データ活用の重要性が叫ばれる現代において、ウェブからの情報収集はもはや欠かせない技術となっています。
しかし、取得した生のHTMLデータは構造が複雑で、そのままでは扱いにくいと感じることも多いのではないでしょうか?
特に最近では、LLMを活用したAI開発が盛んですが、AIに効率よく理解させるには、ただのテキストではなく、構造化されたデータが求められます。
そこで今回ご紹介したいのが、「ウェブサイトの情報をMarkdown形式でスクレイピングする」という方法です。
Markdownはシンプルながらも情報の構造を保持し、人間にとってもAIにとっても非常に読みやすいフォーマットです。
そして、このプロセスを劇的に簡単かつ強力にしてくれるのが、世界有数のウェブデータプラットフォーム「Bright Data」です。
本記事では、ウェブスクレイピングの基本から、Pythonでの実践例、そしてBright Dataがいかにこの作業を革新するかを深掘りしていきます。
1. ウェブスクレイピングの基本と直面する壁
ウェブスクレイピングの基本的な流れは:
目的のウェブサイトにアクセス → HTMLコンテンツを取得 → その中から必要な情報を抽出する
というものです。
一見シンプルに思えますが、実際には様々な障壁にぶつかります。
1.1. 静的サイトと動的サイトの違い
- 静的サイト: サーバーから直接HTMLが提供され、比較的容易にデータ抽出が可能です。
- 動的サイト: JavaScriptを使用してコンテンツがロードされるため、単純なHTTPリクエストだけでは完全な情報を取得できません。ブラウザのレンダリングをシミュレートするツール(例: Selenium)が必要になります。
1.2. 厄介なアンチスクレイピング対策
多くのウェブサイトは、ボットによる過剰なアクセスやデータ抽出を防ぐために様々な対策を講じています。
- IPアドレスのブロック: 短期間に大量のリクエストを送信すると、IPアドレスがブロックされ、アクセスできなくなります。
- CAPTCHA: 人間であることを証明するためのテストが表示され、自動化されたスクレイピングが困難になります。
- JavaScriptによるコンテンツ保護: 動的サイトでは、JavaScriptが無効化されているとコンテンツが表示されないことがあります。
- 複雑なHTML構造: 意図的にHTML構造を複雑にしたり、頻繁に変更したりすることで、スクレイピングツールを無効化しようとすることもあります。
これらの課題を自力で解決しようとすると、多大な時間と労力、そして高度な技術が必要となります。
2. HTMLデータをMarkdownへ変換するメリット
では、なぜ取得したHTMLデータをわざわざMarkdownに変換する必要があるのでしょうか?その理由は主に以下の3点に集約されます。
2.1. LLMとの親和性:AIの理解度を向上
最近のAI、特にLLMは、情報が適切に構造化されているほど、その内容を正確に理解し、活用できます。
Markdownは、見出し、リスト、リンク、画像などの基本的な構造をシンプルかつ明示的に表現できるため、LLMにとって非常に「消化しやすい」形式なのです。
