まとめ(自戒)
- CWAgentで取得する項目は最小限に絞る:不要な項目はコスト増の要因になるため削除。
- ディメンションの扱いに注意:ディメンションの組み合わせ数だけメトリクス料金が発生する。
- Cost Explorerを定期的に確認する:異常に気づいたら「サービスごとの内訳(Usage Type)」をチェックする。
背景
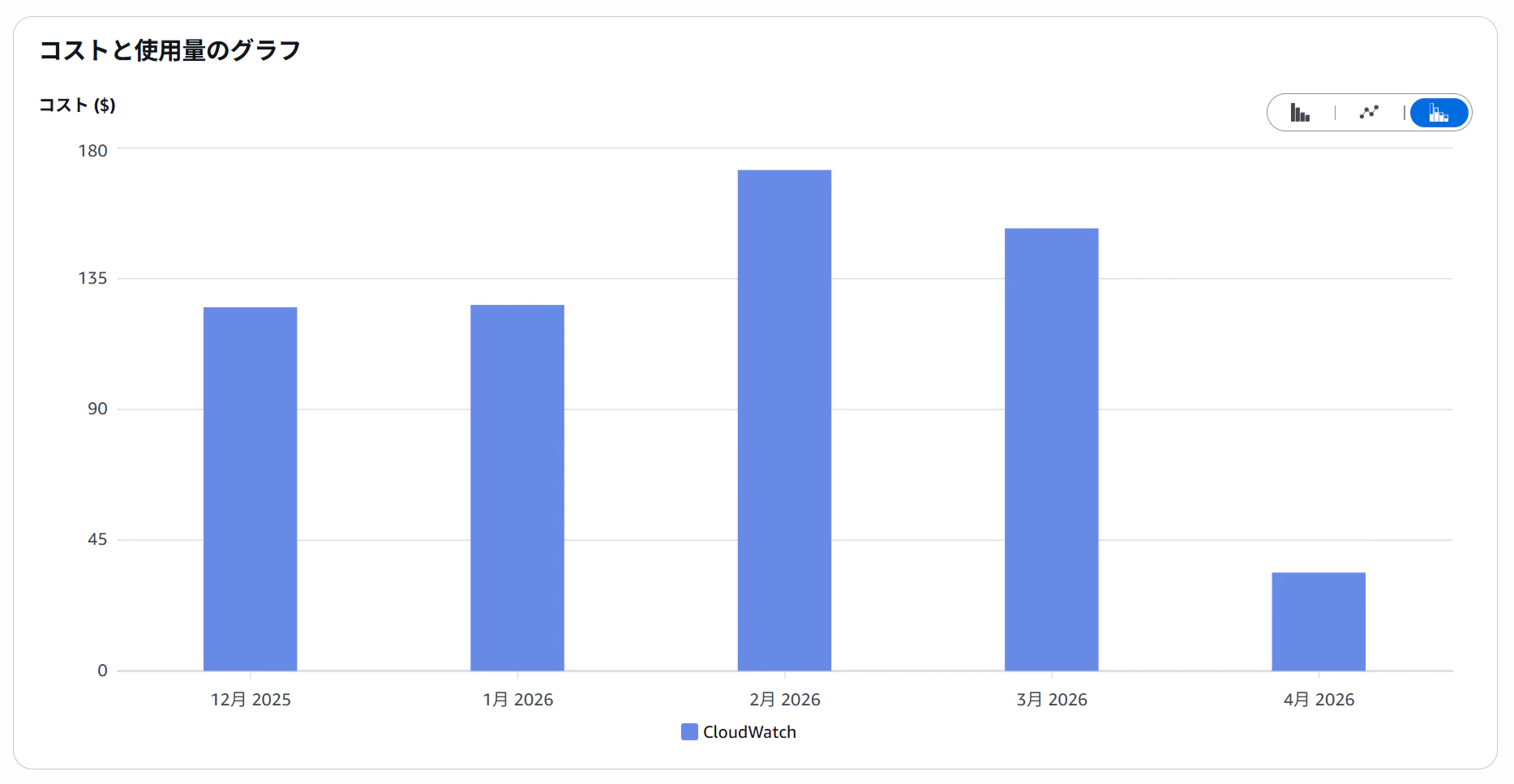
CloudWatchのコストが毎月2万円?そんなたくさんログ記録している...?
