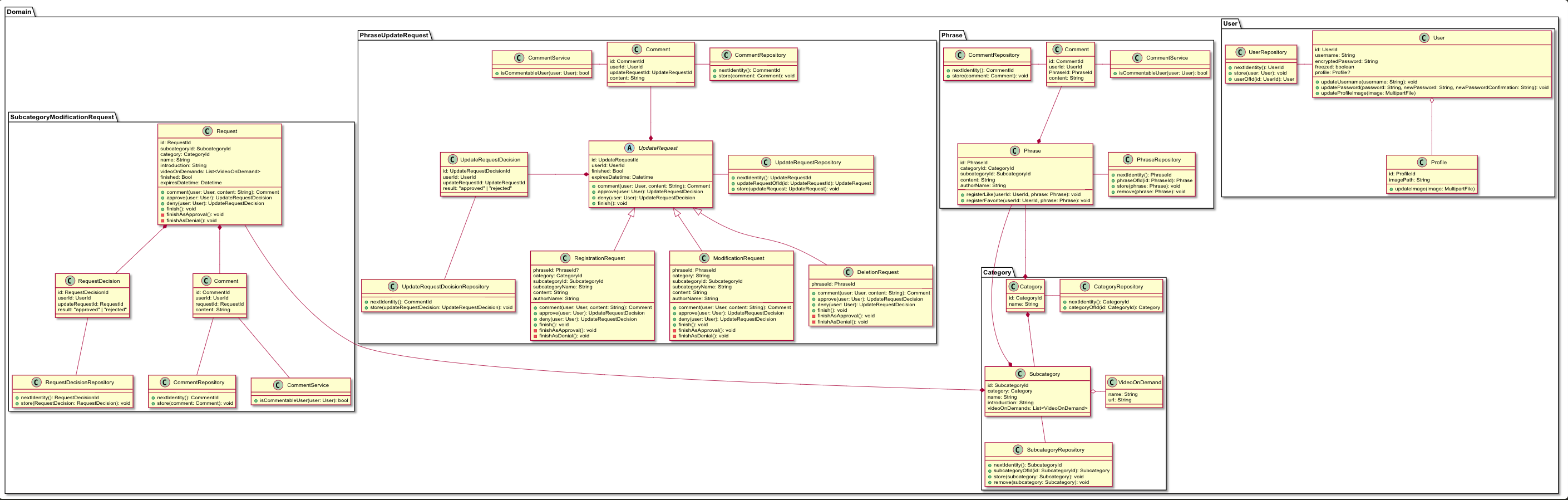 
|
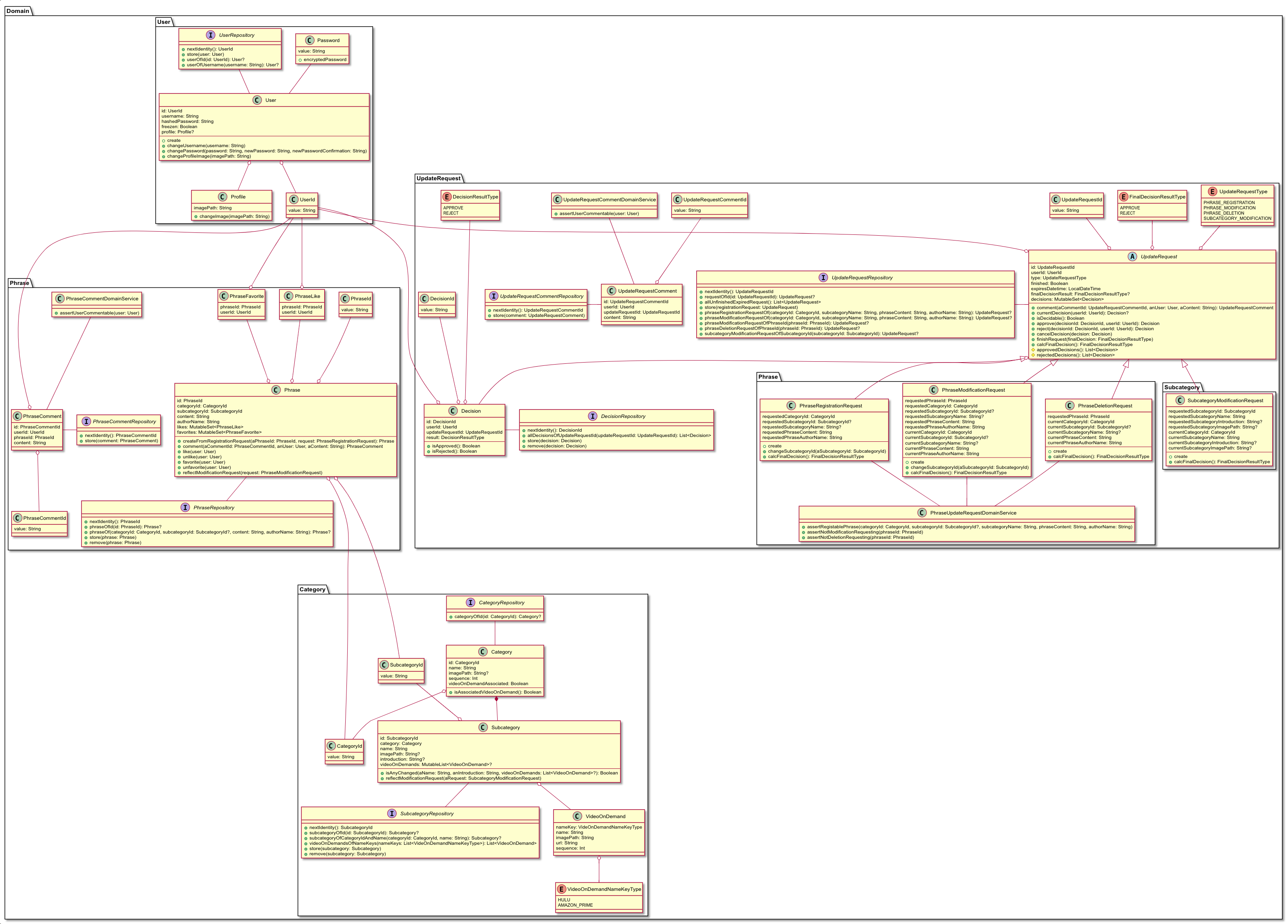 
|
(利用ツール : esa & Visual Studio Code)
それぞれ以下のタイミング・内容で更新された設計になります。
| version | 更新タイミング | 更新内容 |
|---|---|---|
| Version1 | 一番最初に作成。 | - |
| Version2 | クラス図 Version1 作成直後 | Userのもつメソッド(振る舞い)が明らかに多かったことに違和感があり、他の記事を参考に振る舞いを定義するクラスを変更した。 また、取得処理をQueryに切り出すように変更した。 |
| Version3 | 実装途中(前半) | 実装中に必要になったメソッド、不要になったメソッドが多数出てきたので更新した。 |
個人的に今回一番大きい発見だったのは、Version1 → Version2の変更のところですね。
メソッドの置き場所の考え方を改めて考えさせられました。
例えば、「ユーザーが申請を出す」というユースケースをどのように表現するか考えたときに、そのまま英語に直せば
「A user submit a request.」
のようになると思うので、メソッド的には
user.submit(request)
とするのがそのまま読めて綺麗なのかな?というのがVersion1時点での考え方でした。
しかし、Version1のクラス図を見てわかる通り、この考え方でメソッドの置き場所を定義していくと、Userクラスにかなりのメソッド(振る舞い)が集中してしまいます。
(ユースケースの主語になるのは、ユーザーが主であるため。)
逆に、他のクラスのメソッド(振る舞い)が必然的に激減してしまうので、いわゆるドメイン貧血症になってしまうように思えました。
このことに違和感を覚えて、メソッドの置き場所について色々な記事を読んでみたのですが、下の記事が改善の大きなヒントになりました。
ドメインオブジェクトの責務について
https://qiita.com/j5ik2o/items/a64007c6d7a89ec2e086
結論からいうと、上の例で出した「ユーザーが申請を出す」という振る舞いについて定義するのは申請クラスにするようになります。
今までユーザー(アクター)が英文的に主語になる場合は、その主語になるユーザーのクラスに置くべきだと考えていたのですが、そもそもユーザークラスというのは、ユーザーという概念の関心事・振る舞いを定義する場所で、別にそのユーザー自身を示しているわけではないという理由です。
つまり、「申請を出す」というのは、あくまで申請の関心事であり振る舞いであるというのが、上記の記事で言われていることだと思っています。
(上記の記事の場合は、「Customerが銀行口座にお金を預ける」というユースケースについて、同様の例が記述されています。)
当たり前の人にとっては当たり前の事かもしれないのですが、今までここまで深く考えていなかった自分としては、初めてメソッドの定義場所をちゃんと理解したような気がします。
そして、Version2→Version3についてもかなり構造を変更していますが、もちろん1回でここまで大きく改善できたわけではなく、何度も何度も違和感を感じる度に改修を加えていき、最終的にVersion3の形になりました。
(それこそ、実装途中でも5回や6回では済まない回数改修を加えたと思います。)
実際にDDDをやってみて思うのは、やはりこの違和感がある度に細かく改修・改善していくことがとても大切なのかなと感じました。
最初からいい形を作るのはとても難しいと思いますし、それを目指そうとして設計に時間をかけるというのも時間の割に成果が出にくいと思っています。