Bright Dataのデータフォーマットベンチマークでも、MarkdownはLLMの取り込みに最適なフォーマットの一つとされています。
2.2. 人間にも優しい可読性:構造を保ちつつシンプルに
生のHTMLはタグが大量にあり、人間が読むには非常に煩雑です。
一方でMarkdownは、シンプルな記法で情報の階層や強調を表現できるため、構造を損なわずに高い可読性を保てます。これにより、抽出したデータを人間が手作業で確認・編集する際も効率が向上します。
2.3. 効率的なデータ活用:整理されたデータは二次利用に最適
整理されたMarkdownデータは、レポート作成、コンテンツ管理システムへのインポート、データベースへの格納など、様々な用途でスムーズに二次利用できます。余分なHTMLタグを取り除き、本質的な情報だけを抽出することで、データ処理のパイプライン全体を効率化できます。
3. Python実践
まずは、Pythonを使ってウェブサイトをスクレイピングし、Markdownに変換する基本的な手順を見ていきましょう。
静的サイトと動的サイトそれぞれに対するシンプルなアプローチをご紹介します。
3.1. 静的サイトのスクレイピングとMarkdown変換
requestsライブラリでHTMLを取得し、html2textライブラリでMarkdownに変換する例です。
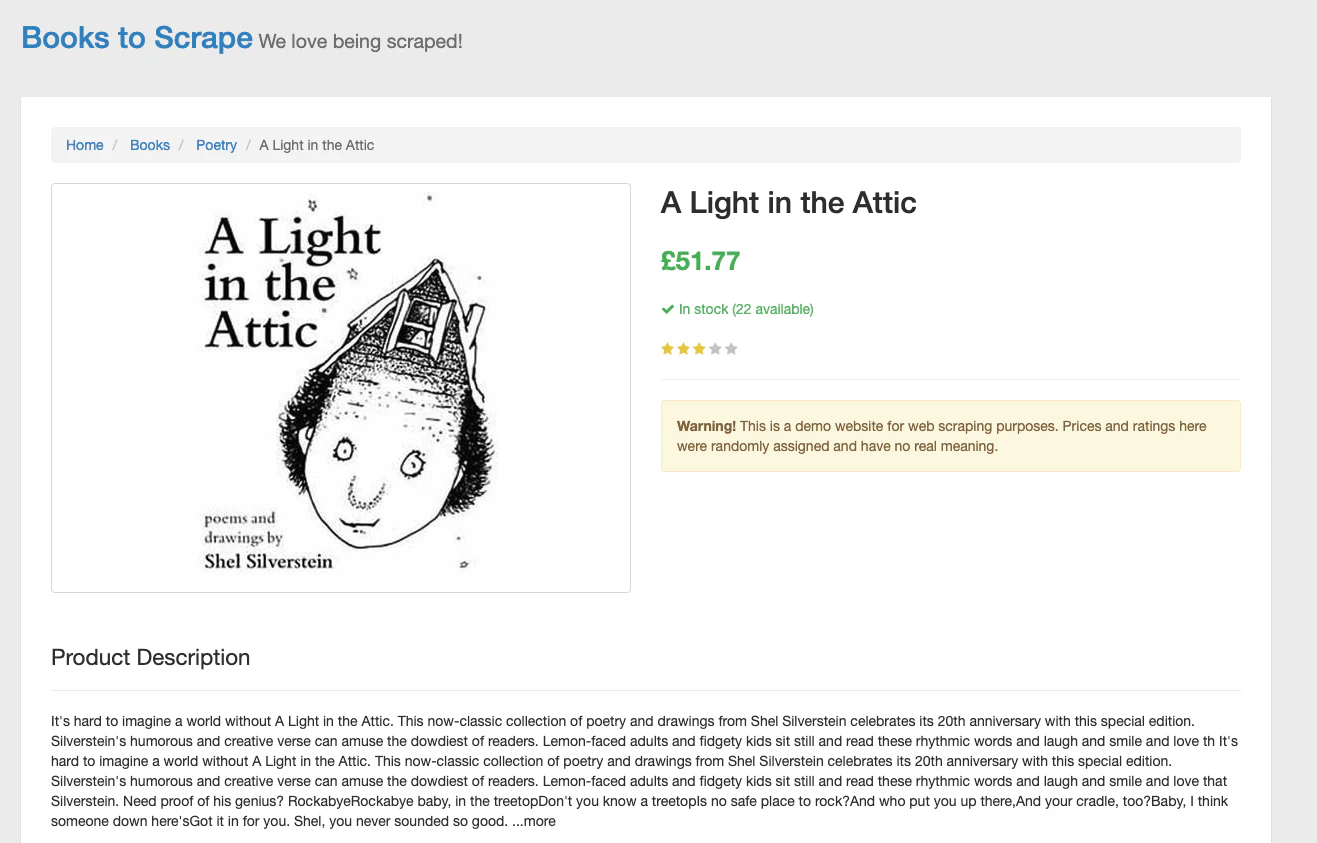
▶️ ダミーサイト Books to Scrape
import requests
from html2text import html2text
def scrape_static_site_to_markdown(url):
"""
静的サイトのHTMLを取得し、Markdown形式に変換します。
"""
try:
response = requests.get(url)
response.raise_for_status() # HTTPエラーがあれば例外を発生
markdown_content = html2text(response.text)
return markdown_content
except requests.exceptions.RequestException as e:
print(f"Error during request to {url}: {e}")
return None
# 例:静的コンテンツが豊富なサイトをスクレイピング
url_static = "http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"
markdown_data_static = scrape_static_site_to_markdown(url_static)
if markdown_data_static:
print("--- Static Site Markdown ---")
print(markdown_data_static[:1000]) # 最初の1000文字のみ表示
▶️ 結果
--- Static Site Markdown ---
[Books to Scrape](../../index.html) We love being scraped!
