https://studio.azureml.net/
http://gallery.azureml.net/
Azure Machine Learningとは?
Azure Machine Learning(AzureML)はマイクロソフトのAzureプラットフォームの内の機械学習サービスです(クラウドAI)。
機械学習のプログラムを書かなくてもデータをAzureMLに投入しモデルの定義だけすれば機械学習の機能が利用できます。
対抗馬としてAmazon Machine Learningがありますが、先行リリースしたAzureMLのほうが機能は豊富です。
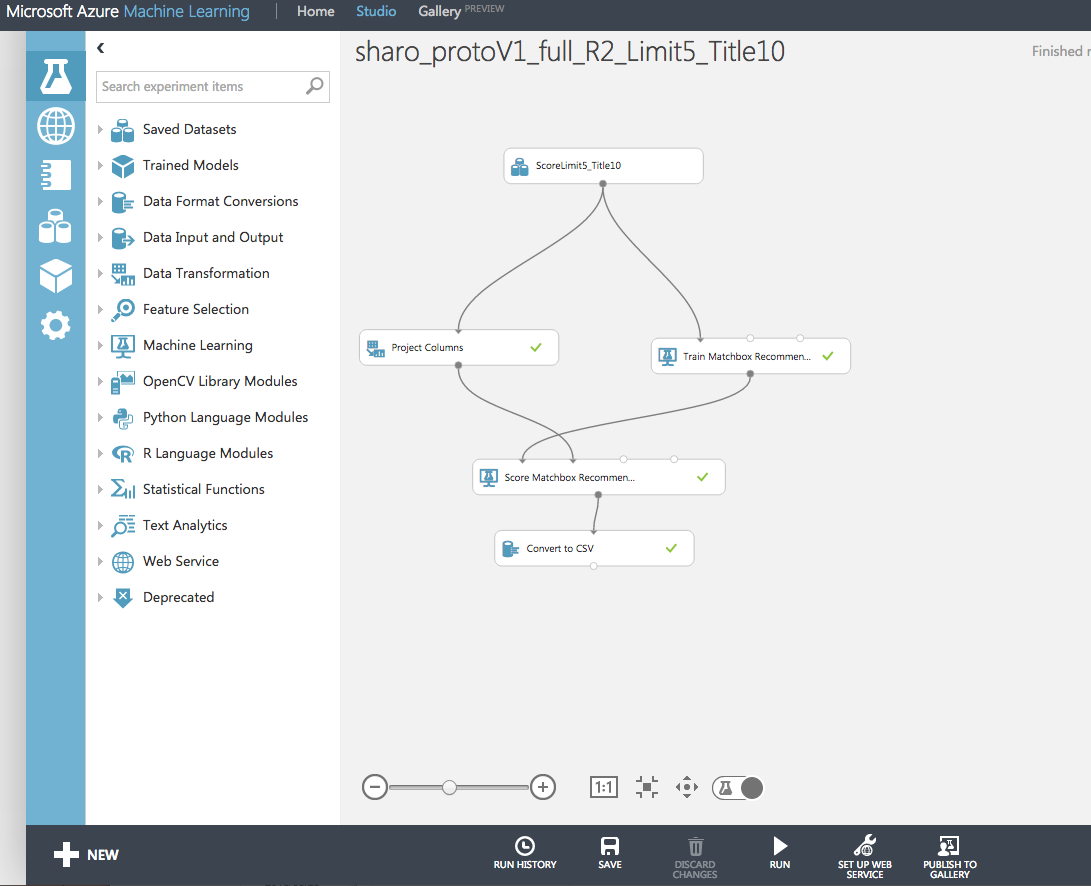
Azure Machine Learning Studioでのモデリングの画面(ブラウザからモデリングできます)
対象のTwitterのデータ
8月15日から9月8日まで(24日分)の「2015年夏期クールのアニメ作品」に関するつぶやきデータ(1100万レコード)
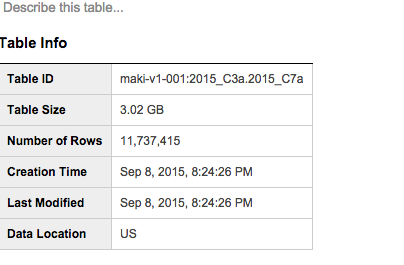
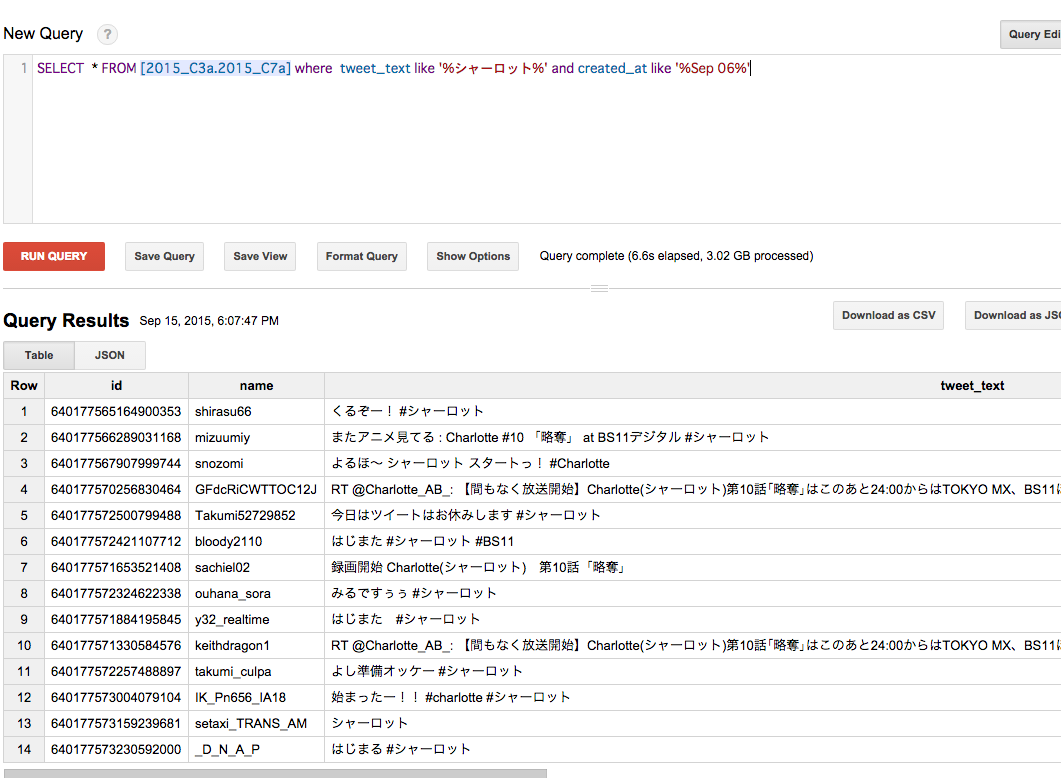
TwitterのデータCSVをGoogle BigQueryのテーブルに変換
TwitterのデータはStreamingAPIでCSVに格納したものを用意します。
CSVの構造
| id | name | tweet_text | source | retweet_count | favorite_count | created_at |
|---|---|---|---|---|---|---|
| 640177573004079104 | twitter_acount | 始まったー!! #charlotte #シャーロット | Twitter for iPhone | 0 | 0 | Sun Sep 06 00:00:01 JST 2015 |
次にデータベースに格納しSQLで集計するためにGoogle BigQueryを使用します。
Google BigQueryに読み込ませるDDL
| カラム名 | 形式 |
|---|---|
| id | INTEGER |
| name | STRING |
| tweet_text | STRING |
| source | STRING |
| retweet_count | STRING |
| favorite_count | INTEGER |
| created_at | STRING |
Google BigQueryでCSVファイルを上げてテーブルに変換するまでは以下の記事に以前書いたので参考にしてください。
Google BigQueryで今期アニメに関するツイートを分析するぞい!