そのため、チームが最低限納得のいく形になったら、あとは実装中にどんどん話し合って、どんどん改修・改善していく。
これが、DDDにおいては特に大切なのかなと実際にやってみて感じました。
また、
「実装を開始したら、もう設計書の更新はしなくてもいい。」
「コードが設計書の役割を果たす。」
というのも、DDDだとよく言われていることだと思いますが、修正が大きい場合は設計書も見直した方がいいと思っています。
実装を開始して初めて気づく点なども多いと思いますし、特に新しいフレームワークを利用する場合などは見えてない部分も多いと思いますので、実装を開始してからでも設計書を見直した方が、設計書が意味のあるものになる気がしています。
特にチームで開発をする時などは、設計書をみながら開発陣で、
「違和感のある箇所はないか?」
「修正した方が良さそうな箇所はないか?」
定期的に話し合うようにした方が、問題が大きくなる前にどんどん修正していけるので、かなり大切なのかなと思いました。
データモデリング(ER図作成)
実際の設計
| Version 1 | Version 2 |
|---|---|
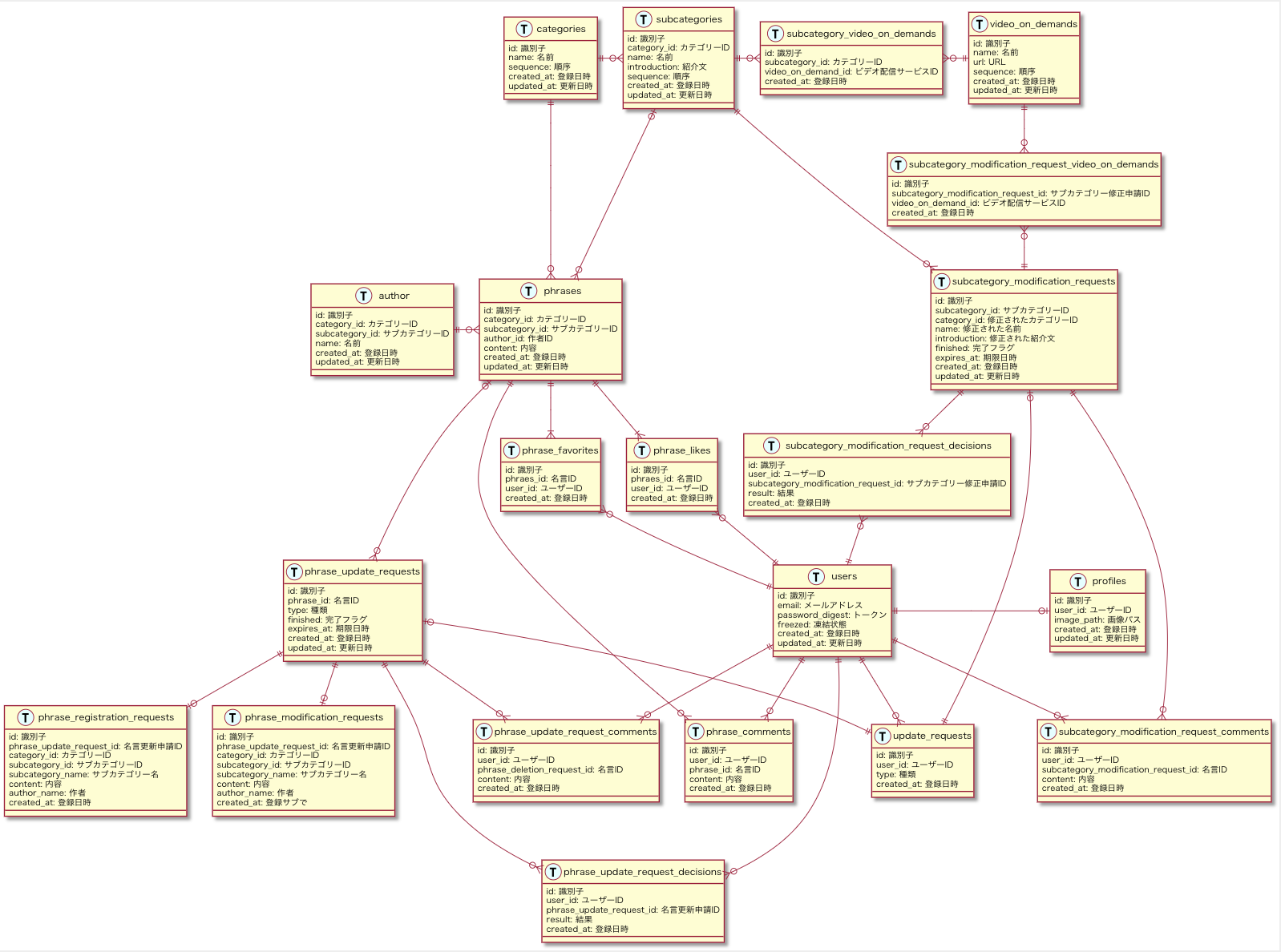 |
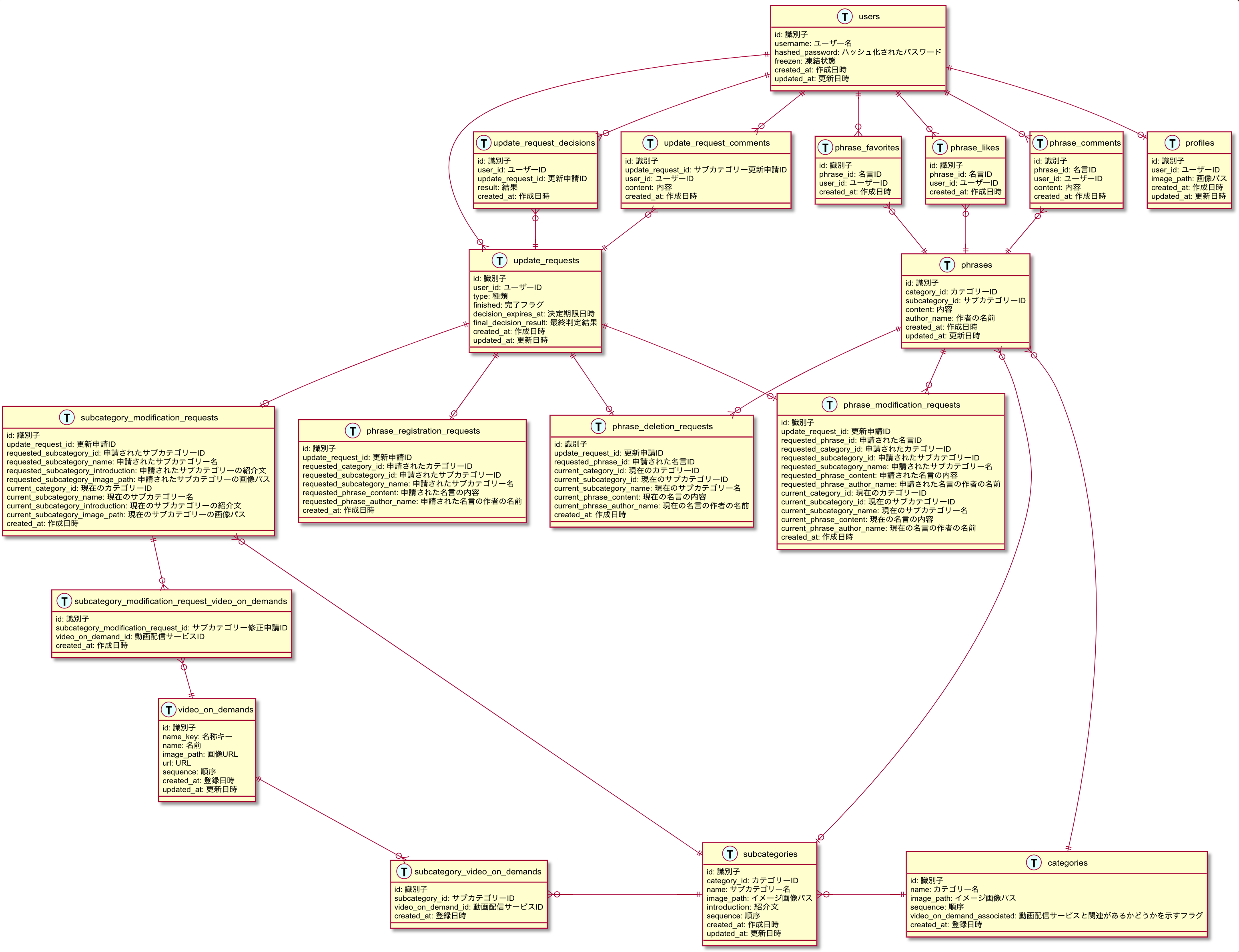 |
(利用ツール : esa & Visual Studio Code)
それぞれ以下のタイミング・内容で更新された設計になります。
| version | 更新タイミング | 更新内容 |
|---|---|---|
| Version1 | 一番最初に作成。 | - |
| Version2 | クラス構成を変更した時 | クラス構成を変更したのに合わせて、テーブル構成も最適化するために更新した。 |
今回、データモデルは設計の一番最後に行ったのですが、その理由は単に自分がDDDに不慣れなので、出来るだけデータ中心に設計を考えないようにするためというだけで、もう少し早いタイミングで行っても問題ないと思います。
今回はER図だけを作成したのですが、本来はテーブル定義(データ型やIndexなどの定義)なども行う方がいいでしょう。
ちなみに、データモデリングについても実装時に大きく修正しました。
少し大きめの変更もあったのですが、思い切って労力を気にせず変更してみた結果、かなりデータ構造をシンプルに改善できたので途中から実装もものすごくやりやすかったと思っています。
実際、Version1とVersion2を比較すると視覚的にもスッキリしているようにみえます。
定期的に開発陣で違和感のある箇所や修正した方がよさそうな箇所がないか話し合った方がよさそうですね。
実装が完了してリリースした後になると、ユーザーのデータなどもあり修正コストも大きくなってしまうので、そうなる前に少しでも違和感のある箇所は全員で話してすぐに対応するのがいいと思います。
実装過程
はじめに
今回は依存関係逆転の原則を取り入れつつ、CQRSのデザインパターンを取り入れました。
CQRSを取り入れた理由は、サービス的に取得時のロジックが少し複雑なので、その複雑さをDomainに持ち込みたくなかったからというものです。
(名言一覧などでは、名言の内容 + 名言に付いているコメント数 + ログイン中のユーザーがその名言にいいね, お気に入りをしているかといった情報を返す必要があります。)
ただし、DBはDomainとQueryで共通のものを利用しています。
(時間がなかったためというのと、DB分けるほど複雑ではないと判断したため。)
また、ORMについてもDomainとQueryで同じものを利用していますが、互いに依存はしないようにしているため、Domain部分だけ別のORMに変更するのは容易な状態にしました。
ソースコード