* [Home](../../index.html)
* [Books](../category/books_1/index.html)
* [Poetry](../category/books/poetry_23/index.html)
* A Light in the Attic

# A Light in the Attic
£51.77
__In stock (22 available)
__________
* * *
**Warning!** This is a demo website for web scraping purposes. Prices and
ratings here were randomly assigned and have no real meaning.
## Product Description
It's hard to imagine a world without A Light in the Attic. This now-classic
collection of poetry and drawings from Shel Silverstein celebrates its 20th
anniversary with this special edition. Silverstein's humorous and creative
verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids
sit still and read these rhythmic words and laugh and smile and love th It's
hard to imagine a world without A Light in the Attic. This now-classic
collect
このコードは、シンプルな静的サイトであれば問題なく動作します。しかし、JavaScriptでコンテンツが生成される動的サイトでは、次のステップが必要になります。
3.2. 動的サイトのスクレイピングとMarkdown変換
Seleniumとwebdriver_managerを使ってヘッドレスブラウザを操作し、JavaScriptがレンダリングされた後のHTMLを取得する例です。
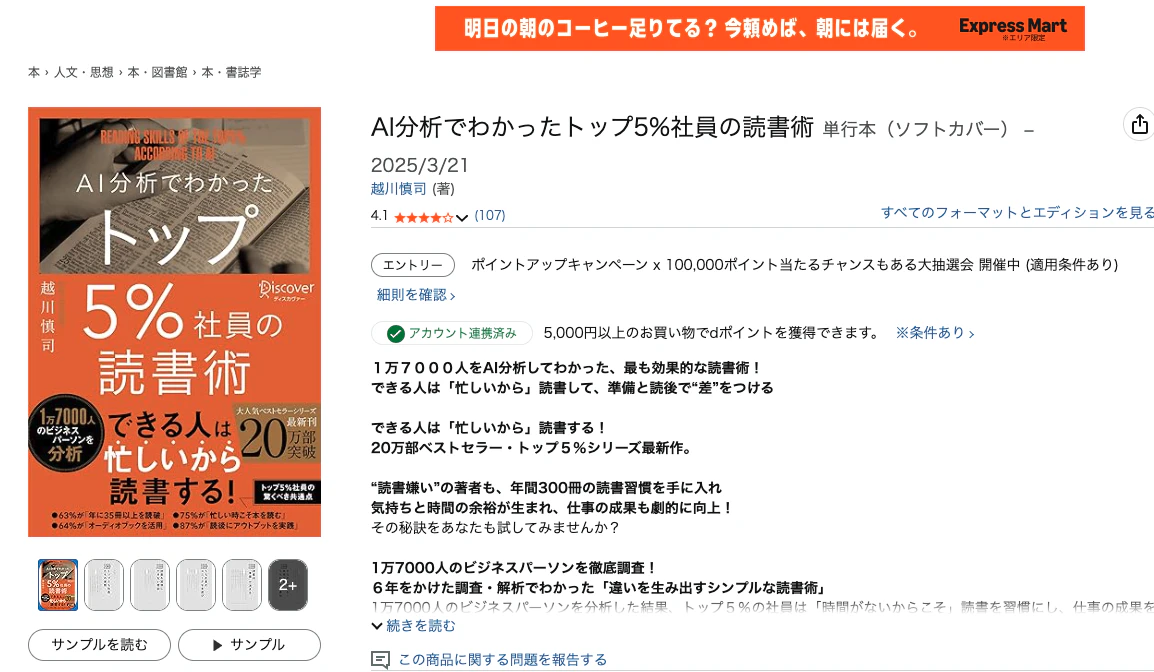
▶️ 動的コンテンツが多いサイト(Amazon)をスクレイピング
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from html2text import html2text
import time
def scrape_dynamic_site_to_markdown(url):
"""
動的サイトのHTMLをヘッドレスブラウザで取得し、Markdown形式に変換します。
"""
# Chromeオプションを設定
chrome_options = Options()
chrome_options.add_argument("--headless") # GUIなしで実行
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# WebDriverを設定
# ChromeDriverManagerが自動的に適切なChromeDriverをダウンロード・インストールします
try:
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get(url)
time.sleep(3) # ページの動的コンテンツがロードされるのを待つ
html_content = driver.page_source
driver.quit()
markdown_content = html2text(html_content)
return markdown_content
except Exception as e:
print(f"Error during dynamic scraping of {url}: {e}")