TwitterテーブルをAzureMLの協調フィルタリングに読み込ませるために「評価テーブル」に加工
AzureMLでリコメンドを行うため今回は「協調フィルタリング」のユーザーベースレコメンドという機械学習アルゴリズムを使用します。
AzureMLではこのようなデータ形式にする必要があります。
| ユーザー | 商品 | 評価 |
|---|---|---|
| User1 | ポンカレー | 4 |
| User2 | ポンカレー | 2 |
| User2 | ジャバカレー | 4 |
| User3 | インドカリー | 5 |
「誰がどの商品に何点評価したか?」というデータ形式です。(ユーザーと商品でユニークレコード)
これをツイッターのアニメデータに適用し「誰がどの作品について何回つぶやいたか?」というテーブル形式にします。
ただし、評点に差がありすぎたり、評点が大きすぎるとAzureMLでエラーがでるので評点は5にリミットをかけます。(100回つぶやいても評点は5)。何度か試した結果20以上はスタックオーバーフローが出ました(データによるとは思いますが参考までに)。
| TwitterAccount | title | score |
|---|---|---|
| 000kasyojudo | アイドルマスター シンデレラガールズ 2nd SEASON | 1 |
| 000koma | 下ネタという概念が存在しない退屈な世界 | 5 |
| 000koma | オーバーロード | 5 |
| 000koma | がっこうぐらし | 5 |
| 000ld | がっこうぐらし | 2 |
| 000mikkel000 | オーバーロード | 5 |
先ほどのTwitterのテーブルを評点データに加工するSQLは以下です。
SELECT
name,
title,
IF(sum(score) > 5, 5, sum(score) ) as score
FROM (
SELECT
name,
title,
1 AS score,
FROM (
SELECT
name,
CASE
WHEN tweet_text CONTAINS '城下町のダンデライオン' OR tweet_text CONTAINS 'ダンデライオン' OR tweet_text CONTAINS '城下町のダンデライオン' OR tweet_text CONTAINS '城下町のダンデライオン' OR tweet_text CONTAINS 'dande_anime' THEN '城下町のダンデライオン'
WHEN tweet_text CONTAINS '六花の勇者' OR tweet_text CONTAINS '六花の勇者' OR tweet_text CONTAINS '六花の勇者' OR tweet_text CONTAINS '六花の勇者' OR tweet_text CONTAINS 'rokka_anime' THEN '六花の勇者'
WHEN tweet_text CONTAINS '干物妹!うまるちゃん' OR tweet_text CONTAINS 'うまるちゃん' OR tweet_text CONTAINS '干物妹!うまるちゃん' OR tweet_text CONTAINS '干物妹!うまるちゃん' OR tweet_text CONTAINS 'umaru_anime' THEN '干物妹!うまるちゃん'