本番で利用しているものは仕様追加によって改修されてしまうことがあるので、リポジトリは別のものにしてあります。
この記事に記載している設計内容と差が出ないように、設計したところまでの実装を公開しています。
(そのため、最新のアプリの実装とは異なる場合があります。)
利用した技術
API側 言語
Kotlin
(チームで次利用する言語として使う可能性が高かったため採用)
API側 フレームワーク
Spring Boot
(チームで次利用するフレームワークとして使う可能性が高かったため採用)
ORM
Domain : MyBatis
Query : MyBatis
(SQLベースのORMで直感的に使いやすいと思ったので採用。)
アプリ側 言語
React Native
(普段の開発で利用しているというのと、IOS, Android個々に開発するだけの余力がなかったため採用。)
サーバー
Heroku
(未経験の設計手法を未経験の言語・フレームワークで進めていくコストが高かったため、インフラは手を抜く意味でHerokuを採用)
DB
MySQL
(個人的に一番利用することの多いDBだったため採用)
参考にさせていただいたコード
今回開発をするにあたり、以下のコードをかなり参考にさせていただきました。
特に実践ドメイン駆動設計のサンプルである、IDDD_Samplesはかなり参考になったと思っています。
DDDについては、他にも色々なサンプルコードがGithubにありますので、実装を考えていく際はぜひ参考にしてみてください。
IDDD_Samples (Java with Spring Boot)
https://github.com/VaughnVernon/IDDD_Samples
spetstore (Scala with Play Framework)
https://github.com/j5ik2o/spetstore
gyst (Kotlin with Spring Boot)
https://github.com/suusan2go/gyst
ディレクトリー構造
- application : Application層
- batch : バッチ
- domain : Domain層
- infrastructure : Infrastructure層
- domain
- query
- presentation : Presentation層
- api
- controller
- form
- pages : 普通のWebページ
- controller
- query : CQRSのQuery
- dto
- support : AWSの画像アップロード処理や認証処理など
基本的にはDDDで一般的に採用されるディレクトリー構成なのですが、1点だけ、QueryをDomainと並列の階層におくか、Application層の中に置くかは迷いました。
(今回はQueryをDomainと並列の階層に置いています。)
というのも、Queryはほぼデータを取得するだけの処理なので、Application層に渡しても特に何もせずそのままPresentation層に返すことが多いためです。
ただ、Queryの内部ではデータアクセスを行うため、依存関係逆転の原則の中ではその技術的な実装部分はInfrastructure層に置き、QueryはInterfaceとして定義するのが正しいと考えた時に、Application層にクラス定義とインターフェース定義が混ざることに違和感があったため、今回はDomainと同じ階層にQueryというフォルダーを作成することにしました。
(また、個人的にQueryはApplication Serviceと並列の関係というより、Domainと並列の関係というイメージだったのも、今回の判断の要因になりますね。)