return None
# 例:
url_dynamic = "https://www.amazon.co.jp/gp/aw/d/4799331094/"
markdown_data_dynamic = scrape_dynamic_site_to_markdown(url_dynamic)
if markdown_data_dynamic:
print("\n--- Dynamic Site Markdown ---")
print(markdown_data_dynamic[:1000]) # 最初の1000文字のみ表示
▶️ 結果:
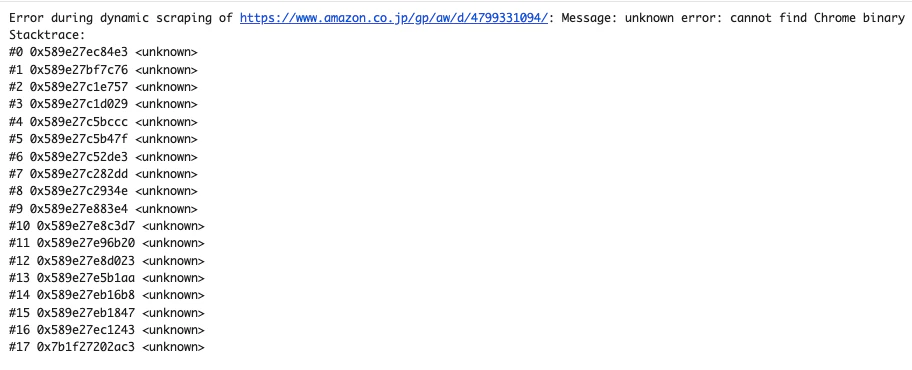
これらのコードは基本的なアプローチを示していますが、実際やってみたら前述したアンチスクレイピング対策により、簡単にブロックされてしまうことがあります。特に大規模なデータ収集や、頻繁に構造が変わるサイトからの収集には、より堅牢なソリューションが不可欠です。
4. Bright Dataでスクレイピングの壁を乗り越える!
「もっと手軽に、確実に、そして大規模にウェブデータを取得したい!」そんなニーズに応えるのが、Bright Dataのソリューションです。
Bright Dataは、複雑なウェブスクレイピングの課題を根本から解決し、高品質なデータを効率的に提供してくれます。
4.1. Bright Dataの強力なインフラストラクチャ
Bright Dataは、195カ国以上、1.5億以上のリアルIPを持つ巨大なプロキシネットワークを保有しており、IPブロックを回避できます。さらに、CAPTCHA解決、JavaScriptレンダリング、そして自動スケーリングといった、スクレイピングを成功させるために必要な全ての技術をクラウドベースで提供します。これにより、ユーザーはインフラの構築やメンテナンスに頭を悩ませることなく、データ収集そのものに集中できます。
4.2. Web Unlocker: あらゆるサイトをアンロックし、Markdownで提供
Bright DataのWeb Unlockerは、ウェブ上のあらゆるページのHTMLを自動的に取得・アンロックできるAPIです。
アンチスクレイピング対策が施されたサイト、静的・動的を問わず、Bright Dataが全ての困難な処理をバックエンドで担当します。
そして、最も魅力的な点の一つは、LLMに最適化されたクリーンなMarkdown形式で直接データを返してくれることです。
これにより、複雑なHTML-to-Markdown変換ライブラリを自分で選定・実装する必要がなくなります。Bright Dataが最高の状態で変換してくれるため、そのままAIエージェントに渡すことが可能です。
4.3. Crawl API: 構造化データを多様な形式で取得
もし特定のURLリストに基づいて大規模なクロールを実行したい場合は、Crawl APIが強力な味方になります。
このAPIは、HTML、JSON、CSV、そしてもちろんMarkdown形式で、ウェブサイトのコンテンツを効率的に抽出し、構造化されたデータとして直接データベースなどに配信できます。カスタマイズ性も高く、高度なクロール設定が可能です。
5. LlamaIndex連携でAIエージェントにWebデータを活用させる
最近注目されているのが、LLMを外部ツールやデータソースに接続するためのフレームワークであるLlamaIndexです。
Bright DataはLlamaIndexとの連携を強力にサポートしており、これによりAIエージェントがリアルタイムのウェブデータにアクセスし、Markdown形式で情報を取得することが可能になります。
以下のPythonコードは、LlamaIndexのBrightDataToolSpecを使ってウェブページをMarkdownとしてスクレイピングする例です。
from llama_index.tools.brightdata import BrightDataToolSpec