WHEN tweet_text CONTAINS 'がっこうぐらし' OR tweet_text CONTAINS 'がっこうぐらし' OR tweet_text CONTAINS 'がっこうぐらし' OR tweet_text CONTAINS 'がっこうぐらし' OR tweet_text CONTAINS 'がっこうぐらし' THEN 'がっこうぐらし'
WHEN tweet_text CONTAINS 'アイドルマスター シンデレラガールズ 2nd SEASON' OR tweet_text CONTAINS 'シンデレラガールズ' OR tweet_text CONTAINS 'デレマス' OR tweet_text CONTAINS 'モバマス' OR tweet_text CONTAINS 'imas_cg' THEN 'アイドルマスター シンデレラガールズ 2nd SEASON'
WHEN tweet_text CONTAINS 'GATE 自衛隊 彼の地にて、斯く戦えり' OR tweet_text CONTAINS 'ゲート' OR tweet_text CONTAINS 'GATE' OR tweet_text CONTAINS 'GATE 自衛隊 彼の地にて、斯く戦えり' OR tweet_text CONTAINS 'gate_anime' THEN 'GATE 自衛隊 彼の地にて、斯く戦えり'
WHEN tweet_text CONTAINS 'Charlotte(シャーロット)' OR tweet_text CONTAINS 'シャーロット' OR tweet_text CONTAINS 'Charlotte(シャーロット)' OR tweet_text CONTAINS 'Charlotte(シャーロット)' OR tweet_text CONTAINS 'シャーロット ' THEN 'Charlotte(シャーロット)'
WHEN tweet_text CONTAINS '監獄学園(プリズンスクール)' OR tweet_text CONTAINS 'プリズンスクール' OR tweet_text CONTAINS '監獄学園(プリズンスクール)' OR tweet_text CONTAINS '監獄学園(プリズンスクール)' OR tweet_text CONTAINS 'プリズン' THEN '監獄学園(プリズンスクール)'
WHEN tweet_text CONTAINS '下ネタという概念が存在しない退屈な世界' OR tweet_text CONTAINS '下セカ' OR tweet_text CONTAINS '下ネタという概念が存在しない退屈な世界' OR tweet_text CONTAINS '下ネタという概念が存在しない退屈な世界' OR tweet_text CONTAINS 'shimoseka' THEN '下ネタという概念が存在しない退屈な世界'
WHEN tweet_text CONTAINS 'オーバーロード' OR tweet_text CONTAINS 'オーバーロード' OR tweet_text CONTAINS 'オーバーロード' OR tweet_text CONTAINS 'オーバーロード' OR tweet_text CONTAINS 'overlord_anime' THEN 'オーバーロード'
ELSE NULL END AS title
FROM [2015_C3a.2015_C7a] ) )
WHERE
title IS NOT NULL group by name, title order by name
2015年夏期のアニメは40作品程度ありますが、数が多いと男女のアニメがまざったりするので今回は独断と偏見でメジャー作品と思われる作品タイトルに絞っています。
