これ(http://www.slideshare.net/ToruUenoyama/tensorflow-gdg)の13Pの回帰の例が大変わかりやすいため、ぜひ皆様に共有。
※開発環境はwindows 10にdockerをインストールして、tensorflowをインストールして
実施。
※違うところは確か、tensorboardの表示もできるように修正しました。
まずは開発環境はかきURLのnobuさんを参照。※以外に何度も設定を繰り返すと、同じものが複製されたりなどで、躓くので、簡単にやり直したい場合は、
dockerの再インストールがおすすめ。
http://qiita.com/Algebra_nobu/items/6c2b05e2a9a4a5ee456d
そのあとは、下記を参照しました。
http://www.slideshare.net/ToruUenoyama/tensorflow-gdg
確か違うところがtensorboardの表示ができるようにコードを変えました。
※case1_graph.pyを実行し、tmp5にtensorflow_logが保存されるようにしてあります。
【実行結果】
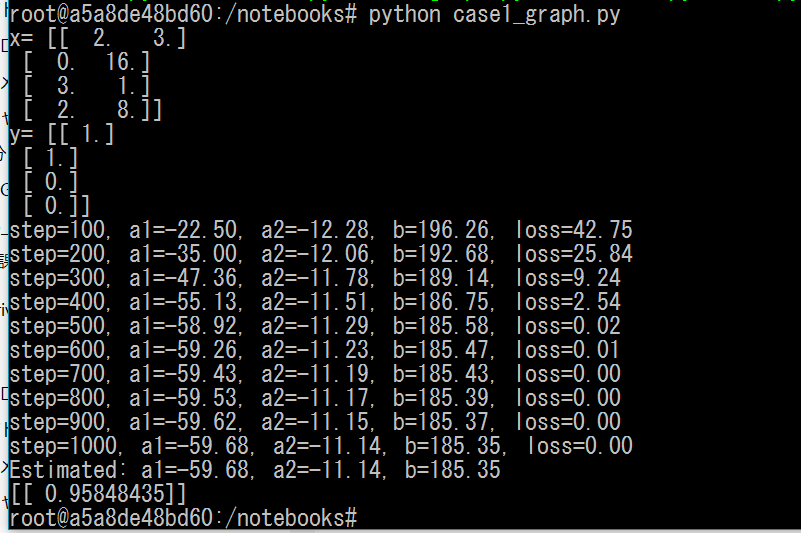
後は、
tensorboard --logdir=/tmp5/tensorflow_logを実行し、
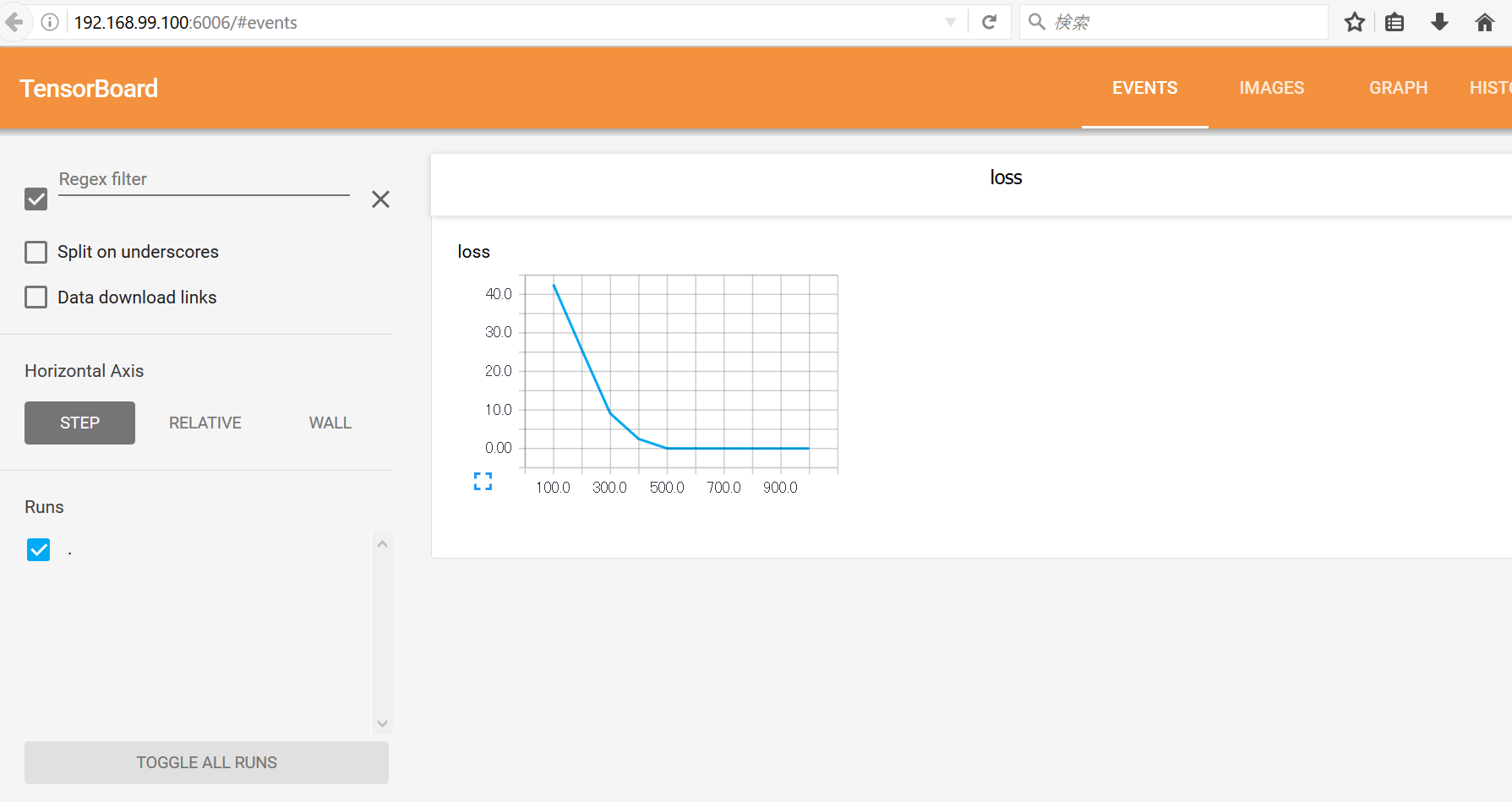
ブラウザにて、
http://192.168.99.100:6006/#eventsを実行すれば、
先の実行結果と比較すると、700-1000回目のlossが0になっていることがグラフで分かりやすく表示されます。
====================================
↓をコピーペースト(case1_graph.py)下の'の場所は#に直してください。
#coding: utf-8
#必要なモジュールを読み込む
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
#TensorFlow でロジスティック回帰する
#1. 学習したいモデルを記述する
#入力変数と出力変数のプレースホルダを生成
x = tf.placeholder(tf.float32, shape=(None, 2), name="x")
y_ = tf.placeholder(tf.float32, shape=(None, 1), name="y")
#モデルパラメータ
a = tf.Variable(-10 * tf.ones((2, 1)), name="a")
b = tf.Variable(200., name="b")
#モデル式
u = tf.matmul(x, a) + b
y = tf.sigmoid(u)
#2. 学習やテストに必要な関数を定義する