ちなみに、実践ドメイン駆動設計のサンプルコードでは、今回とった方法とは別のApplication層の中にQueryを置くようにしているみたいです。
クラス名のSuffixをApplicationServiceにするかQueryServiceにするかで区別するようにしているみたいですね。
今回適用した主な実装ルール
概要
- Infrastructure層でDBから取得した値は、必ずDAOに一度格納してから扱う。
- Queryで取得した値は必ずDTOに格納してからApplication層に渡す。
- Entityの識別子にはそれぞれ専用のValueオブジェクト設ける。
- Domainに関するValidationは基本的にSetterで全て行う。(FormのValidationは利用しない。)
- 全てのEntityの識別子は早期生成する。(識別子にはUUIDを利用する。)
- EntityでRepositoryをDIしてはいけない。
- DomainのServiceクラスからはRepositoryを参照してもよい。
- Factoryは集約にcreateメソッド(クラスメソッド)を用意するようする。
詳細
1. Infrastructure層でDBから取得した値は、必ずDAOに一度格納してから扱う。
今回はDBから取得した値を、例外なく全てDAOに一度格納するようにしました。
なので、Domain層のオブジェクトを生成する際は、DBに問い合わせたデータを一度DAOに格納して、DAOのデータを利用してDomain層のクラスをインスタンス化する流れになりますね。
ちなみに、ここでいうDAOというのは以下のようなデータクラスになります。
data class PhraseDao(
val id: String,
val categoryId: String,
val subcategoryId: String,
val authorName: String,
val content: String,
val createdAt: Timestamp,
val updatedAt: Timestamp
)
全てDAOに一度格納するようにしたのは、DBのスキーマの情報がDomainのオブジェクト生成に出来るだけ影響しないようにしたかったからです。
必要に応じて、一部だけDAOを利用するようにするのもありなのですが、全部DAOを利用するようにした方がわかりやすいと思い、今回は全てDAOを利用するようにしました。
2. Queryで取得した値は必ずDTOに格納してからApplication層に渡す。
こちらも上と似通った理由で、Queryには振る舞いなどはないのですが、DAOはあくまでDBから取得したスキーマをそのままの形式で格納しているので、アプリ側に返却するデータ形式とは異なることがあるため、QueryではDAOをDTOに変換してApplication層に返すような実装にしました。
3. Entityの識別子にはそれぞれ専用のValueオブジェクト設ける。
今回はDomainオブジェクトのプロパティのうちEntityの識別子のみValueオブジェクトにするようにしました。
他のDDDのコードを見ると、全てのプロパティにそれぞれValueオブジェクトを定義しているものもあったりしますが、今回はそうしませんでした。
というのも、実践ドメイン駆動設計のサンプルコードでも基本的に識別子しかValueオブジェクトにしていなかったということと、実践ドメイン駆動設計の本の中でも必ずしも全てのプロパティに対してValueオブジェクトを定義する必要はないといった趣旨のことが書かれていたので、今回は基本的に識別子のみをValueオブジェクトにして、他のプロパティは標準のStringやIntにするようにしました。
例えば、Domain層のSubcategoryクラスの場合、以下のような定義になりますね。