評点データCSVをGoogle Cloud Storageからダウンロード
出力結果のレコードは40万レコードあるのでGoogle BigQueryからデータを保存できません。
一度テーブルにデータを保存しGoogle Cloud Storageにエクスポートします。
「Save as Table」を押下
「Destination table」にテーブル名を記入
Export Tableを押下
Google Cloud Storage にCSVファイルをエクスポートする。
(参考) Azureプラットフォームなのに、あえてGoogle BigQueryを使う理由
クラウドAIにデータを格納する場合、対象となる機械学習のアルゴリズムに合わせてデータを加工する必要は必ずあります。
対象がビッグデータの場合は通常のRDSでは処理がおいつかないため、Google BigQuery、Amazon Refshiftに代表されるMPPデータベースを使うのがベターです。しかしMicrosoftのAzureプラットフォームにはMPPデータベースは存在せず、SQL Serverを無理やり使うかHDInsight(Azure上で動くHortonworksのHadoop)を用意してHive or Sparkを使う必要があります。
Azure公式サイトによればHDInsightは20分でクリックインストールできるらしいですが、SQLをぶん投げたいためにわざわざHDInsightを構築するのは大げさです。

| クラウドAI | データ加工のために使うべきプラットフォーム | 個人的お勧め度 |
|---|---|---|
| Amazon Machine Learning | Redshift | (・∀・) |
| Azure Machine Learning | Google BigQuery | (・∀・) |
| Azure Machine Learning | Azure SQL Server | (´・ω・`) |
| Azure Machine Learning | Azure HDInsight | (´・ω・`) |
Azure Machine Learning Studioに「評価テーブル」をアップロード
https://studio.azureml.net/
Azure Machine Learning Studioにログインします。

「my experiments」をクリック
左のサイドメニューの「DATASETS」をクリック
左下の「+」をクリック
「FROM LOCAL FILE」をクリック
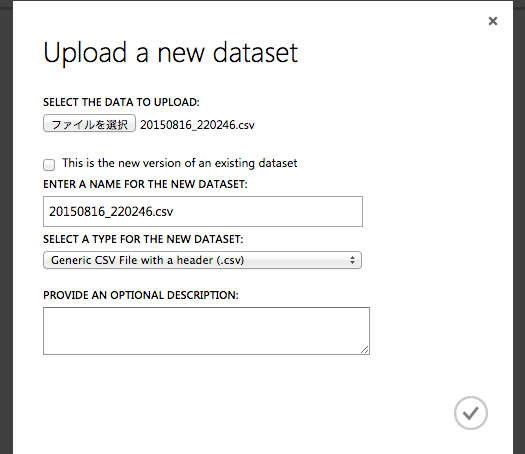
ローカルのファイルを選択する。
DATA TYPEは拡張子から判定してるため、拡張子がないファイルを選択する場合は自分で選択する必要がある。

アップロードすると下のバーに進捗が表示される。
ファイルを機械学習専用のデータ形式に変換しているためかはわからないがサイズに比べてかなりアップロードには時間がかかる。
completedが表示されるまで待つ。
Azure Machine Learning Studioでモデル作成、レコメンド
左メニューから「EXPERIMENT」を選択し左下の「+」ボタンを押下
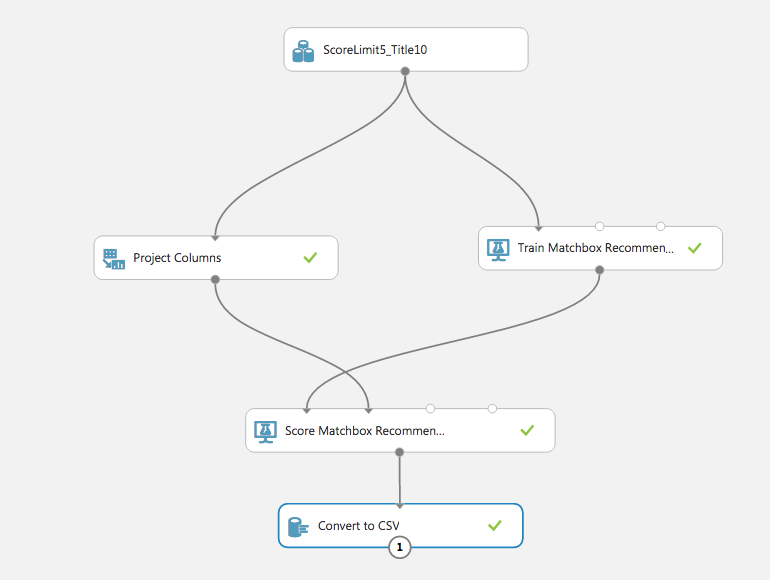
キャンバスが表示されるので以下のパーツをキャンバスに配置していく。
- ① Saved Datasets -> My Datasetsを選択し先ほどアップロードしたファイルを配置
