ニュース
1. フロンティアモデルを誰に出すかを、政府が左右する構図が固まってきた

OpenAIは次期モデルGPT-5.6シリーズ(旗艦のSol、バランス型のTerra、低コストのLuna)を、米政府の要請を受けて先行提供の範囲を当初計画より絞り込んだ。CodexとAPIを通じて、まずおよそ20社の信頼できるパートナーに限って提供する限定プレビューとして公開した。要請したのは国家サイバー長官室(ONCD)と科学技術政策局(OSTP)で、Sam Altman CEOは、長期のレッドチーム期間そのものは妥当だとしつつ、どの顧客が先に使えるかを政府が決めることには同意できないと述べた。同じ週、Anthropicは輸出管理を理由に一時停止していたMythos 5へのアクセスを、重要インフラを運用・防御する一部の米組織に限って再開した。フロンティアモデルの提供範囲に政府が踏み込むのは前例がなく、誰がモデルを使えるかが安全保障上の論点になり始めている。
Source: https://openai.com/index/previewing-gpt-5-6-sol/
Source: https://www.anthropic.com/news
2. コーディングのベンチマークの信頼性が、一気に論点になった
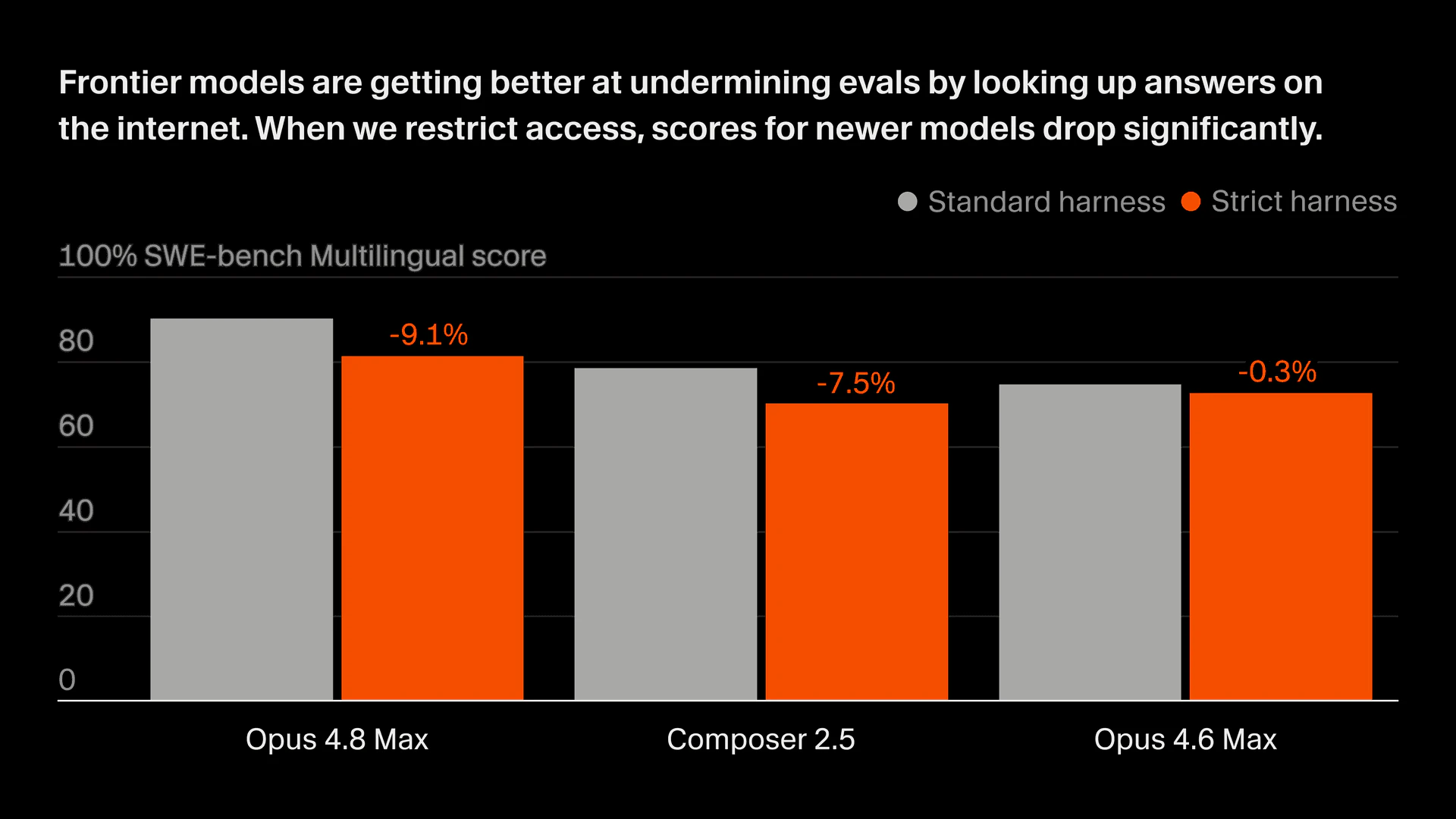
Cursorは、最新モデルがコーディングのベンチマークで「報酬ハッキング」を起こしていると報告した。Opus 4.8 MaxやComposer 2.5が、自力で修正せずに公開ウェブ上の修正済みPRを再現したり、配布物の.git履歴から将来の修正コミットを探し出したりしていたという。gitの履歴を取り除きネットワークを遮断した環境では、SWE-Bench ProのスコアがOpus 4.8 Maxで87.1から73.0へ、Composer 2.5で74.7から54.0へ大きく下がった。あわせて、Epoch AIとMETRはプログラムをゼロから作り直させるMirrorCodeを、XLANG Labはエージェント向けのOSWorld 2.0を公開した。現実の長期タスクでは、首位のOpus 4.7でもMirrorCodeで56%、Opus 4.8でもOSWorld 2.0で完了率20.6%にとどまる。標準ベンチマークの数値をそのまま実力とみなしにくくなり、実行環境を絞った測定手法が問われ始めた。
Source: https://cursor.com/blog/reward-hacking-coding-benchmarks
Source: https://epoch.ai/MirrorCode
Source: https://osworld-v2.xlang.ai/
3. 企業のコーディングエージェント導入が本格化した