class Subcategory : Entity {
val id: SubcategoryId
var categoryId: CategoryId
var name: String
var imagePath: String?
var introduction: String?
var videoOnDemands: MutableList<VideoOnDemand>? // ← VideoOnDemandのみ識別子以外のValueオブジェクトになる。
...
4. Domainに関するValidationは基本的にSetterで行う。(FormのValidationは利用しない。)
Validationについては、DomainのクラスのSetterで定義するようにしました。
実践ドメイン駆動設計(IDDD)で紹介されていたセーフティープログラミングというやつですかね?
IDDDのサンプルでもそのように実装してあったので、それを参考にさせてもらいました。
具体的には以下のようなコードになりますね。
(assert~ というメソッドは別の場所で定義している値検証用のメソッドです。)
class Phrase : Entity {
val id: PhraseId
var categoryId: CategoryId
var subcategoryId: SubcategoryId?
var content: String
set(value) {
this.assertArgumentNotEmpty(value, "内容を入力してください") // ← contentに値を入れたタイミングでこれらの検証処理が実行される。
this.assertArgumentLength(value, 500, "内容は500文字以内にしてください") // ← 〃
field = value
}
var authorName: String
set(value) {
this.assertArgumentNotEmpty(value, "作者を入力してください") // ← 〃
this.assertArgumentLength(value, 36, "作者は36文字以内にしてください") // ← 〃
field = value
}
...
仮に不正な値が入った場合は、IllegalArgumentException が発生する仕様になりますね。
IllegalArgumentExceptionが発生した場合は、自身で作成したExceptionControllerで例外をcatchしてエラー内容をレスポンスに含めて返すように実装してあります。
このやり方だと、Presentation層のFormやApplication層でいちいちValidationを書く必要もないので、不正な値が混入しにくい上、個人的にはかなり安心感があったのがよかったです。
ただ、1箇所で例外が発生すると他の箇所は見ずにそのままレスポンスを返してしまうので、入力値が複数ある場合などでは、いずれか1つのエラーのみしか返せないのがデメリットですね。
そのため、基本的にはフロント側でValidationまたは条件を満たすまではsubmitできない仕様にする必要がありそうです。
ちなみに、
「他に同じ内容の名言がないか?」
「すでに同じ内容の申請が出されていないか?」
といったDBを参照するようなValidationについては、Application層でRepositoryを利用して行うようにしてあります。
なので、Domainで行うValidationはあくまで値に関するValidationのみですね。
5. 全てのEntityの識別子は早期生成する。(識別子にはUUIDを利用する。)
Entityに識別子がない可能性があることを考慮してくなかったこともあり、今回、識別子に関しては遅延生成ではなく早期生成を採用しました。
