動作環境
GeForce GTX 1070 (8GB)
ASRock Z170M Pro4S [Intel Z170chipset]
Ubuntu 14.04 LTS desktop amd64
TensorFlow v0.11
cuDNN v5.1 for Linux
CUDA v8.0
Python 2.7.6
IPython 5.1.0 -- An enhanced Interactive Python.
gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
TensorFlowの学習過程の誤差出力をprint()で行っている。
リダイレクション(> res)付きでTensorFlowコードを実行しているが、出力先ファイル(res)のサイズがすぐには増えていかなかった。何かのタイミングの時に大きく増えるような動作だった。
flushをすればいいのではと思い調べ、以下を見つけた。
sys.stdout.flush()
以下のように92行目にsys.stdout.flush()を追加することで、学習過程の誤差出力が適時行われるようになった。
情報感謝です。
learn_in100out100.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import tensorflow as tf
import tensorflow.contrib.slim as slim
import numpy as np
'''
v0.6 Feb. 19, 2017
- add sys.stdout.flush() to immediately print
v0.5 Feb. 18, 2017
- add fc_drop()
v0.4 Feb. 15, 2017
- fix bug > ZeroDivisionError: float division by zero @ shuffle_batch()
v0.3 Feb. 15, 2017
- tweak [batch_size] for shuffle_batch()
v0.2 Feb. 15, 2017
- fix bug > different dimensions for placeholder and network
v0.1 Feb. 06, 2017
- read [test_in.csv],[test_out.csv]
'''
'''
codingrule:PEP8
'''
def fc_drop(inputs, *args, **kwargs):
# Thanks to: http://qiita.com/shngt/items/f532601b4f059ce8584f
net = slim.fully_connected(inputs, *args, **kwargs)
return slim.dropout(net, 0.5)
filename_inp = tf.train.string_input_producer(["test_in.csv"])
filename_out = tf.train.string_input_producer(["test_out.csv"])
NUM_INP_NODE = 100
NUM_OUT_NODE = 100
# parse csv
# a. input node
reader = tf.TextLineReader()
key, value = reader.read(filename_inp)
deflist = [[0.] for idx in range(NUM_INP_NODE)]
input1 = tf.decode_csv(value, record_defaults=deflist)
# b. output node
key, value = reader.read(filename_out)
deflist = [[0.] for idx in range(NUM_OUT_NODE)]
output1 = tf.decode_csv(value, record_defaults=deflist)
# c. pack
# inputs = tf.pack([input1])
inputs = input1
# outputs = tf.pack([output1])
outputs = output1
batch_size = 2
inputs_batch, output_batch = tf.train.shuffle_batch(
[inputs, outputs], batch_size, capacity=10, min_after_dequeue=batch_size)
input_ph = tf.placeholder("float", [None, 100])
output_ph = tf.placeholder("float", [None, 100])
# network
hiddens = slim.stack(input_ph, slim.fully_connected, [7, 7, 7],
activation_fn=tf.nn.sigmoid, scope="hidden")
# a. without dropout
# prediction = slim.fully_connected(
# hiddens, 100, activation_fn=None, scope="output")
# b. with dropout
drpout = slim.stack(hiddens, fc_drop, [100, 100], scope='fc')
prediction = slim.fully_connected(
drpout, 100, activation_fn=None, scope="output")
loss = tf.contrib.losses.mean_squared_error(prediction, output_ph)
train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.001))
init_op = tf.initialize_all_variables()
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
sess.run(init_op)
# for idx in range(10000):
for idx in range(100000):
inpbt, outbt = sess.run([inputs_batch, output_batch])
_, t_loss = sess.run(
[train_op, loss],
feed_dict={input_ph: inpbt, output_ph: outbt})
if (idx+1) % 100 == 0:
print("%d,%f" % (idx+1, t_loss))
sys.stdout.flush()
finally:
coord.request_stop()
coord.join(threads)
$ python learn_in100out100.py > res.learn.N\=1000_dropout@output_longrun_170218
res.learn.N=1000_dropout@output_longrun_170218が適宜更新され、Jupyterでの誤差グラフの確認が便利になった。
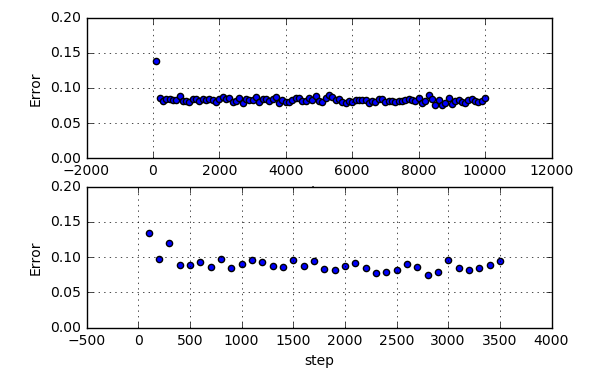
下が学習途中の結果。
全然ダメな結果ということがすぐに分かり。。。