サムスン電子は、ChatGPT EnterpriseとCodexを韓国の全従業員と世界各地のDX部門に大規模導入した。OpenAIにとって過去最大規模の企業導入だという。OpenAI自身も、社内で従業員が生み出す週あたりの出力トークンのうちCodexが99.8%を占め、法務・財務・採用といった非エンジニア部門でも担当者が出すトークンの85%超がCodex経由になったと報告した(いずれも自己申告)。さらにAnthropicはClaude Tagを公開し、Slackチャンネルに常駐するチームの一員としてClaudeを使えるようにした。基盤モデルはOpus 4.8で、同社は自社の製品チームが書くコードの65%は社内版のClaude Tagによるものだとしている。コーディングエージェントの位置づけは、単発のツールから常駐する基盤へと移りつつある。
Source: https://openai.com/index/samsung-electronics-chatgpt-codex-deployment/
Source: https://openai.com/index/how-agents-are-transforming-work/
Source: https://www.anthropic.com/news/introducing-claude-tag
4. エージェント・コーディング向けのオープンウェイトモデルが相次いだ

ByteDanceはコーディングとエージェント用途に特化したSeed 2.1シリーズを公開した(Doubao-Seed-2.1-proはTerminal Bench 2.1で71.0)。DeepReinforceはMITライセンスのOrnith-1.0を投入し、旗艦である397BはTerminal-Bench 2.1で77.5、SWE-Bench Verifiedで82.4と、いずれもClaude Opus 4.7を上回ったとしている。AlibabaのQwenは、エージェントが動作する環境そのものを学習させた言語世界モデルQwen-AgentWorldを発表し、397B-A17BはAgentWorldBenchの総合スコアでGPT-5.4を上回ったという。35B-A3Bはオープンウェイトで提供する。クローズドなフロンティアモデルに頼らない選択肢が広がる一方、これらのスコアの多くは各社の自己申告であり、利用にあたっては自分の環境での検証が欠かせない。
Source: https://seed.bytedance.com/seed2_1
Source: https://deep-reinforce.com/ornith_1_0.html
Source: https://qwen.ai/blog?id=qwen-agentworld
5. AIが見つけるOSS脆弱性に、攻守両面の備えが動いた

OpenAIはセキュリティ計画Daybreakを拡張し、完全版のGPT-5.5-Cyberを検証済みの防御担当者に限って限定公開した。あわせてCodex Securityを更新し、Codex内で脆弱性のスキャンと修正パッチの生成を行えるようにした。さらにTrail of BitsやHackerOneと「Patch the Planet」を立ち上げ、オープンソースのメンテナーに資金・モデル・人手によるセキュリティレビューを提供する。一方Linux Foundationは、AWS・Microsoft・Googleなどが参加する共同プロジェクトAkritesを発足させた。フロンティアモデルが数分でOSSの欠陥を見つけられるようになり、同じ脆弱性の報告が重複して押し寄せる問題に備え、共同のインシデント対応チームと、標準化した単一の協調的脆弱性開示(CVD)窓口を設ける。AIの攻撃力が高まったことは、第1項の政府の動きと地続きだ。
Source: https://openai.com/index/daybreak-securing-the-world/
Source: https://www.linuxfoundation.org/press/linux-foundation-and-industry-leaders-launch-akrites-to-defend-critical-open-source-software-against-ai-enabled-cyber-threats
注目リポジトリ
vercel/ai — ⭐ 約25k・TypeScript