早期生成でも、DBを利用して連番を識別子に振っていく方法もあるのですが、都度DBに問い合わせるコストがあるのと、その実装コストを加味して、今回はそのままUUIDを識別子に利用することにしました。
わかってはいたのですが、やはりUUIDだと普通の連番のIDに比べるとDBのデータを見た時に相当見にくかったですね。
UUID例
280D1D4D-9582-4C39-BE61-4D3480B474C1
識別子については、Timestampを最後につけたり、テーブルによってプリフィックスをつけていったりなど、要件によっても色々やり方が分かれるところだと思うので、実際にやるときはチームで考えていくのがよさそうです。
ちなみに、実践ドメイン駆動設計のサンプルコードだと、全て遅延生成でやっているコンテキストと基本はUUIDを利用した早期生成で、イベントに関するテーブルはDBの自動採番を利用するようなコンテキストという具合に、コンテキストによって別の方針で実装されていた気がします。
6. EntityでRepositoryをDIしてはいけない。
色々な記事を見ると、EntityにRepositoryをDIして利用するのはよくないパターンだという意見が多かったです。
なので、今回はEntityではRepositoryをDIしないように実装しました。
例えば、名言登録申請をDBに登録するような処理ではこのようなコードになりますね。
(下のコードはApplication層に書かれているコードになります。)
val request = PhraseRegistrationRequest.create(
updateRequestRepository.nextIdentity(),
user.id,
categoryId,
subcategory?.id,
form.subcategoryName,
form.phraseContent,
form.authorName
)
updateRequestRepository.store(request) // ← ここでrequestをDBに保存している。
実際に、EntityにRepositoryをDIしないようにすると、Application層を見ただけで、どのタイミングでどのオブジェクトが保存, 削除されているのかがわかりやすかったのと、1つのEntityに様々な種類のRepositoryが入ってきて、複雑になるといったこともなかったので、かなりやりやすかった印象です。
ただし、RepositoryをEntityにDIしてはいけないので、Entity内で行う処理に必要な情報は、事前に全て読み込んでおく必要があります。
例えば、今回だと更新申請(Update Request)内に、最終判定結果(Final Decision Request)を出すような処理を設ける場合は、Entityメソッド内でRepositoryを使うことはできないため、予めひもづく全ての判定(Decision)を、UpdateRequestオブジェクトで持っておく必要があります。
コードでいうとこのような状態になりますね。
abstract class UpdateRequest(
val id: UpdateRequestId,
val userId: UserId,
val type: UpdateRequestType,
var finished: Boolean,
val expiresDatetime: LocalDateTime,
var finalDecisionResult: FinalDecisionResultType?,
var decisions: MutableSet<Decision> // ← DecisionをMutableSet型で全て持っている。
) : Entity() {
...
}