そんなことを思い、調査をおこないました。
Cost Explorerで詳細な内訳(Usage Type)を確認したところ、
原因はログの増加ではなく、EC2のCWAgentによるカスタムメトリクス(Metrics)であることが判明しました。
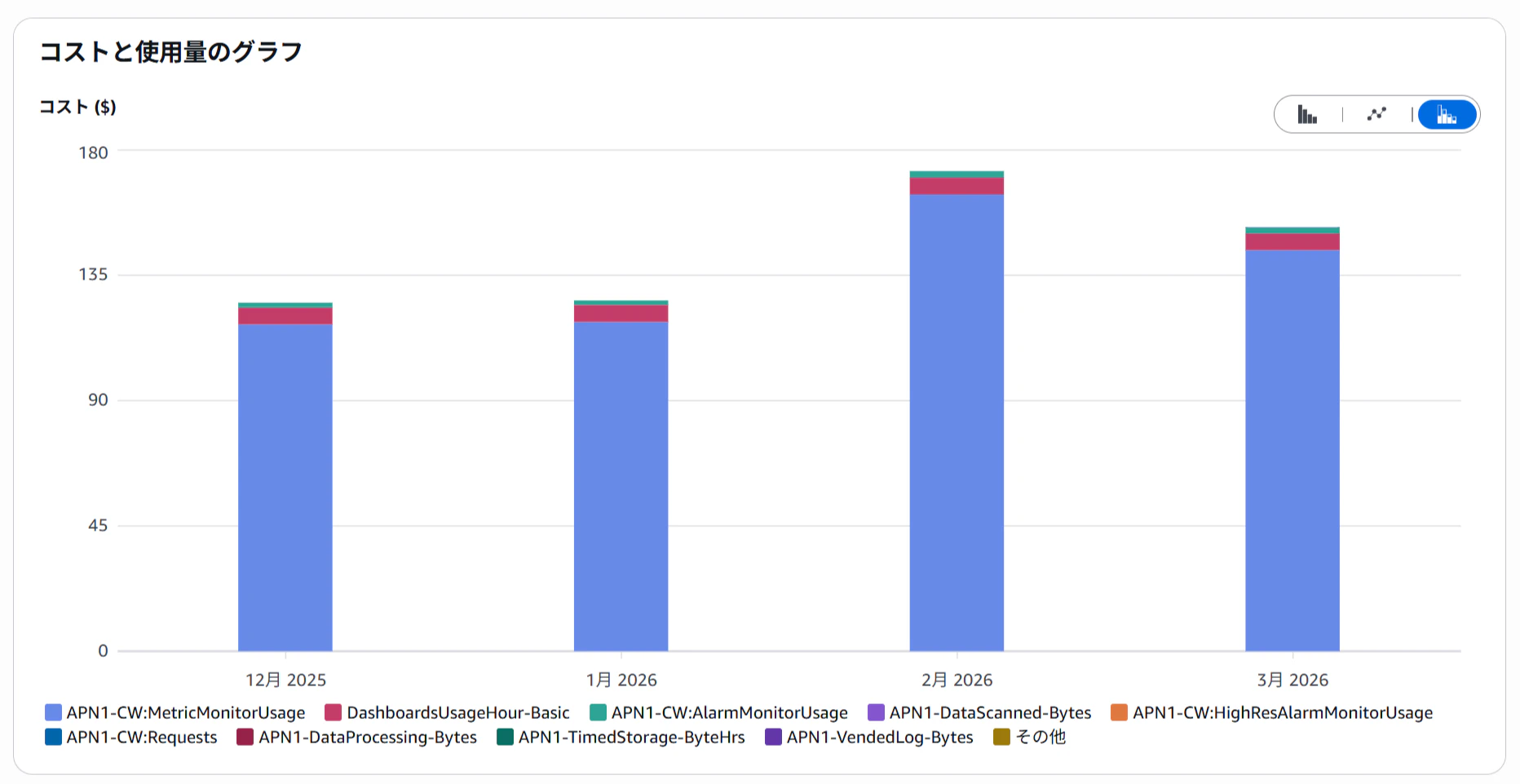
原因
メモリ使用率を取得するために導入したCWAgentですが、
設定を確認したところ、以下の2つの大きな問題が見つかりました。
問題1:ディメンションの掛け合わせによるメトリクス増大
CloudWatchメトリクスは、ディメンションの組み合わせごとに別々のメトリクスとしてカウントされ、課金されます。
元の設定では append_dimensions に4つの項目を指定していたため、1つの計測項目(例:メモリ使用率)に対して、意図せず膨大な数のメトリクスが生成されていました。
問題2:リソースのワイルドカード指定(*)
resources に "*" を指定していたため、サーバー全体だけでなく、以下の単位ですべて個別にメトリクスを送信していました。
- CPU:コア数ごと(t3.mediumの場合、2コアなので2倍)
- ディスク:パーティション(デバイス)ごと
これらが「問題1」のディメンションと掛け合わさり、メトリクス数が爆発的に増えていたのです。
{
"agent": {
"run_as_user": "root"
},
"metrics": {
"aggregation_dimensions": [
["InstanceId"]
],
"append_dimensions": {
"ImageId": "${aws:ImageId}",
"InstanceId": "${aws:InstanceId}",
"InstanceType": "${aws:InstanceType}",
"AutoScalingGroupName": "${aws:AutoScalingGroupName}"
},
"metrics_collected": {
"cpu": {
"measurement": [
"cpu_usage_idle",
"cpu_usage_iowait",
"cpu_usage_user",
"cpu_usage_system"
],
"metrics_collection_interval": 60,
"resources": ["*"],
"totalcpu": false
},
"disk": {
"measurement": [
"used_percent",
"inodes_free"
],
"metrics_collection_interval": 60,
"resources": ["*"]
},
"diskio": {
"measurement": ["io_time"],
"metrics_collection_interval": 60,
"resources": ["*"]
},
"mem": {