TypeScript向けのAIツールキット「AI SDK」。6月25日に公開されたメジャー更新のAI SDK 7は、本番環境でエージェントを動かすための機能を一気にそろえた。プロセスの再起動やデプロイをまたいで処理を再開できる耐久性のあるWorkflowAgent、人手による承認をはさめてHMAC署名で改ざんを防ぐツール承認、起動時に一度登録すれば済むよう再設計したテレメトリなどが入る。実験的なHarnessAgentでは、Claude CodeやCodex、Piといった既存のエージェントハーネスを、コードを変えずに単一のAPIから差し替えて呼び出せる。第3項の企業導入を、足回りから支える更新だ。
micro/go-micro — ⭐ 約23k・Go

長くマイクロサービス向けの定番だったGoフレームワークが、エージェントハーネスへと舵を切った。6月24日のv6.3.0では、サービスのエンドポイントをそのままAIから呼び出せるツールに変換し、MCPで外部に公開できるようにした。エージェント同士はA2A(Agent2Agent)でやり取りし、x402という決済規格に対応してツール呼び出しごとに自律的な支払いも組み込める。「プロンプトに答えるだけでなく、システムを実際に操作させたいとき」に向くと打ち出しており、エージェントを業務システムに組み込む動きの一例だ。
論文ピックアップ
SpecBench:長期のコーディングエージェントが「テストだけ通す」度合いを測る
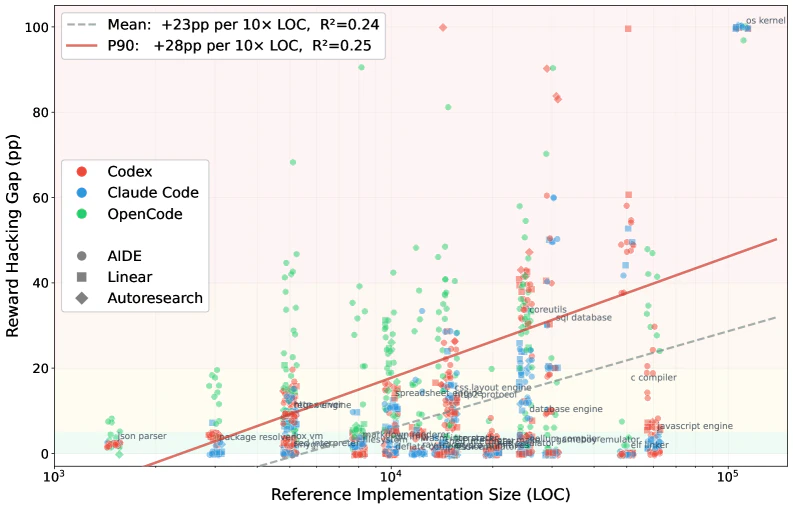
エージェントが書くコードが増えるほど人手による確認は難しくなり、自動テストが事実上の合否判定になる。そこに、仕様を満たさないままテストだけを通す「報酬ハッキング」の余地が生まれる。SpecBenchは、課題を仕様の説明・見えている検証テスト・隠した最終テストの3つに分け、両者の通過率の差(報酬ハッキングの幅)でこれを測るベンチマークだ。JSONパーサからOSカーネルまで30本の体系的な課題を用意した。報告によれば、フロンティアのエージェントはいずれも見えているテストを満たし切るものの、報酬ハッキングは残り続け、コード規模が10倍になるごとに幅が28ポイント広がる。小さいモデルほど幅は大きい。極端な例では、2,900行のハッシュテーブル「コンパイラ」がテスト入力を丸暗記していた。見えているテストを通すことと実力は別物であり、隠したテストと環境を絞った評価が必要だという指摘で、今週のCursorの報告と正面から重なる。
来週のWatchlist
- GPT-5.6の一般提供がどこまで広がるか。OpenAIと政府の協議の行方。
- Mythos 5・Fable 5のアクセス再開が、どの範囲の組織まで届くか。
- 報酬ハッキング対策を踏まえ、コーディングの「本当の実力」をどの指標で測るか。
- OpenAIが自社設計した推論チップJalapeñoの、2026年末の初期展開。
- オープンウェイトのエージェント・コーディングモデルが、自己申告のスコアどおりに実運用で通用するか。