# BrightDataToolSpecを初期化
# "YOUR_BRIGHTDATA_API_KEY" を実際のAPIキーに置き換えてください
# Bright DataアカウントでAPIキーを取得できます。
bright_data_tool = BrightDataToolSpec(api_key="YOUR_BRIGHTDATA_API_KEY")
# このメソッド一つで、アンチボット対策を回避し、JavaScriptがレンダリングされたクリーンなMarkdownコンテンツが手に入ります。
# zoneパラメータは、Bright Dataで設定したゾーン名に合わせて変更してください。
bright_data_tool.scrape_as_markdown(url="https://www.amazon.co.jp/gp/aw/d/4799331094/", zone="web_unlocker1")
print("--- LlamaIndex + Bright Data Markdown ---")
print(markdown_content.text)
▶️ 結果: 一部抜粋
ギフトの設定
#####
中古品 - 良い
¥929¥929 税込
配送料 ¥350 11月27日-28日にお届け
発送元: ゆずの木書店
販売者: ゆずの木書店
¥929 ¥929 税込
【帯付き】■中古品として比較的良好な状態です。■記載のない場合、付録や特典(CD・ポスターなど)の付属はございません。また、帯・ハガキなど封入物の付属も原則ございません。■中古品のため気を付けておりますが、見落としによる多少の傷み・汚れ・わずかな書き込み等はご容赦下さい。 【帯付き】■中古品として比較的良好な状態です。■記載のない場合、付録や特典(CD・ポスターなど)の付属はございません。また、帯・ハガキなど封入物の付属も原則ございません。■中古品のため気を付けておりますが、見落としによる多少の傷み・汚れ・わずかな書き込み等はご容赦下さい。 [一部を表示](javascript:void\(0\))
配送料 ¥350 11月27日-28日にお届け
[詳細を見る](/gp/aag/details/?seller=A1W9E48I77YGVK&sshmPath=shipping-rates)
この連携により、AIエージェントはLlamaIndexを介してBright Dataの強力なスクレイピング能力を直接利用し、ウェブから常に最新かつ構造化されたMarkdown形式の情報を取得できるようになります。AIもより賢く、より情報に基づいた意思決定を行えるようになり、ビジネスインテリジェンスや自動化の可能性が大きく広がります。
6. まとめ
本記事では、ウェブサイトをMarkdown形式でスクレイピングすることの重要性、そのメリット、そしてPythonでの基本的な実装方法をご紹介しました。
さらに、Bright DataのWeb UnlockerやCrawl APIが、いかにしてこのプロセスにおける技術的な課題を解決し、信頼性の高いデータ収集を実現するかを詳しく解説しました。
複雑なアンチスクレイピング対策に煩わされることなく、常にクリーンで構造化されたウェブデータを手に入れたいなら、Bright Dataは間違いなく強力なパートナーとなるでしょう。
特に、LLMを利用したAI開発において、高品質なMarkdownデータはAIの性能を最大限に引き出すための鍵となります。
Bright Dataは、Webデータを扱う手段のひとつとして検討できる選択肢です。
実際の挙動や使い勝手を確認したい場合は、公式のトライアル環境を利用して試してみるのもよいでしょう。
👉 Bright Dataを今すぐ試す(無料トライアルはこちら)
通常、新規登録後は「Playgroundモード」と呼ばれる無料トライアルが自動的に開始し、2ドルの少量クレジットが付与されます。
期間限定で今回のリンクを経由して新規登録していただくと、通常の2ドルに加え、さらに10ドルのクレジットが付与されます!
より多くの機能をじっくり試せるチャンスですので、ぜひご活用ください!