"measurement": ["mem_used_percent"],
"metrics_collection_interval": 60
},
"swap": {
"measurement": ["swap_used_percent"],
"metrics_collection_interval": 60
}
}
}
}
対策
修正1:ディメンションを「InstanceId」のみに集約
append_dimensions を InstanceId 1つに絞りました。
これにより、複数の属性の組み合わせでメトリクスが重複発行されるのを防ぎ、コストを大幅に抑制しました。
また、これに伴い aggregation_dimensions の設定も不要になったため削除しています。
修正2:取得項目を「メモリ」と「ディスク容量(ルートのみ)」に限定
-
CPU:デフォルトの標準メトリクス(
CPUUtilization)でサーバー全体の使用率は確認できます。
CWAgentで取得できる詳細な項目は今回は不要と判断し、削除しました。 -
ディスク容量:必要なのはルートディスクの空き容量のみだったため、
resourcesを ["/"] に固定し、項目もused_percentのみに絞りました。
{
"agent": {
"run_as_user": "root"
},
"metrics": {
"append_dimensions": {
"InstanceId": "${aws:InstanceId}"
},
"metrics_collected": {
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"disk": {
"measurement": [
"used_percent"
],
"metrics_collection_interval": 60,
"resources": [
"/"
]
}
}
}
}
設定の更新は Systems Manager Run Command を使用しました。
正しく反映されているかは、対象EC2で以下のファイルを確認することでチェックできます。
/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/ssm_AmazonCloudWatch-Config
ECS編
EC2の見直しと主にECS(Container Insight)の見直しも行いました。
Container InsightをオンにするとECSから多くのメトリクスを取得することができます。
オフにしてもCPU使用率等取得できており、今回はそちらでカバーできるのでオフにいたしました。
結果
毎月2万円くらいの削減に成功しました!!!
取得できる項目なんて多ければ多いほどええやろと思っていましたが、
クラウドではその一つひとつがコストに直結します。
定期的に Cost Explorer をチェックし、本当に必要なデータを見極めることが重要だと痛感しました...。