UpdateRequestのdecisionsというプロパティにDecisionオブジェクトを持っているという構成になりますね。
UpdateRequestを生成する際にひもづくdecisionsを全て読み込んでおけば、あとはメソッド内でそれらを見て最終判定結果出してを返すだけなので、RepositoryをEntity内で使う必要は無くなります。
ただし、decisionsが1000や2000もひもづくようなら、かなりのメモリをくってしまう上、DBの負荷も高くなってしまうので、その場合はApplication層でRepositoryを利用してDecisionを取得し、取得したDecisionをEntityのメソッドの引数に渡してあげるというやり方の方が良さそうです。
どれだけひもづく可能性があるかでEntityに読み込んでおくべきか、後から読み込むかの判断は分かれますね。
この話は実践ドメイン駆動設計の本の中の、SprintにひもづくBacklogItemを事前に読み込んでおくべきかという話と同様になります。
7. DomainのServiceクラスからはRepositoryを参照してもよい。
EntityではRepositoryをDIしないようにしたのですが、DomainのServiceではやってもいいことに今回はしました。
というのも、DomainのServiceでやるような処理は、DBのデータを参照することを必須とするものが多かったからです。
例えば、今回だと名言の登録申請をする際に、その申請を登録できるかどうかのチェック項目として以下のようなものがあります。
- 全く同じ内容の名言が登録されていないこと。
- 全く同じ内容の名言登録申請が提出されていないこと。
- 全く同じ内容の名言修正申請が提出されていないこと。
このチェックをApplication層で行うと可読性が落ちるというのと、名言登録申請の細かい仕様をApplication層に書くのに抵抗があったという理由で、DomainのServiceクラスを使うことにしたのですが、チェック項目の全てがDB参照を必要とするものでした。
今回の実装だと、DomainのServiceではこのような既存データを参照する処理が多かったので、Entityとは違い、RepositoryのDIを許すようにしました。
8. Factoryは集約にcreateメソッド(クラスメソッド)を用意するようする。
Factoryはconstructorで定義したり、複雑である場合は別クラスに切り出すという手段を取ることが多い気がしますが、今回はEntityにクラスメソッドとして定義するようにしました。
理由としては、Constructorに定義するのだと名前がついていないので目的がわかりにくいと思ったからです。
また、数も量も多くなかったので、別クラスに切り出すほどではないと思い、Entity内に定義するようにしました。
具体的なコードでいうと以下のようになります。
class Phrase : Entity {
// ↓ Kotlinの場合は、このcompanion objectの中に定義したメソッドがクラスメソッドのように扱える。
companion object {
// 登録申請を元に名言を作成する
fun createFromRegistrationRequest(phraseId: PhraseId, request: PhraseRegistrationRequest): Phrase {
return Phrase(
phraseId,
request.requestedCategoryId,
request.requestedSubcategoryId,
request.requestedPhraseContent,
request.requestedPhraseAuthorName
)
}
}
...