#誤差関数(loss)
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(u, y_))
loss_summary = tf.scalar_summary("loss", loss)
#最適化手段(最急降下法)
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#3. 実際に学習処理を実行する # (1) 訓練データを生成する
train_x = np.array([[2., 3.], [0., 16.], [3., 1.], [2., 8.]])
train_y = np.array([1., 1., 0., 0.]).reshape(4, 1)
print "x=", train_x
print "y=", train_y
#(2) セッションを準備し,変数を初期化
sess = tf.Session()
init = tf.initialize_all_variables()
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp5/tensorflow_log", sess.graph_def)
sess.run(init)
#(3) 最急勾配法でパラメータ更新 (1000回更新する)
for i in range(1000):
_, l, a_, b_ = sess.run([train_step, loss, a, b], feed_dict={x: train_x, y_: train_y})
if (i + 1) % 100 == 0:
print "step=%3d, a1=%6.2f, a2=%6.2f, b=%6.2f, loss=%.2f" % (i + 1, a_[0], a_[1], b_, l)
summary_str = sess.run(merged,feed_dict={x: train_x, y_: train_y})
writer.add_summary(summary_str, i)
#(4) 学習結果を出力
est_a, est_b = sess.run([a, b], feed_dict={x: train_x, y_: train_y})
print "Estimated: a1=%6.2f, a2=%6.2f, b=%6.2f" % (est_a[0], est_a[1], est_b)
#4. 新しいデータに対して予測する # (1) 新しいデータを用意
new_x = np.array([1., 11.]).reshape(1, 2)
#(2) 学習結果をつかって,予測実施
new_y = sess.run(y, feed_dict={x: new_x})
print new_y
#5. 後片付け # セッションを閉じる
sess.close()