- ② Machine Learning -> Train -> MatchBox Recommender
- ③ Data Transformation -> Manipulation -> Project Columns
- ④ Machine Learning -> Score -> Score MatchBox Recommender
- ⑤ Data Format Conversions -> Convert to CSV
配置したらこの絵のように紐づける
各種パーツの設定
MatchBox Recommender
デフォルト設定のまま
Project Columns
Launch column selectorを押下
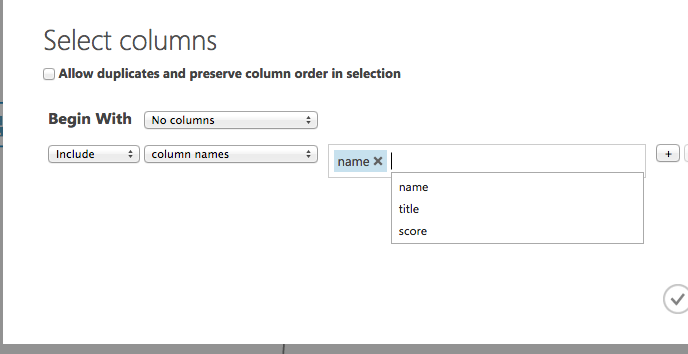
nameをカラムに指定
Score MatchBox Recommender
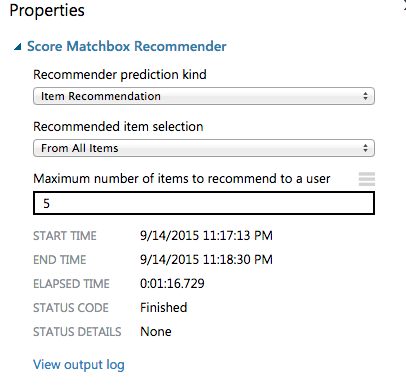
Recommended item selectionを「From All items」にする
RUNを実行
キャンバスの配置と設定が終わったらRUNを押下し機械学習エンジンを実行します。
データ量が大きいのとテーブルの正規化をしていないこともありますが、40万レコード(40万ユーザー)に11商品のうち5商品を推薦するのに10〜30分程度かかります。
Azureのサーバーで動作しているのでブラウザを閉じても大丈夫です。時間がかかりそうだったらブラウザを一旦閉じましょう。
レコメンドの結果確認
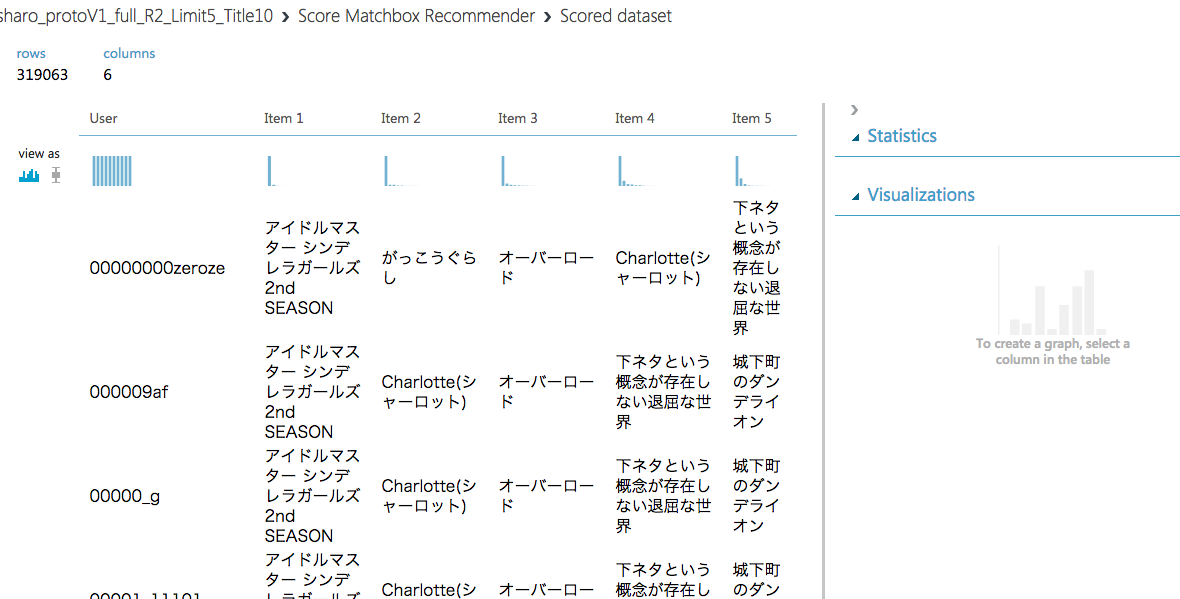
Score MatchBox Recommenderで一部データを確認
Score MatchBox Recommenderを右クリックし「Scored dataset -> Visualize」を選択するとリコメンドの先頭データを閲覧できます。
Item1が一番そのアカウントに推薦すべき作品になります。
CSVファイルをダウンロードして確認
「Convert to CSV」を選択し右クリックResult datasetをクリックしDownloadを選択しブラウザからダウンロード。

協調フィルタリングでの推薦のため、あるユーザーが**「がっこうぐらし」についてしかTwitterでつぶやいていなくても、「アイドルマスター」**を第一推薦作品としてリコメンドできています。
作成したリコメンドデータの活用方法
作成したリコメンドモデルはそのままAzure WEBサービスとしてデプロイでき、ユーザーIDを引数にリコメンドできたりしますが挙動が多少怪しいのとAzure APIサーバーは従量課金対象になるためあまりお勧めしません。
データをSQLサーバーにつっこんで自前で作ったリコメンドサーバー(SinatraとかPlayとか)がそれを読み込みAPIでJSONなどを返すというアプローチが今は安全でベストな方法だと思います。
Azure MLの所感
機械学習の前提知識が多少は必要とはいえ、機械学習アルゴリズムを実装したエンジンを用意する必要がなく、データを突っ込んで
アルゴリズムを選択してブラウザでポトペタすればマイクロソフトの巨大AIインフラを利用できるのは素晴らしいと思います。
ブラウザでエンジンを起動すると30分〜1時間待たされるのは旧世代の大型コンピューターのイメージ彷彿とさせます。
個人で強力な巨人の力(クラウドAI)を使える素晴らしい時代になったので、いい使い方をどんどん考案したいと思えるいいサービスだと思います。