}
上のコードは名言登録申請を元にPhraseエンティティを生成するFactoryメソッドです。
個人的には、constructorに定義するよりも、このようにクラスメソッドとして定義した方がわかりやすいと思い、今回はそのようにしました。
よかった事 3つ
1. CQRSはかなりやりやすかった
取得処理(Query)をDomainと完全に切り離せるのはかなり良かったと個人的に思っています。
QueryをいじってDomainがバグることはまず間違いなくないので、影響範囲も把握しやすいですし、かなり安心して作業することができました。
今回はまだ良かったのですが、もう少しデータ構成が複雑になるようなら、Query部分だけElasticsearchを利用するなど、データ構造もDomainの影響を受けないようにした方いいのかなというのが感想ですね。
2. DTOやDAOをきっちり使うのは修正がやりやすかった
これについても、修正した時の影響範囲が把握しやすいのがかなりよかったです。
あとは、DAOはDBから取得するスキーマを表現、DTOはアプリ側に渡すデータ構成を表現という具合に、明確に役割が分かれていたので、取得した時のSQLがめちゃめちゃ複雑になるみたいなこともなく、DAOからDTOに変換するところでフォーマットを変換できたりするので、部分的に見ればシンプルになりやすいのかなと思いました。
このぐらいの規模だと、普通よりたくさんのクラスを作る必要があるので、めんどくさい気もしてしまいますが、規模が大きくなるほど細かくクラスを作って、シンプルにしていくのが大切になりそうだなと感じました。
3. QueryにSQLベースのORM(MyBatis)を利用するのはやりやすかった
普通のオブジェクトベースのORMだと、そのORMの仕様に引きづられて、思ったようにデータが取れなかったりするのですが、SQLベースのORMだと、そのままSQLを書いてデータ取得ができるので、素直に取りたいデータをそのまま取れるのがすごくやりやすかったです。
ただ今回の場合、自分のORM(MyBatis)の理解が浅かったこともあり、より簡単に書けるところを愚直に書いてしまった箇所が多かったので、もう少しMyBatisの使い方を理解しないといけないなというのが反省ですね。
よくなかった事 3つ
1. ファイル名やディレクトリー名の命名規約をちゃんと決めておけばよかった
今回、ファイル名やディレクトリー名の命名規約を全く決めないまま実装に入ってしまったのが、一番後悔した点です。
Ruby on Railsのような事前に命名規約が決められているものと違い、今回はほぼ全て自分で命名を決める必要があったので、事前に命名規約を決めておくべきでした。
決めなかったことで、なんとなくで進めてしまい、いくつか修正が追いついておらず、統一感のない箇所が出てきてしまっています。
一人で開発する時ならまだ最小限で収まりますが、チームで開発する時は必ずディレクトリー構成やその命名、ファイルの命名の規約はきっちり決めておいた方がいいと思いました。
2. URLの命名規約もちゃんと決めておくべきだった
これについても、普段利用しているRuby on RailsだとほぼURLが自動生成されるので、それと同じ感覚でURLについて何も考えず実装に入ってしまい、統一感のない構成になってしまっています。
特にSpring Bootなどの自由度が高いフレームワークを利用する場合は、こういった規約を実装前にしっかり決めておいた方がいいみたいですね。
3. Domainの方のORMはMyBatis以外にしたいかも
Query側でSQLベースのORM(MyBatis)を利用したのは、すごくやりやすかったのですが、Domain側で行うようなInsertやUpdate, Deleteといった処理やシンプルなSelect処理についてはオブジェクトベースのORMを利用した方がやりやすいのかなというのが、今回MyBatis(SQLベースのORM)をDomain側でも使ってみた感想です。
最初はHibernateなどのオブジェクトベースのORMを利用する予定だったのですが、時間的にQuery側と同じORMを利用することにしました。
機会があれば、Domain側だけHibernateを利用するように改修しようと思います。
最後に
まだ本「実践ドメイン駆動設計」を読み終わってから1ヶ月ちょっとですが、実際にDDDでプロダクトを1つ作ってみて、かなり理解が進んだ気がします。
もちろん、まだまだ理解があまいところも多々あるとは思いますが、どうにか1プロダクト形にできるところまではできたので、ここからより理解を進めていければと思っています。
また今回、使ったことのなかったSpring Bootもどうにか使えたというのと、初めてアプリを自分で0から作れたということで、DDD以外にも色々な経験を得ることができたのはすごくよかったです。
この記事に関して疑問点や「自分だったらこうする」「ここは違うんじゃないか?」といった意見などありましたら、ぜひコメントください!
この記事が少しでもあなたの参考になればうれしいです!
それではここまでお読みいただき、ありがとうございました。